 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-and-Knowledge Enhanced Large Language Model for Generalizable Pedestrian Crossing Behavior Inference
Jan 02, 2026Existing paradigms for inferring pedestrian crossing behavior, ranging from statistical models to supervised learning methods, demonstrate limited generalizability and perform inadequately on new sites. Recent advances in Large Language Models (LLMs) offer a shift from numerical pattern fitting to semantic, context-aware behavioral reasoning, yet existing LLM applications lack domain-specific adaptation and visual context. This study introduces Pedestrian Crossing LLM (PedX-LLM), a vision-and-knowledge enhanced framework designed to transform pedestrian crossing inference from site-specific pattern recognition to generalizable behavioral reasoning. By integrating LLaVA-extracted visual features with textual data and transportation domain knowledge, PedX-LLM fine-tunes a LLaMA-2-7B foundation model via Low-Rank Adaptation (LoRA) to infer crossing decisions. PedX-LLM achieves 82.0% balanced accuracy, outperforming the best statistical and supervised learning methods. Results demonstrate that the vision-augmented module contributes a 2.9% performance gain by capturing the built environment and integrating domain knowledge yields an additional 4.1% improvement. To evaluate generalizability across unseen environments, cross-site validation was conducted using site-based partitioning. The zero-shot PedX-LLM configuration achieves 66.9% balanced accuracy on five unseen test sites, outperforming the baseline data-driven methods by at least 18 percentage points. Incorporating just five validation examples via few-shot learning to PedX-LLM further elevates the balanced accuracy to 72.2%. PedX-LLM demonstrates strong generalizability to unseen scenarios, confirming that vision-and-knowledge-enhanced reasoning enables the model to mimic human-like decision logic and overcome the limitations of purely data-driven methods.
VALLR-Pin: Uncertainty-Factorized Visual Speech Recognition for Mandarin with Pinyin Guidance
Dec 29, 2025Visual speech recognition (VSR) aims to transcribe spoken content from silent lip-motion videos and is particularly challenging in Mandarin due to severe viseme ambiguity and pervasive homophones. We propose VALLR-Pin, a two-stage Mandarin VSR framework that extends the VALLR architecture by explicitly incorporating Pinyin as an intermediate representation. In the first stage, a shared visual encoder feeds dual decoders that jointly predict Mandarin characters and their corresponding Pinyin sequences, encouraging more robust visual-linguistic representations. In the second stage, an LLM-based refinement module takes the predicted Pinyin sequence together with an N-best list of character hypotheses to resolve homophone-induced ambiguities. To further adapt the LLM to visual recognition errors, we fine-tune it on synthetic instruction data constructed from model-generated Pinyin-text pairs, enabling error-aware correction. Experiments on public Mandarin VSR benchmarks demonstrate that VALLR-Pin consistently improves transcription accuracy under multi-speaker conditions, highlighting the effectiveness of combining phonetic guidance with lightweight LLM refinement.
VALLR-Pin: Dual-Decoding Visual Speech Recognition for Mandarin with Pinyin-Guided LLM Refinement
Dec 23, 2025Visual Speech Recognition aims to transcribe spoken words from silent lip-motion videos. This task is particularly challenging for Mandarin, as visemes are highly ambiguous and homophones are prevalent. We propose VALLR-Pin, a novel two-stage framework that extends the recent VALLR architecture from English to Mandarin. First, a shared video encoder feeds into dual decoders, which jointly predict both Chinese character sequences and their standard Pinyin romanization. The multi-task learning of character and phonetic outputs fosters robust visual-semantic representations. During inference, the text decoder generates multiple candidate transcripts. We construct a prompt by concatenating the Pinyin output with these candidate Chinese sequences and feed it to a large language model to resolve ambiguities and refine the transcription. This provides the LLM with explicit phonetic context to correct homophone-induced errors. Finally, we fine-tune the LLM on synthetic noisy examples: we generate imperfect Pinyin-text pairs from intermediate VALLR-Pin checkpoints using the training data, creating instruction-response pairs for error correction. This endows the LLM with awareness of our model's specific error patterns. In summary, VALLR-Pin synergizes visual features with phonetic and linguistic context to improve Mandarin lip-reading performance.
Can We Ignore Labels In Out of Distribution Detection?
Apr 20, 2025
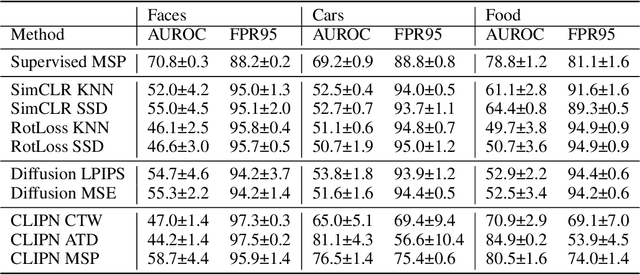

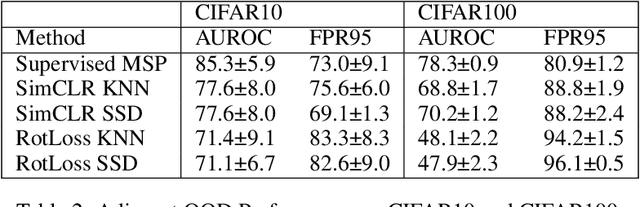
Out-of-distribution (OOD) detection methods have recently become more prominent, serving as a core element in safety-critical autonomous systems. One major purpose of OOD detection is to reject invalid inputs that could lead to unpredictable errors and compromise safety. Due to the cost of labeled data, recent works have investigated the feasibility of self-supervised learning (SSL) OOD detection, unlabeled OOD detection, and zero shot OOD detection. In this work, we identify a set of conditions for a theoretical guarantee of failure in unlabeled OOD detection algorithms from an information-theoretic perspective. These conditions are present in all OOD tasks dealing with real-world data: I) we provide theoretical proof of unlabeled OOD detection failure when there exists zero mutual information between the learning objective and the in-distribution labels, a.k.a. 'label blindness', II) we define a new OOD task - Adjacent OOD detection - that tests for label blindness and accounts for a previously ignored safety gap in all OOD detection benchmarks, and III) we perform experiments demonstrating that existing unlabeled OOD methods fail under conditions suggested by our label blindness theory and analyze the implications for future research in unlabeled OOD methods.
HEAT:History-Enhanced Dual-phase Actor-Critic Algorithm with A Shared Transformer
Apr 13, 2025

For a single-gateway LoRaWAN network, this study proposed a history-enhanced two-phase actor-critic algorithm with a shared transformer algorithm (HEAT) to improve network performance. HEAT considers uplink parameters and often neglected downlink parameters, and effectively integrates offline and online reinforcement learning, using historical data and real-time interaction to improve model performance. In addition, this study developed an open source LoRaWAN network simulator LoRaWANSim. The simulator considers the demodulator lock effect and supports multi-channel, multi-demodulator and bidirectional communication. Simulation experiments show that compared with the best results of all compared algorithms, HEAT improves the packet success rate and energy efficiency by 15% and 95%, respectively.
Optimizing Multi-Gateway LoRaWAN via Cloud-Edge Collaboration and Knowledge Distillation
Apr 13, 2025For large-scale multi-gateway LoRaWAN networks, this study proposes a cloud-edge collaborative resource allocation and decision-making method based on edge intelligence, HEAT-LDL (HEAT-Local Distill Lyapunov), which realizes collaborative decision-making between gateways and terminal nodes. HEAT-LDL combines the Actor-Critic architecture and the Lyapunov optimization method to achieve intelligent downlink control and gateway load balancing. When the signal quality is good, the network server uses the HEAT algorithm to schedule the terminal nodes. To improve the efficiency of autonomous decision-making of terminal nodes, HEAT-LDL performs cloud-edge knowledge distillation on the HEAT teacher model on the terminal node side. When the downlink decision instruction is lost, the terminal node uses the student model and the edge decider based on prior knowledge and local history to make collaborative autonomous decisions. Simulation experiments show that compared with the optimal results of all compared algorithms, HEAT-LDL improves the packet success rate and energy efficiency by 20.5% and 88.1%, respectively.
Neuro Symbolic Knowledge Reasoning for Procedural Video Question Answering
Mar 19, 2025



This paper introduces a new video question-answering (VQA) dataset that challenges models to leverage procedural knowledge for complex reasoning. It requires recognizing visual entities, generating hypotheses, and performing contextual, causal, and counterfactual reasoning. To address this, we propose neuro symbolic reasoning module that integrates neural networks and LLM-driven constrained reasoning over variables for interpretable answer generation. Results show that combining LLMs with structured knowledge reasoning with logic enhances procedural reasoning on the STAR benchmark and our dataset. Code and dataset at https://github.com/LUNAProject22/KML soon.
Drone Data Analytics for Measuring Traffic Metrics at Intersections in High-Density Areas
Nov 04, 2024This study employed over 100 hours of high-altitude drone video data from eight intersections in Hohhot to generate a unique and extensive dataset encompassing high-density urban road intersections in China. This research has enhanced the YOLOUAV model to enable precise target recognition on unmanned aerial vehicle (UAV) datasets. An automated calibration algorithm is presented to create a functional dataset in high-density traffic flows, which saves human and material resources. This algorithm can capture up to 200 vehicles per frame while accurately tracking over 1 million road users, including cars, buses, and trucks. Moreover, the dataset has recorded over 50,000 complete lane changes. It is the largest publicly available road user trajectories in high-density urban intersections. Furthermore, this paper updates speed and acceleration algorithms based on UAV elevation and implements a UAV offset correction algorithm. A case study demonstrates the usefulness of the proposed methods, showing essential parameters to evaluate intersections and traffic conditions in traffic engineering. The model can track more than 200 vehicles of different types simultaneously in highly dense traffic on an urban intersection in Hohhot, generating heatmaps based on spatial-temporal traffic flow data and locating traffic conflicts by conducting lane change analysis and surrogate measures. With the diverse data and high accuracy of results, this study aims to advance research and development of UAVs in transportation significantly. The High-Density Intersection Dataset is available for download at https://github.com/Qpu523/High-density-Intersection-Dataset.
No Analog Combiner TTD-based Hybrid Precoding for Multi-User Sub-THz Communications
Jun 17, 2024

We address the design and optimization of real-world-suitable hybrid precoders for multi-user wideband sub-terahertz (sub-THz) communications. We note that the conventional fully connected true-time delay (TTD)-based architecture is impractical because there is no room for the required large number of analog signal combiners in the circuit board. Additionally, analog signal combiners incur significant signal power loss. These limitations are often overlooked in sub-THz research. To overcome these issues, we study a non-overlapping subarray architecture that eliminates the need for analog combiners. We extend the conventional single-user assumption by formulating an optimization problem to maximize the minimum data rate for simultaneously served users. This complex optimization problem is divided into two sub-problems. The first sub-problem aims to ensure a fair subarray allocation for all users and is solved via a continuous domain relaxation technique. The second sub-problem deals with practical TTD device constraints on range and resolution to maximize the subarray gain and is resolved by shifting to the phase domain. Our simulation results highlight significant performance gain for our real-world-ready TTD-based hybrid precoders.
Learning Optimal Linear Precoding for Cell-Free Massive MIMO with GNN
Jun 06, 2024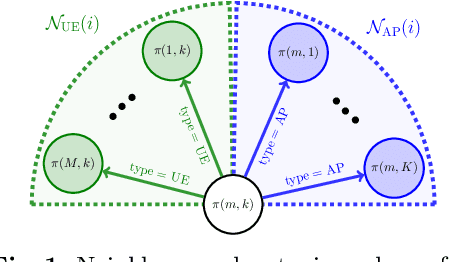
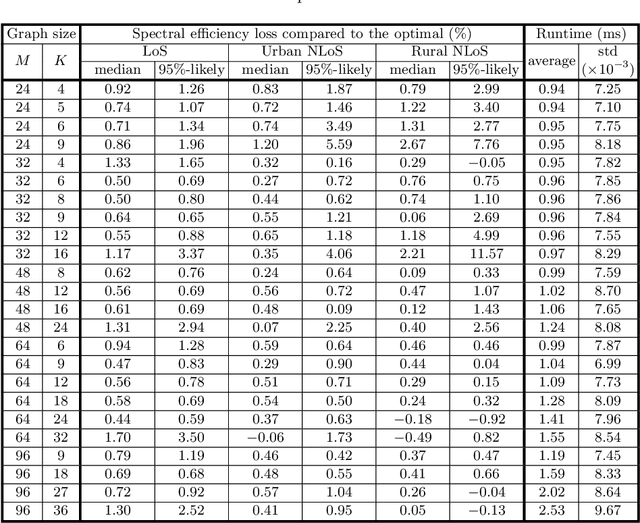

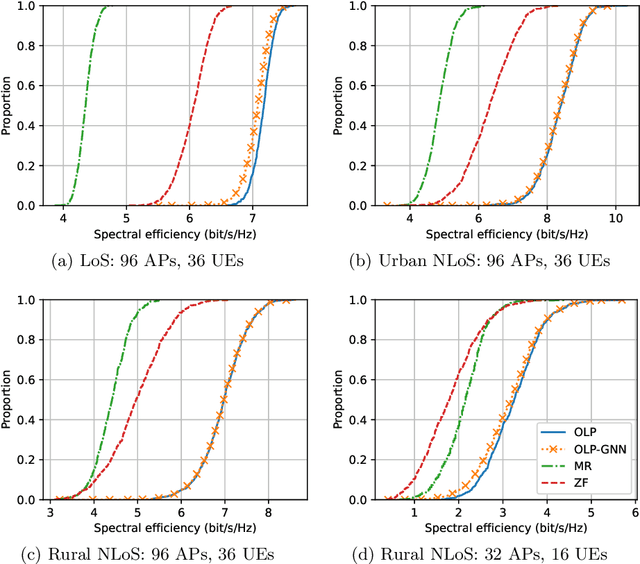
We develop a graph neural network (GNN) to compute, within a time budget of 1 to 2 milliseconds required by practical systems, the optimal linear precoder (OLP) maximizing the minimal downlink user data rate for a Cell-Free Massive MIMO system - a key 6G wireless technology. The state-of-the-art method is a bisection search on second order cone programming feasibility test (B-SOCP) which is a magnitude too slow for practical systems. Our approach relies on representing OLP as a node-level prediction task on a graph. We construct a graph that accurately captures the interdependence relation between access points (APs) and user equipments (UEs), and the permutation equivariance of the Max-Min problem. Our neural network, named OLP-GNN, is trained on data obtained by B-SOCP. We tailor the OLP-GNN size, together with several artful data preprocessing and postprocessing methods to meet the runtime requirement. We show by extensive simulations that it achieves near optimal spectral efficiency in a range of scenarios with different number of APs and UEs, and for both line-of-sight and non-line-of-sight radio propagation environments.