 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBird Distribution Modelling using Remote Sensing and Citizen Science data
May 01, 2023



Climate change is a major driver of biodiversity loss, changing the geographic range and abundance of many species. However, there remain significant knowledge gaps about the distribution of species, due principally to the amount of effort and expertise required for traditional field monitoring. We propose an approach leveraging computer vision to improve species distribution modelling, combining the wide availability of remote sensing data with sparse on-ground citizen science data. We introduce a novel task and dataset for mapping US bird species to their habitats by predicting species encounter rates from satellite images, along with baseline models which demonstrate the power of our approach. Our methods open up possibilities for scalably modelling ecosystems properties worldwide.
Teaching Algorithmic Reasoning via In-context Learning
Nov 15, 2022



Large language models (LLMs) have shown increasing in-context learning capabilities through scaling up model and data size. Despite this progress, LLMs are still unable to solve algorithmic reasoning problems. While providing a rationale with the final answer has led to further improvements in multi-step reasoning problems, Anil et al. 2022 showed that even simple algorithmic reasoning tasks such as parity are far from solved. In this work, we identify and study four key stages for successfully teaching algorithmic reasoning to LLMs: (1) formulating algorithms as skills, (2) teaching multiple skills simultaneously (skill accumulation), (3) teaching how to combine skills (skill composition) and (4) teaching how to use skills as tools. We show that it is possible to teach algorithmic reasoning to LLMs via in-context learning, which we refer to as algorithmic prompting. We evaluate our approach on a variety of arithmetic and quantitative reasoning tasks, and demonstrate significant boosts in performance over existing prompting techniques. In particular, for long parity, addition, multiplication and subtraction, we achieve an error reduction of approximately 10x, 9x, 5x and 2x respectively compared to the best available baselines.
Repository-Level Prompt Generation for Large Language Models of Code
Jun 26, 2022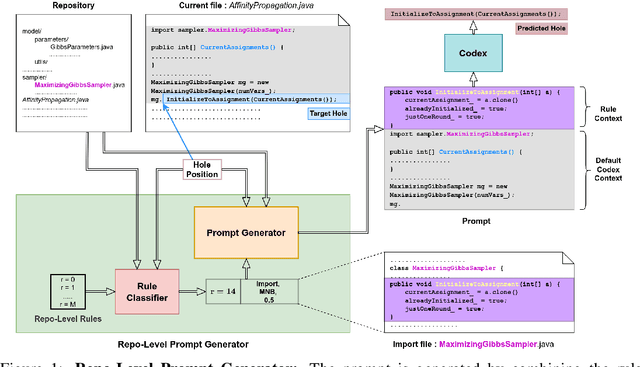
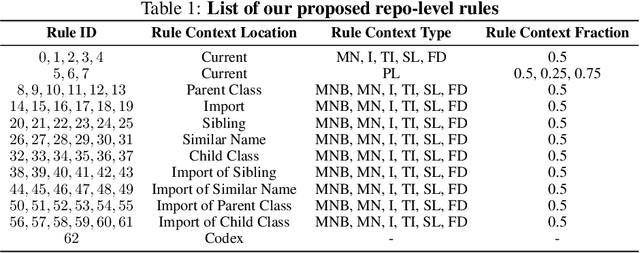

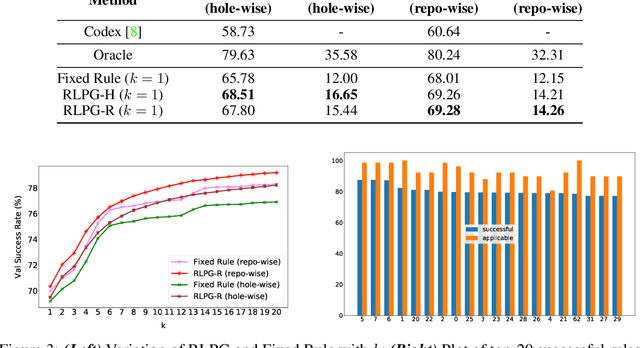
With the success of large language models (LLMs) of code and their use as code assistants (e.g. Codex used in GitHub Copilot), techniques for introducing domain-specific knowledge in the prompt design process become important. In this work, we propose a framework called Repo-Level Prompt Generator that learns to generate example-specific prompts using a set of rules. These rules take context from the entire repository, thereby incorporating both the structure of the repository and the context from other relevant files (e.g. imports, parent class files). Our technique doesn't require any access to the weights of the LLM, making it applicable in cases where we only have black-box access to the LLM. We conduct experiments on the task of single-line code-autocompletion using code repositories taken from Google Code archives. We demonstrate that an oracle constructed from our proposed rules gives up to 36% relative improvement over Codex, showing the quality of the rules. Further, we show that when we train a model to select the best rule, we can achieve significant performance gains over Codex. The code for our work can be found at: https://github.com/shrivastavadisha/repo_level_prompt_generation.
Matching Feature Sets for Few-Shot Image Classification
Apr 02, 2022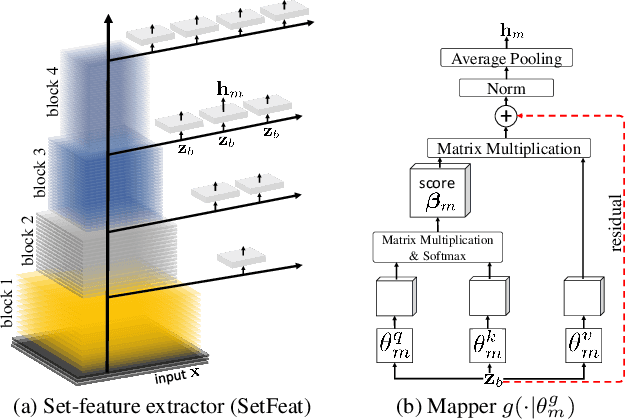
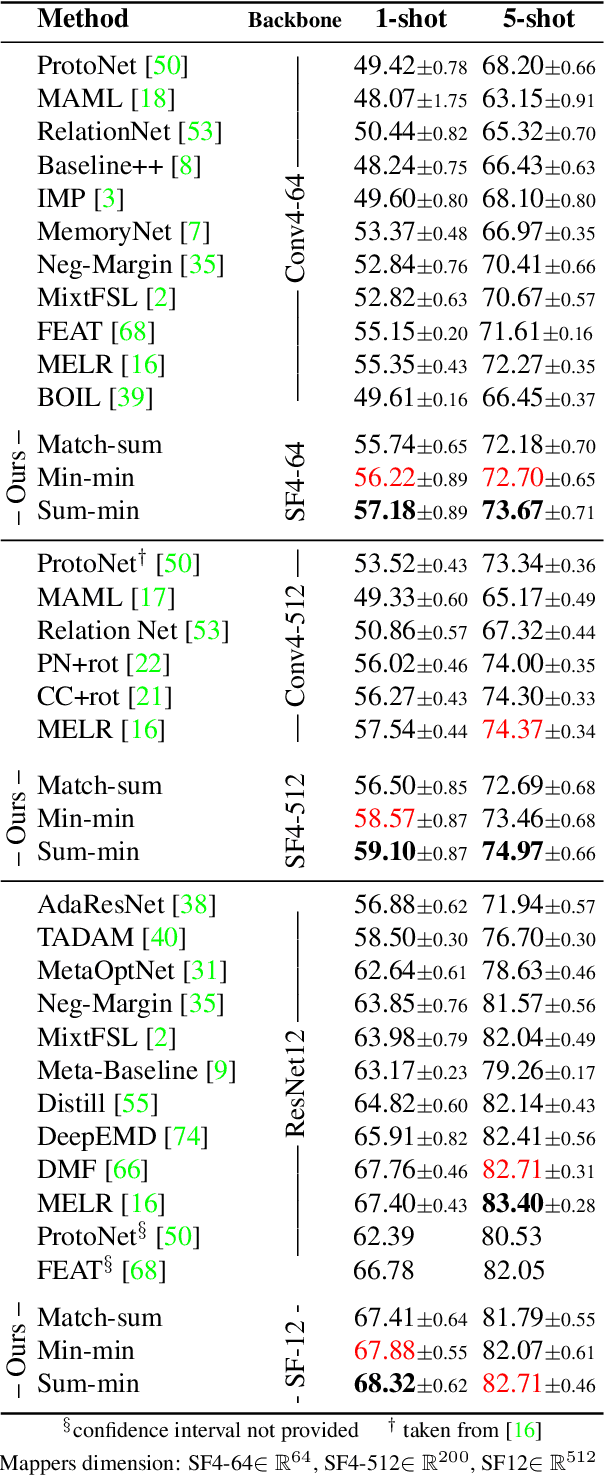
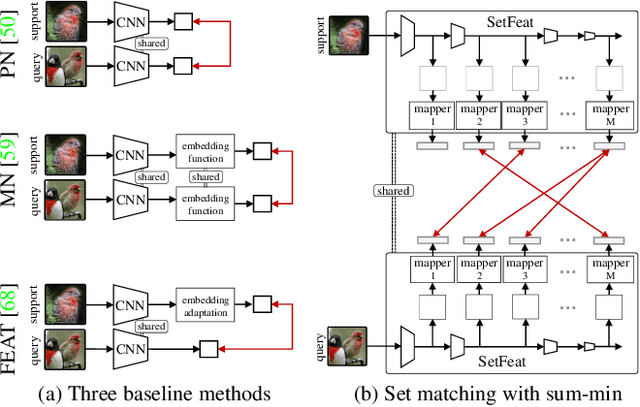
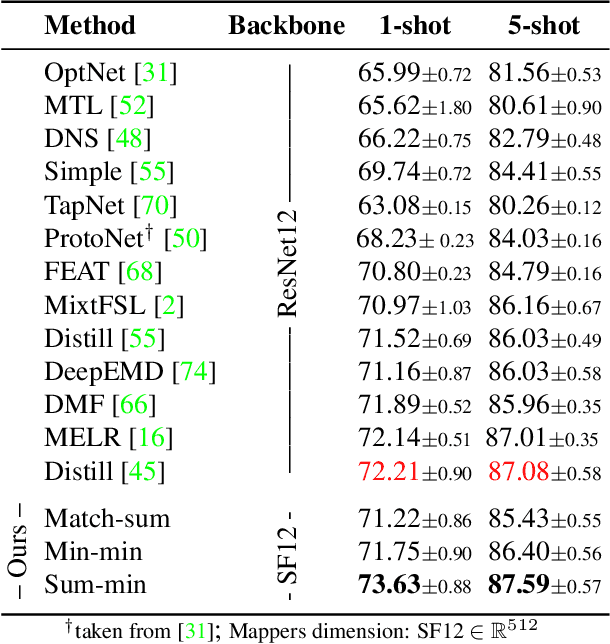
In image classification, it is common practice to train deep networks to extract a single feature vector per input image. Few-shot classification methods also mostly follow this trend. In this work, we depart from this established direction and instead propose to extract sets of feature vectors for each image. We argue that a set-based representation intrinsically builds a richer representation of images from the base classes, which can subsequently better transfer to the few-shot classes. To do so, we propose to adapt existing feature extractors to instead produce sets of feature vectors from images. Our approach, dubbed SetFeat, embeds shallow self-attention mechanisms inside existing encoder architectures. The attention modules are lightweight, and as such our method results in encoders that have approximately the same number of parameters as their original versions. During training and inference, a set-to-set matching metric is used to perform image classification. The effectiveness of our proposed architecture and metrics is demonstrated via thorough experiments on standard few-shot datasets -- namely miniImageNet, tieredImageNet, and CUB -- in both the 1- and 5-shot scenarios. In all cases but one, our method outperforms the state-of-the-art.
Static Prediction of Runtime Errors by Learning to Execute Programs with External Resource Descriptions
Mar 07, 2022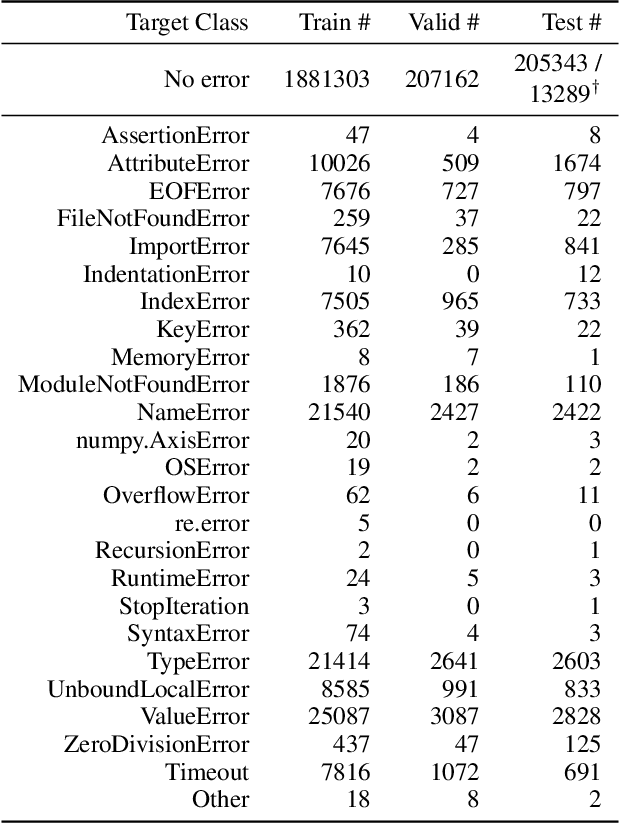

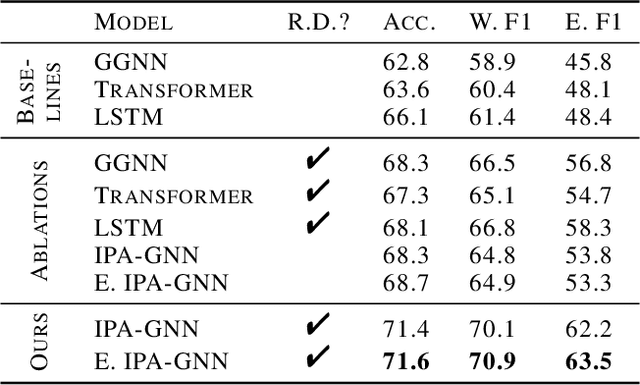
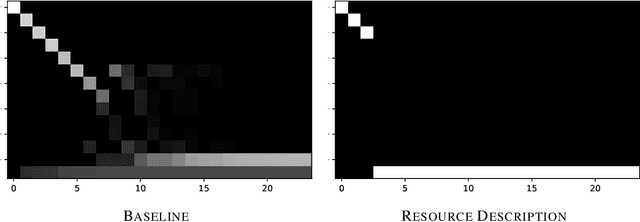
The execution behavior of a program often depends on external resources, such as program inputs or file contents, and so cannot be run in isolation. Nevertheless, software developers benefit from fast iteration loops where automated tools identify errors as early as possible, even before programs can be compiled and run. This presents an interesting machine learning challenge: can we predict runtime errors in a "static" setting, where program execution is not possible? Here, we introduce a real-world dataset and task for predicting runtime errors, which we show is difficult for generic models like Transformers. We approach this task by developing an interpreter-inspired architecture with an inductive bias towards mimicking program executions, which models exception handling and "learns to execute" descriptions of the contents of external resources. Surprisingly, we show that the model can also predict the location of the error, despite being trained only on labels indicating the presence/absence and kind of error. In total, we present a practical and difficult-yet-approachable challenge problem related to learning program execution and we demonstrate promising new capabilities of interpreter-inspired machine learning models for code.
Fortuitous Forgetting in Connectionist Networks
Feb 01, 2022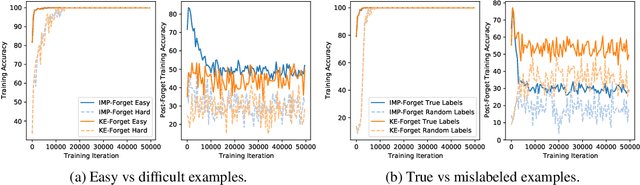
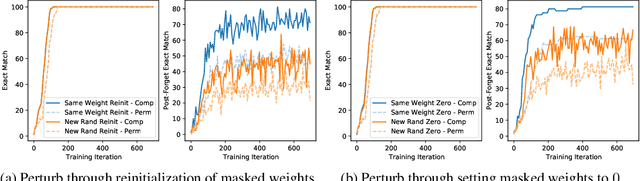
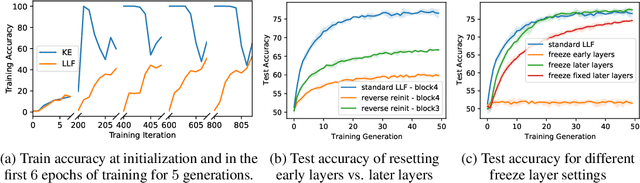
Forgetting is often seen as an unwanted characteristic in both human and machine learning. However, we propose that forgetting can in fact be favorable to learning. We introduce "forget-and-relearn" as a powerful paradigm for shaping the learning trajectories of artificial neural networks. In this process, the forgetting step selectively removes undesirable information from the model, and the relearning step reinforces features that are consistently useful under different conditions. The forget-and-relearn framework unifies many existing iterative training algorithms in the image classification and language emergence literature, and allows us to understand the success of these algorithms in terms of the disproportionate forgetting of undesirable information. We leverage this understanding to improve upon existing algorithms by designing more targeted forgetting operations. Insights from our analysis provide a coherent view on the dynamics of iterative training in neural networks and offer a clear path towards performance improvements.
* ICLR Camera Ready
Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
Jan 10, 2022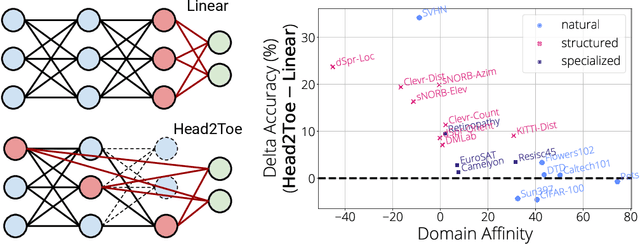
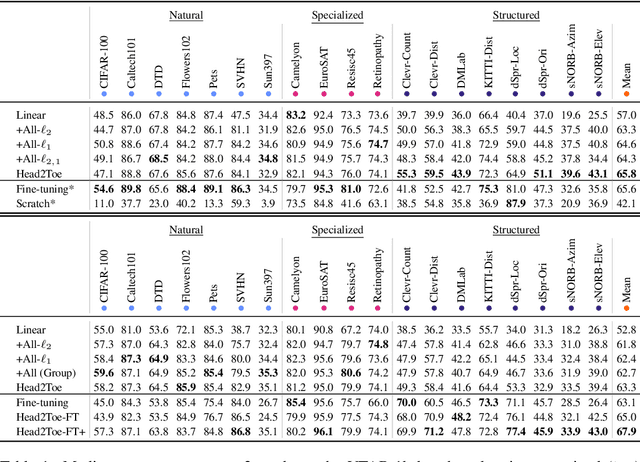
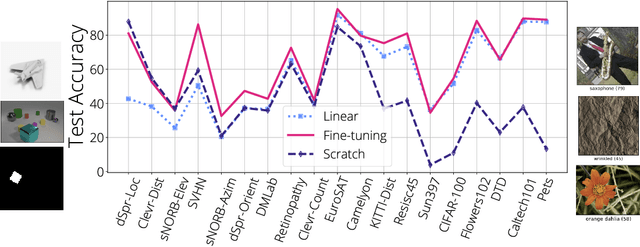
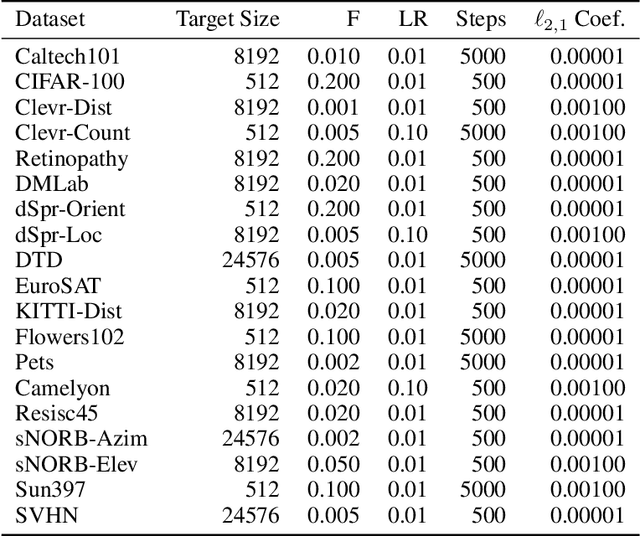
Transfer-learning methods aim to improve performance in a data-scarce target domain using a model pretrained on a data-rich source domain. A cost-efficient strategy, linear probing, involves freezing the source model and training a new classification head for the target domain. This strategy is outperformed by a more costly but state-of-the-art method -- fine-tuning all parameters of the source model to the target domain -- possibly because fine-tuning allows the model to leverage useful information from intermediate layers which is otherwise discarded by the later pretrained layers. We explore the hypothesis that these intermediate layers might be directly exploited. We propose a method, Head-to-Toe probing (Head2Toe), that selects features from all layers of the source model to train a classification head for the target-domain. In evaluations on the VTAB-1k, Head2Toe matches performance obtained with fine-tuning on average while reducing training and storage cost hundred folds or more, but critically, for out-of-distribution transfer, Head2Toe outperforms fine-tuning.
Impact of Aliasing on Generalization in Deep Convolutional Networks
Aug 07, 2021

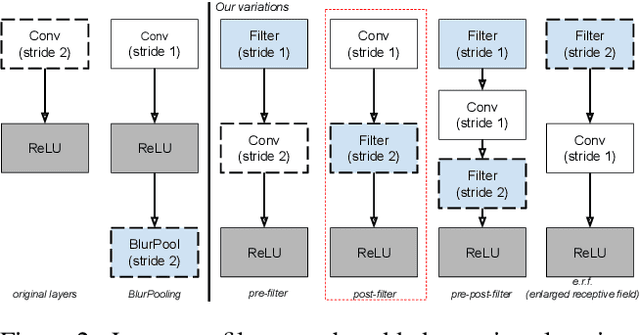
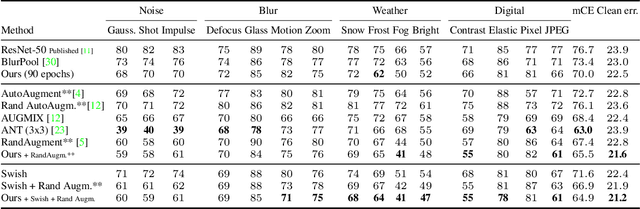
We investigate the impact of aliasing on generalization in Deep Convolutional Networks and show that data augmentation schemes alone are unable to prevent it due to structural limitations in widely used architectures. Drawing insights from frequency analysis theory, we take a closer look at ResNet and EfficientNet architectures and review the trade-off between aliasing and information loss in each of their major components. We show how to mitigate aliasing by inserting non-trainable low-pass filters at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in generalization on i.i.d. and even more on out-of-distribution conditions, such as image classification under natural corruptions on ImageNet-C [11] and few-shot learning on Meta-Dataset [26]. State-of-the art results are achieved on both datasets without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Learning to Combine Per-Example Solutions for Neural Program Synthesis
Jun 14, 2021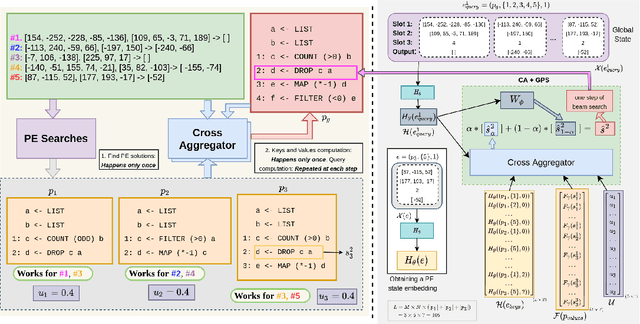

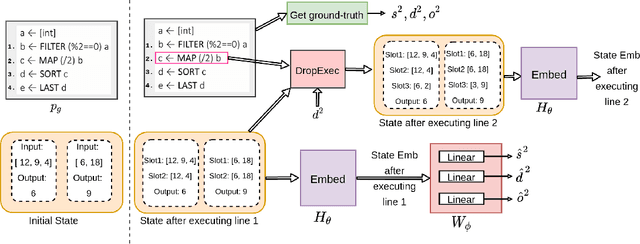
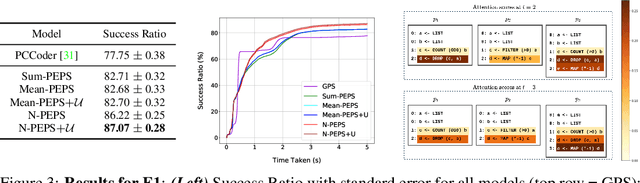
The goal of program synthesis from examples is to find a computer program that is consistent with a given set of input-output examples. Most learning-based approaches try to find a program that satisfies all examples at once. Our work, by contrast, considers an approach that breaks the problem into two stages: (a) find programs that satisfy only one example, and (b) leverage these per-example solutions to yield a program that satisfies all examples. We introduce the Cross Aggregator neural network module based on a multi-head attention mechanism that learns to combine the cues present in these per-example solutions to synthesize a global solution. Evaluation across programs of different lengths and under two different experimental settings reveal that when given the same time budget, our technique significantly improves the success rate over PCCoder arXiv:1809.04682v2 [cs.LG] and other ablation baselines. The code, data and trained models for our work can be found at https://github.com/shrivastavadisha/N-PEPS.
Learning a Universal Template for Few-shot Dataset Generalization
May 14, 2021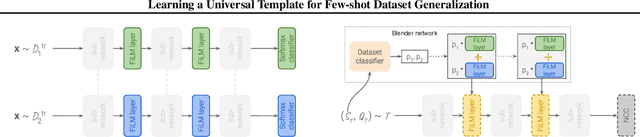
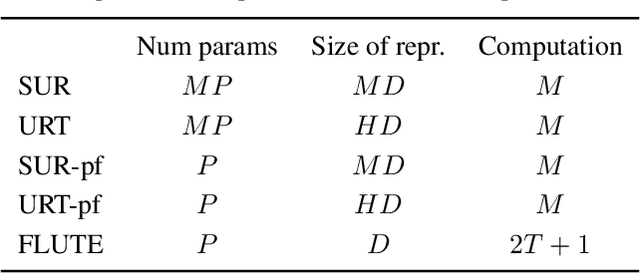
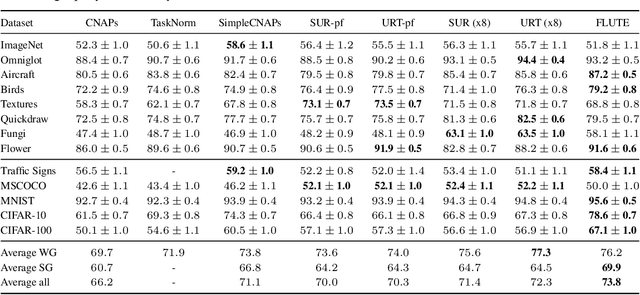

Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from new datasets using only a few examples. To this end, we propose to utilize the diverse training set to construct a universal template: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.