 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification
May 30, 2025In this paper, we leverage the advantages of event cameras to resist harsh lighting conditions, reduce background interference, achieve high time resolution, and protect facial information to study the long-sequence event-based person re-identification (Re-ID) task. To this end, we propose a simple and efficient long-sequence event Re-ID model, namely the Spike-guided Spatiotemporal Semantic Coupling and Expansion Network (S3CE-Net). To better handle asynchronous event data, we build S3CE-Net based on spiking neural networks (SNNs). The S3CE-Net incorporates the Spike-guided Spatial-temporal Attention Mechanism (SSAM) and the Spatiotemporal Feature Sampling Strategy (STFS). The SSAM is designed to carry out semantic interaction and association in both spatial and temporal dimensions, leveraging the capabilities of SNNs. The STFS involves sampling spatial feature subsequences and temporal feature subsequences from the spatiotemporal dimensions, driving the Re-ID model to perceive broader and more robust effective semantics. Notably, the STFS introduces no additional parameters and is only utilized during the training stage. Therefore, S3CE-Net is a low-parameter and high-efficiency model for long-sequence event-based person Re-ID. Extensive experiments have verified that our S3CE-Net achieves outstanding performance on many mainstream long-sequence event-based person Re-ID datasets. Code is available at:https://github.com/Mhsunshine/SC3E_Net.
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
Incomplete Descriptor Mining with Elastic Loss for Person Re-Identification
Aug 17, 2020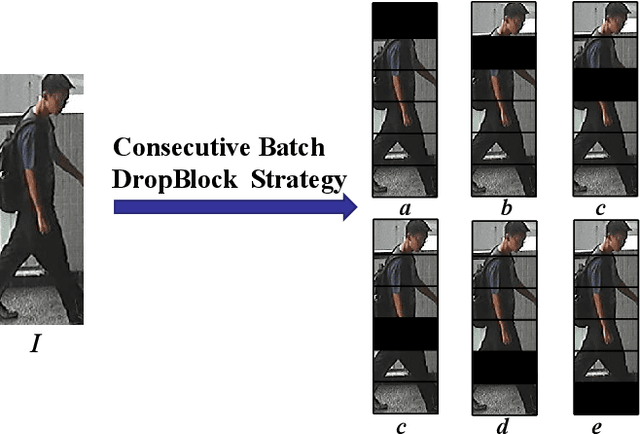
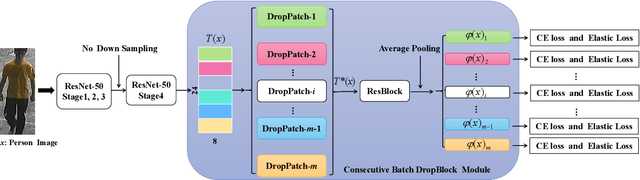
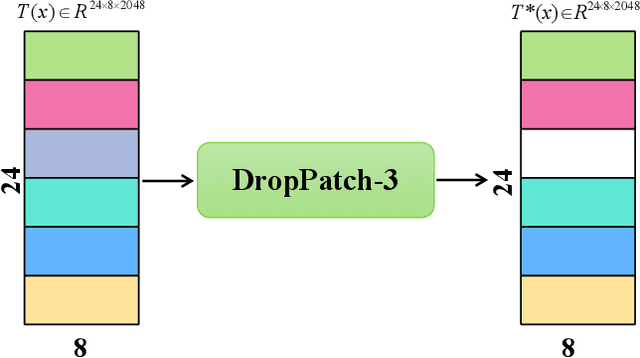
In this paper, we propose a novel person Re-ID model, Consecutive Batch DropBlock Network (CBDB-Net), to help the person Re-ID model to capture the attentive and robust person descriptor. The CBDB-Net contains two novel modules: the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss. In the Consecutive Batch DropBlock Module (CBDBM), it firstly conducts uniform partition on the feature maps. And then, the CBDBM independently and continuously drops each patch from top to bottom on the feature maps, which outputs multiple incomplete features to push the model to capture the robust person descriptor. In the Elastic Loss, we design a novel weight control item to help the deep model adaptively balance hard sample pairs and easy sample pairs in the whole training process. Through an extensive set of ablation studies, we verify that the Consecutive Batch DropBlock Module (CBDBM) and the Elastic Loss each contribute to the performance boosts of CBDB-Net. We demonstrate that our CBDB-Net can achieve the competitive performance on the three generic person Re-ID datasets (the Market-1501, the DukeMTMC-Re-ID, and the CUHK03 dataset), three occlusion Person Re-ID datasets (the Occluded DukeMTMC, the Partial-REID, and the Partial iLIDS dataset), and the other image retrieval dataset (In-Shop Clothes Retrieval dataset).