 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScepsy: Serving Agentic Workflows Using Aggregate LLM Pipelines
Apr 16, 2026Agentic workflows carry out complex tasks by orchestrating multiple large language models (LLMs) and tools. Serving such workflows at a target throughput with low latency is challenging because they can be defined using arbitrary agentic frameworks and exhibit unpredictable execution times: execution may branch, fan-out, or recur in data-dependent ways. Since LLMs in workflows often outnumber available GPUs, their execution also leads to GPU oversubscription. We describe Scepsy, a new agentic serving system that efficiently schedules arbitrary multi-LLM agentic workflows onto a GPU cluster. Scepsy exploits the insight that, while agentic workflows have unpredictable end-to-end latencies, the shares of each LLM's total execution times are comparatively stable across executions. Scepsy decides on GPU allocations based on these aggregate shares: first, it profiles the LLMs under different parallelism degrees. It then uses these statistics to construct an Aggregate LLM Pipeline, which is a lightweight latency/throughput predictor for allocations. To find a GPU allocation that minimizes latency while achieving a target throughput, Scepsy uses the Aggregate LLM Pipeline to explore a search space over fractional GPU shares, tensor parallelism degrees, and replica counts. It uses a hierarchical heuristic to place the best allocation onto the GPU cluster, minimizing fragmentation, while respecting network topology constraints. Our evaluation on realistic agentic workflows shows that Scepsy achieves up to 2.4x higher throughput and 27x lower latency compared to systems that optimize LLMs independently or rely on user-specified allocations.
MSRL: Distributed Reinforcement Learning with Dataflow Fragments
Oct 03, 2022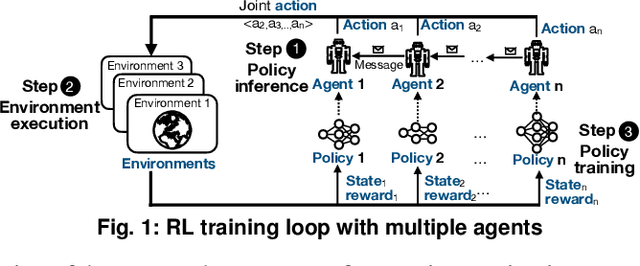
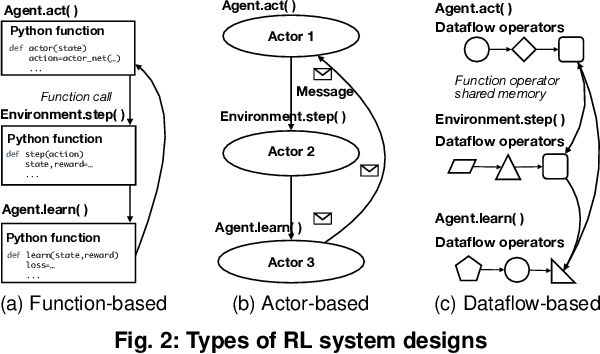
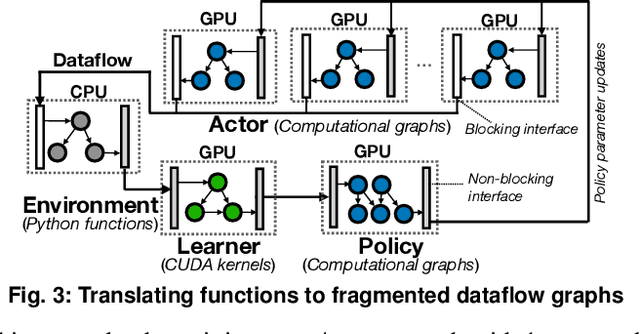
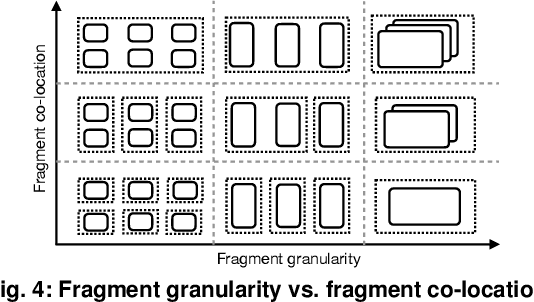
Reinforcement learning~(RL) trains many agents, which is resource-intensive and must scale to large GPU clusters. Different RL training algorithms offer different opportunities for distributing and parallelising the computation. Yet, current distributed RL systems tie the definition of RL algorithms to their distributed execution: they hard-code particular distribution strategies and only accelerate specific parts of the computation (e.g. policy network updates) on GPU workers. Fundamentally, current systems lack abstractions that decouple RL algorithms from their execution. We describe MindSpore Reinforcement Learning (MSRL), a distributed RL training system that supports distribution policies that govern how RL training computation is parallelised and distributed on cluster resources, without requiring changes to the algorithm implementation. MSRL introduces the new abstraction of a fragmented dataflow graph, which maps Python functions from an RL algorithm's training loop to parallel computational fragments. Fragments are executed on different devices by translating them to low-level dataflow representations, e.g. computational graphs as supported by deep learning engines, CUDA implementations or multi-threaded CPU processes. We show that MSRL subsumes the distribution strategies of existing systems, while scaling RL training to 64 GPUs.