 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning
Nov 04, 2019
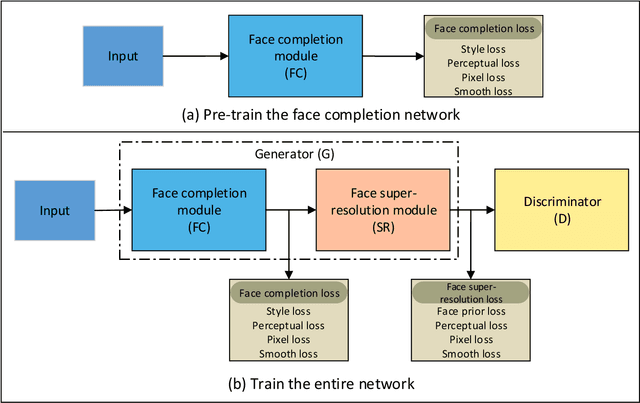
Combined variations containing low-resolution and occlusion often present in face images in the wild, e.g., under the scenario of video surveillance. While most of the existing face image recovery approaches can handle only one type of variation per model, in this work, we propose a deep generative adversarial network (FCSR-GAN) for performing joint face completion and face super-resolution via multi-task learning. The generator of FCSR-GAN aims to recover a high-resolution face image without occlusion given an input low-resolution face image with occlusion. The discriminator of FCSR-GAN uses a set of carefully designed losses (an adversarial loss, a perceptual loss, a pixel loss, a smooth loss, a style loss, and a face prior loss) to assure the high quality of the recovered high-resolution face images without occlusion. The whole network of FCSR-GAN can be trained end-to-end using our two-stage training strategy. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms the state-of-the-art methods in jointly performing face super-resolution (up to 8 $\times$) and face completion, and shows good generalization ability in cross-database testing. Our FCSR-GAN is also useful for improving face identification performance when there are low-resolution and occlusion in face images.
RhythmNet: End-to-end Heart Rate Estimation from Face via Spatial-temporal Representation
Nov 04, 2019
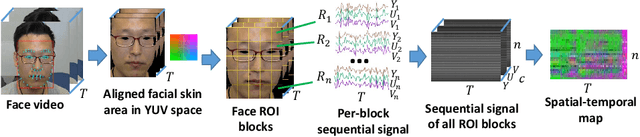
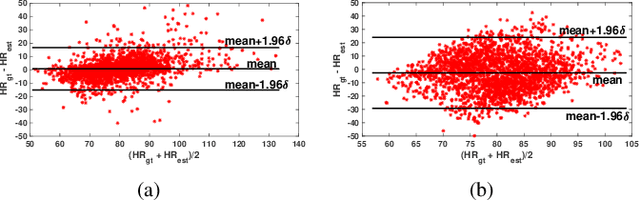
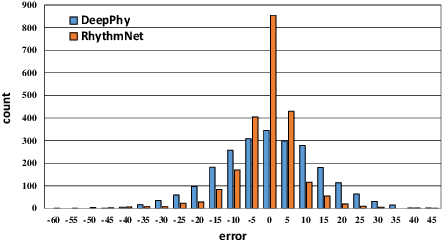
Heart rate (HR) is an important physiological signal that reflects the physical and emotional status of a person. Traditional HR measurements usually rely on contact monitors, which may cause inconvenience and discomfort. Recently, some methods have been proposed for remote HR estimation from face videos; however, most of them focus on well-controlled scenarios, their generalization ability into less-constrained scenarios (e.g., with head movement, and bad illumination) are not known. At the same time, lacking large-scale HR databases has limited the use of deep models for remote HR estimation. In this paper, we propose an end-to-end RhythmNet for remote HR estimation from the face. In RyhthmNet, we use a spatial-temporal representation encoding the HR signals from multiple ROI volumes as its input. Then the spatial-temporal representations are fed into a convolutional network for HR estimation. We also take into account the relationship of adjacent HR measurements from a video sequence via Gated Recurrent Unit (GRU) and achieves efficient HR measurement. In addition, we build a large-scale multi-modal HR database (named as VIPL-HR, available at 'http://vipl.ict.ac.cn/view_database.php?id=15'), which contains 2,378 visible light videos (VIS) and 752 near-infrared (NIR) videos of 107 subjects. Our VIPL-HR database contains various variations such as head movements, illumination variations, and acquisition device changes, replicating a less-constrained scenario for HR estimation. The proposed approach outperforms the state-of-the-art methods on both the public-domain and our VIPL-HR databases.
Multi-label Co-regularization for Semi-supervised Facial Action Unit Recognition
Oct 24, 2019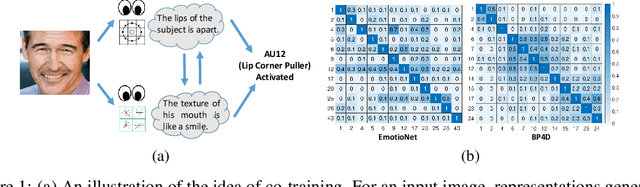
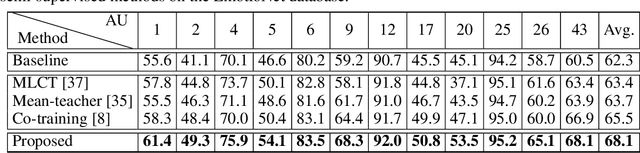
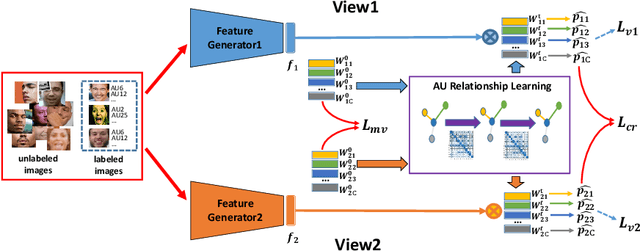
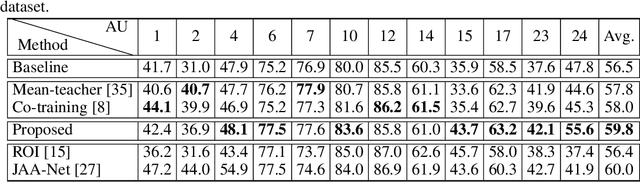
Facial action units (AUs) recognition is essential for emotion analysis and has been widely applied in mental state analysis. Existing work on AU recognition usually requires big face dataset with AU labels; however, manual AU annotation requires expertise and can be time-consuming. In this work, we propose a semi-supervised approach for AU recognition utilizing a large number of web face images without AU labels and a relatively small face dataset with AU annotations inspired by the co-training methods. Unlike traditional co-training methods that require provided multi-view features and model re-training, we propose a novel co-training method, namely multi-label co-regularization, for semi-supervised facial AU recognition. Two deep neural networks are utilized to generate multi-view features for both labeled and unlabeled face images, and a multi-view loss is designed to enforce the two feature generators to get conditional independent representations. In order to constrain the prediction consistency of the two views, we further propose a multi-label co-regularization loss by minimizing the distance of the predicted AU probability distributions of two views. In addition, prior knowledge of the relationship between individual AUs is embedded through a graph convolutional network (GCN) for exploiting useful information from the big unlabeled dataset. Experiments on several benchmarks show that the proposed approach can effectively leverage large datasets of face images without AU labels to improve the AU recognition accuracy and outperform the state-of-the-art semi-supervised AU recognition methods.
Encoding CT Anatomy Knowledge for Unpaired Chest X-ray Image Decomposition
Sep 16, 2019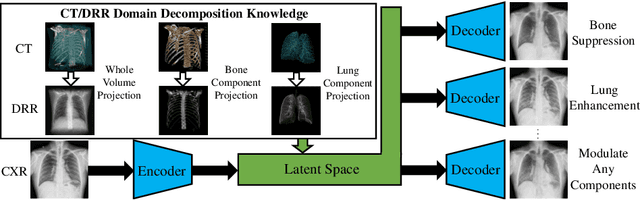
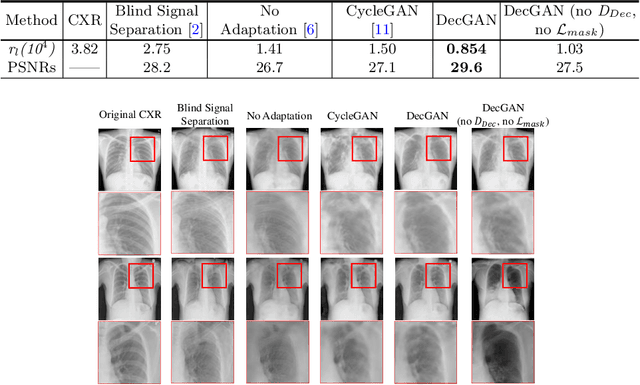
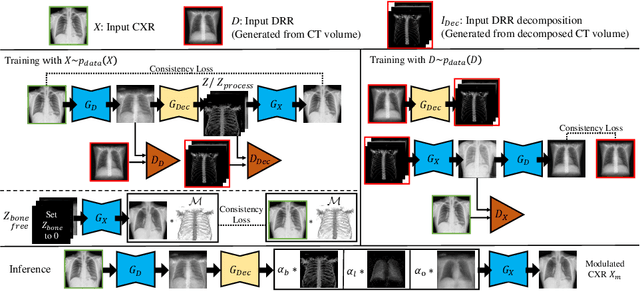
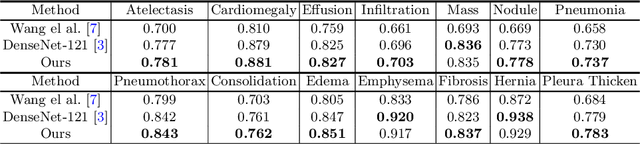
Although chest X-ray (CXR) offers a 2D projection with overlapped anatomies, it is widely used for clinical diagnosis. There is clinical evidence supporting that decomposing an X-ray image into different components (e.g., bone, lung and soft tissue) improves diagnostic value. We hereby propose a decomposition generative adversarial network (DecGAN) to anatomically decompose a CXR image but with unpaired data. We leverage the anatomy knowledge embedded in CT, which features a 3D volume with clearly visible anatomies. Our key idea is to embed CT priori decomposition knowledge into the latent space of unpaired CXR autoencoder. Specifically, we train DecGAN with a decomposition loss, adversarial losses, cycle-consistency losses and a mask loss to guarantee that the decomposed results of the latent space preserve realistic body structures. Extensive experiments demonstrate that DecGAN provides superior unsupervised CXR bone suppression results and the feasibility of modulating CXR components by latent space disentanglement. Furthermore, we illustrate the diagnostic value of DecGAN and demonstrate that it outperforms the state-of-the-art approaches in terms of predicting 11 out of 14 common lung diseases.
3D U$^2$-Net: A 3D Universal U-Net for Multi-Domain Medical Image Segmentation
Sep 04, 2019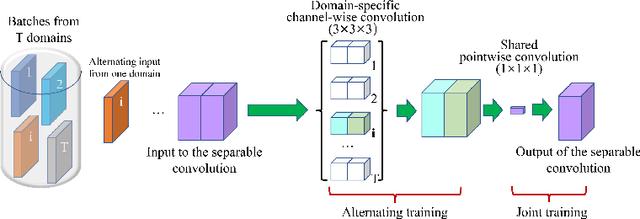

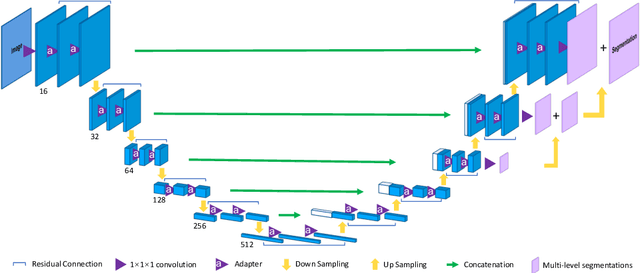
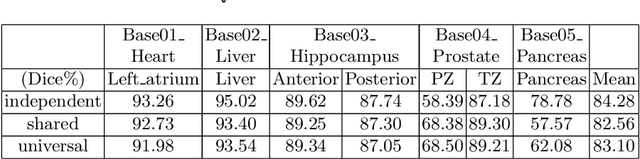
Fully convolutional neural networks like U-Net have been the state-of-the-art methods in medical image segmentation. Practically, a network is highly specialized and trained separately for each segmentation task. Instead of a collection of multiple models, it is highly desirable to learn a universal data representation for different tasks, ideally a single model with the addition of a minimal number of parameters steered to each task. Inspired by the recent success of multi-domain learning in image classification, for the first time we explore a promising universal architecture that handles multiple medical segmentation tasks and is extendable for new tasks, regardless of different organs and imaging modalities. Our 3D Universal U-Net (3D U$^2$-Net) is built upon separable convolution, assuming that {\it images from different domains have domain-specific spatial correlations which can be probed with channel-wise convolution while also share cross-channel correlations which can be modeled with pointwise convolution}. We evaluate the 3D U$^2$-Net on five organ segmentation datasets. Experimental results show that this universal network is capable of competing with traditional models in terms of segmentation accuracy, while requiring only about $1\%$ of the parameters. Additionally, we observe that the architecture can be easily and effectively adapted to a new domain without sacrificing performance in the domains used to learn the shared parameterization of the universal network. We put the code of 3D U$^2$-Net into public domain. \url{https://github.com/huangmozhilv/u2net_torch/}
Tattoo Image Search at Scale: Joint Detection and Compact Representation Learning
Nov 01, 2018
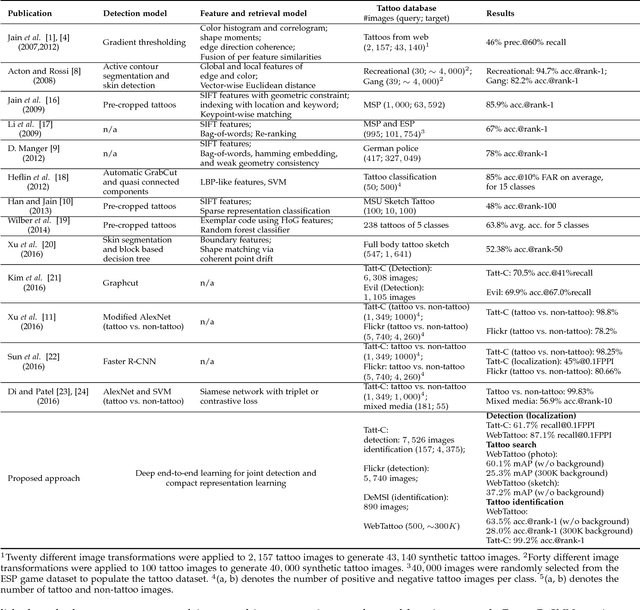

The explosive growth of digital images in video surveillance and social media has led to the significant need for efficient search of persons of interest in law enforcement and forensic applications. Despite tremendous progress in primary biometric traits (e.g., face and fingerprint) based person identification, a single biometric trait alone cannot meet the desired recognition accuracy in forensic scenarios. Tattoos, as one of the important soft biometric traits, have been found to be valuable for assisting in person identification. However, tattoo search in a large collection of unconstrained images remains a difficult problem, and existing tattoo search methods mainly focus on matching cropped tattoos, which is different from real application scenarios. To close the gap, we propose an efficient tattoo search approach that is able to learn tattoo detection and compact representation jointly in a single convolutional neural network (CNN) via multi-task learning. While the features in the backbone network are shared by both tattoo detection and compact representation learning, individual latent layers of each sub-network optimize the shared features toward the detection and feature learning tasks, respectively. We resolve the small batch size issue inside the joint tattoo detection and compact representation learning network via random image stitch and preceding feature buffering. We evaluate the proposed tattoo search system using multiple public-domain tattoo benchmarks, and a gallery set with about 300K distracter tattoo images compiled from these datasets and images from the Internet. In addition, we also introduce a tattoo sketch dataset containing 300 tattoos for sketch-based tattoo search. Experimental results show that the proposed approach has superior performance in tattoo detection and tattoo search at scale compared to several state-of-the-art tattoo retrieval algorithms.
VIPL-HR: A Multi-modal Database for Pulse Estimation from Less-constrained Face Video
Oct 11, 2018

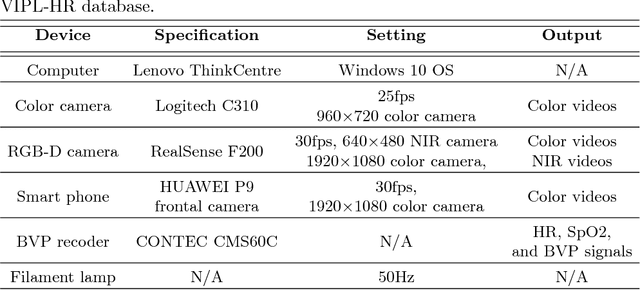
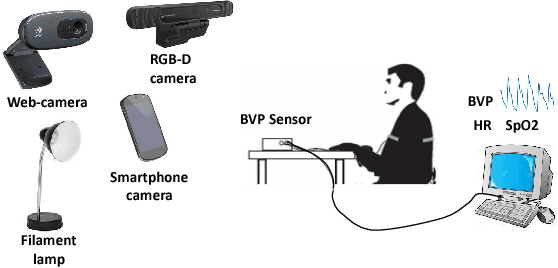
Heart rate (HR) is an important physiological signal that reflects the physical and emotional activities of humans. Traditional HR measurements are mainly based on contact monitors, which are inconvenient and may cause discomfort for the subjects. Recently, methods have been proposed for remote HR estimation from face videos. However, most of the existing methods focus on well-controlled scenarios, their generalization ability into less-constrained scenarios are not known. At the same time, lacking large-scale databases has limited the use of deep representation learning methods in remote HR estimation. In this paper, we introduce a large-scale multi-modal HR database (named as VIPL-HR), which contains 2,451 visible light videos (VIS) and 752 near-infrared (NIR) videos of 107 subjects. Our VIPL-HR database also contains various variations such as head movements, illumination variations, and acquisition device changes. We also learn a deep HR estimator (named as RhythmNet) with the proposed spatial-temporal representation, which achieves promising results on both the public-domain and our VIPL-HR HR estimation databases. We would like to put the VIPL-HR database into the public domain.
Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach
Sep 28, 2017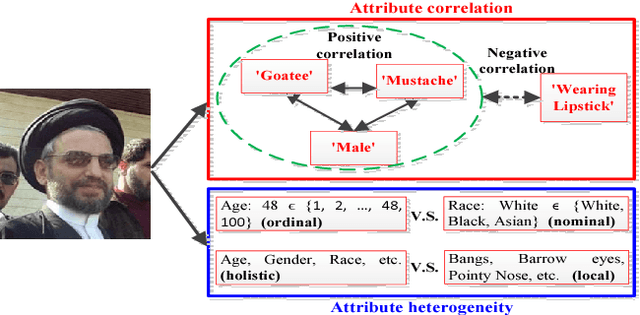
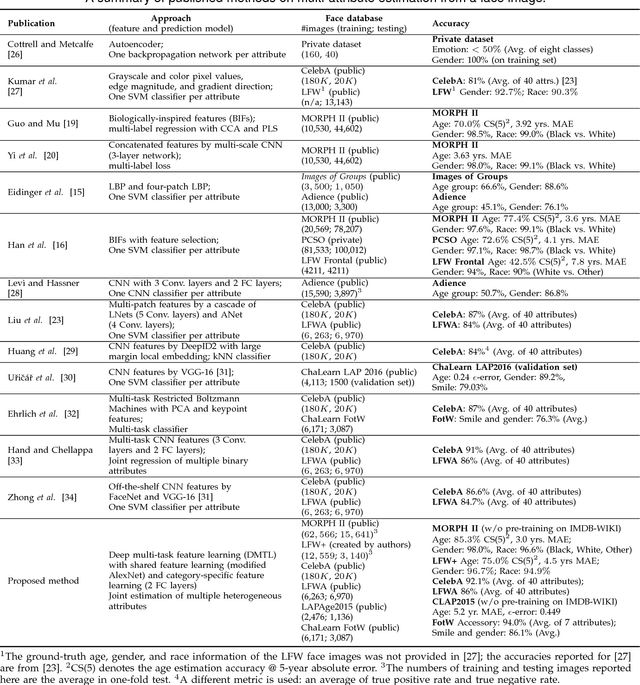
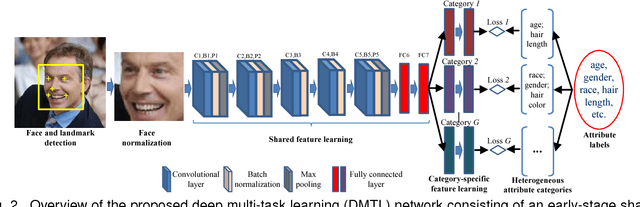
Face attribute estimation has many potential applications in video surveillance, face retrieval, and social media. While a number of methods have been proposed for face attribute estimation, most of them did not explicitly consider the attribute correlation and heterogeneity (e.g., ordinal vs. nominal and holistic vs. local) during feature representation learning. In this paper, we present a Deep Multi-Task Learning (DMTL) approach to jointly estimate multiple heterogeneous attributes from a single face image. In DMTL, we tackle attribute correlation and heterogeneity with convolutional neural networks (CNNs) consisting of shared feature learning for all the attributes, and category-specific feature learning for heterogeneous attributes. We also introduce an unconstrained face database (LFW+), an extension of public-domain LFW, with heterogeneous demographic attributes (age, gender, and race) obtained via crowdsourcing. Experimental results on benchmarks with multiple face attributes (MORPH II, LFW+, CelebA, LFWA, and FotW) show that the proposed approach has superior performance compared to state of the art. Finally, evaluations on a public-domain face database (LAP) with a single attribute show that the proposed approach has excellent generalization ability.