 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMid-attribute speaker generation using optimal-transport-based interpolation of Gaussian mixture models
Oct 18, 2022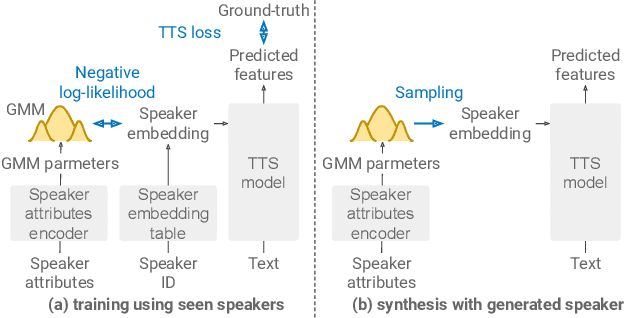
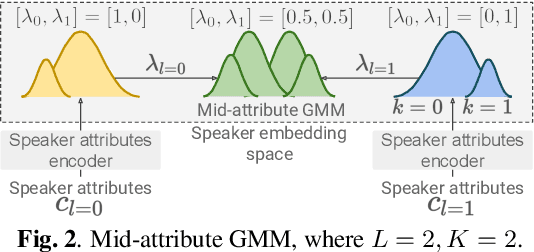
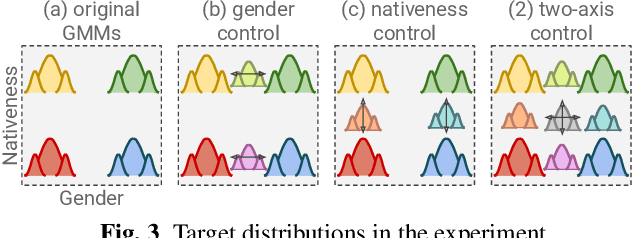
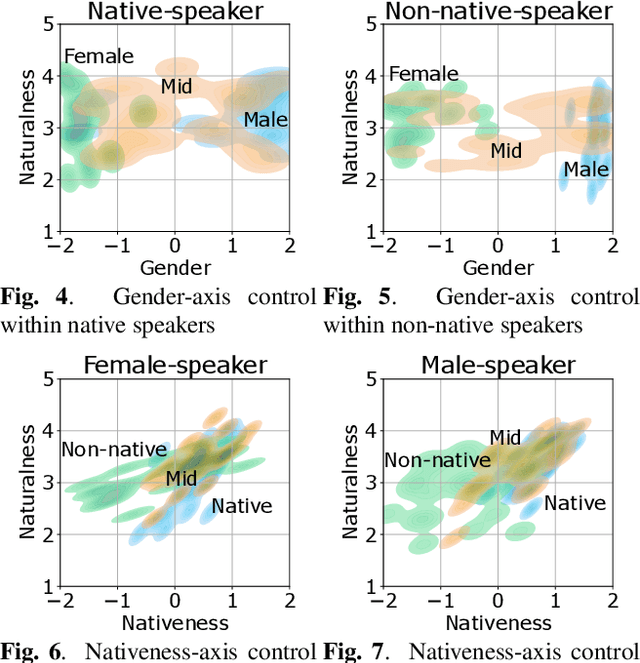
In this paper, we propose a method for intermediating multiple speakers' attributes and diversifying their voice characteristics in ``speaker generation,'' an emerging task that aims to synthesize a nonexistent speaker's naturally sounding voice. The conventional TacoSpawn-based speaker generation method represents the distributions of speaker embeddings by Gaussian mixture models (GMMs) conditioned with speaker attributes. Although this method enables the sampling of various speakers from the speaker-attribute-aware GMMs, it is not yet clear whether the learned distributions can represent speakers with an intermediate attribute (i.e., mid-attribute). To this end, we propose an optimal-transport-based method that interpolates the learned GMMs to generate nonexistent speakers with mid-attribute (e.g., gender-neutral) voices. We empirically validate our method and evaluate the naturalness of synthetic speech and the controllability of two speaker attributes: gender and language fluency. The evaluation results show that our method can control the generated speakers' attributes by a continuous scalar value without statistically significant degradation of speech naturalness.
Spontaneous speech synthesis with linguistic-speech consistency training using pseudo-filled pauses
Oct 18, 2022

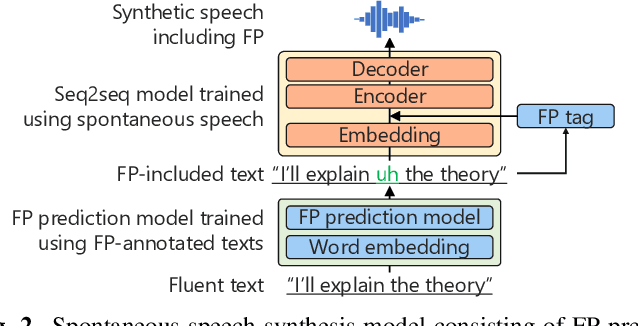

We propose a training method for spontaneous speech synthesis models that guarantees the consistency of linguistic parts of synthesized speech. Personalized spontaneous speech synthesis aims to reproduce the individuality of disfluency, such as filled pauses. Our prior model includes a filled-pause prediction model and synthesizes filled-pause-included speech from text without filled pauses. However, inserting the filled pauses degrades the quality of the linguistic parts of the synthesized speech. This might be because filled-pause insertion tendencies differ between training and inference, and the synthesis model cannot represent connections between filled pauses and surrounding phonemes in inference. We, therefore, developed a linguistic-speech consistency training that guarantees the consistency of linguistic parts of synthetic speech with and without filled pauses. The proposed consistency training utilizes not only ground-truth-filled pauses but also pseudo ones. Our experiments demonstrate that this method improves the naturalness of the synthetic linguistic speech and the entire predicted-filled-pause-included synthetic speech.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022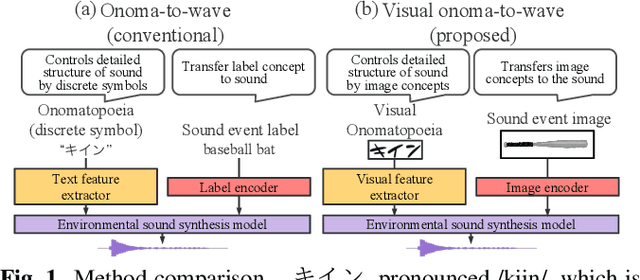
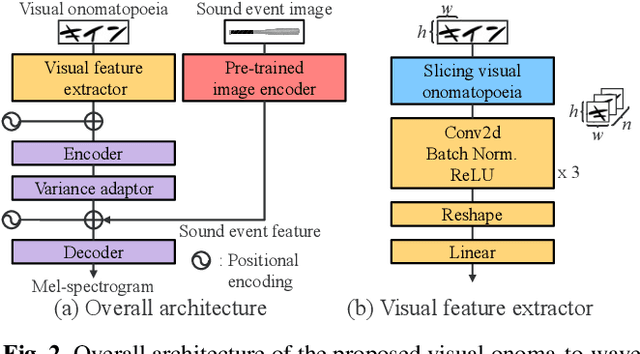

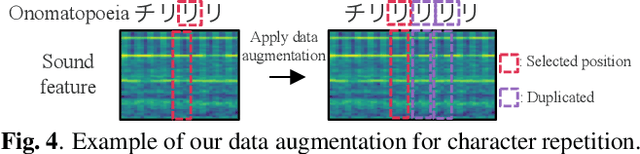
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
Empirical Study Incorporating Linguistic Knowledge on Filled Pauses for Personalized Spontaneous Speech Synthesis
Oct 14, 2022
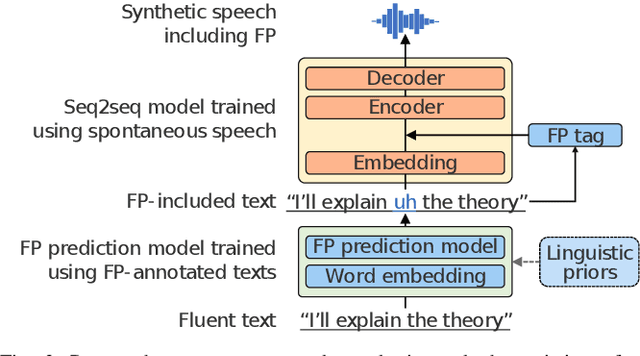
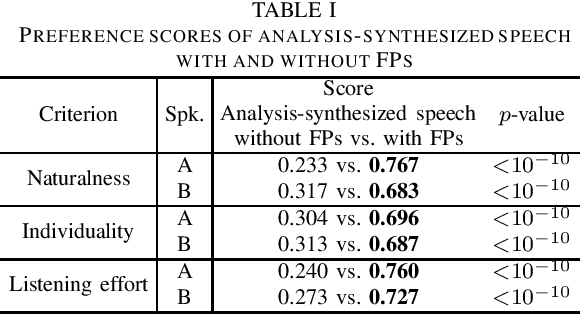
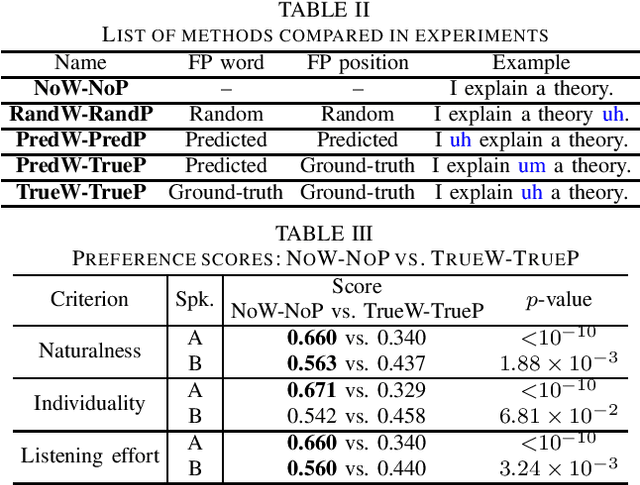
We present a comprehensive empirical study for personalized spontaneous speech synthesis on the basis of linguistic knowledge. With the advent of voice cloning for reading-style speech synthesis, a new voice cloning paradigm for human-like and spontaneous speech synthesis is required. We, therefore, focus on personalized spontaneous speech synthesis that can clone both the individual's voice timbre and speech disfluency. Specifically, we deal with filled pauses, a major source of speech disfluency, which is known to play an important role in speech generation and communication in psychology and linguistics. To comparatively evaluate personalized filled pause insertion and non-personalized filled pause prediction methods, we developed a speech synthesis method with a non-personalized external filled pause predictor trained with a multi-speaker corpus. The results clarify the position-word entanglement of filled pauses, i.e., the necessity of precisely predicting positions for naturalness and the necessity of precisely predicting words for individuality on the evaluation of synthesized speech.
Hyperbolic Timbre Embedding for Musical Instrument Sound Synthesis Based on Variational Autoencoders
Sep 27, 2022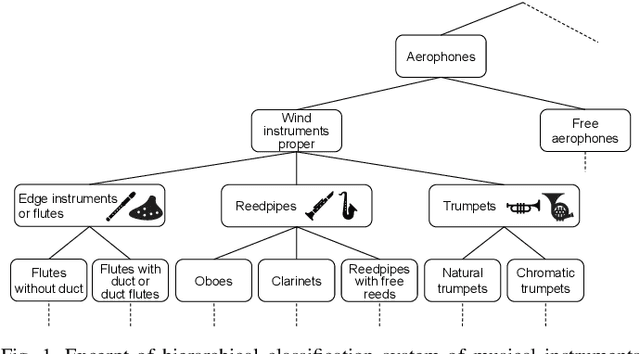
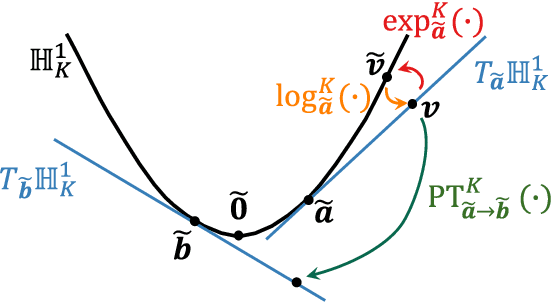
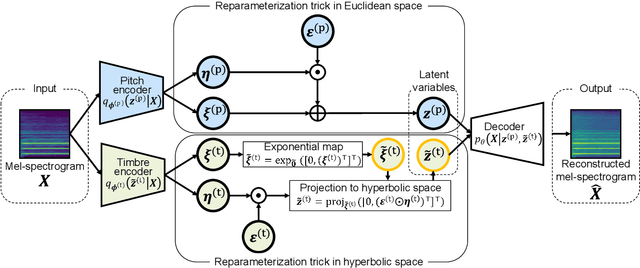
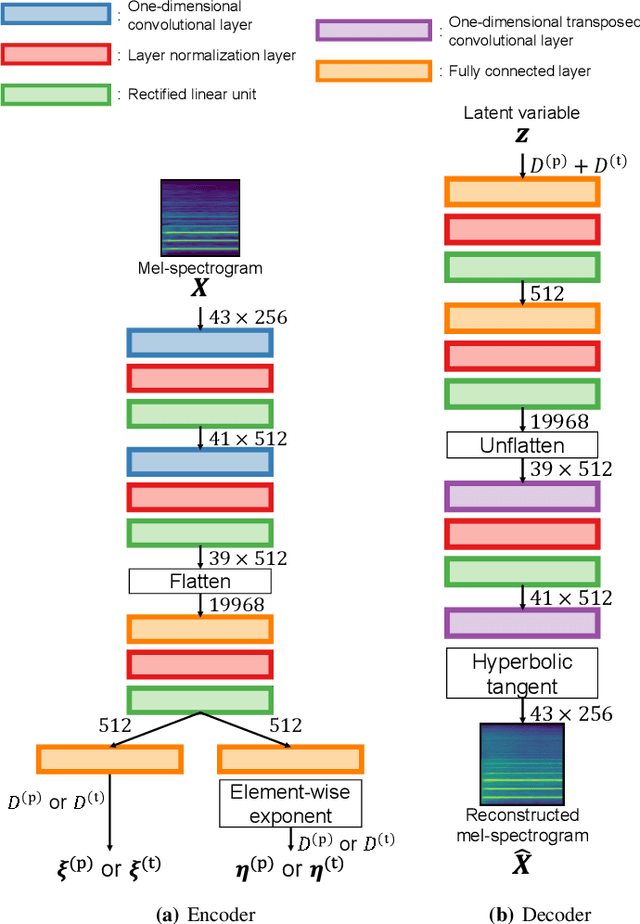
In this paper, we propose a musical instrument sound synthesis (MISS) method based on a variational autoencoder (VAE) that has a hierarchy-inducing latent space for timbre. VAE-based MISS methods embed an input signal into a low-dimensional latent representation that captures the characteristics of the input. Adequately manipulating this representation leads to sound morphing and timbre replacement. Although most VAE-based MISS methods seek a disentangled representation of pitch and timbre, how to capture an underlying structure in timbre remains an open problem. To address this problem, we focus on the fact that musical instruments can be hierarchically classified on the basis of their physical mechanisms. Motivated by this hierarchy, we propose a VAE-based MISS method by introducing a hyperbolic space for timbre. The hyperbolic space can represent treelike data more efficiently than the Euclidean space owing to its exponential growth property. Results of experiments show that the proposed method provides an efficient latent representation of timbre compared with the method using the Euclidean space.
Multi-Task Adversarial Training Algorithm for Multi-Speaker Neural Text-to-Speech
Sep 26, 2022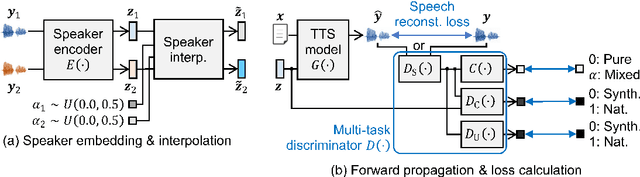
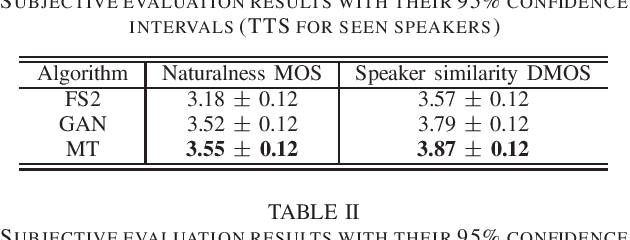
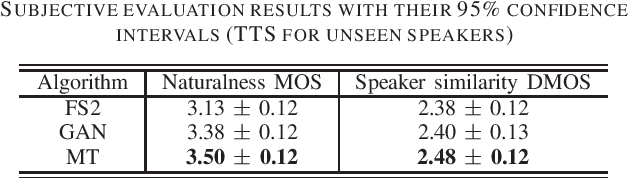
We propose a novel training algorithm for a multi-speaker neural text-to-speech (TTS) model based on multi-task adversarial training. A conventional generative adversarial network (GAN)-based training algorithm significantly improves the quality of synthetic speech by reducing the statistical difference between natural and synthetic speech. However, the algorithm does not guarantee the generalization performance of the trained TTS model in synthesizing voices of unseen speakers who are not included in the training data. Our algorithm alternatively trains two deep neural networks: multi-task discriminator and multi-speaker neural TTS model (i.e., generator of GANs). The discriminator is trained not only to distinguish between natural and synthetic speech but also to verify the speaker of input speech is existent or non-existent (i.e., newly generated by interpolating seen speakers' embedding vectors). Meanwhile, the generator is trained to minimize the weighted sum of the speech reconstruction loss and adversarial loss for fooling the discriminator, which achieves high-quality multi-speaker TTS even if the target speaker is unseen. Experimental evaluation shows that our algorithm improves the quality of synthetic speech better than a conventional GANSpeech algorithm.
Head-Related Transfer Function Interpolation from Spatially Sparse Measurements Using Autoencoder with Source Position Conditioning
Jul 22, 2022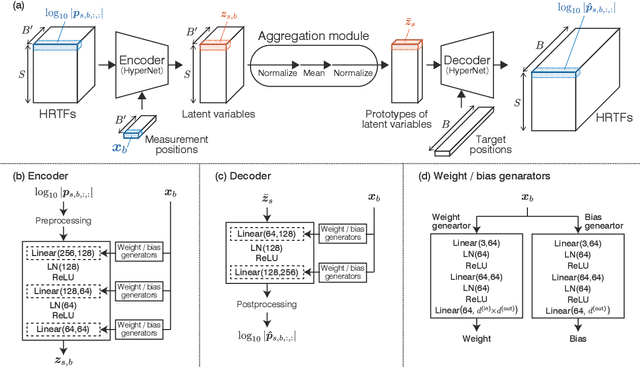
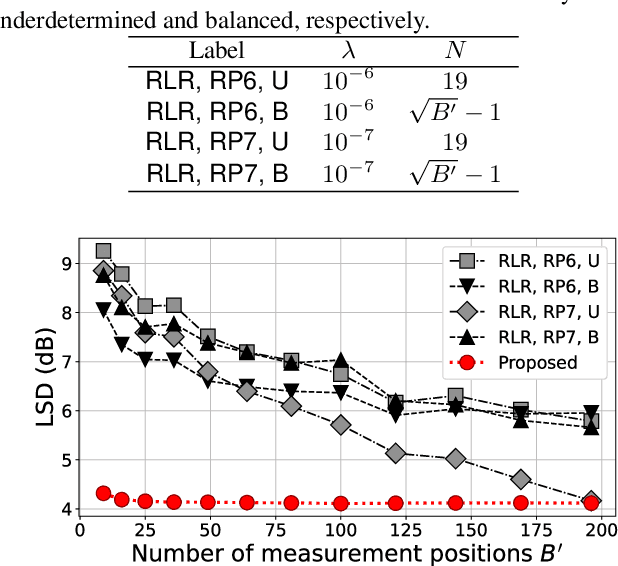
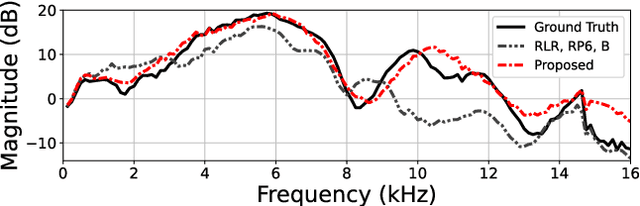
We propose a method of head-related transfer function (HRTF) interpolation from sparsely measured HRTFs using an autoencoder with source position conditioning. The proposed method is drawn from an analogy between an HRTF interpolation method based on regularized linear regression (RLR) and an autoencoder. Through this analogy, we found the key feature of the RLR-based method that HRTFs are decomposed into source-position-dependent and source-position-independent factors. On the basis of this finding, we design the encoder and decoder so that their weights and biases are generated from source positions. Furthermore, we introduce an aggregation module that reduces the dependence of latent variables on source position for obtaining a source-position-independent representation of each subject. Numerical experiments show that the proposed method can work well for unseen subjects and achieve an interpolation performance with only one-eighth measurements comparable to that of the RLR-based method.
Physics-informed convolutional neural network with bicubic spline interpolation for sound field estimation
Jul 22, 2022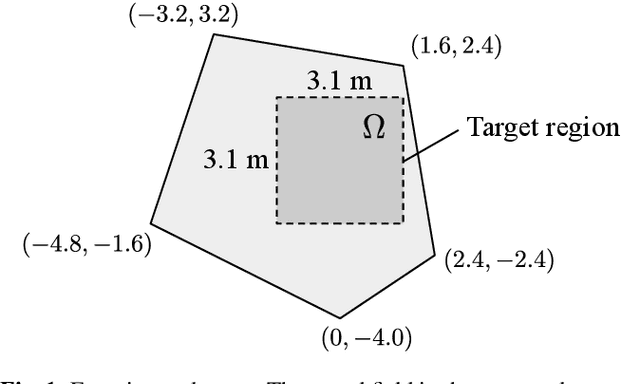
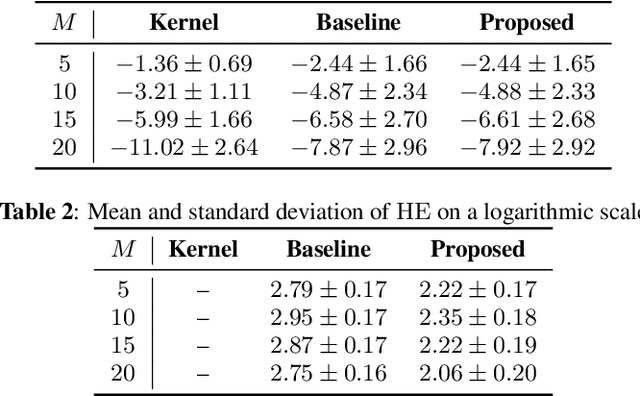
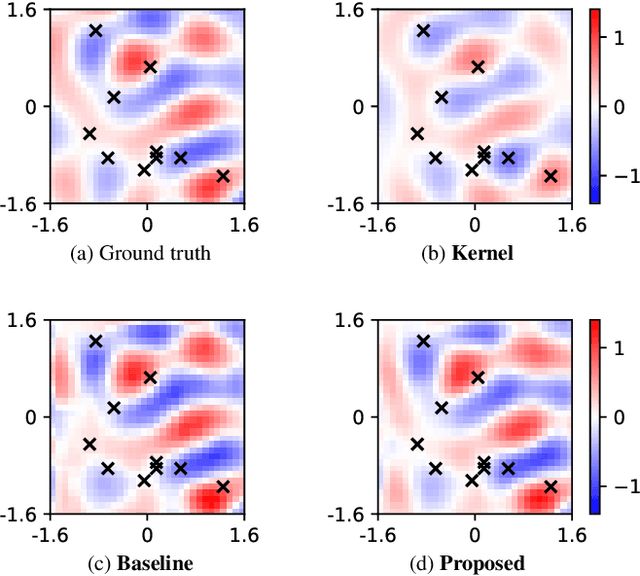
A sound field estimation method based on a physics-informed convolutional neural network (PICNN) using spline interpolation is proposed. Most of the sound field estimation methods are based on wavefunction expansion, making the estimated function satisfy the Helmholtz equation. However, these methods rely only on physical properties; thus, they suffer from a significant deterioration of accuracy when the number of measurements is small. Recent learning-based methods based on neural networks have advantages in estimating from sparse measurements when training data are available. However, since physical properties are not taken into consideration, the estimated function can be a physically infeasible solution. We propose the application of PICNN to the sound field estimation problem by using a loss function that penalizes deviation from the Helmholtz equation. Since the output of CNN is a spatially discretized pressure distribution, it is difficult to directly evaluate the Helmholtz-equation loss function. Therefore, we incorporate bicubic spline interpolation in the PICNN framework. Experimental results indicated that accurate and physically feasible estimation from sparse measurements can be achieved with the proposed method.
Exploring the Effectiveness of Self-supervised Learning and Classifier Chains in Emotion Recognition of Nonverbal Vocalizations
Jun 21, 2022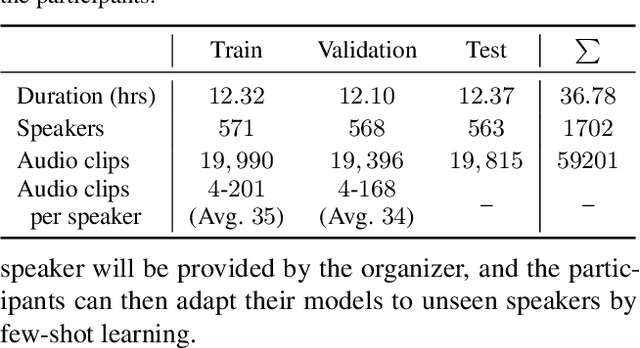
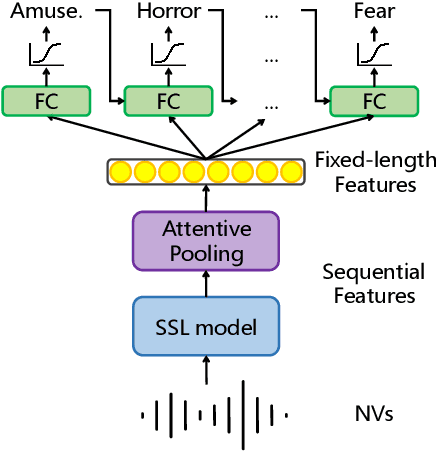
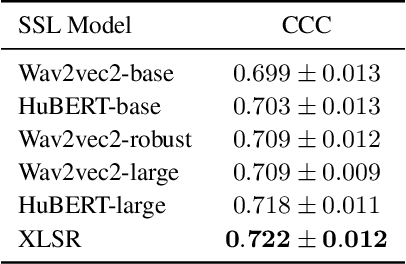
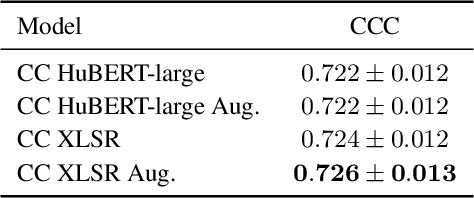
We present an emotion recognition system for nonverbal vocalizations (NVs) submitted to the ExVo Few-Shot track of the ICML Expressive Vocalizations Competition 2022. The proposed method uses self-supervised learning (SSL) models to extract features from NVs and uses a classifier chain to model the label dependency between emotions. Experimental results demonstrate that the proposed method can significantly improve the performance of this task compared to several baseline methods. Our proposed method obtained a mean concordance correlation coefficient (CCC) of $0.725$ in the validation set and $0.739$ in the test set, while the best baseline method only obtained $0.554$ in the validation set. We publicate our code at https://github.com/Aria-K-Alethia/ExVo to help others to reproduce our experimental results.
Human-in-the-loop Speaker Adaptation for DNN-based Multi-speaker TTS
Jun 21, 2022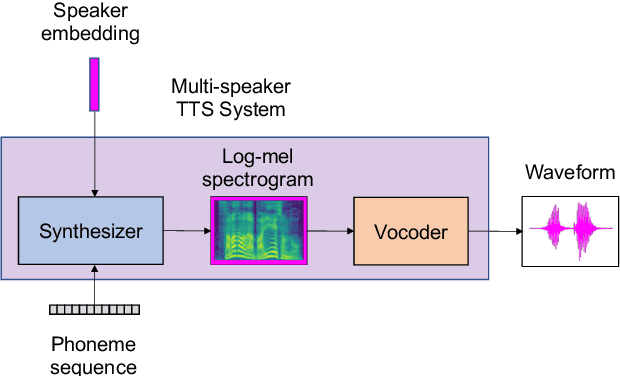
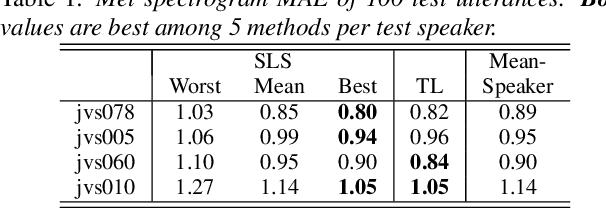
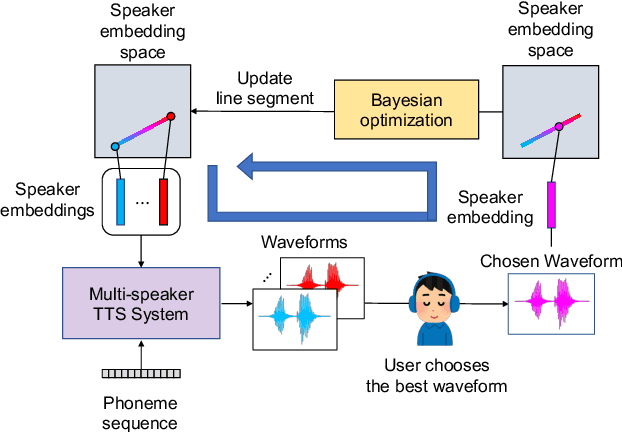
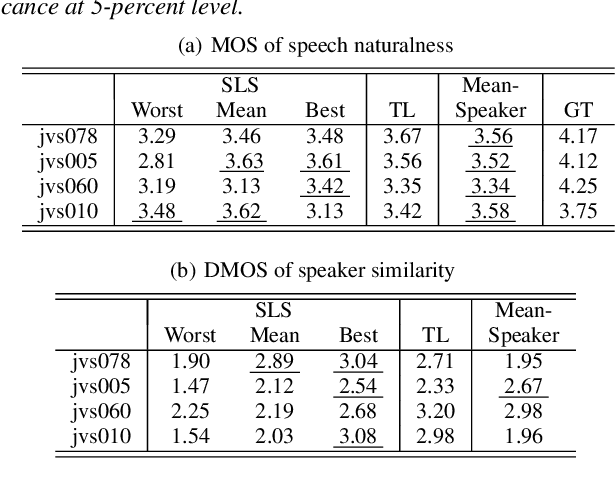
This paper proposes a human-in-the-loop speaker-adaptation method for multi-speaker text-to-speech. With a conventional speaker-adaptation method, a target speaker's embedding vector is extracted from his/her reference speech using a speaker encoder trained on a speaker-discriminative task. However, this method cannot obtain an embedding vector for the target speaker when the reference speech is unavailable. Our method is based on a human-in-the-loop optimization framework, which incorporates a user to explore the speaker-embedding space to find the target speaker's embedding. The proposed method uses a sequential line search algorithm that repeatedly asks a user to select a point on a line segment in the embedding space. To efficiently choose the best speech sample from multiple stimuli, we also developed a system in which a user can switch between multiple speakers' voices for each phoneme while looping an utterance. Experimental results indicate that the proposed method can achieve comparable performance to the conventional one in objective and subjective evaluations even if reference speech is not used as the input of a speaker encoder directly.