 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Contrastive Learning for Weakly Paired Multimodal Data
Feb 03, 2026We present GROOVE, a semi-supervised multi-modal representation learning approach for high-content perturbation data where samples across modalities are weakly paired through shared perturbation labels but lack direct correspondence. Our primary contribution is GroupCLIP, a novel group-level contrastive loss that bridges the gap between CLIP for paired cross-modal data and SupCon for uni-modal supervised contrastive learning, addressing a fundamental gap in contrastive learning for weakly-paired settings. We integrate GroupCLIP with an on-the-fly backtranslating autoencoder framework to encourage cross-modally entangled representations while maintaining group-level coherence within a shared latent space. Critically, we introduce a comprehensive combinatorial evaluation framework that systematically assesses representation learners across multiple optimal transport aligners, addressing key limitations in existing evaluation strategies. This framework includes novel simulations that systematically vary shared versus modality-specific perturbation effects enabling principled assessment of method robustness. Our combinatorial benchmarking reveals that there is not yet an aligner that uniformly dominates across settings or modality pairs. Across simulations and two real single-cell genetic perturbation datasets, GROOVE performs on par with or outperforms existing approaches for downstream cross-modal matching and imputation tasks. Our ablation studies demonstrate that GroupCLIP is the key component driving performance gains. These results highlight the importance of leveraging group-level constraints for effective multi-modal representation learning in scenarios where only weak pairing is available.
Joint Embedding vs Reconstruction: Provable Benefits of Latent Space Prediction for Self Supervised Learning
May 18, 2025



Reconstruction and joint embedding have emerged as two leading paradigms in Self Supervised Learning (SSL). Reconstruction methods focus on recovering the original sample from a different view in input space. On the other hand, joint embedding methods align the representations of different views in latent space. Both approaches offer compelling advantages, yet practitioners lack clear guidelines for choosing between them. In this work, we unveil the core mechanisms that distinguish each paradigm. By leveraging closed form solutions for both approaches, we precisely characterize how the view generation process, e.g. data augmentation, impacts the learned representations. We then demonstrate that, unlike supervised learning, both SSL paradigms require a minimal alignment between augmentations and irrelevant features to achieve asymptotic optimality with increasing sample size. Our findings indicate that in scenarios where these irrelevant features have a large magnitude, joint embedding methods are preferable because they impose a strictly weaker alignment condition compared to reconstruction based methods. These results not only clarify the trade offs between the two paradigms but also substantiate the empirical success of joint embedding approaches on real world challenging datasets.
Ditch the Denoiser: Emergence of Noise Robustness in Self-Supervised Learning from Data Curriculum
May 18, 2025Self-Supervised Learning (SSL) has become a powerful solution to extract rich representations from unlabeled data. Yet, SSL research is mostly focused on clean, curated and high-quality datasets. As a result, applying SSL on noisy data remains a challenge, despite being crucial to applications such as astrophysics, medical imaging, geophysics or finance. In this work, we present a fully self-supervised framework that enables noise-robust representation learning without requiring a denoiser at inference or downstream fine-tuning. Our method first trains an SSL denoiser on noisy data, then uses it to construct a denoised-to-noisy data curriculum (i.e., training first on denoised, then noisy samples) for pretraining a SSL backbone (e.g., DINOv2), combined with a teacher-guided regularization that anchors noisy embeddings to their denoised counterparts. This process encourages the model to internalize noise robustness. Notably, the denoiser can be discarded after pretraining, simplifying deployment. On ImageNet-1k with ViT-B under extreme Gaussian noise ($\sigma=255$, SNR = 0.72 dB), our method improves linear probing accuracy by 4.8% over DINOv2, demonstrating that denoiser-free robustness can emerge from noise-aware pretraining. The code is available at https://github.com/wenquanlu/noisy_dinov2.
Distributional Reduction: Unifying Dimensionality Reduction and Clustering with Gromov-Wasserstein Projection
Feb 03, 2024Unsupervised learning aims to capture the underlying structure of potentially large and high-dimensional datasets. Traditionally, this involves using dimensionality reduction methods to project data onto interpretable spaces or organizing points into meaningful clusters. In practice, these methods are used sequentially, without guaranteeing that the clustering aligns well with the conducted dimensionality reduction. In this work, we offer a fresh perspective: that of distributions. Leveraging tools from optimal transport, particularly the Gromov-Wasserstein distance, we unify clustering and dimensionality reduction into a single framework called distributional reduction. This allows us to jointly address clustering and dimensionality reduction with a single optimization problem. Through comprehensive experiments, we highlight the versatility and interpretability of our method and show that it outperforms existing approaches across a variety of image and genomics datasets.
Interpolating between Clustering and Dimensionality Reduction with Gromov-Wasserstein
Oct 05, 2023

We present a versatile adaptation of existing dimensionality reduction (DR) objectives, enabling the simultaneous reduction of both sample and feature sizes. Correspondances between input and embedding samples are computed through a semi-relaxed Gromov-Wasserstein optimal transport (OT) problem. When the embedding sample size matches that of the input, our model recovers classical popular DR models. When the embedding's dimensionality is unconstrained, we show that the OT plan delivers a competitive hard clustering. We emphasize the importance of intermediate stages that blend DR and clustering for summarizing real data and apply our method to visualize datasets of images.
Optimal Transport with Adaptive Regularisation
Oct 04, 2023Regularising the primal formulation of optimal transport (OT) with a strictly convex term leads to enhanced numerical complexity and a denser transport plan. Many formulations impose a global constraint on the transport plan, for instance by relying on entropic regularisation. As it is more expensive to diffuse mass for outlier points compared to central ones, this typically results in a significant imbalance in the way mass is spread across the points. This can be detrimental for some applications where a minimum of smoothing is required per point. To remedy this, we introduce OT with Adaptive RegularIsation (OTARI), a new formulation of OT that imposes constraints on the mass going in or/and out of each point. We then showcase the benefits of this approach for domain adaptation.
SNEkhorn: Dimension Reduction with Symmetric Entropic Affinities
May 23, 2023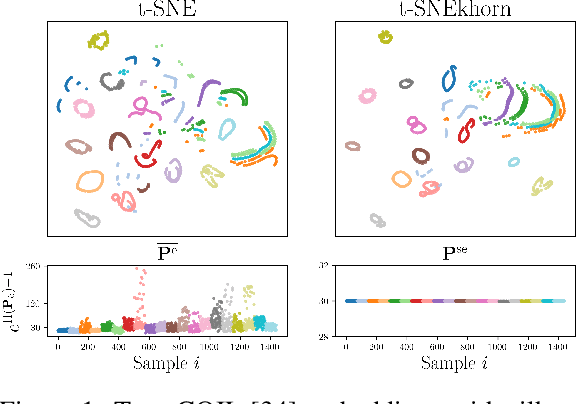



Many approaches in machine learning rely on a weighted graph to encode the similarities between samples in a dataset. Entropic affinities (EAs), which are notably used in the popular Dimensionality Reduction (DR) algorithm t-SNE, are particular instances of such graphs. To ensure robustness to heterogeneous sampling densities, EAs assign a kernel bandwidth parameter to every sample in such a way that the entropy of each row in the affinity matrix is kept constant at a specific value, whose exponential is known as perplexity. EAs are inherently asymmetric and row-wise stochastic, but they are used in DR approaches after undergoing heuristic symmetrization methods that violate both the row-wise constant entropy and stochasticity properties. In this work, we uncover a novel characterization of EA as an optimal transport problem, allowing a natural symmetrization that can be computed efficiently using dual ascent. The corresponding novel affinity matrix derives advantages from symmetric doubly stochastic normalization in terms of clustering performance, while also effectively controlling the entropy of each row thus making it particularly robust to varying noise levels. Following, we present a new DR algorithm, SNEkhorn, that leverages this new affinity matrix. We show its clear superiority to state-of-the-art approaches with several indicators on both synthetic and real-world datasets.