 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPIRin: Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models
Apr 11, 2026End-to-end full-duplex Speech Language Models (SLMs) require precise turn-taking for natural interaction. However, optimizing temporal dynamics via standard raw-token reinforcement learning (RL) degrades semantic quality, causing severe generative collapse and repetition. We propose ASPIRin, an interactivity-optimized RL framework that explicitly decouples when to speak from what to say. Using Action Space Projection, ASPIRin maps the text vocabulary into a coarse-grained binary state (active speech vs. inactive silence). By applying Group Relative Policy Optimization (GRPO) with rule-based rewards, it balances user interruption and response latency. Empirical evaluations show ASPIRin optimizes interactivity across turn-taking, backchanneling, and pause handling. Crucially, isolating timing from token selection preserves semantic coherence and reduces the portion of duplicate n-grams by over 50% compared to standard GRPO, effectively eliminating degenerative repetition.
An End-to-End Mispronunciation Detection System for L2 English Speech Leveraging Novel Anti-Phone Modeling
May 25, 2020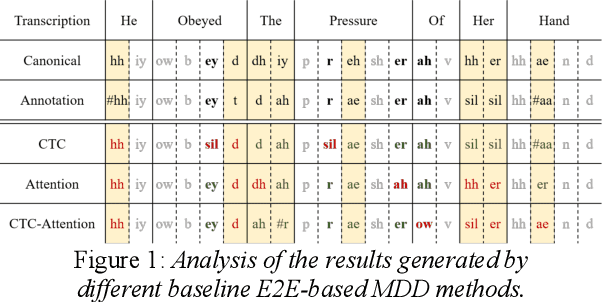
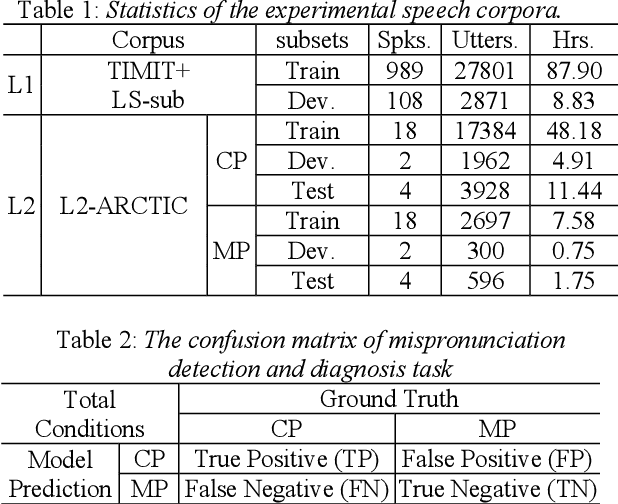
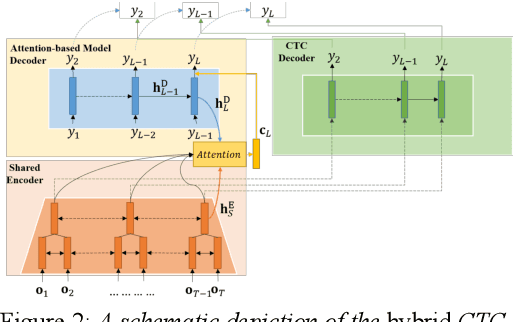
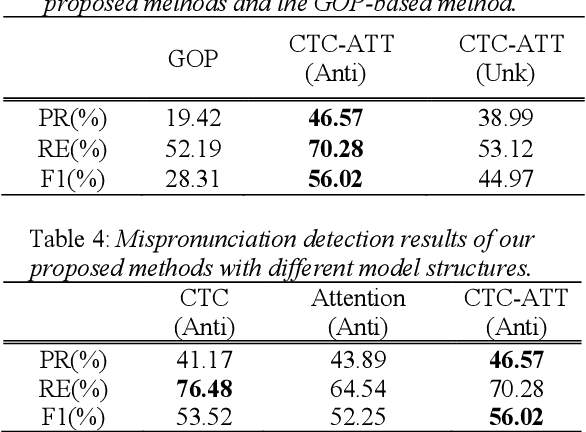
Mispronunciation detection and diagnosis (MDD) is a core component of computer-assisted pronunciation training (CAPT). Most of the existing MDD approaches focus on dealing with categorical errors (viz. one canonical phone is substituted by another one, aside from those mispronunciations caused by deletions or insertions). However, accurate detection and diagnosis of non-categorial or distortion errors (viz. approximating L2 phones with L1 (first-language) phones, or erroneous pronunciations in between) still seems out of reach. In view of this, we propose to conduct MDD with a novel end- to-end automatic speech recognition (E2E-based ASR) approach. In particular, we expand the original L2 phone set with their corresponding anti-phone set, making the E2E-based MDD approach have a better capability to take in both categorical and non-categorial mispronunciations, aiming to provide better mispronunciation detection and diagnosis feedback. Furthermore, a novel transfer-learning paradigm is devised to obtain the initial model estimate of the E2E-based MDD system without resource to any phonological rules. Extensive sets of experimental results on the L2-ARCTIC dataset show that our best system can outperform the existing E2E baseline system and pronunciation scoring based method (GOP) in terms of the F1-score, by 11.05% and 27.71%, respectively.