 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Textured Non-manifold 3D Meshes using Transformers
Apr 02, 2026Textured 3D meshes jointly represent geometry, topology, and appearance, yet their irregular structure poses significant challenges for deep-learning-based semantic segmentation. While a few recent methods operate directly on meshes without imposing geometric constraints, they typically overlook the rich textural information also provided by such meshes. We introduce a texture-aware transformer that learns directly from raw pixels associated with each mesh face, coupled with a new hierarchical learning scheme for multi-scale feature aggregation. A texture branch summarizes all face-level pixels into a learnable token, which is fused with geometrical descriptors and processed by a stack of Two-Stage Transformer Blocks (TSTB), which allow for both a local and a global information flow. We evaluate our model on the Semantic Urban Meshes (SUM) benchmark and a newly curated cultural-heritage dataset comprising textured roof tiles with triangle-level annotations for damage types. Our method achieves 81.9\% mF1 and 94.3\% OA on SUM and 49.7\% mF1 and 72.8\% OA on the new dataset, substantially outperforming existing approaches.
Open-Vocabulary Semantic Segmentation in Remote Sensing via Hierarchical Attention Masking and Model Composition
Feb 27, 2026In this paper, we propose ReSeg-CLIP, a new training-free Open-Vocabulary Semantic Segmentation method for remote sensing data. To compensate for the problems of vision language models, such as CLIP in semantic segmentation caused by inappropriate interactions within the self-attention layers, we introduce a hierarchical scheme utilizing masks generated by SAM to constrain the interactions at multiple scales. We also present a model composition approach that averages the parameters of multiple RS-specific CLIP variants, taking advantage of a new weighting scheme that evaluates representational quality using varying text prompts. Our method achieves state-of-the-art results across three RS benchmarks without additional training.
Evaluating saliency scores in point clouds of natural environments by learning surface anomalies
Aug 26, 2024



In recent years, three-dimensional point clouds are used increasingly to document natural environments. Each dataset contains a diverse set of objects, at varying shapes and sizes, distributed throughout the data and intricately intertwined with the topography. Therefore, regions of interest are difficult to find and consequent analyses become a challenge. Inspired from visual perception principles, we propose to differentiate objects of interest from the cluttered environment by evaluating how much they stand out from their surroundings, i.e., their geometric salience. Previous saliency detection approaches suggested mostly handcrafted attributes for the task. However, such methods fail when the data are too noisy or have high levels of texture. Here we propose a learning-based mechanism that accommodates noise and textured surfaces. We assume that within the natural environment any change from the prevalent surface would suggest a salient object. Thus, we first learn the underlying surface and then search for anomalies within it. Initially, a deep neural network is trained to reconstruct the surface. Regions where the reconstructed part deviates significantly from the original point cloud yield a substantial reconstruction error, signifying an anomaly, i.e., saliency. We demonstrate the effectiveness of the proposed approach by searching for salient features in various natural scenarios, which were acquired by different acquisition platforms. We show the strong correlation between the reconstruction error and salient objects.
Multimodal Metadata Assignment for Cultural Heritage Artifacts
Jun 01, 2024We develop a multimodal classifier for the cultural heritage domain using a late fusion approach and introduce a novel dataset. The three modalities are Image, Text, and Tabular data. We based the image classifier on a ResNet convolutional neural network architecture and the text classifier on a multilingual transformer architecture (XML-Roberta). Both are trained as multitask classifiers and use the focal loss to handle class imbalance. Tabular data and late fusion are handled by Gradient Tree Boosting. We also show how we leveraged specific data models and taxonomy in a Knowledge Graph to create the dataset and to store classification results. All individual classifiers accurately predict missing properties in the digitized silk artifacts, with the multimodal approach providing the best results.
Appearance Based Deep Domain Adaptation for the Classification of Aerial Images
Aug 17, 2021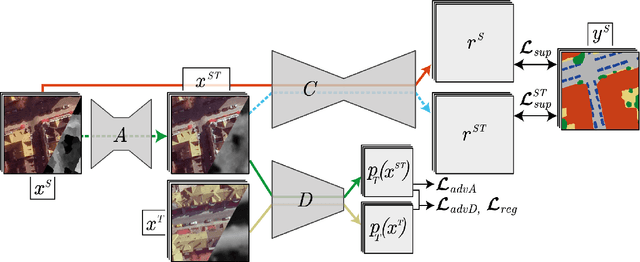
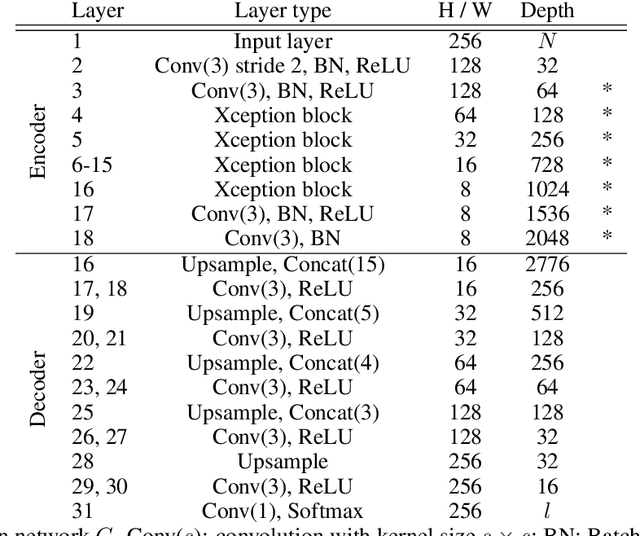
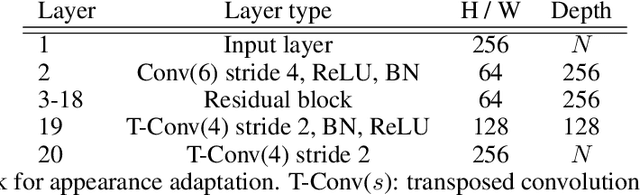
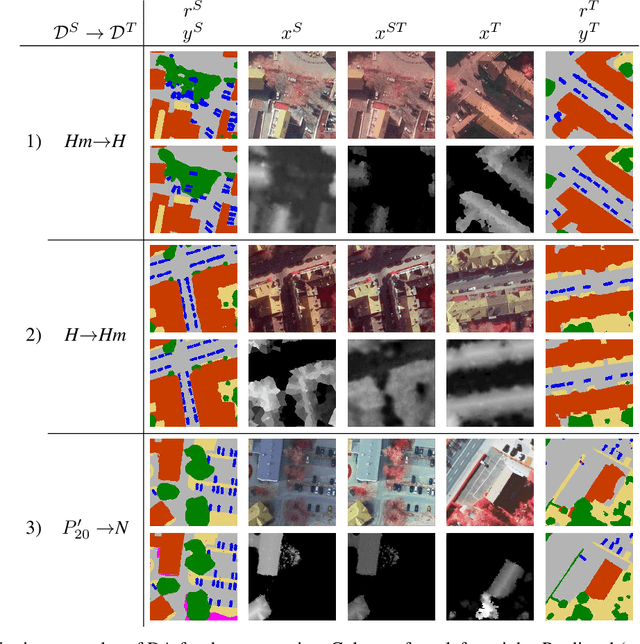
This paper addresses domain adaptation for the pixel-wise classification of remotely sensed data using deep neural networks (DNN) as a strategy to reduce the requirements of DNN with respect to the availability of training data. We focus on the setting in which labelled data are only available in a source domain DS, but not in a target domain DT. Our method is based on adversarial training of an appearance adaptation network (AAN) that transforms images from DS such that they look like images from DT. Together with the original label maps from DS, the transformed images are used to adapt a DNN to DT. We propose a joint training strategy of the AAN and the classifier, which constrains the AAN to transform the images such that they are correctly classified. In this way, objects of a certain class are changed such that they resemble objects of the same class in DT. To further improve the adaptation performance, we propose a new regularization loss for the discriminator network used in domain adversarial training. We also address the problem of finding the optimal values of the trained network parameters, proposing an unsupervised entropy based parameter selection criterion which compensates for the fact that there is no validation set in DT that could be monitored. As a minor contribution, we present a new weighting strategy for the cross-entropy loss, addressing the problem of imbalanced class distributions. Our method is evaluated in 42 adaptation scenarios using datasets from 7 cities, all consisting of high-resolution digital orthophotos and height data. It achieves a positive transfer in all cases, and on average it improves the performance in the target domain by 4.3% in overall accuracy. In adaptation scenarios between datasets from the ISPRS semantic labelling benchmark our method outperforms those from recent publications by 10-20% with respect to the mean intersection over union.
Pose Estimation and 3D Reconstruction of Vehicles from Stereo-Images Using a Subcategory-Aware Shape Prior
Jul 22, 2021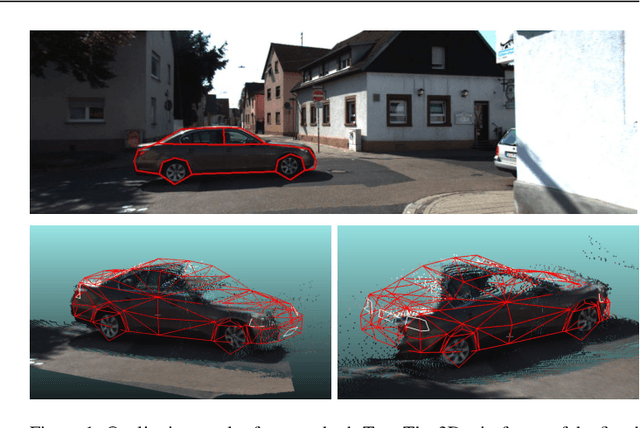
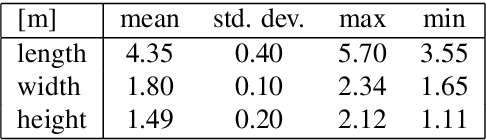

The 3D reconstruction of objects is a prerequisite for many highly relevant applications of computer vision such as mobile robotics or autonomous driving. To deal with the inverse problem of reconstructing 3D objects from their 2D projections, a common strategy is to incorporate prior object knowledge into the reconstruction approach by establishing a 3D model and aligning it to the 2D image plane. However, current approaches are limited due to inadequate shape priors and the insufficiency of the derived image observations for a reliable alignment with the 3D model. The goal of this paper is to show how 3D object reconstruction can profit from a more sophisticated shape prior and from a combined incorporation of different observation types inferred from the images. We introduce a subcategory-aware deformable vehicle model that makes use of a prediction of the vehicle type for a more appropriate regularisation of the vehicle shape. A multi-branch CNN is presented to derive predictions of the vehicle type and orientation. This information is also introduced as prior information for model fitting. Furthermore, the CNN extracts vehicle keypoints and wireframes, which are well-suited for model-to-image association and model fitting. The task of pose estimation and reconstruction is addressed by a versatile probabilistic model. Extensive experiments are conducted using two challenging real-world data sets on both of which the benefit of the developed shape prior can be shown. A comparison to state-of-the-art methods for vehicle pose estimation shows that the proposed approach performs on par or better, confirming the suitability of the developed shape prior and probabilistic model for vehicle reconstruction.
A hierarchical deep learning framework for the consistent classification of land use objects in geospatial databases
Apr 14, 2021
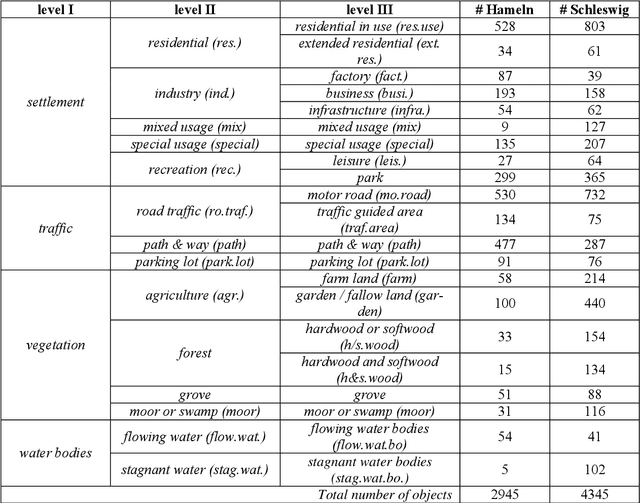
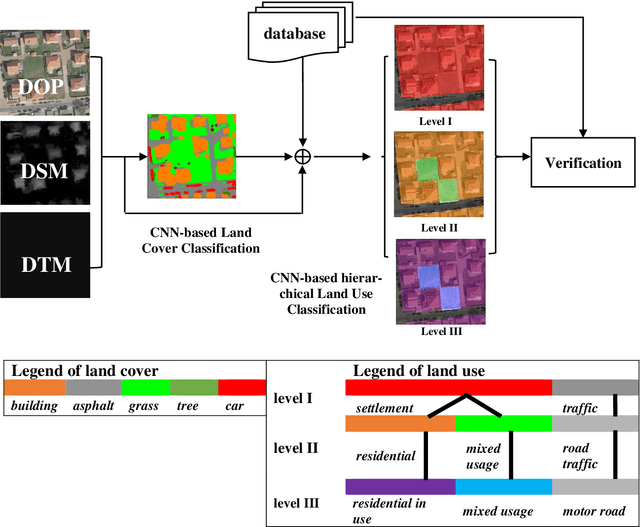

Land use as contained in geospatial databases constitutes an essential input for different applica-tions such as urban management, regional planning and environmental monitoring. In this paper, a hierarchical deep learning framework is proposed to verify the land use information. For this purpose, a two-step strategy is applied. First, given high-resolution aerial images, the land cover information is determined. To achieve this, an encoder-decoder based convolutional neural net-work (CNN) is proposed. Second, the pixel-wise land cover information along with the aerial images serves as input for another CNN to classify land use. Because the object catalogue of geospatial databases is frequently constructed in a hierarchical manner, we propose a new CNN-based method aiming to predict land use in multiple levels hierarchically and simultaneously. A so called Joint Optimization (JO) is proposed where predictions are made by selecting the hier-archical tuple over all levels which has the maximum joint class scores, providing consistent results across the different levels. The conducted experiments show that the CNN relying on JO outperforms previous results, achieving an overall accuracy up to 92.5%. In addition to the individual experiments on two test sites, we investigate whether data showing different characteristics can improve the results of land cover and land use classification, when processed together. To do so, we combine the two datasets and undertake some additional experiments. The results show that adding more data helps both land cover and land use classification, especially the identification of underrepre-sented categories, despite their different characteristics.
The Hessigheim 3D (H3D) Benchmark on Semantic Segmentation of High-Resolution 3D Point Clouds and Textured Meshes from UAV LiDAR and Multi-View-Stereo
Feb 25, 2021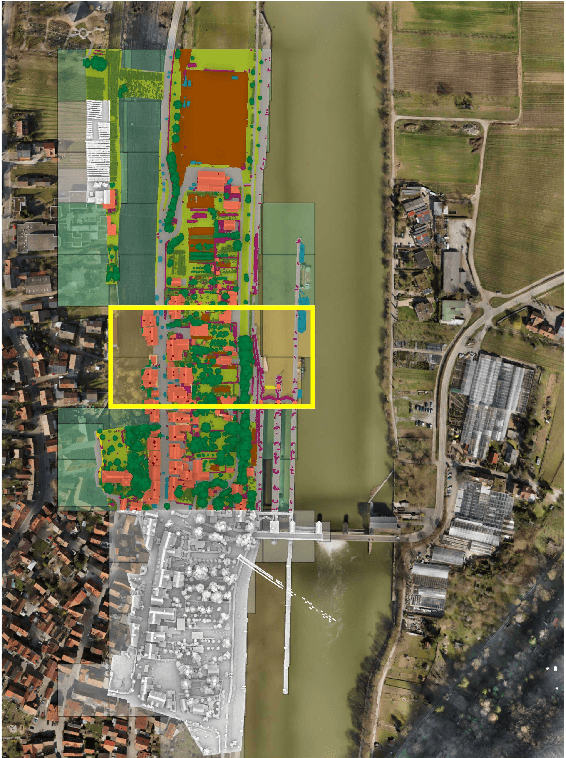
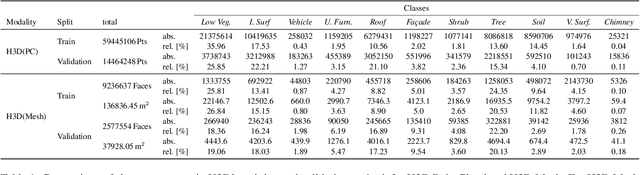


Automated semantic segmentation and object detection are of great importance in geospatial data analysis. However, supervised machine learning systems such as convolutional neural networks require large corpora of annotated training data. Especially in the geospatial domain, such datasets are quite scarce. Within this paper, we aim to alleviate this issue by introducing a new annotated 3D dataset that is unique in three ways: i) The dataset consists of both an Unmanned Aerial Vehicle (UAV) laser scanning point cloud and a 3D textured mesh. ii) The point cloud features a mean point density of about 800 pts/sqm and the oblique imagery used for 3D mesh texturing realizes a ground sampling distance of about 2-3 cm. This enables the identification of fine-grained structures and represents the state of the art in UAV-based mapping. iii) Both data modalities will be published for a total of three epochs allowing applications such as change detection. The dataset depicts the village of Hessigheim (Germany), henceforth referred to as H3D. It is designed to promote research in the field of 3D data analysis on one hand and to evaluate and rank existing and emerging approaches for semantic segmentation of both data modalities on the other hand. Ultimately, we hope that H3D will become a widely used benchmark dataset in company with the well-established ISPRS Vaihingen 3D Semantic Labeling Challenge benchmark (V3D). The dataset can be downloaded from https://ifpwww.ifp.uni-stuttgart.de/benchmark/hessigheim/default.aspx.
Probabilistic Vehicle Reconstruction Using a Multi-Task CNN
Feb 21, 2021
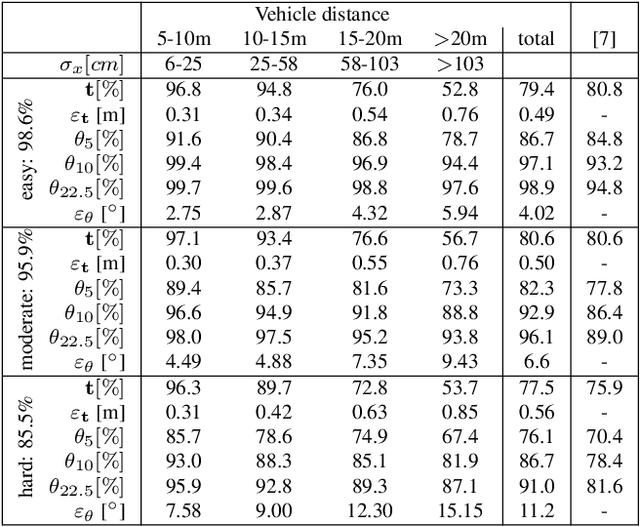
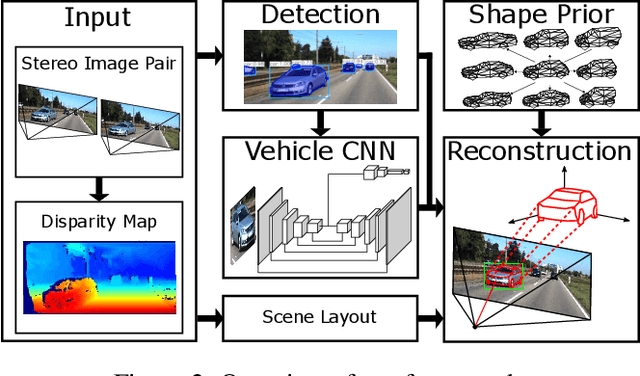

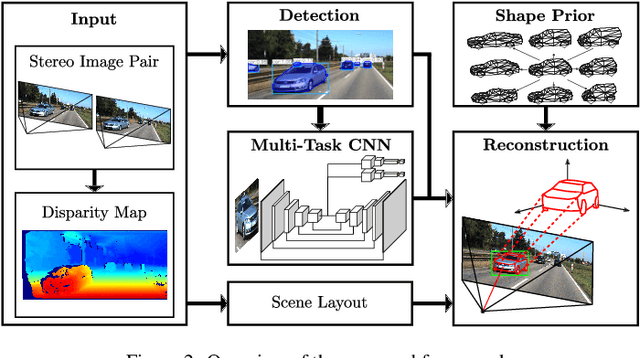
The retrieval of the 3D pose and shape of objects from images is an ill-posed problem. A common way to object reconstruction is to match entities such as keypoints, edges, or contours of a deformable 3D model, used as shape prior, to their corresponding entities inferred from the image. However, such approaches are highly sensitive to model initialisation, imprecise keypoint localisations and/or illumination conditions. In this paper, we present a probabilistic approach for shape-aware 3D vehicle reconstruction from stereo images that leverages the outputs of a novel multi-task CNN. Specifically, we train a CNN that outputs probability distributions for the vehicle's orientation and for both, vehicle keypoints and wireframe edges. Together with 3D stereo information we integrate the predicted distributions into a common probabilistic framework. We believe that the CNN-based detection of wireframe edges reduces the sensitivity to illumination conditions and object contrast and that using the raw probability maps instead of inferring keypoint positions reduces the sensitivity to keypoint localisation errors. We show that our method achieves state-of-the-art results, evaluating our method on the challenging KITTI benchmark and on our own new 'Stereo-Vehicle' dataset.
A two-layer Conditional Random Field for the classification of partially occluded objects
Sep 13, 2013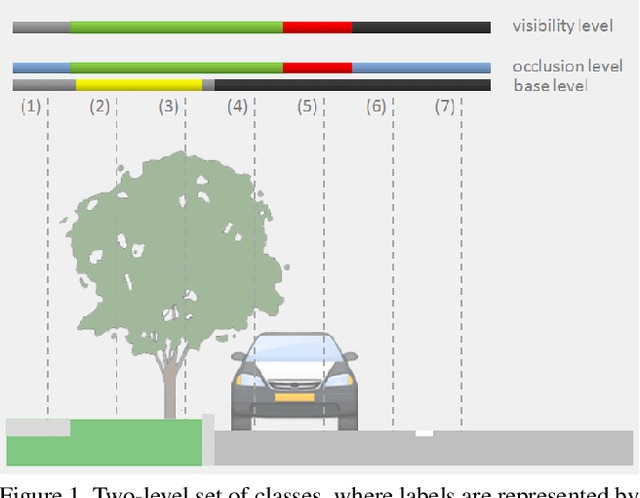
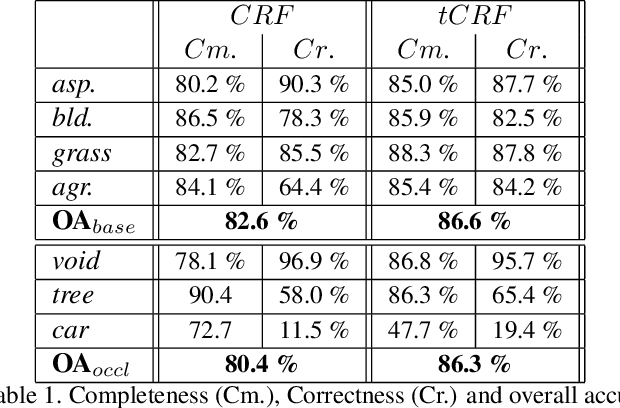
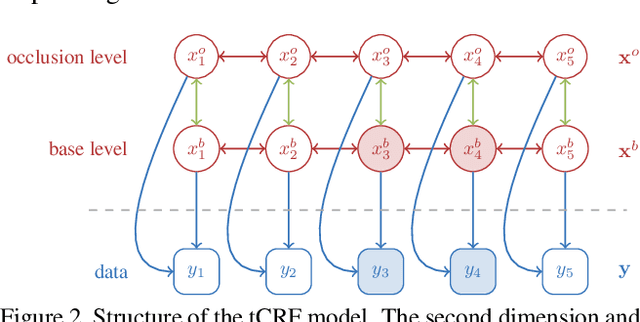
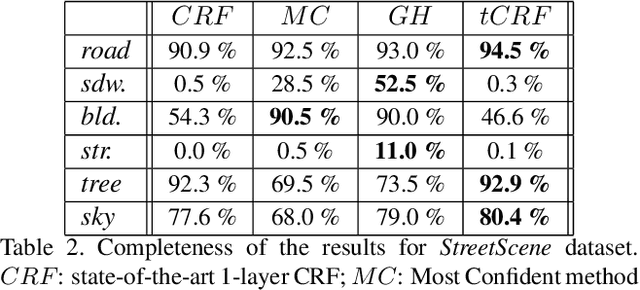
Conditional Random Fields (CRF) are among the most popular techniques for image labelling because of their flexibility in modelling dependencies between the labels and the image features. This paper proposes a novel CRF-framework for image labeling problems which is capable to classify partially occluded objects. Our approach is evaluated on aerial near-vertical images as well as on urban street-view images and compared with another methods.