 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHUMT: An Open Source Toolkit for Neural Machine Translation
Jun 20, 2017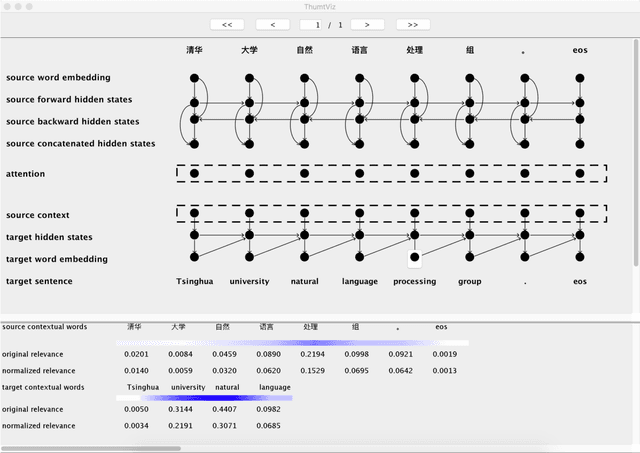
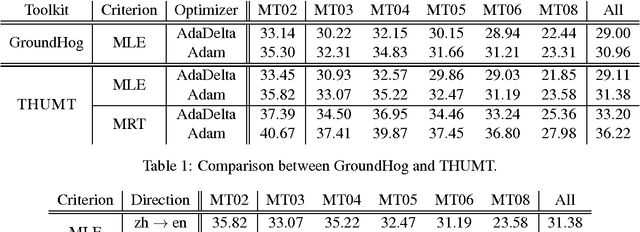
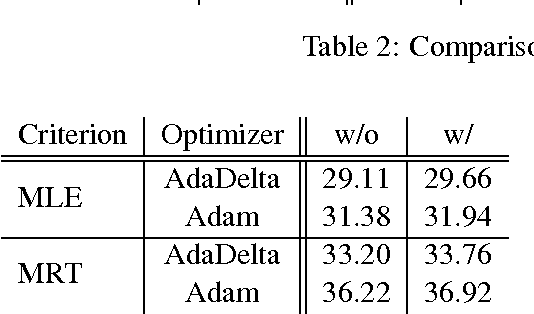
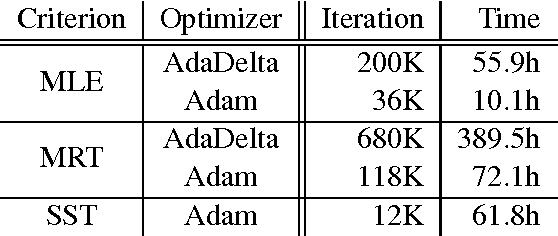
This paper introduces THUMT, an open-source toolkit for neural machine translation (NMT) developed by the Natural Language Processing Group at Tsinghua University. THUMT implements the standard attention-based encoder-decoder framework on top of Theano and supports three training criteria: maximum likelihood estimation, minimum risk training, and semi-supervised training. It features a visualization tool for displaying the relevance between hidden states in neural networks and contextual words, which helps to analyze the internal workings of NMT. Experiments on Chinese-English datasets show that THUMT using minimum risk training significantly outperforms GroundHog, a state-of-the-art toolkit for NMT.
Image-embodied Knowledge Representation Learning
May 22, 2017

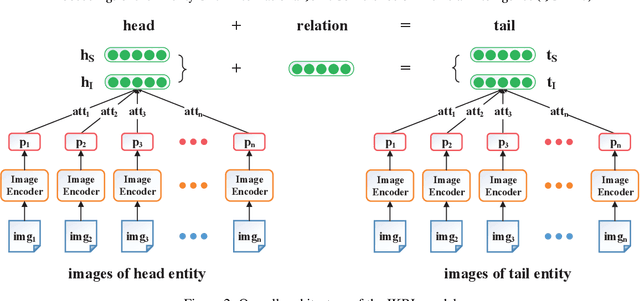
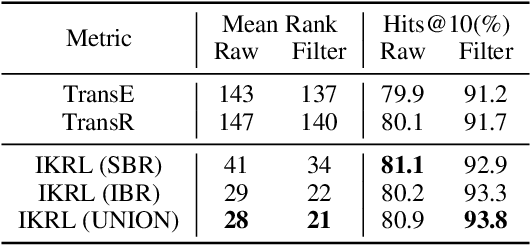
Entity images could provide significant visual information for knowledge representation learning. Most conventional methods learn knowledge representations merely from structured triples, ignoring rich visual information extracted from entity images. In this paper, we propose a novel Image-embodied Knowledge Representation Learning model (IKRL), where knowledge representations are learned with both triple facts and images. More specifically, we first construct representations for all images of an entity with a neural image encoder. These image representations are then integrated into an aggregated image-based representation via an attention-based method. We evaluate our IKRL models on knowledge graph completion and triple classification. Experimental results demonstrate that our models outperform all baselines on both tasks, which indicates the significance of visual information for knowledge representations and the capability of our models in learning knowledge representations with images.
Agreement-based Learning of Parallel Lexicons and Phrases from Non-Parallel Corpora
Jun 15, 2016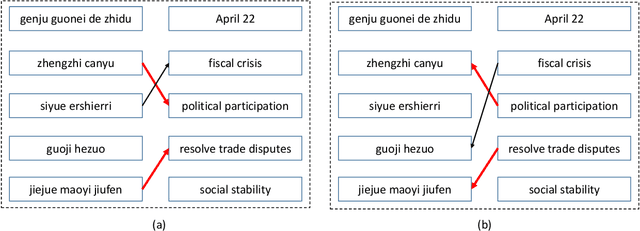
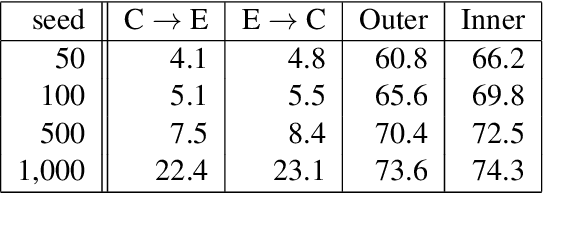
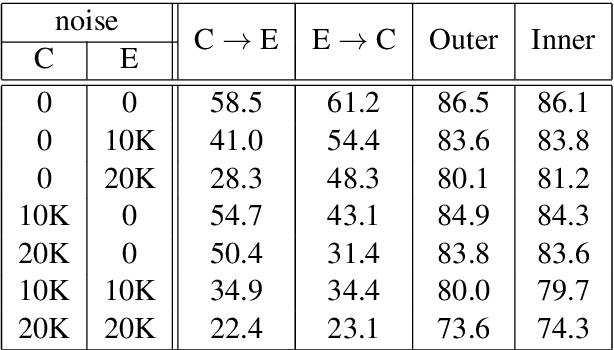
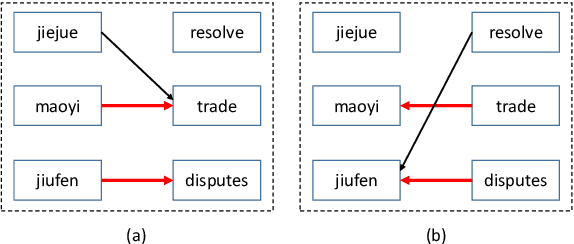
We introduce an agreement-based approach to learning parallel lexicons and phrases from non-parallel corpora. The basic idea is to encourage two asymmetric latent-variable translation models (i.e., source-to-target and target-to-source) to agree on identifying latent phrase and word alignments. The agreement is defined at both word and phrase levels. We develop a Viterbi EM algorithm for jointly training the two unidirectional models efficiently. Experiments on the Chinese-English dataset show that agreement-based learning significantly improves both alignment and translation performance.
Modeling Relation Paths for Representation Learning of Knowledge Bases
Aug 15, 2015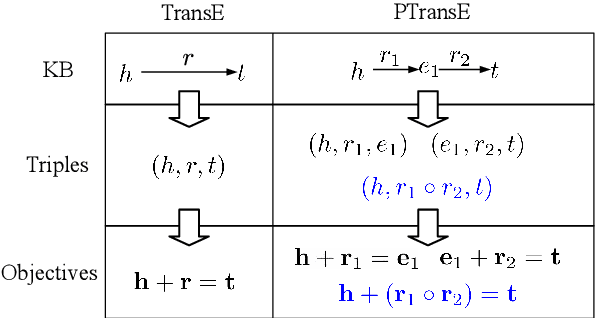

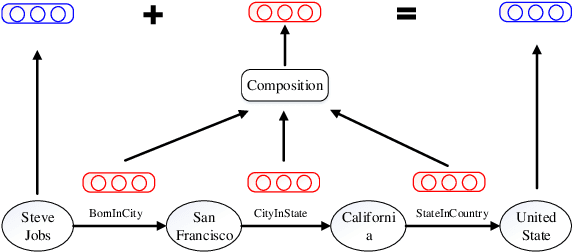
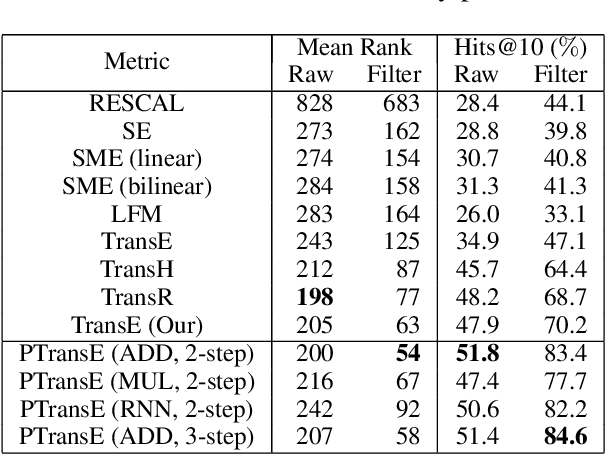
Representation learning of knowledge bases (KBs) aims to embed both entities and relations into a low-dimensional space. Most existing methods only consider direct relations in representation learning. We argue that multiple-step relation paths also contain rich inference patterns between entities, and propose a path-based representation learning model. This model considers relation paths as translations between entities for representation learning, and addresses two key challenges: (1) Since not all relation paths are reliable, we design a path-constraint resource allocation algorithm to measure the reliability of relation paths. (2) We represent relation paths via semantic composition of relation embeddings. Experimental results on real-world datasets show that, as compared with baselines, our model achieves significant and consistent improvements on knowledge base completion and relation extraction from text.