 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAIT: A Syntactic Parsing Toolkit for Child-Adult InTeractions
May 19, 2026CHILDES is a paramount resource for language acquisition studies -- yet computational tools for analyzing its syntactic structure remain limited. Leveraging the recent release of the UD-English-CHILDES treebank with gold-standard Universal Dependencies (UD) annotations, we train a state-of-the-art dependency parser specifically tailored to CHILDES. The parser more accurately captures syntactic patterns in child--adult interactions, outperforming widely used off-the-shelf English parsers, including SpaCy and Stanza. Alongside the parser, we also release a Part-of-Speech tagger and an utterance-level construction tagger, which together form the open-source Syntactic Parsing Toolkit for Child--Adult InTeractions (CAIT). Through a detailed error analysis and a case study tracking the distribution of syntactic constructions across developmental time in CHILDES, we demonstrate the practical utility of the toolkit for large-scale, reproducible research on language acquisition.
Is Child-Directed Language Optimized for Word Learning? A Computational Study of Verb Meaning Acquisition
May 12, 2026Is child-directed language (CDL) optimized to support language learning, and which aspects of linguistic development does it facilitate? We investigate this question using neural language models trained on CDL versus adult-directed language (ADL). We selectively remove syntactic or lexical co-occurrence information from the model training data, and evaluate the impact of these manipulations on verb meaning acquisition. While disrupting syntax impairs learning across all datasets, models trained on CDL and spoken ADL show significantly higher resilience than those trained on written input. Tracking semantic and syntactic performance over training, we observe a semantic-first trajectory, with verb meanings emerging prior to robust syntactic proficiency, an asynchrony most pronounced in the spoken domain, especially CDL. These results suggest that the advantage for verb learning previously attributed to CDL may instead reflect broader properties of the spoken register, rather than a uniquely CDL-specific optimization.
The mutual exclusivity bias of bilingual visually grounded speech models
Jun 04, 2025Mutual exclusivity (ME) is a strategy where a novel word is associated with a novel object rather than a familiar one, facilitating language learning in children. Recent work has found an ME bias in a visually grounded speech (VGS) model trained on English speech with paired images. But ME has also been studied in bilingual children, who may employ it less due to cross-lingual ambiguity. We explore this pattern computationally using bilingual VGS models trained on combinations of English, French, and Dutch. We find that bilingual models generally exhibit a weaker ME bias than monolingual models, though exceptions exist. Analyses show that the combined visual embeddings of bilingual models have a smaller variance for familiar data, partly explaining the increase in confusion between novel and familiar concepts. We also provide new insights into why the ME bias exists in VGS models in the first place. Code and data: https://github.com/danoneata/me-vgs
Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
May 29, 2025Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of adult-directed written text, suggesting that CDL could provide more effective LM training material than the commonly used internet-crawled data. However, the generalizability of these results across languages, model types, and evaluation settings remains unclear. We test this by comparing models trained on CDL vs. Wikipedia across two LM objectives (masked and causal), three languages (English, French, German), and three syntactic minimal-pair benchmarks. Our results on these benchmarks show inconsistent benefits of CDL, which in most cases is outperformed by Wikipedia models. We then identify various shortcomings in previous benchmarks, and introduce a novel testing methodology, FIT-CLAMS, which uses a frequency-controlled design to enable balanced comparisons across training corpora. Through minimal pair evaluations and regression analysis we show that training on CDL does not yield stronger generalizations for acquiring syntax and highlight the importance of controlling for frequency effects when evaluating syntactic ability.
Generating Completions for Fragmented Broca's Aphasic Sentences Using Large Language Models
Dec 23, 2024Broca's aphasia is a type of aphasia characterized by non-fluent, effortful and fragmented speech production with relatively good comprehension. Since traditional aphasia treatment methods are often time-consuming, labour-intensive, and do not reflect real-world conversations, applying natural language processing based approaches such as Large Language Models (LLMs) could potentially contribute to improving existing treatment approaches. To address this issue, we explore the use of sequence-to-sequence LLMs for completing fragmented Broca's aphasic sentences. We first generate synthetic Broca's aphasic data using a rule-based system designed to mirror the linguistic characteristics of Broca's aphasic speech. Using this synthetic data, we then fine-tune four pre-trained LLMs on the task of completing fragmented sentences. We evaluate our fine-tuned models on both synthetic and authentic Broca's aphasic data. We demonstrate LLMs' capability for reconstructing fragmented sentences, with the models showing improved performance with longer input utterances. Our result highlights the LLMs' potential in advancing communication aids for individuals with Broca's aphasia and possibly other clinical populations.
Choosy Babies Need One Coach: Inducing Mode-Seeking Behavior in BabyLlama with Reverse KL Divergence
Oct 29, 2024


This study presents our submission to the Strict-Small Track of the 2nd BabyLM Challenge. We use a teacher-student distillation setup with the BabyLLaMa model (Timiryasov and Tastet, 2023) as a backbone. To make the student's learning process more focused, we replace the objective function with a reverse Kullback-Leibler divergence, known to cause mode-seeking (rather than mode-averaging) behaviour in computational learners. We further experiment with having a single teacher (instead of an ensemble of two teachers) and implement additional optimization strategies to improve the distillation process. Our experiments show that under reverse KL divergence, a single-teacher model often outperforms or matches multiple-teacher models across most tasks. Additionally, incorporating advanced optimization techniques further enhances model performance, demonstrating the effectiveness and robustness of our proposed approach. These findings support our idea that "choosy babies need one coach".
Visually Grounded Speech Models have a Mutual Exclusivity Bias
Mar 20, 2024When children learn new words, they employ constraints such as the mutual exclusivity (ME) bias: a novel word is mapped to a novel object rather than a familiar one. This bias has been studied computationally, but only in models that use discrete word representations as input, ignoring the high variability of spoken words. We investigate the ME bias in the context of visually grounded speech models that learn from natural images and continuous speech audio. Concretely, we train a model on familiar words and test its ME bias by asking it to select between a novel and a familiar object when queried with a novel word. To simulate prior acoustic and visual knowledge, we experiment with several initialisation strategies using pretrained speech and vision networks. Our findings reveal the ME bias across the different initialisation approaches, with a stronger bias in models with more prior (in particular, visual) knowledge. Additional tests confirm the robustness of our results, even when different loss functions are considered.
Acoustic word embeddings for zero-resource languages using self-supervised contrastive learning and multilingual adaptation
Mar 19, 2021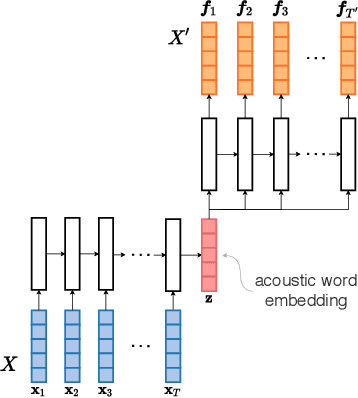
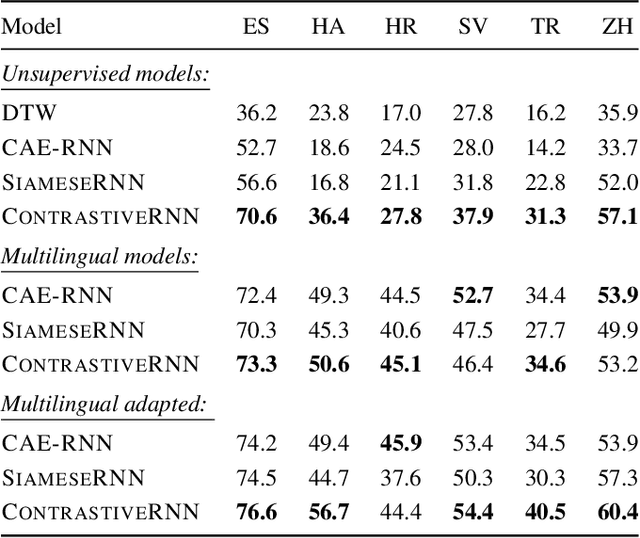
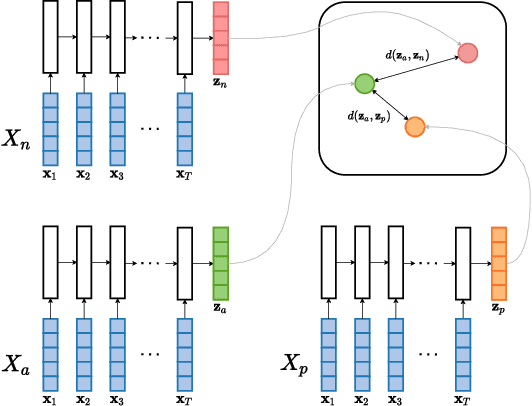
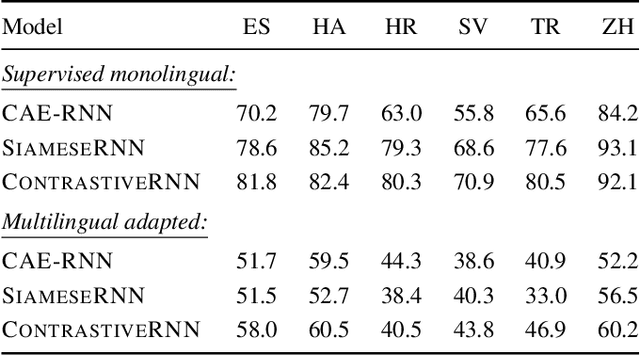
Acoustic word embeddings (AWEs) are fixed-dimensional representations of variable-length speech segments. For zero-resource languages where labelled data is not available, one AWE approach is to use unsupervised autoencoder-based recurrent models. Another recent approach is to use multilingual transfer: a supervised AWE model is trained on several well-resourced languages and then applied to an unseen zero-resource language. We consider how a recent contrastive learning loss can be used in both the purely unsupervised and multilingual transfer settings. Firstly, we show that terms from an unsupervised term discovery system can be used for contrastive self-supervision, resulting in improvements over previous unsupervised monolingual AWE models. Secondly, we consider how multilingual AWE models can be adapted to a specific zero-resource language using discovered terms. We find that self-supervised contrastive adaptation outperforms adapted multilingual correspondence autoencoder and Siamese AWE models, giving the best overall results in a word discrimination task on six zero-resource languages.
A phonetic model of non-native spoken word processing
Jan 27, 2021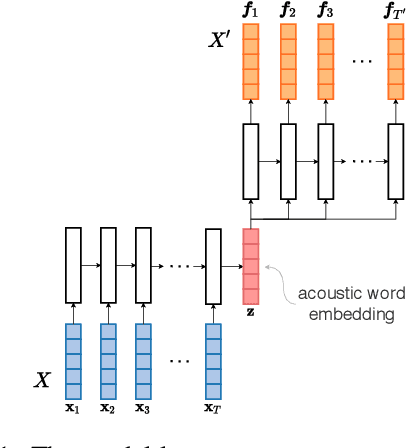
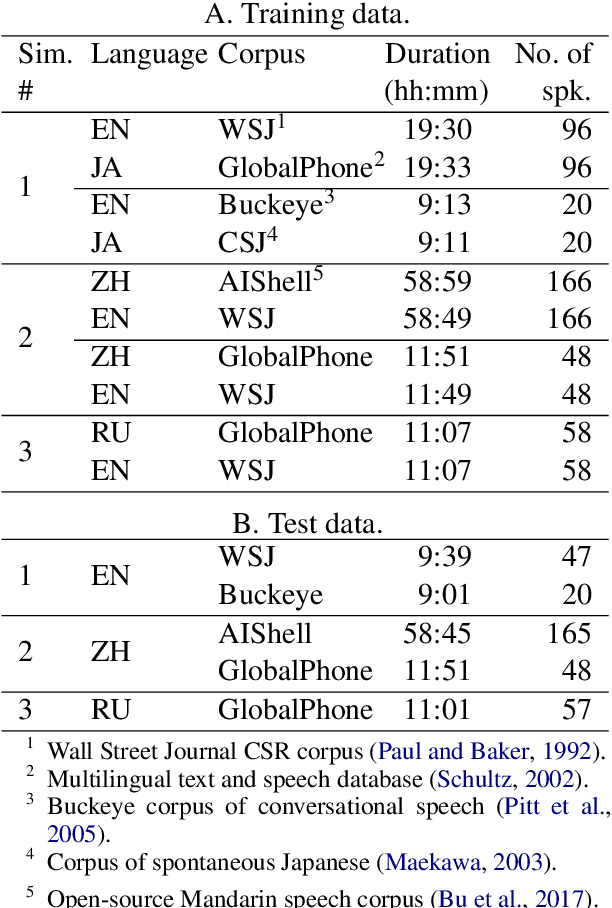
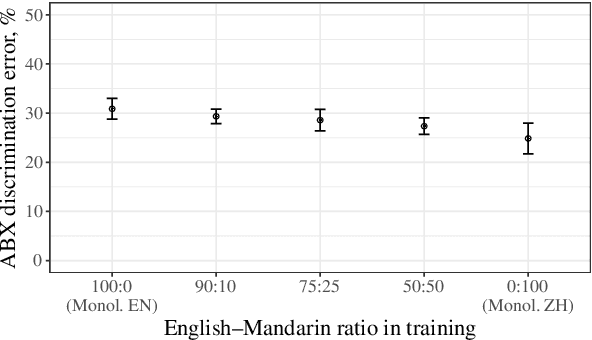
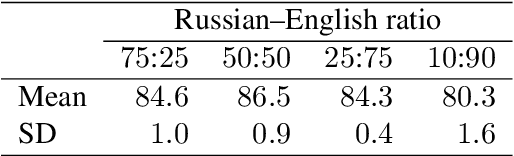
Non-native speakers show difficulties with spoken word processing. Many studies attribute these difficulties to imprecise phonological encoding of words in the lexical memory. We test an alternative hypothesis: that some of these difficulties can arise from the non-native speakers' phonetic perception. We train a computational model of phonetic learning, which has no access to phonology, on either one or two languages. We first show that the model exhibits predictable behaviors on phone-level and word-level discrimination tasks. We then test the model on a spoken word processing task, showing that phonology may not be necessary to explain some of the word processing effects observed in non-native speakers. We run an additional analysis of the model's lexical representation space, showing that the two training languages are not fully separated in that space, similarly to the languages of a bilingual human speaker.
Evaluating computational models of infant phonetic learning across languages
Aug 06, 2020



In the first year of life, infants' speech perception becomes attuned to the sounds of their native language. Many accounts of this early phonetic learning exist, but computational models predicting the attunement patterns observed in infants from the speech input they hear have been lacking. A recent study presented the first such model, drawing on algorithms proposed for unsupervised learning from naturalistic speech, and tested it on a single phone contrast. Here we study five such algorithms, selected for their potential cognitive relevance. We simulate phonetic learning with each algorithm and perform tests on three phone contrasts from different languages, comparing the results to infants' discrimination patterns. The five models display varying degrees of agreement with empirical observations, showing that our approach can help decide between candidate mechanisms for early phonetic learning, and providing insight into which aspects of the models are critical for capturing infants' perceptual development.
* 7 pages, 1 figure