 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGICDM: Mitigating Hubness for Reliable Distance-Based Generative Model Evaluation
Feb 18, 2026Generative model evaluation commonly relies on high-dimensional embedding spaces to compute distances between samples. We show that dataset representations in these spaces are affected by the hubness phenomenon, which distorts nearest neighbor relationships and biases distance-based metrics. Building on the classical Iterative Contextual Dissimilarity Measure (ICDM), we introduce Generative ICDM (GICDM), a method to correct neighborhood estimation for both real and generated data. We introduce a multi-scale extension to improve empirical behavior. Extensive experiments on synthetic and real benchmarks demonstrate that GICDM resolves hubness-induced failures, restores reliable metric behavior, and improves alignment with human judgment.
Enhanced Generative Model Evaluation with Clipped Density and Coverage
Jul 02, 2025

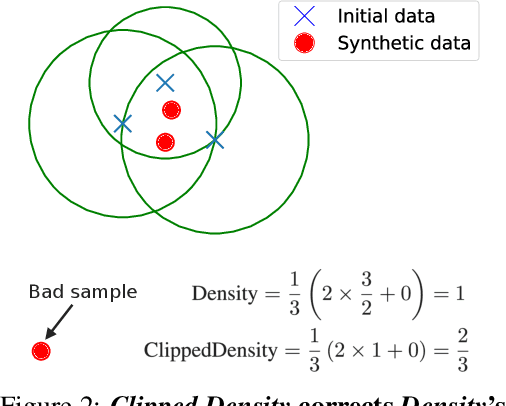

Although generative models have made remarkable progress in recent years, their use in critical applications has been hindered by their incapacity to reliably evaluate sample quality. Quality refers to at least two complementary concepts: fidelity and coverage. Current quality metrics often lack reliable, interpretable values due to an absence of calibration or insufficient robustness to outliers. To address these shortcomings, we introduce two novel metrics, Clipped Density and Clipped Coverage. By clipping individual sample contributions and, for fidelity, the radii of nearest neighbor balls, our metrics prevent out-of-distribution samples from biasing the aggregated values. Through analytical and empirical calibration, these metrics exhibit linear score degradation as the proportion of poor samples increases. Thus, they can be straightforwardly interpreted as equivalent proportions of good samples. Extensive experiments on synthetic and real-world datasets demonstrate that Clipped Density and Clipped Coverage outperform existing methods in terms of robustness, sensitivity, and interpretability for evaluating generative models.