 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextless Speech-to-Speech Translation on Real Data
Dec 15, 2021
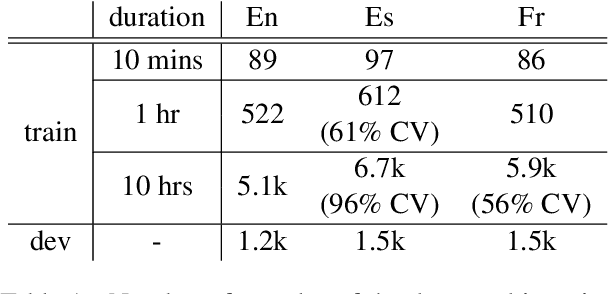
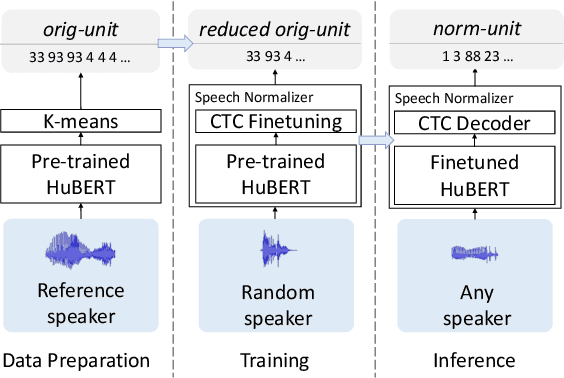
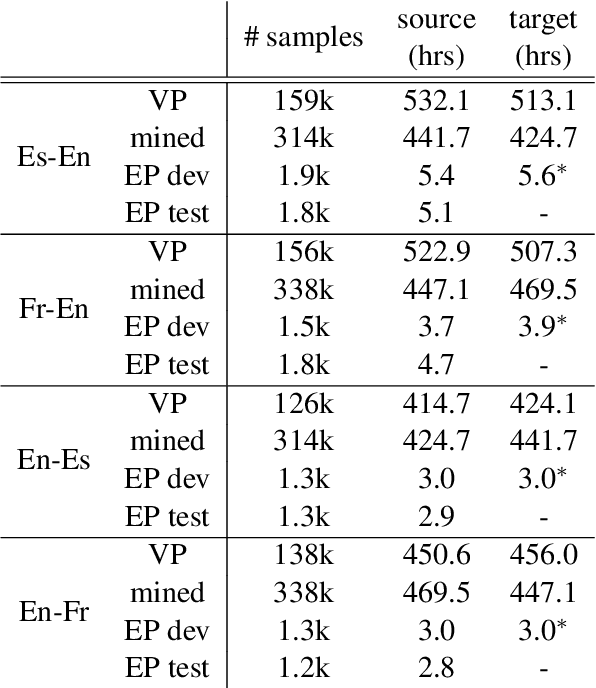
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.
Direct simultaneous speech to speech translation
Oct 15, 2021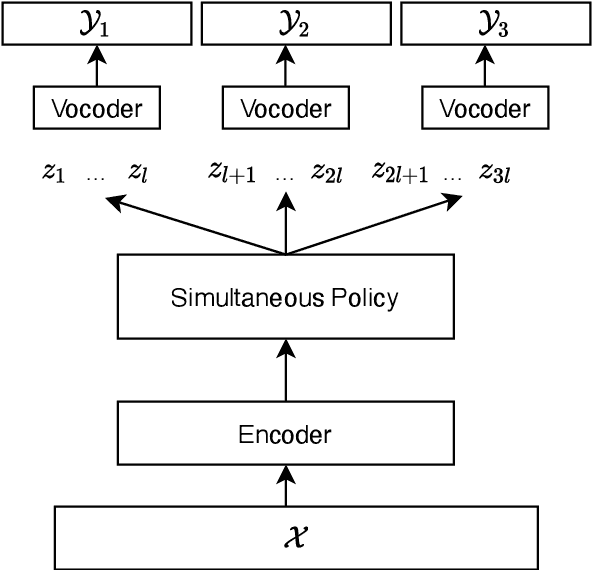
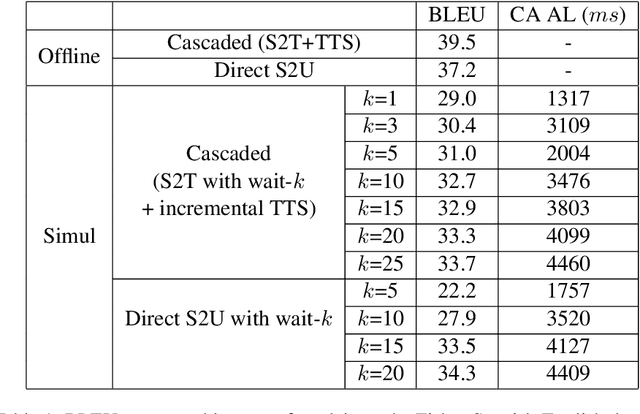
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
Incremental Speech Synthesis For Speech-To-Speech Translation
Oct 15, 2021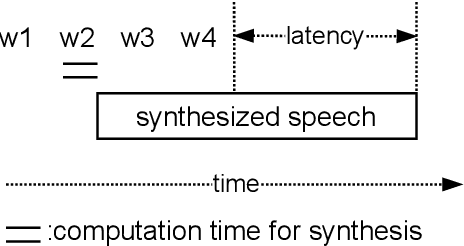
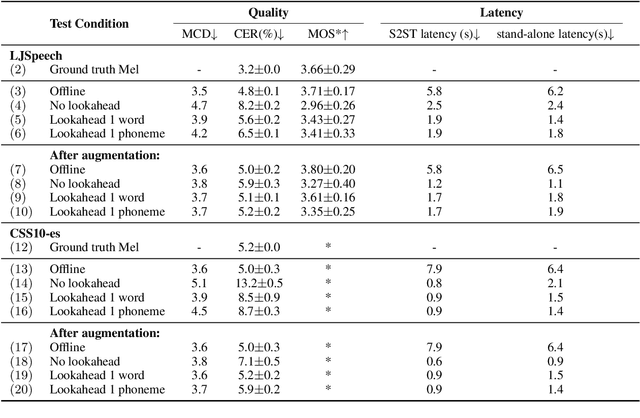

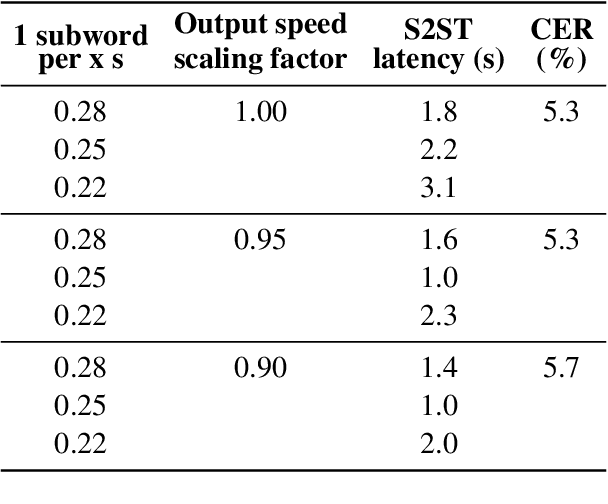
In a speech-to-speech translation (S2ST) pipeline, the text-to-speech (TTS) module is an important component for delivering the translated speech to users. To enable incremental S2ST, the TTS module must be capable of synthesizing and playing utterances while its input text is still streaming in. In this work, we focus on improving the incremental synthesis performance of TTS models. With a simple data augmentation strategy based on prefixes, we are able to improve the incremental TTS quality to approach offline performance. Furthermore, we bring our incremental TTS system to the practical scenario in combination with an upstream simultaneous speech translation system, and show the gains also carry over to this use-case. In addition, we propose latency metrics tailored to S2ST applications, and investigate methods for latency reduction in this context.
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Aug 14, 2021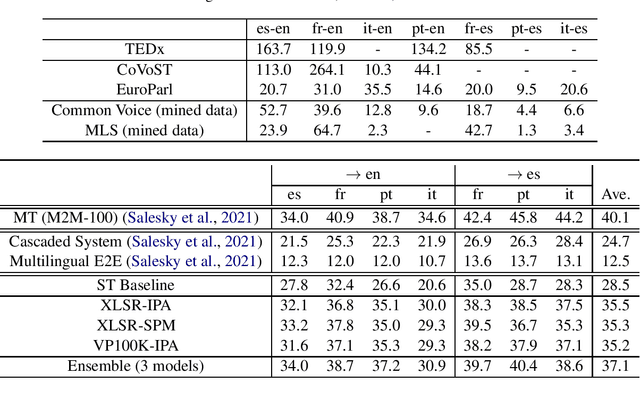
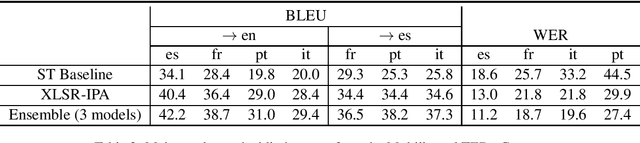
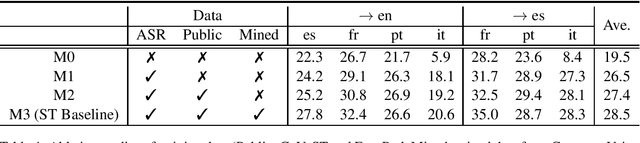
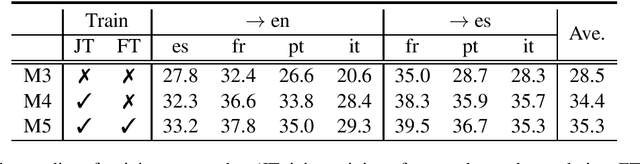
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Pay Better Attention to Attention: Head Selection in Multilingual and Multi-Domain Sequence Modeling
Jun 21, 2021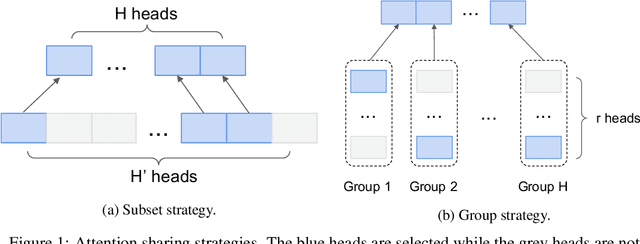
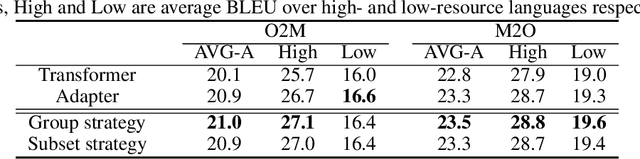

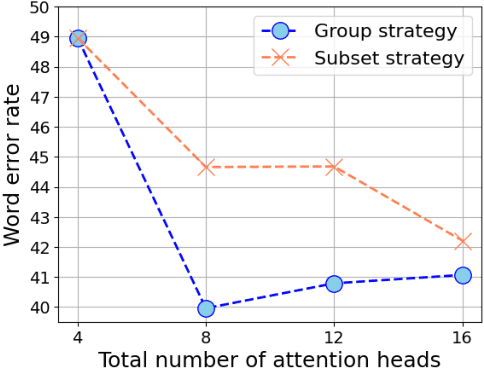
Multi-head attention has each of the attention heads collect salient information from different parts of an input sequence, making it a powerful mechanism for sequence modeling. Multilingual and multi-domain learning are common scenarios for sequence modeling, where the key challenge is to maximize positive transfer and mitigate negative transfer across languages and domains. In this paper, we find that non-selective attention sharing is sub-optimal for achieving good generalization across all languages and domains. We further propose attention sharing strategies to facilitate parameter sharing and specialization in multilingual and multi-domain sequence modeling. Our approach automatically learns shared and specialized attention heads for different languages and domains to mitigate their interference. Evaluated in various tasks including speech recognition, text-to-text and speech-to-text translation, the proposed attention sharing strategies consistently bring gains to sequence models built upon multi-head attention. For speech-to-text translation, our approach yields an average of $+2.0$ BLEU over $13$ language directions in multilingual setting and $+2.0$ BLEU over $3$ domains in multi-domain setting.
LAWDR: Language-Agnostic Weighted Document Representations from Pre-trained Models
Jun 07, 2021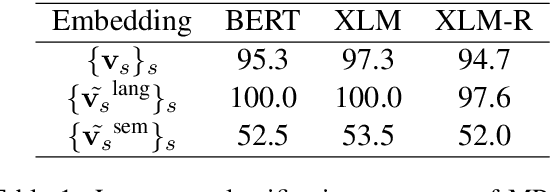
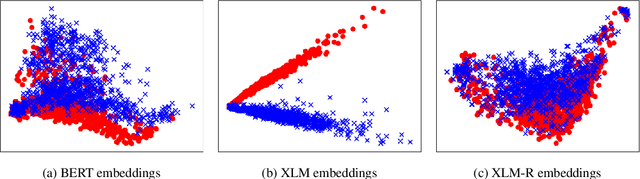
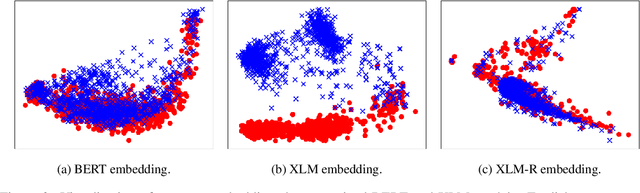
Cross-lingual document representations enable language understanding in multilingual contexts and allow transfer learning from high-resource to low-resource languages at the document level. Recently large pre-trained language models such as BERT, XLM and XLM-RoBERTa have achieved great success when fine-tuned on sentence-level downstream tasks. It is tempting to apply these cross-lingual models to document representation learning. However, there are two challenges: (1) these models impose high costs on long document processing and thus many of them have strict length limit; (2) model fine-tuning requires extra data and computational resources, which is not practical in resource-limited settings. In this work, we address these challenges by proposing unsupervised Language-Agnostic Weighted Document Representations (LAWDR). We study the geometry of pre-trained sentence embeddings and leverage it to derive document representations without fine-tuning. Evaluated on cross-lingual document alignment, LAWDR demonstrates comparable performance to state-of-the-art models on benchmark datasets.
Abusive Language Detection in Heterogeneous Contexts: Dataset Collection and the Role of Supervised Attention
May 24, 2021
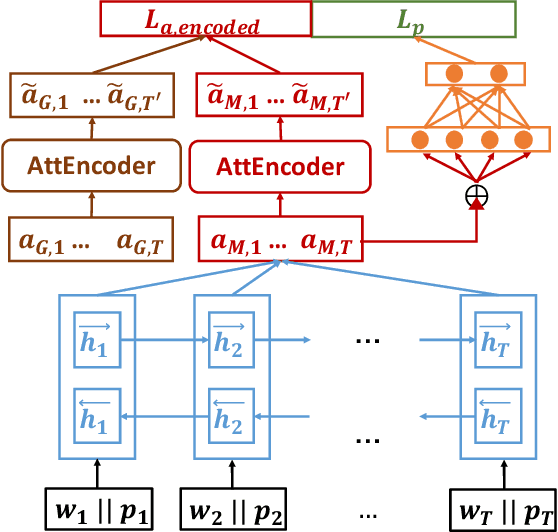
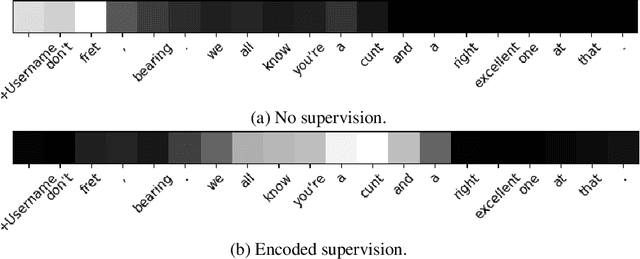

Abusive language is a massive problem in online social platforms. Existing abusive language detection techniques are particularly ill-suited to comments containing heterogeneous abusive language patterns, i.e., both abusive and non-abusive parts. This is due in part to the lack of datasets that explicitly annotate heterogeneity in abusive language. We tackle this challenge by providing an annotated dataset of abusive language in over 11,000 comments from YouTube. We account for heterogeneity in this dataset by separately annotating both the comment as a whole and the individual sentences that comprise each comment. We then propose an algorithm that uses a supervised attention mechanism to detect and categorize abusive content using multi-task learning. We empirically demonstrate the challenges of using traditional techniques on heterogeneous content and the comparative gains in performance of the proposed approach over state-of-the-art methods.
From Solving a Problem Boldly to Cutting the Gordian Knot: Idiomatic Text Generation
May 11, 2021
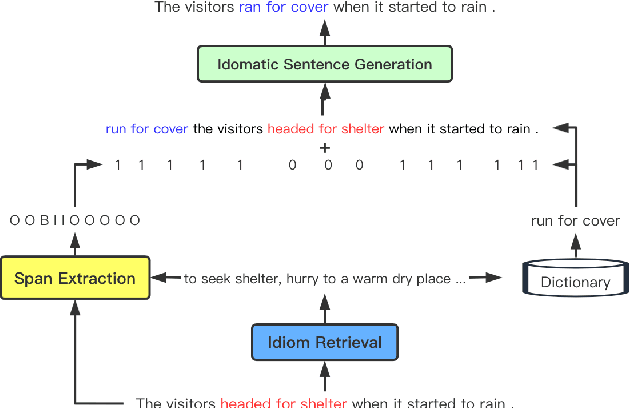
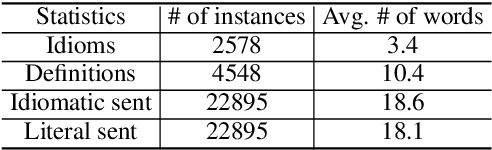
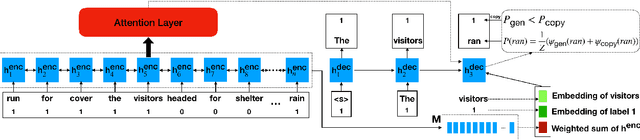
We study a new application for text generation -- idiomatic sentence generation -- which aims to transfer literal phrases in sentences into their idiomatic counterparts. Inspired by psycholinguistic theories of idiom use in one's native language, we propose a novel approach for this task, which retrieves the appropriate idiom for a given literal sentence, extracts the span of the sentence to be replaced by the idiom, and generates the idiomatic sentence by using a neural model to combine the retrieved idiom and the remainder of the sentence. Experiments on a novel dataset created for this task show that our model is able to effectively transfer literal sentences into idiomatic ones. Furthermore, automatic and human evaluations show that for this task, the proposed model outperforms a series of competitive baseline models for text generation.
Demystify Optimization Challenges in Multilingual Transformers
Apr 20, 2021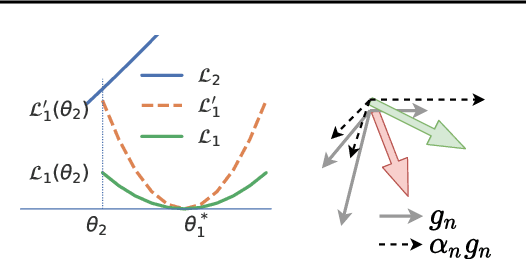
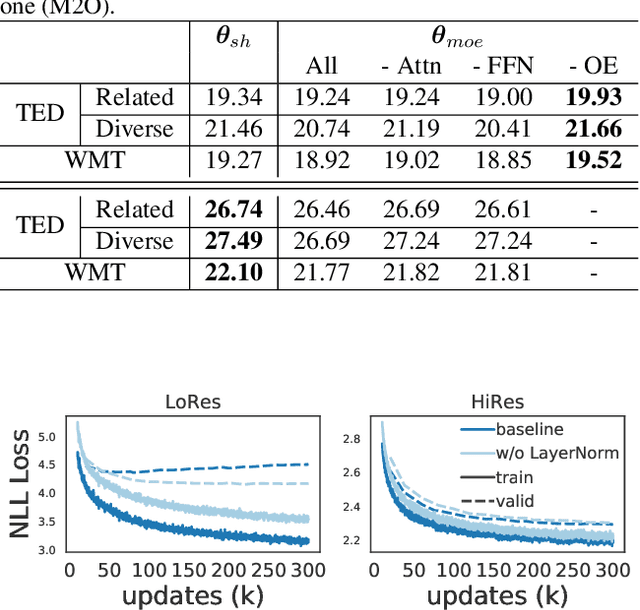
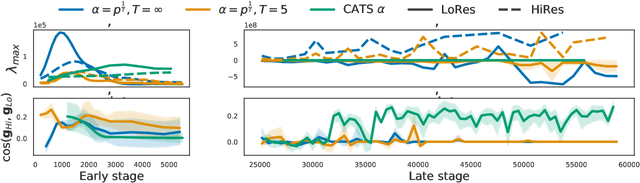
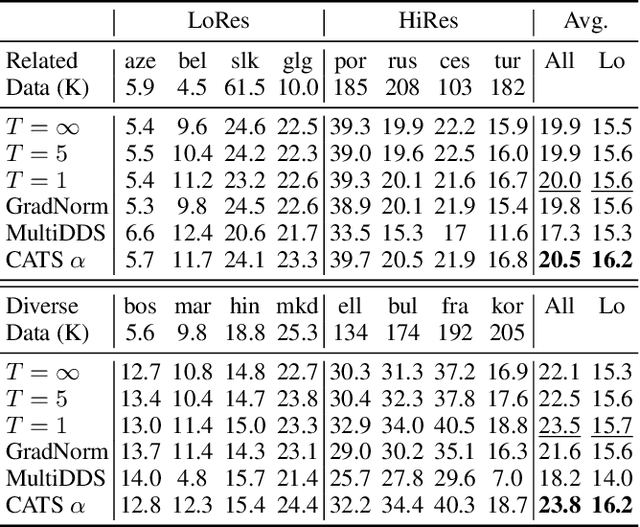
Multilingual Transformer improves parameter efficiency and crosslingual transfer. How to effectively train multilingual models has not been well studied. Using multilingual machine translation as a testbed, we study optimization challenges from loss landscape and parameter plasticity perspectives. We found that imbalanced training data poses task interference between high and low resource languages, characterized by nearly orthogonal gradients for major parameters and the optimization trajectory being mostly dominated by high resource. We show that local curvature of the loss surface affects the degree of interference, and existing heuristics of data subsampling implicitly reduces the sharpness, although still face a trade-off between high and low resource languages. We propose a principled multi-objective optimization algorithm, Curvature Aware Task Scaling (CATS), which improves both optimization and generalization especially for low resource. Experiments on TED, WMT and OPUS-100 benchmarks demonstrate that CATS advances the Pareto front of accuracy while being efficient to apply to massive multilingual settings at the scale of 100 languages.
Adaptive Sparse Transformer for Multilingual Translation
Apr 15, 2021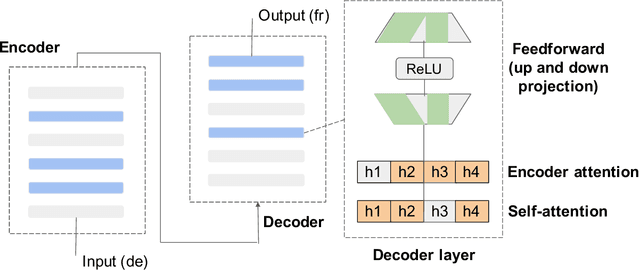
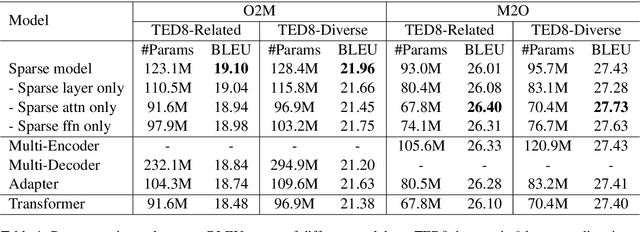
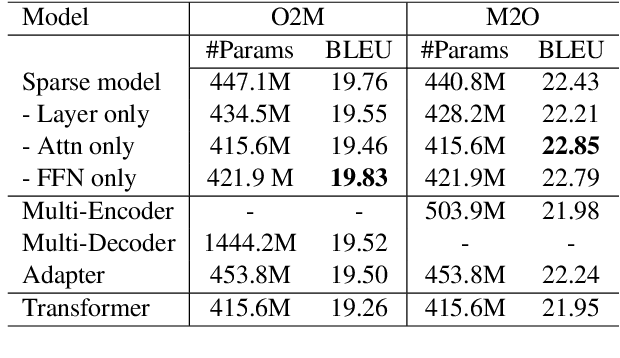
Multilingual machine translation has attracted much attention recently due to its support of knowledge transfer among languages and the low cost of training and deployment compared with numerous bilingual models. A known challenge of multilingual models is the negative language interference. In order to enhance the translation quality, deeper and wider architectures are applied to multilingual modeling for larger model capacity, which suffers from the increased inference cost at the same time. It has been pointed out in recent studies that parameters shared among languages are the cause of interference while they may also enable positive transfer. Based on these insights, we propose an adaptive and sparse architecture for multilingual modeling, and train the model to learn shared and language-specific parameters to improve the positive transfer and mitigate the interference. The sparse architecture only activates a subnetwork which preserves inference efficiency, and the adaptive design selects different subnetworks based on the input languages. Evaluated on multilingual translation across multiple public datasets, our model outperforms strong baselines in terms of translation quality without increasing the inference cost.