 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUM Parts: Benchmarking Part-Level Semantic Segmentation of Urban Meshes
Mar 21, 2025Semantic segmentation in urban scene analysis has mainly focused on images or point clouds, while textured meshes - offering richer spatial representation - remain underexplored. This paper introduces SUM Parts, the first large-scale dataset for urban textured meshes with part-level semantic labels, covering about 2.5 km2 with 21 classes. The dataset was created using our own annotation tool, which supports both face- and texture-based annotations with efficient interactive selection. We also provide a comprehensive evaluation of 3D semantic segmentation and interactive annotation methods on this dataset. Our project page is available at https://tudelft3d.github.io/SUMParts/.
DDL-MVS: Depth Discontinuity Learning for MVS Networks
Mar 30, 2022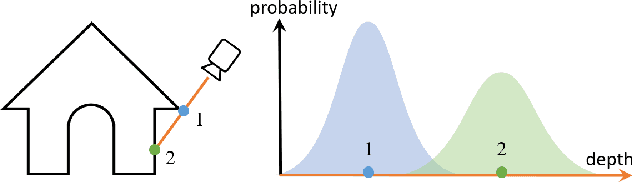


Traditional MVS methods have good accuracy but struggle with completeness, while recently developed learning-based multi-view stereo (MVS) techniques have improved completeness except accuracy being compromised. We propose depth discontinuity learning for MVS methods, which further improves accuracy while retaining the completeness of the reconstruction. Our idea is to jointly estimate the depth and boundary maps where the boundary maps are explicitly used for further refinement of the depth maps. We validate our idea and demonstrate that our strategies can be easily integrated into the existing learning-based MVS pipeline where the reconstruction depends on high-quality depth map estimation. Extensive experiments on various datasets show that our method improves reconstruction quality compared to baseline. Experiments also demonstrate that the presented model and strategies have good generalization capabilities. The source code will be available soon.
PSSNet: Planarity-sensible Semantic Segmentation of Large-scale Urban Meshes
Feb 09, 2022

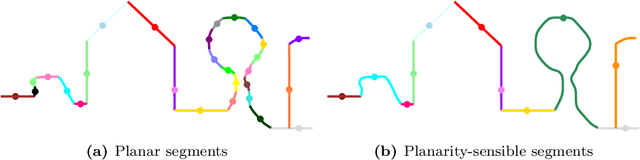
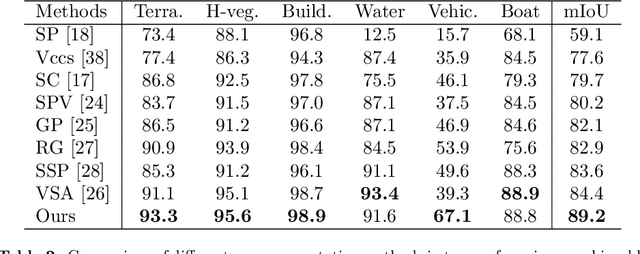
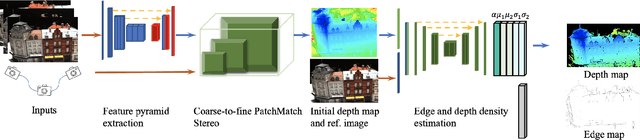
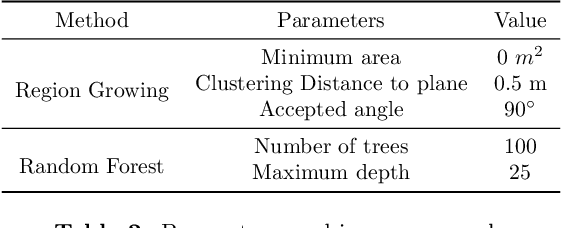
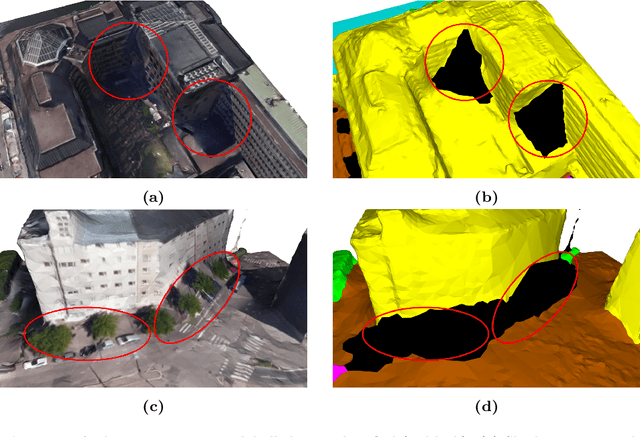
We introduce a novel deep learning-based framework to interpret 3D urban scenes represented as textured meshes. Based on the observation that object boundaries typically align with the boundaries of planar regions, our framework achieves semantic segmentation in two steps: planarity-sensible over-segmentation followed by semantic classification. The over-segmentation step generates an initial set of mesh segments that capture the planar and non-planar regions of urban scenes. In the subsequent classification step, we construct a graph that encodes geometric and photometric features of the segments in its nodes and multi-scale contextual features in its edges. The final semantic segmentation is obtained by classifying the segments using a graph convolutional network. Experiments and comparisons on a large semantic urban mesh benchmark demonstrate that our approach outperforms the state-of-the-art methods in terms of boundary quality and mean IoU (intersection over union). Besides, we also introduce several new metrics for evaluating mesh over-segmentation methods dedicated for semantic segmentation, and our proposed over-segmentation approach outperforms state-of-the-art methods on all metrics. Our source code will be released when the paper is accepted.
Reconstructing Compact Building Models from Point Clouds Using Deep Implicit Fields
Jan 09, 2022
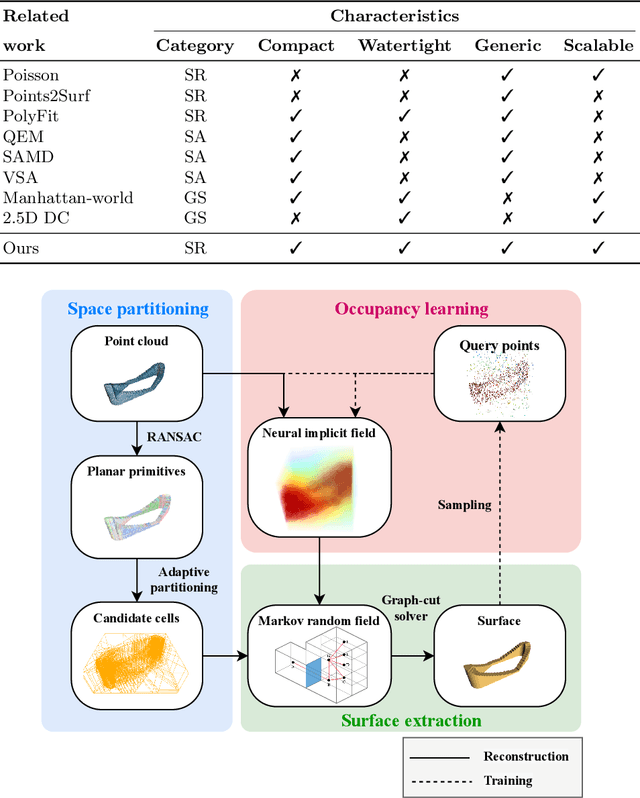

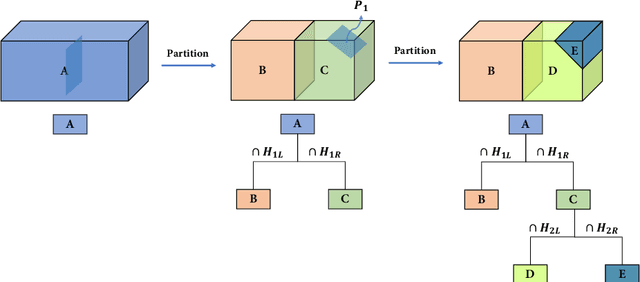
Three-dimensional (3D) building models play an increasingly pivotal role in many real-world applications while obtaining a compact representation of buildings remains an open problem. In this paper, we present a novel framework for reconstructing compact, watertight, polygonal building models from point clouds. Our framework comprises three components: (a) a cell complex is generated via adaptive space partitioning that provides a polyhedral embedding as the candidate set; (b) an implicit field is learned by a deep neural network that facilitates building occupancy estimation; (c) a Markov random field is formulated to extract the outer surface of a building via combinatorial optimization. We evaluate and compare our method with state-of-the-art methods in shape reconstruction, surface approximation, and geometry simplification. Experiments on both synthetic and real-world point clouds have demonstrated that, with our neural-guided strategy, high-quality building models can be obtained with significant advantages in fidelity, compactness, and computational efficiency. Our method shows robustness to noise and insufficient measurements, and it can directly generalize from synthetic scans to real-world measurements. The source code of this work is freely available at https://github.com/chenzhaiyu/points2poly.
SUM: A Benchmark Dataset of Semantic Urban Meshes
Feb 27, 2021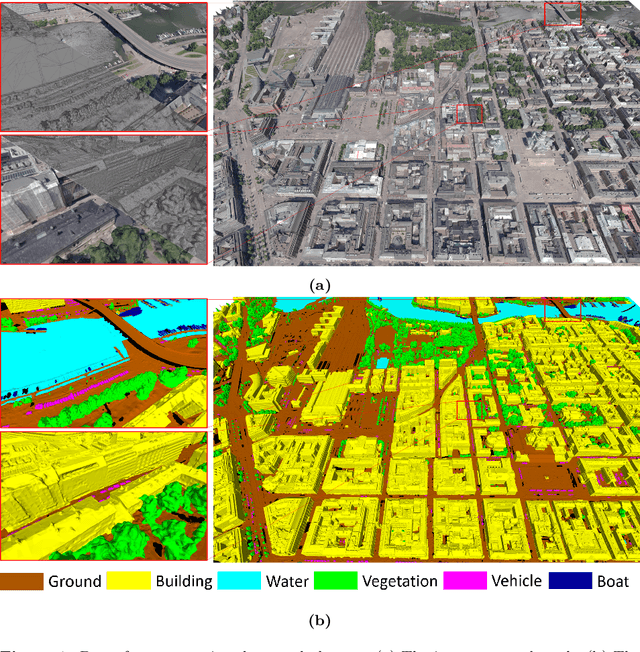
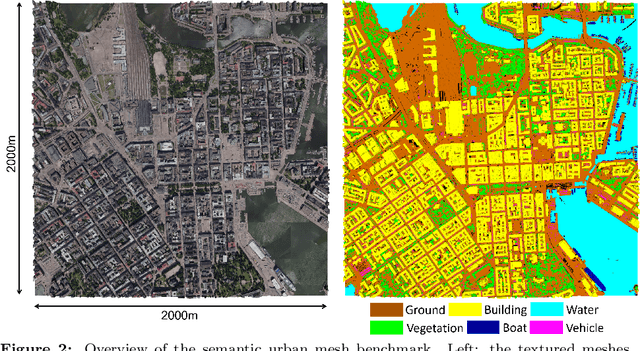
Recent developments in data acquisition technology allow us to collect 3D texture meshes quickly. Those can help us understand and analyse the urban environment, and as a consequence are useful for several applications like spatial analysis and urban planning. Semantic segmentation of texture meshes through deep learning methods can enhance this understanding, but it requires a lot of labelled data. This paper introduces a new benchmark dataset of semantic urban meshes, a novel semi-automatic annotation framework, and an open-source annotation tool for 3D meshes. In particular, our dataset covers about 4 km2 in Helsinki (Finland), with six classes, and we estimate that we save about 600 hours of labelling work using our annotation framework, which includes initial segmentation and interactive refinement. Furthermore, we compare the performance of several representative 3D semantic segmentation methods on our annotated dataset. The results show our initial segmentation outperforms other methods and achieves an overall accuracy of 93.0% and mIoU of 66.2% with less training time compared to other deep learning methods. We also evaluate the effect of the input training data, which shows that our method only requires about 7% (which covers about 0.23 km2) to approach robust and adequate results whereas KPConv needs at least 33% (which covers about 1.0 km2).
The Hessigheim 3D (H3D) Benchmark on Semantic Segmentation of High-Resolution 3D Point Clouds and Textured Meshes from UAV LiDAR and Multi-View-Stereo
Feb 25, 2021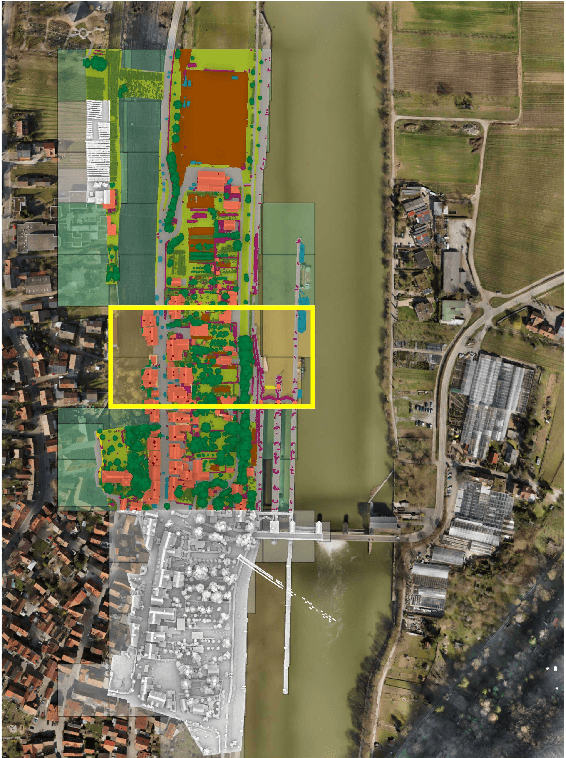
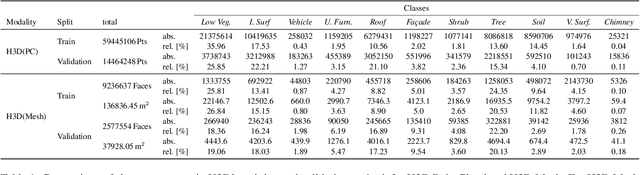


Automated semantic segmentation and object detection are of great importance in geospatial data analysis. However, supervised machine learning systems such as convolutional neural networks require large corpora of annotated training data. Especially in the geospatial domain, such datasets are quite scarce. Within this paper, we aim to alleviate this issue by introducing a new annotated 3D dataset that is unique in three ways: i) The dataset consists of both an Unmanned Aerial Vehicle (UAV) laser scanning point cloud and a 3D textured mesh. ii) The point cloud features a mean point density of about 800 pts/sqm and the oblique imagery used for 3D mesh texturing realizes a ground sampling distance of about 2-3 cm. This enables the identification of fine-grained structures and represents the state of the art in UAV-based mapping. iii) Both data modalities will be published for a total of three epochs allowing applications such as change detection. The dataset depicts the village of Hessigheim (Germany), henceforth referred to as H3D. It is designed to promote research in the field of 3D data analysis on one hand and to evaluate and rank existing and emerging approaches for semantic segmentation of both data modalities on the other hand. Ultimately, we hope that H3D will become a widely used benchmark dataset in company with the well-established ISPRS Vaihingen 3D Semantic Labeling Challenge benchmark (V3D). The dataset can be downloaded from https://ifpwww.ifp.uni-stuttgart.de/benchmark/hessigheim/default.aspx.