 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransST: Transfer Learning Embedded Spatial Factor Modeling of Spatial Transcriptomics Data
Apr 15, 2025
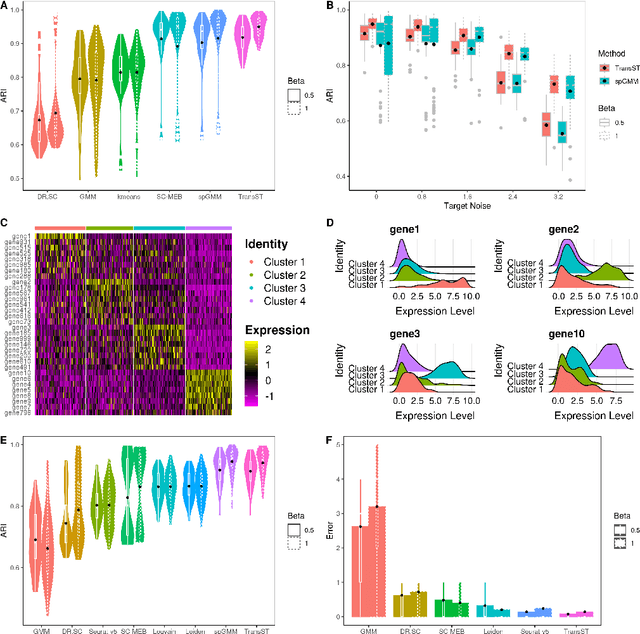


Background: Spatial transcriptomics have emerged as a powerful tool in biomedical research because of its ability to capture both the spatial contexts and abundance of the complete RNA transcript profile in organs of interest. However, limitations of the technology such as the relatively low resolution and comparatively insufficient sequencing depth make it difficult to reliably extract real biological signals from these data. To alleviate this challenge, we propose a novel transfer learning framework, referred to as TransST, to adaptively leverage the cell-labeled information from external sources in inferring cell-level heterogeneity of a target spatial transcriptomics data. Results: Applications in several real studies as well as a number of simulation settings show that our approach significantly improves existing techniques. For example, in the breast cancer study, TransST successfully identifies five biologically meaningful cell clusters, including the two subgroups of cancer in situ and invasive cancer; in addition, only TransST is able to separate the adipose tissues from the connective issues among all the studied methods. Conclusions: In summary, the proposed method TransST is both effective and robust in identifying cell subclusters and detecting corresponding driving biomarkers in spatial transcriptomics data.
Bias in Large Language Models: Origin, Evaluation, and Mitigation
Nov 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing, but their susceptibility to biases poses significant challenges. This comprehensive review examines the landscape of bias in LLMs, from its origins to current mitigation strategies. We categorize biases as intrinsic and extrinsic, analyzing their manifestations in various NLP tasks. The review critically assesses a range of bias evaluation methods, including data-level, model-level, and output-level approaches, providing researchers with a robust toolkit for bias detection. We further explore mitigation strategies, categorizing them into pre-model, intra-model, and post-model techniques, highlighting their effectiveness and limitations. Ethical and legal implications of biased LLMs are discussed, emphasizing potential harms in real-world applications such as healthcare and criminal justice. By synthesizing current knowledge on bias in LLMs, this review contributes to the ongoing effort to develop fair and responsible AI systems. Our work serves as a comprehensive resource for researchers and practitioners working towards understanding, evaluating, and mitigating bias in LLMs, fostering the development of more equitable AI technologies.
Unified Transfer Learning Models for High-Dimensional Linear Regression
Jul 01, 2023Transfer learning plays a key role in modern data analysis when: (1) the target data are scarce but the source data are sufficient; (2) the distributions of the source and target data are heterogeneous. This paper develops an interpretable unified transfer learning model, termed as UTrans, which can detect both transferable variables and source data. More specifically, we establish the estimation error bounds and prove that our bounds are lower than those with target data only. Besides, we propose a source detection algorithm based on hypothesis testing to exclude the nontransferable data. We evaluate and compare UTrans to the existing algorithms in multiple experiments. It is shown that UTrans attains much lower estimation and prediction errors than the existing methods, while preserving interpretability. We finally apply it to the US intergenerational mobility data and compare our proposed algorithms to the classical machine learning algorithms.
Integrative Clustering of Multi-View Data by Nonnegative Matrix Factorization
Oct 25, 2021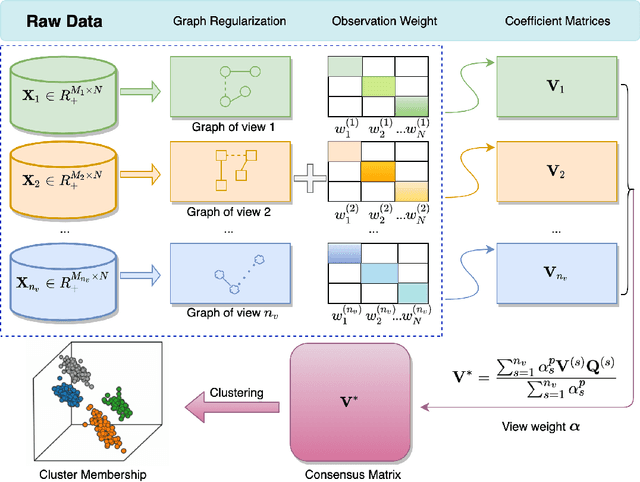

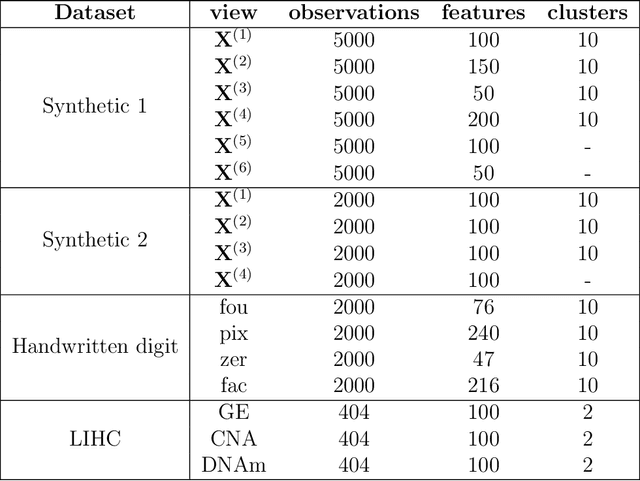
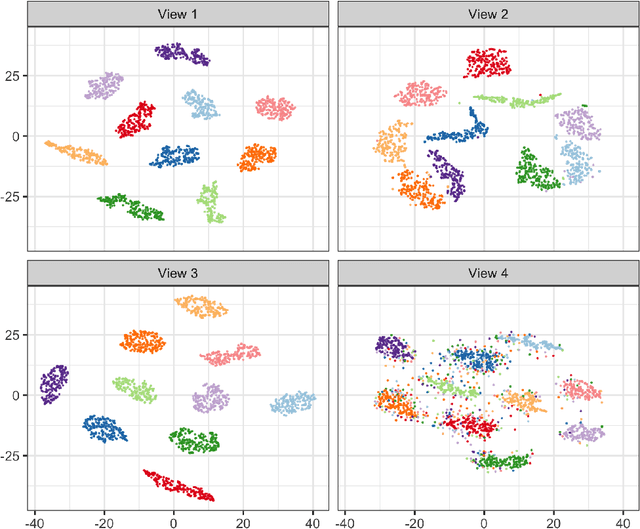
Learning multi-view data is an emerging problem in machine learning research, and nonnegative matrix factorization (NMF) is a popular dimensionality-reduction method for integrating information from multiple views. These views often provide not only consensus but also diverse information. However, most multi-view NMF algorithms assign equal weight to each view or tune the weight via line search empirically, which can be computationally expensive or infeasible without any prior knowledge of the views. In this paper, we propose a weighted multi-view NMF (WM-NMF) algorithm. In particular, we aim to address the critical technical gap, which is to learn both view-specific and observation-specific weights to quantify each view's information content. The introduced weighting scheme can alleviate unnecessary views' adverse effects and enlarge the positive effects of the important views by assigning smaller and larger weights, respectively. In addition, we provide theoretical investigations about the convergence, perturbation analysis, and generalization error of the WM-NMF algorithm. Experimental results confirm the effectiveness and advantages of the proposed algorithm in terms of achieving better clustering performance and dealing with the corrupted data compared to the existing algorithms.