 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved acoustic word embeddings for zero-resource languages using multilingual transfer
Jun 02, 2020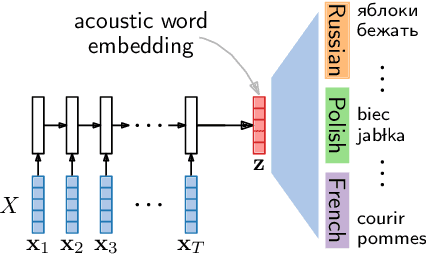
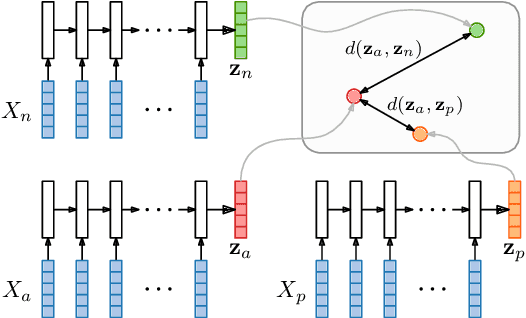
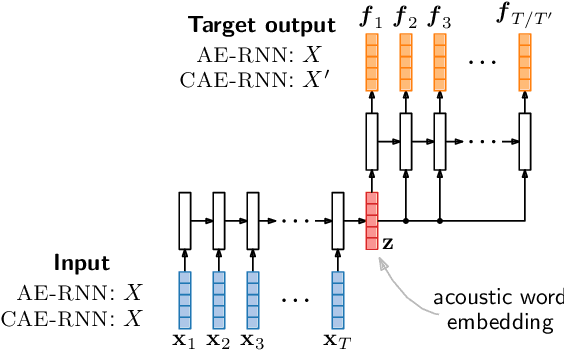
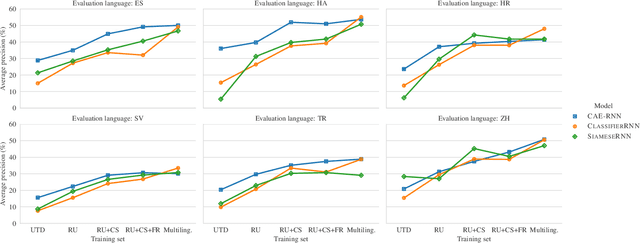
Acoustic word embeddings are fixed-dimensional representations of variable-length speech segments. Such embeddings can form the basis for speech search, indexing and discovery systems when conventional speech recognition is not possible. In zero-resource settings where unlabelled speech is the only available resource, we need a method that gives robust embeddings on an arbitrary language. Here we explore multilingual transfer: we train a single supervised embedding model on labelled data from multiple well-resourced languages and then apply it to unseen zero-resource languages. We consider three multilingual recurrent neural network (RNN) models: a classifier trained on the joint vocabularies of all training languages; a Siamese RNN trained to discriminate between same and different words from multiple languages; and a correspondence autoencoder (CAE) RNN trained to reconstruct word pairs. In a word discrimination task on six target languages, all of these models outperform state-of-the-art unsupervised models trained on the zero-resource languages themselves, giving relative improvements of more than 30% in average precision. When using only a few training languages, the multilingual CAE performs better, but with more training languages the other multilingual models perform similarly. Using more training languages is generally beneficial, but improvements are marginal on some languages. We present probing experiments which show that the CAE encodes more phonetic, word duration, language identity and speaker information than the other multilingual models.
Vector-quantized neural networks for acoustic unit discovery in the ZeroSpeech 2020 challenge
May 19, 2020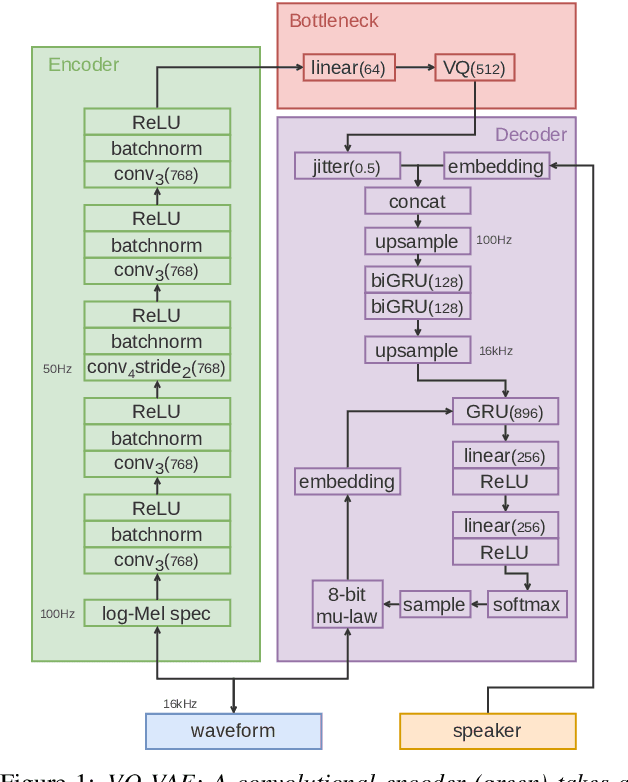
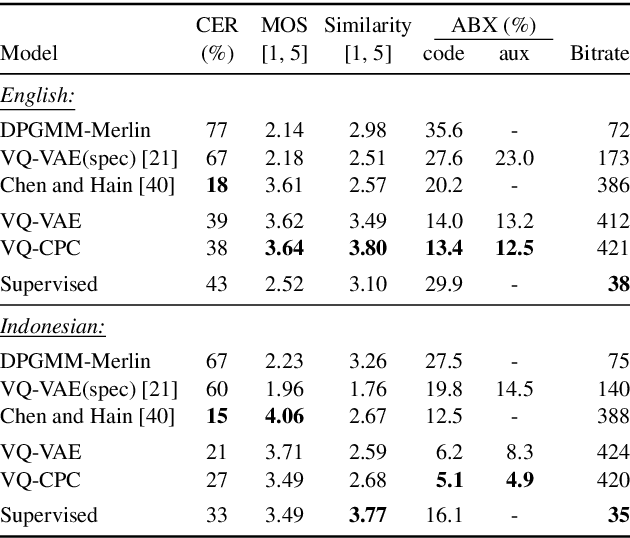
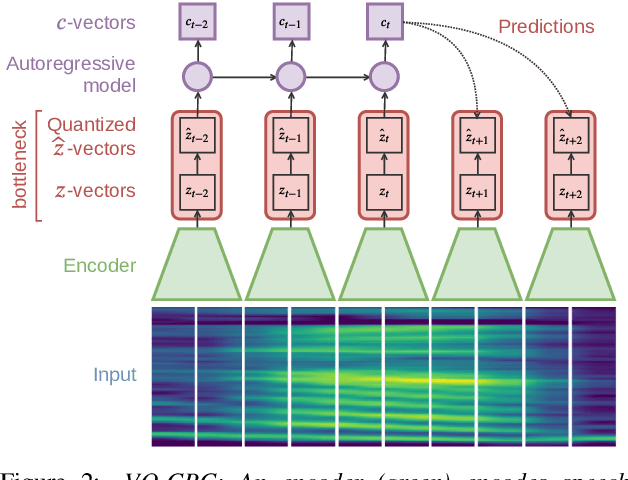
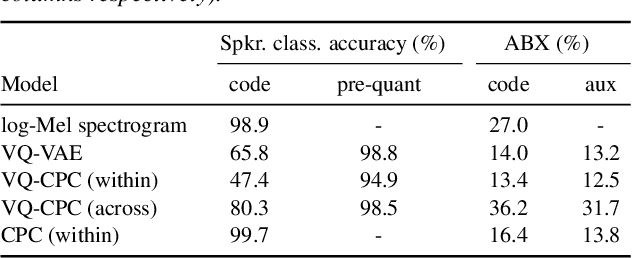
In this paper, we explore vector quantization for acoustic unit discovery. Leveraging unlabelled data, we aim to learn discrete representations of speech that separate phonetic content from speaker-specific details. We propose two neural models to tackle this challenge. Both models use vector quantization to map continuous features to a finite set of codes. The first model is a type of vector-quantized variational autoencoder (VQ-VAE). The VQ-VAE encodes speech into a discrete representation from which the audio waveform is reconstructed. Our second model combines vector quantization with contrastive predictive coding (VQ-CPC). The idea is to learn a representation of speech by predicting future acoustic units. We evaluate the models on English and Indonesian data for the ZeroSpeech 2020 challenge. In ABX phone discrimination tests, both models outperform all submissions to the 2019 and 2020 challenges, with a relative improvement of more than 30%. The discovered units also perform competitively on a downstream voice conversion task. Of the two models, VQ-CPC performs slightly better in general and is simpler and faster to train. Probing experiments show that vector quantization is an effective bottleneck, forcing the models to discard speaker information.
Analyzing autoencoder-based acoustic word embeddings
Apr 03, 2020
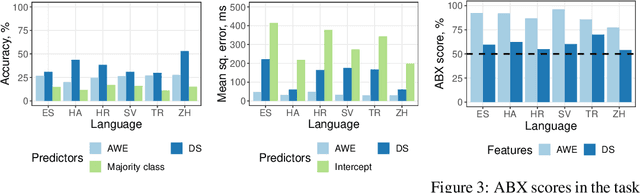
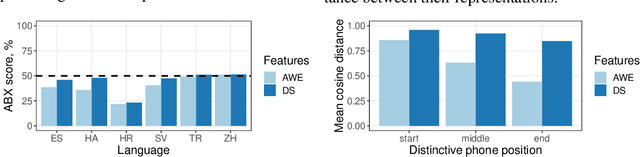
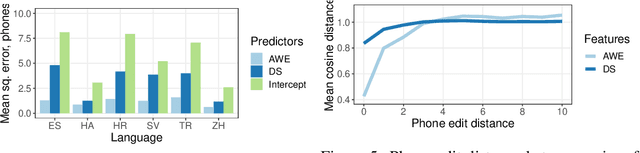
Recent studies have introduced methods for learning acoustic word embeddings (AWEs)---fixed-size vector representations of words which encode their acoustic features. Despite the widespread use of AWEs in speech processing research, they have only been evaluated quantitatively in their ability to discriminate between whole word tokens. To better understand the applications of AWEs in various downstream tasks and in cognitive modeling, we need to analyze the representation spaces of AWEs. Here we analyze basic properties of AWE spaces learned by a sequence-to-sequence encoder-decoder model in six typologically diverse languages. We first show that these AWEs preserve some information about words' absolute duration and speaker. At the same time, the representation space of these AWEs is organized such that the distance between words' embeddings increases with those words' phonetic dissimilarity. Finally, the AWEs exhibit a word onset bias, similar to patterns reported in various studies on human speech processing and lexical access. We argue this is a promising result and encourage further evaluation of AWEs as a potentially useful tool in cognitive science, which could provide a link between speech processing and lexical memory.
Unsupervised feature learning for speech using correspondence and Siamese networks
Mar 28, 2020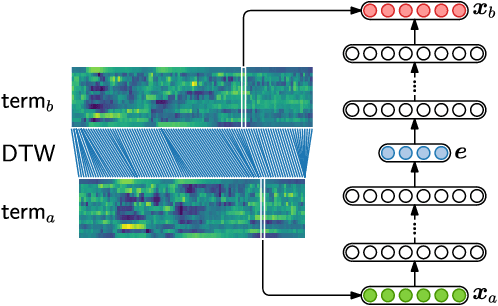
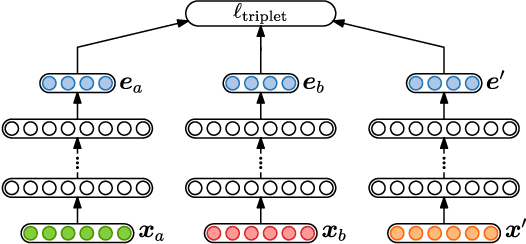
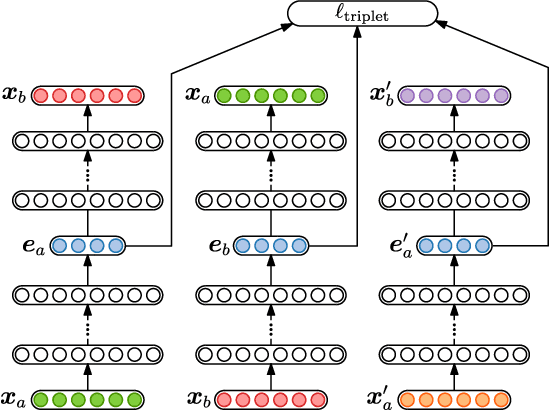
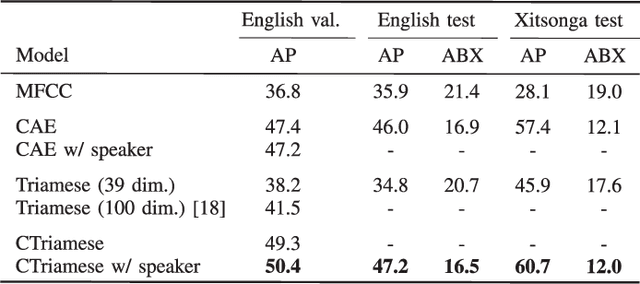
In zero-resource settings where transcribed speech audio is unavailable, unsupervised feature learning is essential for downstream speech processing tasks. Here we compare two recent methods for frame-level acoustic feature learning. For both methods, unsupervised term discovery is used to find pairs of word examples of the same unknown type. Dynamic programming is then used to align the feature frames between each word pair, serving as weak top-down supervision for the two models. For the correspondence autoencoder (CAE), matching frames are presented as input-output pairs. The Triamese network uses a contrastive loss to reduce the distance between frames of the same predicted word type while increasing the distance between negative examples. For the first time, these feature extractors are compared on the same discrimination tasks using the same weak supervision pairs. We find that, on the two datasets considered here, the CAE outperforms the Triamese network. However, we show that a new hybrid correspondence-Triamese approach (CTriamese), consistently outperforms both the CAE and Triamese models in terms of average precision and ABX error rates on both English and Xitsonga evaluation data.
* 5 pages, 3 figures, 2 tables; accepted to the IEEE Signal Processing Letters, (c) 2020 IEEE
Masakhane -- Machine Translation For Africa
Mar 13, 2020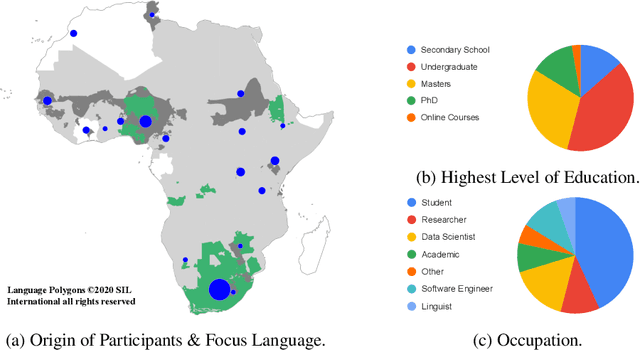
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
Multilingual acoustic word embedding models for processing zero-resource languages
Feb 21, 2020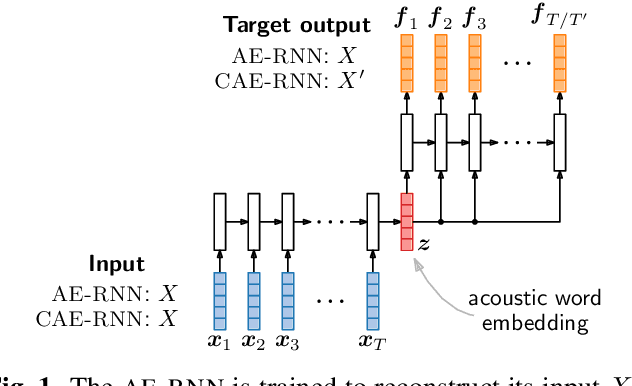
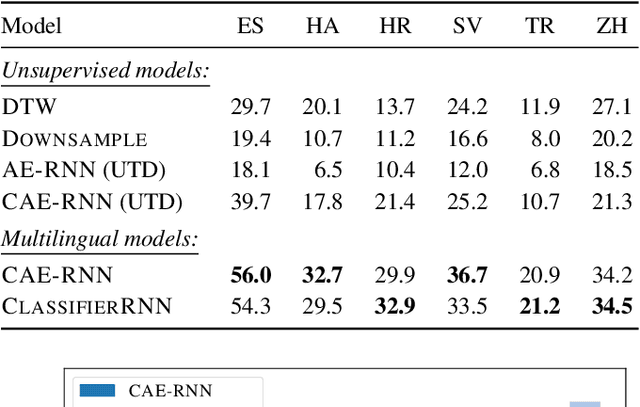
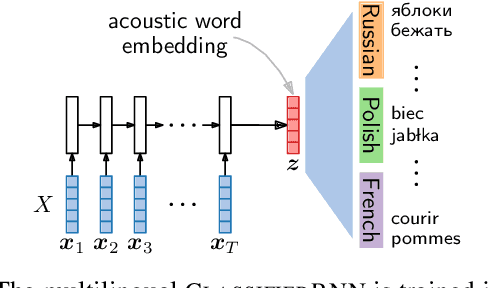
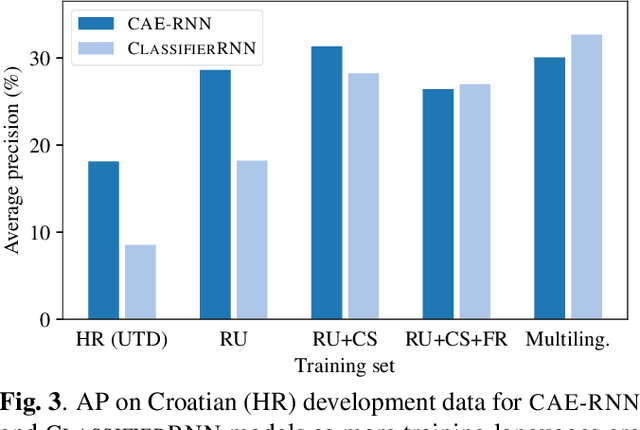
Acoustic word embeddings are fixed-dimensional representations of variable-length speech segments. In settings where unlabelled speech is the only available resource, such embeddings can be used in "zero-resource" speech search, indexing and discovery systems. Here we propose to train a single supervised embedding model on labelled data from multiple well-resourced languages and then apply it to unseen zero-resource languages. For this transfer learning approach, we consider two multilingual recurrent neural network models: a discriminative classifier trained on the joint vocabularies of all training languages, and a correspondence autoencoder trained to reconstruct word pairs. We test these using a word discrimination task on six target zero-resource languages. When trained on seven well-resourced languages, both models perform similarly and outperform unsupervised models trained on the zero-resource languages. With just a single training language, the second model works better, but performance depends more on the particular training--testing language pair.
Deep motion estimation for parallel inter-frame prediction in video compression
Dec 11, 2019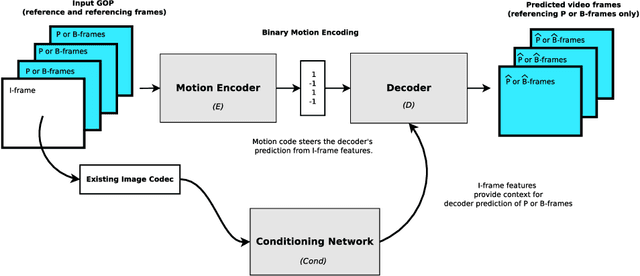
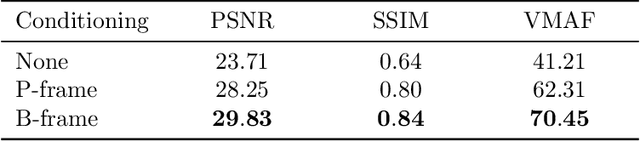
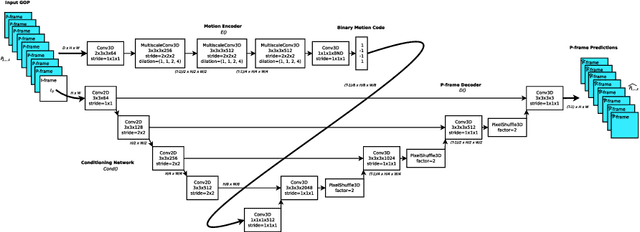

Standard video codecs rely on optical flow to guide inter-frame prediction: pixels from reference frames are moved via motion vectors to predict target video frames. We propose to learn binary motion codes that are encoded based on an input video sequence. These codes are not limited to 2D translations, but can capture complex motion (warping, rotation and occlusion). Our motion codes are learned as part of a single neural network which also learns to compress and decode them. This approach supports parallel video frame decoding instead of the sequential motion estimation and compensation of flow-based methods. We also introduce 3D dynamic bit assignment to adapt to object displacements caused by motion, yielding additional bit savings. By replacing the optical flow-based block-motion algorithms found in an existing video codec with our learned inter-frame prediction model, our approach outperforms the standard H.264 and H.265 video codecs across at low bitrates.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019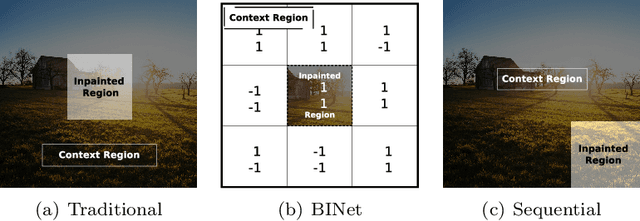

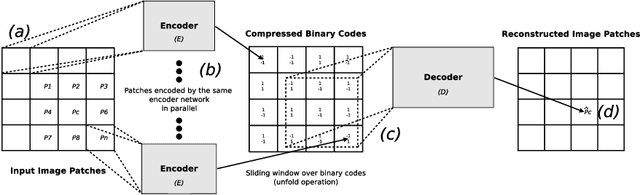

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.
If dropout limits trainable depth, does critical initialisation still matter? A large-scale statistical analysis on ReLU networks
Oct 13, 2019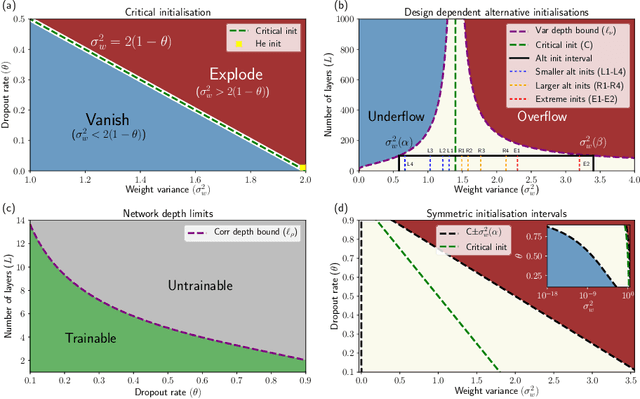

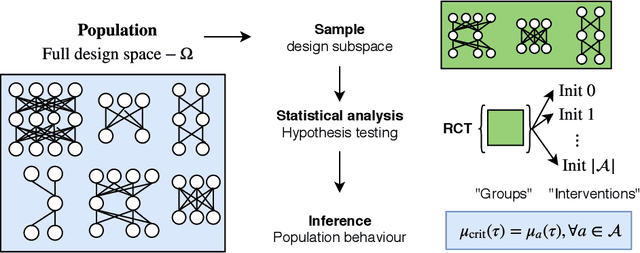
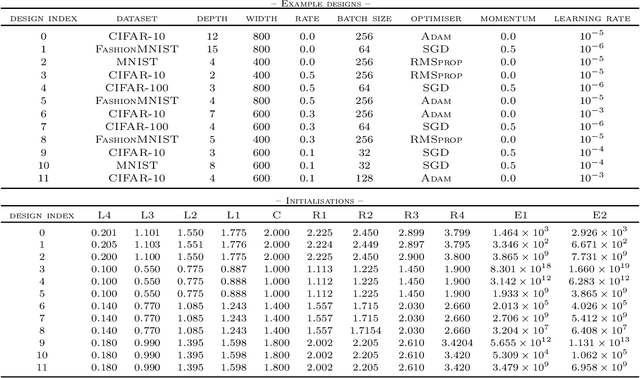
Recent work in signal propagation theory has shown that dropout limits the depth to which information can propagate through a neural network. In this paper, we investigate the effect of initialisation on training speed and generalisation for ReLU networks within this depth limit. We ask the following research question: given that critical initialisation is crucial for training at large depth, if dropout limits the depth at which networks are trainable, does initialising critically still matter? We conduct a large-scale controlled experiment, and perform a statistical analysis of over $12000$ trained networks. We find that (1) trainable networks show no statistically significant difference in performance over a wide range of non-critical initialisations; (2) for initialisations that show a statistically significant difference, the net effect on performance is small; (3) only extreme initialisations (very small or very large) perform worse than criticality. These findings also apply to standard ReLU networks of moderate depth as a special case of zero dropout. Our results therefore suggest that, in the shallow-to-moderate depth setting, critical initialisation provides zero performance gains when compared to off-critical initialisations and that searching for off-critical initialisations that might improve training speed or generalisation, is likely to be a fruitless endeavour.
On the expected behaviour of noise regularised deep neural networks as Gaussian processes
Oct 12, 2019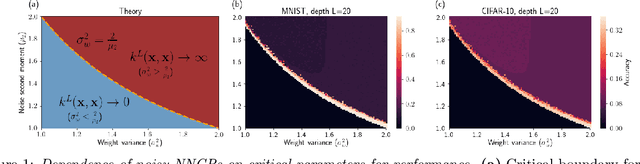
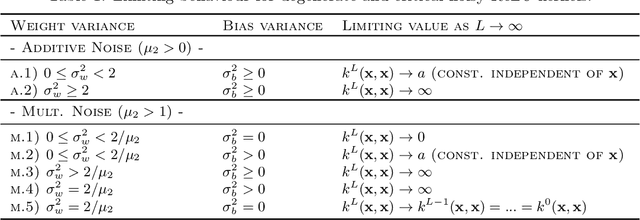
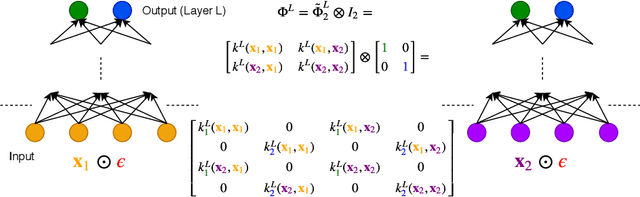
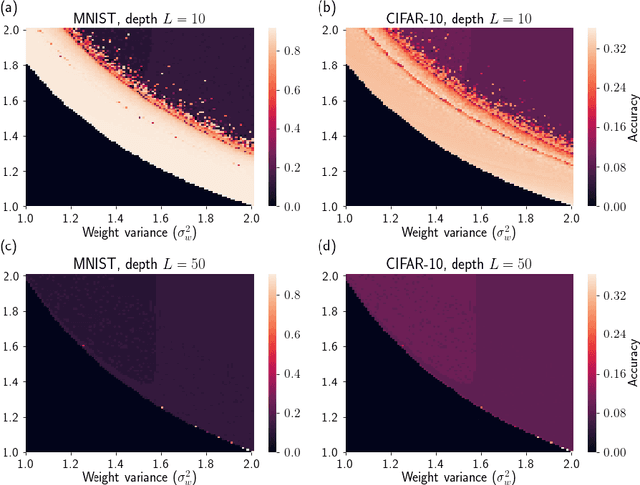
Recent work has established the equivalence between deep neural networks and Gaussian processes (GPs), resulting in so-called neural network Gaussian processes (NNGPs). The behaviour of these models depends on the initialisation of the corresponding network. In this work, we consider the impact of noise regularisation (e.g. dropout) on NNGPs, and relate their behaviour to signal propagation theory in noise regularised deep neural networks. For ReLU activations, we find that the best performing NNGPs have kernel parameters that correspond to a recently proposed initialisation scheme for noise regularised ReLU networks. In addition, we show how the noise influences the covariance matrix of the NNGP, producing a stronger prior towards simple functions away from the training points. We verify our theoretical findings with experiments on MNIST and CIFAR-10 as well as on synthetic data.