 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Retinomorphic Event Stream for Video Recognition and Reinforcement Learning
May 19, 2018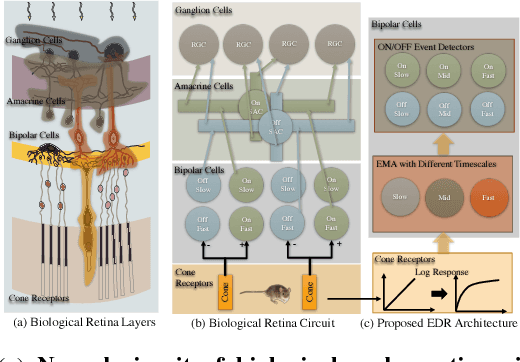
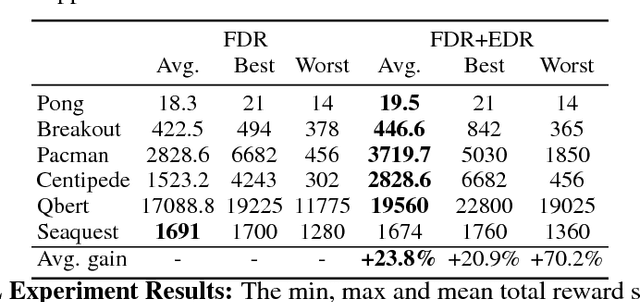
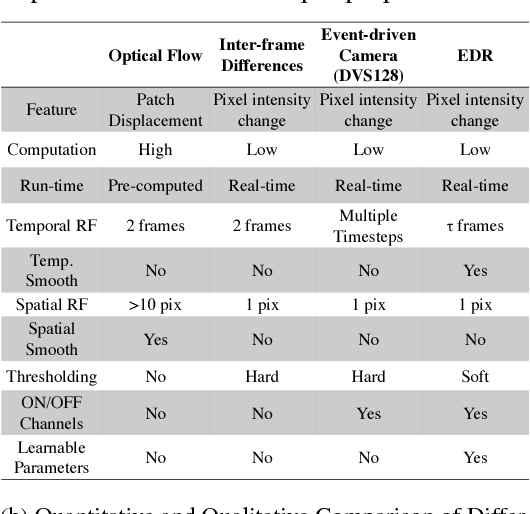
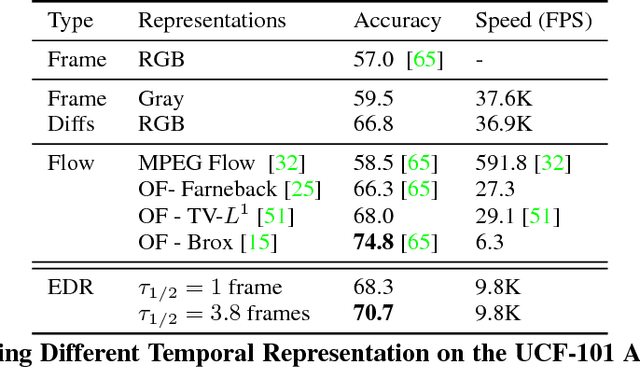
Good temporal representations are crucial for video understanding, and the state-of-the-art video recognition framework is based on two-stream networks. In such framework, besides the regular ConvNets responsible for RGB frame inputs, a second network is introduced to handle the temporal representation, usually the optical flow (OF). However, OF or other task-oriented flow is computationally costly, and is thus typically pre-computed. Critically, this prevents the two-stream approach from being applied to reinforcement learning (RL) applications such as video game playing, where the next state depends on current state and action choices. Inspired by the early vision systems of mammals and insects, we propose a fast event-driven representation (EDR) that models several major properties of early retinal circuits: (1) logarithmic input response, (2) multi-timescale temporal smoothing to filter noise, and (3) bipolar (ON/OFF) pathways for primitive event detection[12]. Trading off the directional information for fast speed (> 9000 fps), EDR en-ables fast real-time inference/learning in video applications that require interaction between an agent and the world such as game-playing, virtual robotics, and domain adaptation. In this vein, we use EDR to demonstrate performance improvements over state-of-the-art reinforcement learning algorithms for Atari games, something that has not been possible with pre-computed OF. Moreover, with UCF-101 video action recognition experiments, we show that EDR performs near state-of-the-art in accuracy while achieving a 1,500x speedup in input representation processing, as compared to optical flow.
Reblur2Deblur: Deblurring Videos via Self-Supervised Learning
Jan 16, 2018
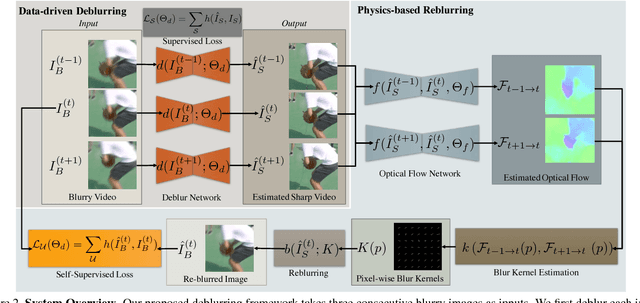

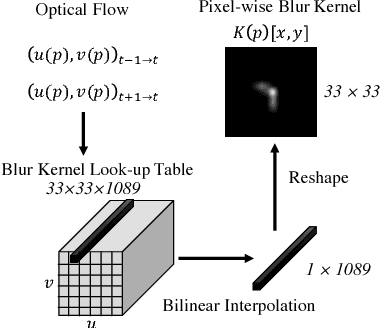
Motion blur is a fundamental problem in computer vision as it impacts image quality and hinders inference. Traditional deblurring algorithms leverage the physics of the image formation model and use hand-crafted priors: they usually produce results that better reflect the underlying scene, but present artifacts. Recent learning-based methods implicitly extract the distribution of natural images directly from the data and use it to synthesize plausible images. Their results are impressive, but they are not always faithful to the content of the latent image. We present an approach that bridges the two. Our method fine-tunes existing deblurring neural networks in a self-supervised fashion by enforcing that the output, when blurred based on the optical flow between subsequent frames, matches the input blurry image. We show that our method significantly improves the performance of existing methods on several datasets both visually and in terms of image quality metrics. The supplementary material is https://goo.gl/nYPjEQ
Online Reweighted Least Squares Algorithm for Sparse Recovery and Application to Short-Wave Infrared Imaging
Jun 29, 2017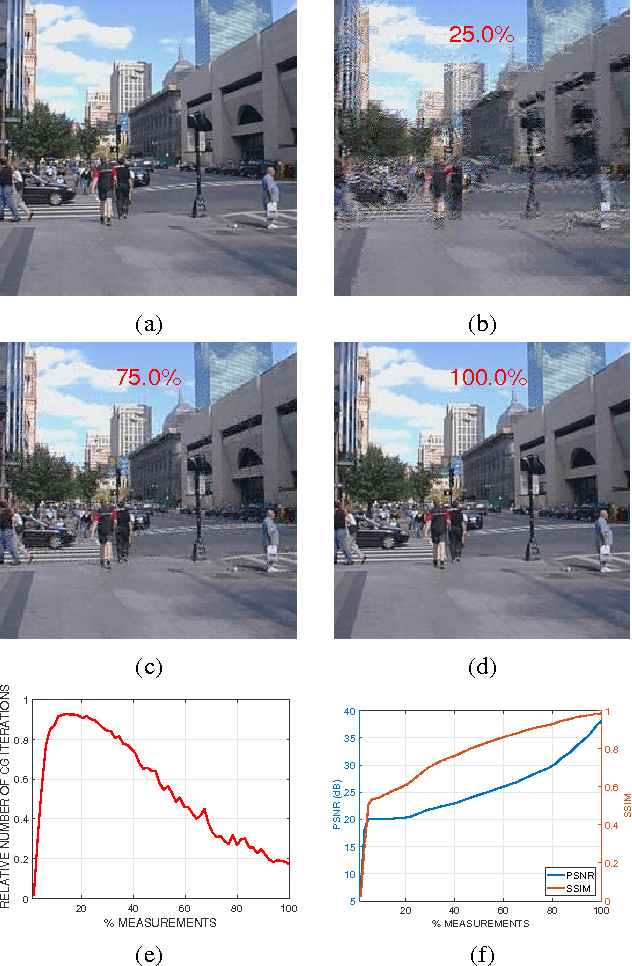
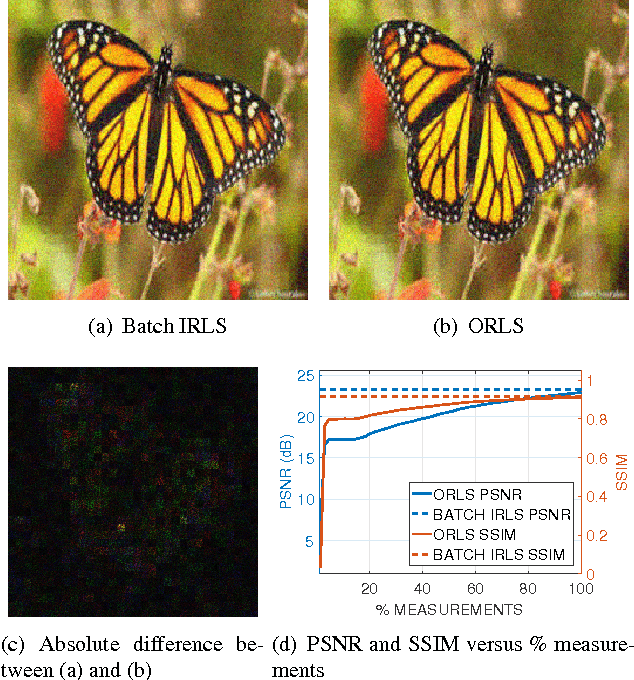

We address the problem of sparse recovery in an online setting, where random linear measurements of a sparse signal are revealed sequentially and the objective is to recover the underlying signal. We propose a reweighted least squares (RLS) algorithm to solve the problem of online sparse reconstruction, wherein a system of linear equations is solved using conjugate gradient with the arrival of every new measurement. The proposed online algorithm is useful in a setting where one seeks to design a progressive decoding strategy to reconstruct a sparse signal from linear measurements so that one does not have to wait until all measurements are acquired. Moreover, the proposed algorithm is also useful in applications where it is infeasible to process all the measurements using a batch algorithm, owing to computational and storage constraints. It is not needed a priori to collect a fixed number of measurements; rather one can keep collecting measurements until the quality of reconstruction is satisfactory and stop taking further measurements once the reconstruction is sufficiently accurate. We provide a proof-of-concept by comparing the performance of our algorithm with the RLS-based batch reconstruction strategy, known as iteratively reweighted least squares (IRLS), on natural images. Experiments on a recently proposed focal plane array-based imaging setup show up to 1 dB improvement in output peak signal-to-noise ratio as compared with the total variation-based reconstruction.
ASP Vision: Optically Computing the First Layer of Convolutional Neural Networks using Angle Sensitive Pixels
Nov 16, 2016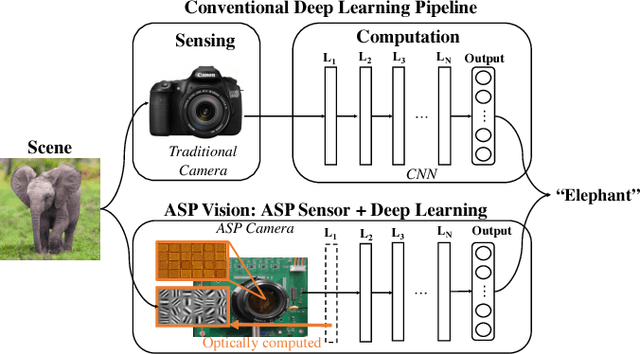
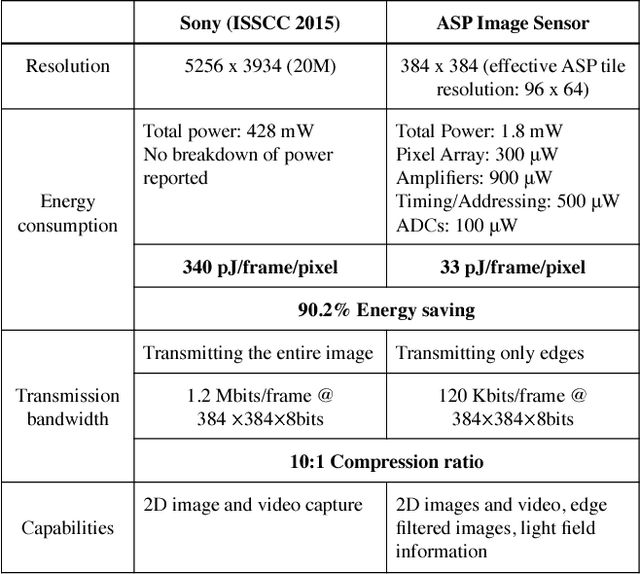

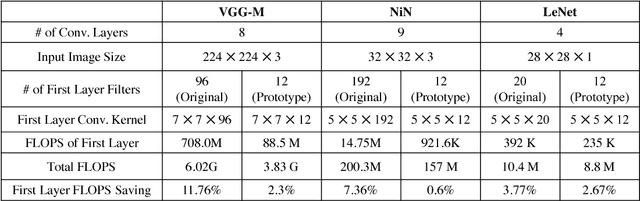
Deep learning using convolutional neural networks (CNNs) is quickly becoming the state-of-the-art for challenging computer vision applications. However, deep learning's power consumption and bandwidth requirements currently limit its application in embedded and mobile systems with tight energy budgets. In this paper, we explore the energy savings of optically computing the first layer of CNNs. To do so, we utilize bio-inspired Angle Sensitive Pixels (ASPs), custom CMOS diffractive image sensors which act similar to Gabor filter banks in the V1 layer of the human visual cortex. ASPs replace both image sensing and the first layer of a conventional CNN by directly performing optical edge filtering, saving sensing energy, data bandwidth, and CNN FLOPS to compute. Our experimental results (both on synthetic data and a hardware prototype) for a variety of vision tasks such as digit recognition, object recognition, and face identification demonstrate using ASPs while achieving similar performance compared to traditional deep learning pipelines.
Compressive Holographic Video
Oct 27, 2016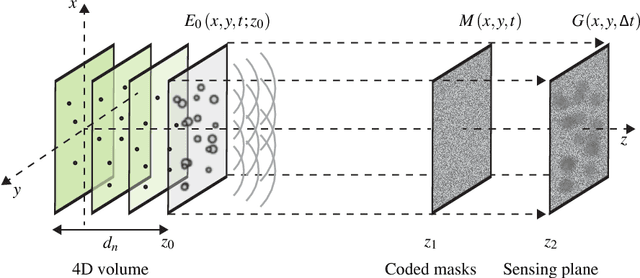
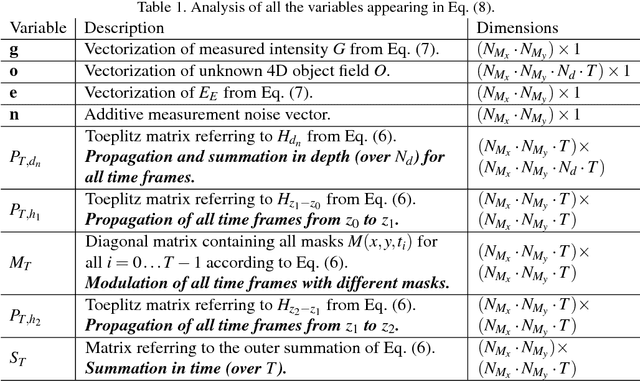
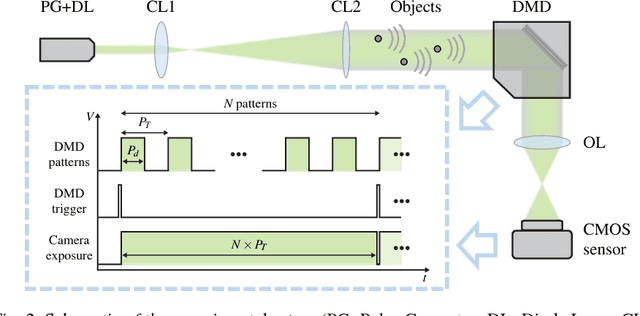
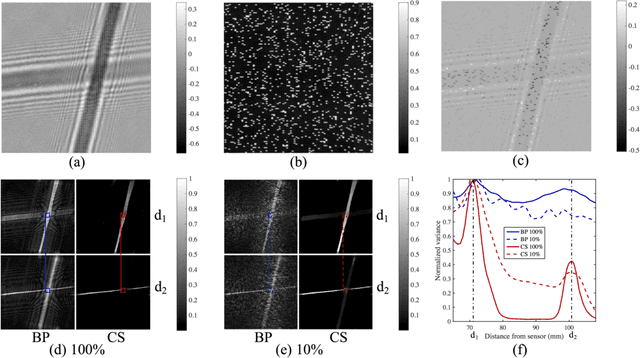
Compressed sensing has been discussed separately in spatial and temporal domains. Compressive holography has been introduced as a method that allows 3D tomographic reconstruction at different depths from a single 2D image. Coded exposure is a temporal compressed sensing method for high speed video acquisition. In this work, we combine compressive holography and coded exposure techniques and extend the discussion to 4D reconstruction in space and time from one coded captured image. In our prototype, digital in-line holography was used for imaging macroscopic, fast moving objects. The pixel-wise temporal modulation was implemented by a digital micromirror device. In this paper we demonstrate $10\times$ temporal super resolution with multiple depths recovery from a single image. Two examples are presented for the purpose of recording subtle vibrations and tracking small particles within 5 ms.
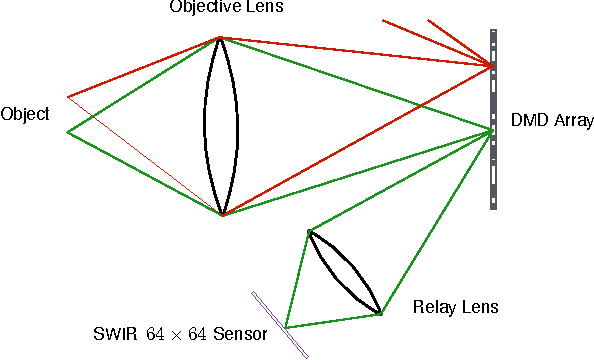
FPA-CS: Focal Plane Array-based Compressive Imaging in Short-wave Infrared
Apr 16, 2015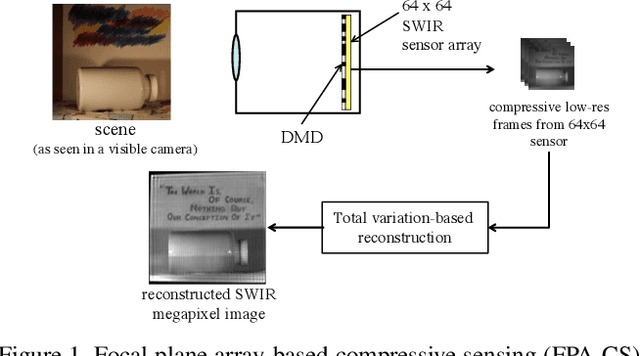
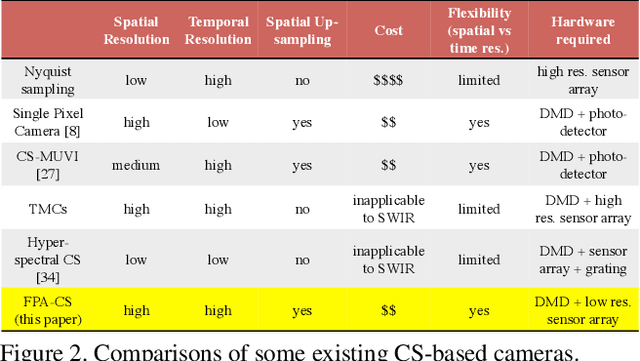
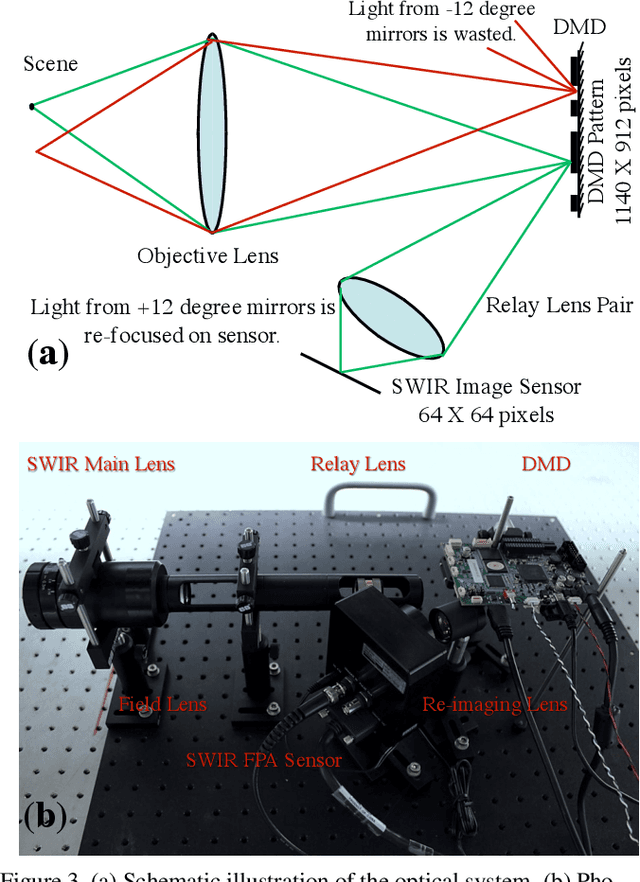
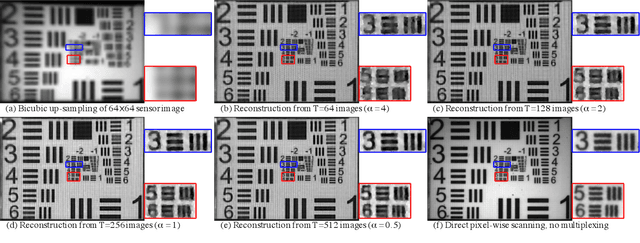
Cameras for imaging in short and mid-wave infrared spectra are significantly more expensive than their counterparts in visible imaging. As a result, high-resolution imaging in those spectrum remains beyond the reach of most consumers. Over the last decade, compressive sensing (CS) has emerged as a potential means to realize inexpensive short-wave infrared cameras. One approach for doing this is the single-pixel camera (SPC) where a single detector acquires coded measurements of a high-resolution image. A computational reconstruction algorithm is then used to recover the image from these coded measurements. Unfortunately, the measurement rate of a SPC is insufficient to enable imaging at high spatial and temporal resolutions. We present a focal plane array-based compressive sensing (FPA-CS) architecture that achieves high spatial and temporal resolutions. The idea is to use an array of SPCs that sense in parallel to increase the measurement rate, and consequently, the achievable spatio-temporal resolution of the camera. We develop a proof-of-concept prototype in the short-wave infrared using a sensor with 64$\times$ 64 pixels; the prototype provides a 4096$\times$ increase in the measurement rate compared to the SPC and achieves a megapixel resolution at video rate using CS techniques.