 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Throughput Image-Based Plant Stand Count Estimation Using Convolutional Neural Networks
Oct 23, 2020
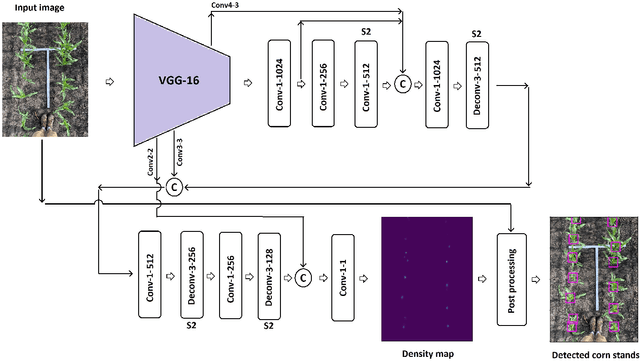
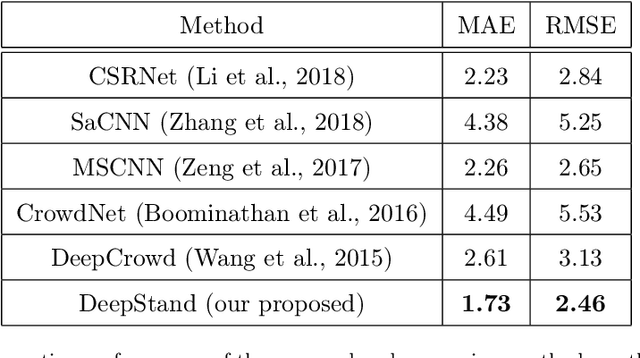

The future landscape of modern farming and plant breeding is rapidly changing due to the complex needs of our society. The explosion of collectable data has started a revolution in agriculture to the point where innovation must occur. To a commercial organization, the accurate and efficient collection of information is necessary to ensure that optimal decisions are made at key points of the breeding cycle. However, due to the shear size of a breeding program and current resource limitations, the ability to collect precise data on individual plants is not possible. In particular, efficient phenotyping of crops to record its color, shape, chemical properties, disease susceptibility, etc. is severely limited due to labor requirements and, oftentimes, expert domain knowledge. In this paper, we propose a deep learning based approach, named DeepStand, for image-based corn stand counting at early phenological stages. The proposed method adopts a truncated VGG-16 network as a backbone feature extractor and merges multiple feature maps with different scales to make the network robust against scale variation. Our extensive computational experiments suggest that our proposed method can successfully count corn stands and out-perform other state-of-the-art methods. It is the goal of our work to be used by the larger agricultural community as a way to enable high-throughput phenotyping without the use of extensive time and labor requirements.
Image-Based Sorghum Head Counting When You Only Look Once
Sep 28, 2020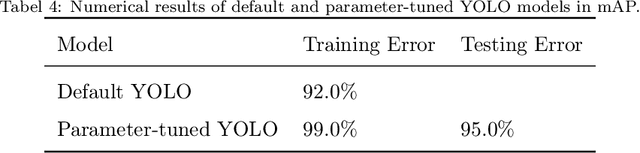
Modern trends in digital agriculture have seen a shift towards artificial intelligence for crop quality assessment and yield estimation. In this work, we document how a parameter tuned single-shot object detection algorithm can be used to identify and count sorghum head from aerial drone images. Our approach involves a novel exploratory analysis that identified key structural elements of the sorghum images and motivated the selection of parameter-tuned anchor boxes that contributed significantly to performance. These insights led to the development of a deep learning model that outperformed the baseline model and achieved an out-of-sample mean average precision of 0.95.
DeepCorn: A Semi-Supervised Deep Learning Method for High-Throughput Image-Based Corn Kernel Counting and Yield Estimation
Jul 20, 2020

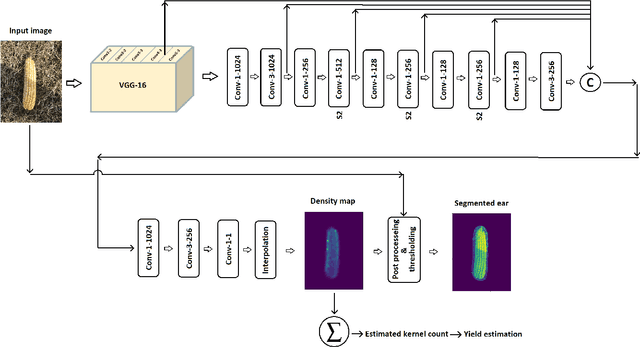
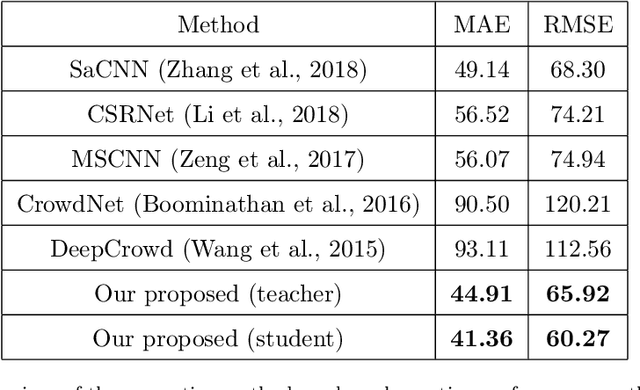
The success of modern farming and plant breeding relies on accurate and efficient collection of data. For a commercial organization that manages large amounts of crops, collecting accurate and consistent data is a bottleneck. Due to limited time and labor, accurately phenotyping crops to record color, head count, height, weight, etc. is severely limited. However, this information, combined with other genetic and environmental factors, is vital for developing new superior crop species that help feed the world's growing population. Recent advances in machine learning, in particular deep learning, have shown promise in mitigating this bottleneck. In this paper, we propose a novel deep learning method for counting on-ear corn kernels in-field to aid in the gathering of real-time data and, ultimately, to improve decision making to maximize yield. We name this approach DeepCorn, and show that this framework is robust under various conditions and can accurately and efficiently count corn kernels. We also adopt a semi-supervised learning approach to further improve the performance of our proposed method. Our experimental results demonstrate the superiority and effectiveness of our proposed method compared to other state-of-the-art methods.
Meta Pseudo Labels
Apr 23, 2020
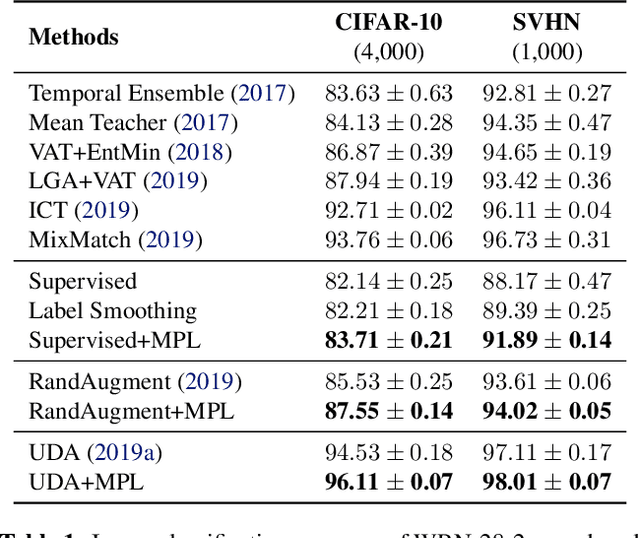

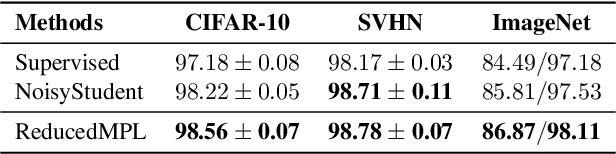
Many training algorithms of a deep neural network can be interpreted as minimizing the cross entropy loss between the prediction made by the network and a target distribution. In supervised learning, this target distribution is typically the ground-truth one-hot vector. In semi-supervised learning, this target distribution is typically generated by a pre-trained teacher model to train the main network. In this work, instead of using such predefined target distributions, we show that learning to adjust the target distribution based on the learning state of the main network can lead to better performances. In particular, we propose an efficient meta-learning algorithm, which encourages the teacher to adjust the target distributions of training examples in the manner that improves the learning of the main network. The teacher is updated by policy gradients computed by evaluating the main network on a held-out validation set. Our experiments demonstrate substantial improvements over strong baselines and establish state-ofthe-art performance on CIFAR-10, SVHN, and ImageNet. For instance, with ResNets on small datasets, we achieve 96.1% on CIFAR-10 with 4,000 labeled examples and 73.9% top-1 on ImageNet with 10% examples. Meanwhile, with EfficientNet on full datasets plus extra unlabeled data, we attain 98.6% accuracy on CIFAR-10 and 86.9% top-1 accuracy on ImageNet.
Convolutional Neural Networks for Image-based Corn Kernel Detection and Counting
Apr 20, 2020
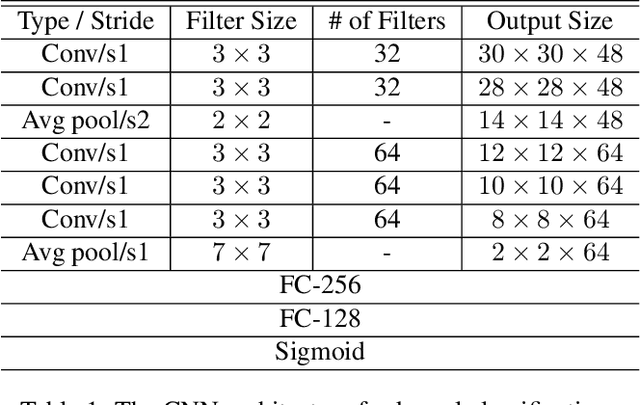
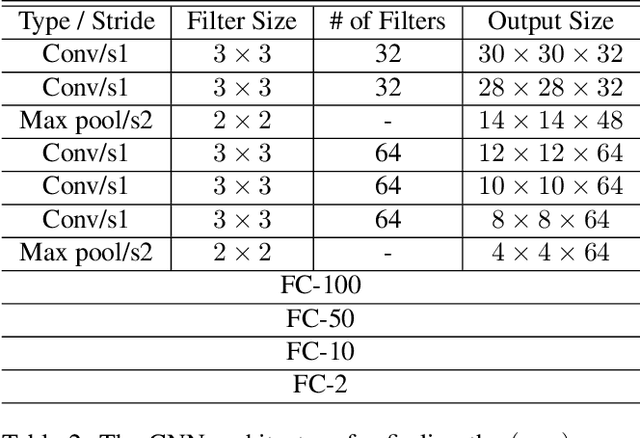

Precise in-season corn grain yield estimates enable farmers to make real-time accurate harvest and grain marketing decisions minimizing possible losses of profitability. A well developed corn ear can have up to 800 kernels, but manually counting the kernels on an ear of corn is labor-intensive, time consuming and prone to human error. From an algorithmic perspective, the detection of the kernels from a single corn ear image is challenging due to the large number of kernels at different angles and very small distance among the kernels. In this paper, we propose a kernel detection and counting method based on a sliding window approach. The proposed method detect and counts all corn kernels in a single corn ear image taken in uncontrolled lighting conditions. The sliding window approach uses a convolutional neural network (CNN) for kernel detection. Then, a non-maximum suppression (NMS) is applied to remove overlapping detections. Finally, windows that are classified as kernel are passed to another CNN regression model for finding the (x,y) coordinates of the center of kernel image patches. Our experiments indicate that the proposed method can successfully detect the corn kernels with a low detection error and is also able to detect kernels on a batch of corn ears positioned at different angles.
Optimizing Data Usage via Differentiable Rewards
Nov 22, 2019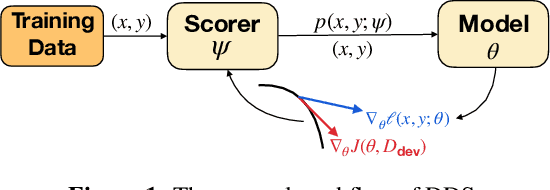
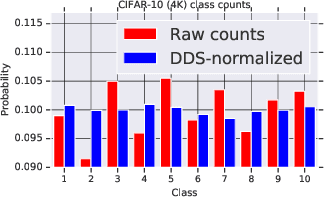

To acquire a new skill, humans learn better and faster if a tutor, based on their current knowledge level, informs them of how much attention they should pay to particular content or practice problems. Similarly, a machine learning model could potentially be trained better with a scorer that "adapts" to its current learning state and estimates the importance of each training data instance. Training such an adaptive scorer efficiently is a challenging problem; in order to precisely quantify the effect of a data instance at a given time during the training, it is typically necessary to first complete the entire training process. To efficiently optimize data usage, we propose a reinforcement learning approach called Differentiable Data Selection (DDS). In DDS, we formulate a scorer network as a learnable function of the training data, which can be efficiently updated along with the main model being trained. Specifically, DDS updates the scorer with an intuitive reward signal: it should up-weigh the data that has a similar gradient with a dev set upon which we would finally like to perform well. Without significant computing overhead, DDS delivers strong and consistent improvements over several strong baselines on two very different tasks of machine translation and image classification.
Optimizing Ensemble Weights and Hyperparameters of Machine Learning Models for Regression Problems
Sep 11, 2019Aggregating multiple learners through an ensemble of models aims to make better predictions by capturing the underlying distribution more accurately. Different ensembling methods, such as bagging, boosting and stacking/blending, have been studied and adopted extensively in research and practice. While bagging and boosting intend to reduce variance and bias, respectively, blending approaches target both by finding the optimal way to combine base learners to find the best trade-off between bias and variance. In blending, ensembles are created from weighted averages of multiple base learners. In this study, a systematic approach is proposed to find the optimal weights to create these ensembles for bias-variance tradeoff using cross-validation for regression problems (Cross-validated Optimal Weighted Ensemble (COWE)). Furthermore, it is known that tuning hyperparameters of each base learner inside the ensemble weight optimization process can produce better performing ensembles. To this end, a nested algorithm based on bi-level optimization that considers tuning hyperparameters as well as finding the optimal weights to combine ensembles (Cross-validated Optimal Weighted Ensemble with Internally Tuned Hyperparameters (COWE-ITH)) was proposed. The algorithm is shown to be generalizable to real data sets though analyses with ten publicly available data sets. The prediction accuracies of COWE-ITH and COWE have been compared to base learners and the state-of-art ensemble methods. The results show that COWE-ITH outperforms other benchmarks as well as base learners in 9 out of 10 data sets.
Multilingual Neural Machine Translation With Soft Decoupled Encoding
Feb 09, 2019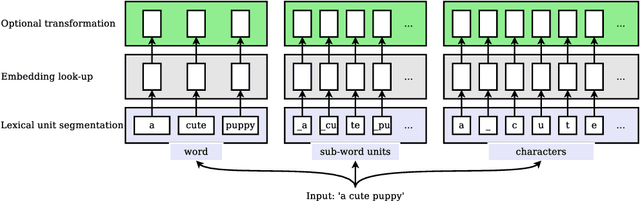


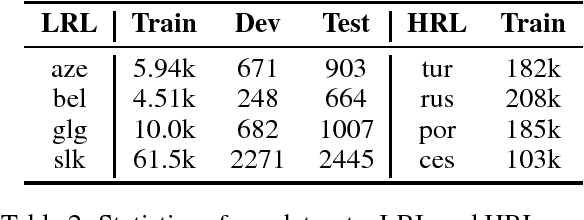
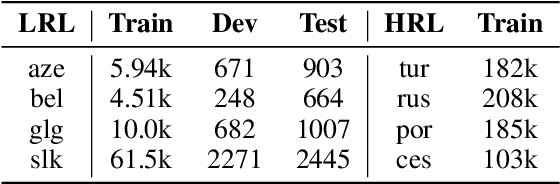
Multilingual training of neural machine translation (NMT) systems has led to impressive accuracy improvements on low-resource languages. However, there are still significant challenges in efficiently learning word representations in the face of paucity of data. In this paper, we propose Soft Decoupled Encoding (SDE), a multilingual lexicon encoding framework specifically designed to share lexical-level information intelligently without requiring heuristic preprocessing such as pre-segmenting the data. SDE represents a word by its spelling through a character encoding, and its semantic meaning through a latent embedding space shared by all languages. Experiments on a standard dataset of four low-resource languages show consistent improvements over strong multilingual NMT baselines, with gains of up to 2 BLEU on one of the tested languages, achieving the new state-of-the-art on all four language pairs.
A Tree-based Decoder for Neural Machine Translation
Aug 28, 2018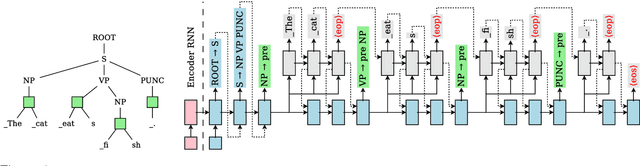
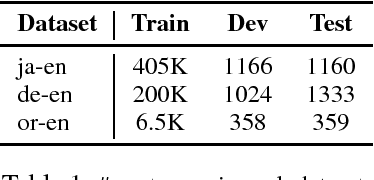
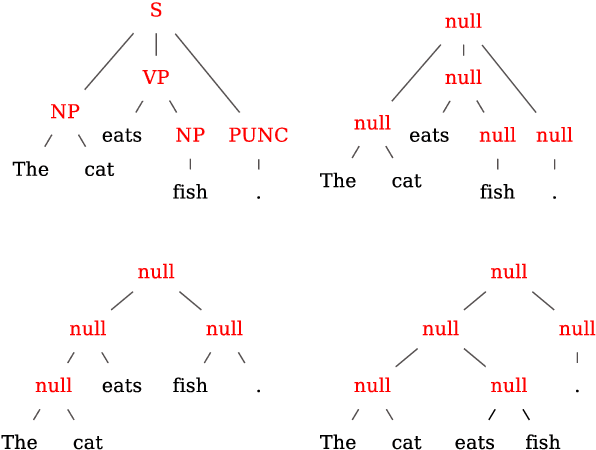
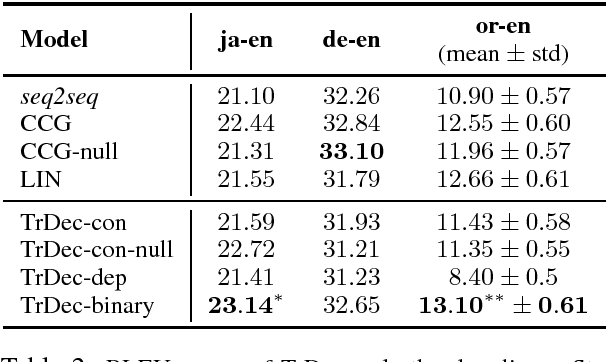
Recent advances in Neural Machine Translation (NMT) show that adding syntactic information to NMT systems can improve the quality of their translations. Most existing work utilizes some specific types of linguistically-inspired tree structures, like constituency and dependency parse trees. This is often done via a standard RNN decoder that operates on a linearized target tree structure. However, it is an open question of what specific linguistic formalism, if any, is the best structural representation for NMT. In this paper, we (1) propose an NMT model that can naturally generate the topology of an arbitrary tree structure on the target side, and (2) experiment with various target tree structures. Our experiments show the surprising result that our model delivers the best improvements with balanced binary trees constructed without any linguistic knowledge; this model outperforms standard seq2seq models by up to 2.1 BLEU points, and other methods for incorporating target-side syntax by up to 0.7 BLEU.
SwitchOut: an Efficient Data Augmentation Algorithm for Neural Machine Translation
Aug 28, 2018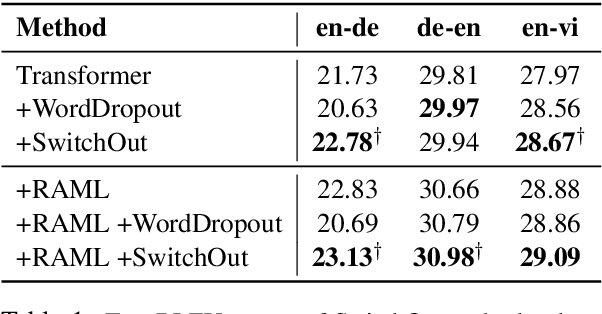
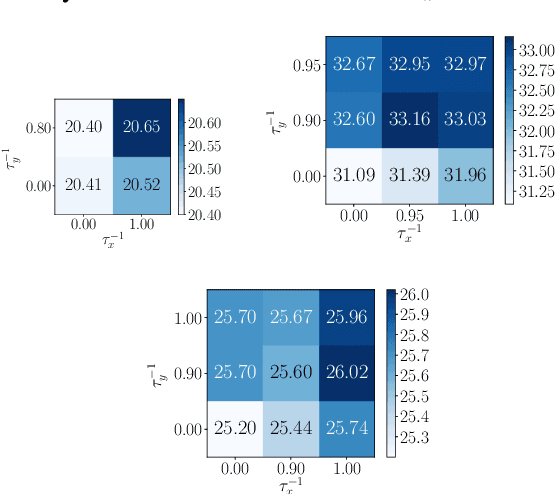
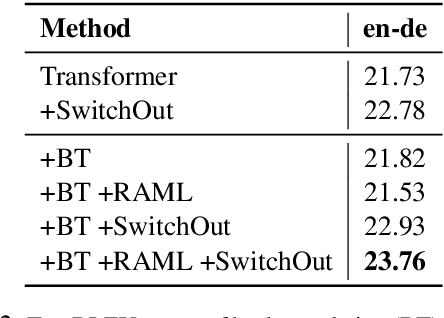
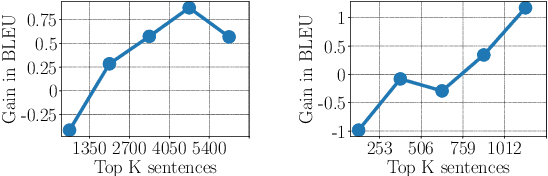
In this work, we examine methods for data augmentation for text-based tasks such as neural machine translation (NMT). We formulate the design of a data augmentation policy with desirable properties as an optimization problem, and derive a generic analytic solution. This solution not only subsumes some existing augmentation schemes, but also leads to an extremely simple data augmentation strategy for NMT: randomly replacing words in both the source sentence and the target sentence with other random words from their corresponding vocabularies. We name this method SwitchOut. Experiments on three translation datasets of different scales show that SwitchOut yields consistent improvements of about 0.5 BLEU, achieving better or comparable performances to strong alternatives such as word dropout (Sennrich et al., 2016a). Code to implement this method is included in the appendix.