 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of AI Ethics Tools in Language Models: A Developers' Perspective Case Stud
Dec 16, 2025



In Artificial Intelligence (AI), language models have gained significant importance due to the widespread adoption of systems capable of simulating realistic conversations with humans through text generation. Because of their impact on society, developing and deploying these language models must be done responsibly, with attention to their negative impacts and possible harms. In this scenario, the number of AI Ethics Tools (AIETs) publications has recently increased. These AIETs are designed to help developers, companies, governments, and other stakeholders establish trust, transparency, and responsibility with their technologies by bringing accepted values to guide AI's design, development, and use stages. However, many AIETs lack good documentation, examples of use, and proof of their effectiveness in practice. This paper presents a methodology for evaluating AIETs in language models. Our approach involved an extensive literature survey on 213 AIETs, and after applying inclusion and exclusion criteria, we selected four AIETs: Model Cards, ALTAI, FactSheets, and Harms Modeling. For evaluation, we applied AIETs to language models developed for the Portuguese language, conducting 35 hours of interviews with their developers. The evaluation considered the developers' perspective on the AIETs' use and quality in helping to identify ethical considerations about their model. The results suggest that the applied AIETs serve as a guide for formulating general ethical considerations about language models. However, we note that they do not address unique aspects of these models, such as idiomatic expressions. Additionally, these AIETs did not help to identify potential negative impacts of models for the Portuguese language.
Yet another algorithmic bias: A Discursive Analysis of Large Language Models Reinforcing Dominant Discourses on Gender and Race
Aug 14, 2025With the advance of Artificial Intelligence (AI), Large Language Models (LLMs) have gained prominence and been applied in diverse contexts. As they evolve into more sophisticated versions, it is essential to assess whether they reproduce biases, such as discrimination and racialization, while maintaining hegemonic discourses. Current bias detection approaches rely mostly on quantitative, automated methods, which often overlook the nuanced ways in which biases emerge in natural language. This study proposes a qualitative, discursive framework to complement such methods. Through manual analysis of LLM-generated short stories featuring Black and white women, we investigate gender and racial biases. We contend that qualitative methods such as the one proposed here are fundamental to help both developers and users identify the precise ways in which biases manifest in LLM outputs, thus enabling better conditions to mitigate them. Results show that Black women are portrayed as tied to ancestry and resistance, while white women appear in self-discovery processes. These patterns reflect how language models replicate crystalized discursive representations, reinforcing essentialization and a sense of social immobility. When prompted to correct biases, models offered superficial revisions that maintained problematic meanings, revealing limitations in fostering inclusive narratives. Our results demonstrate the ideological functioning of algorithms and have significant implications for the ethical use and development of AI. The study reinforces the need for critical, interdisciplinary approaches to AI design and deployment, addressing how LLM-generated discourses reflect and perpetuate inequalities.
FairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024



Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.
CAPIVARA: Cost-Efficient Approach for Improving Multilingual CLIP Performance on Low-Resource Languages
Oct 23, 2023



This work introduces CAPIVARA, a cost-efficient framework designed to enhance the performance of multilingual CLIP models in low-resource languages. While CLIP has excelled in zero-shot vision-language tasks, the resource-intensive nature of model training remains challenging. Many datasets lack linguistic diversity, featuring solely English descriptions for images. CAPIVARA addresses this by augmenting text data using image captioning and machine translation to generate multiple synthetic captions in low-resource languages. We optimize the training pipeline with LiT, LoRA, and gradient checkpointing to alleviate the computational cost. Through extensive experiments, CAPIVARA emerges as state of the art in zero-shot tasks involving images and Portuguese texts. We show the potential for significant improvements in other low-resource languages, achieved by fine-tuning the pre-trained multilingual CLIP using CAPIVARA on a single GPU for 2 hours. Our model and code is available at https://github.com/hiaac-nlp/CAPIVARA.
Weakly Supervised Attention-based Models Using Activation Maps for Citrus Mite and Insect Pest Classification
Oct 02, 2021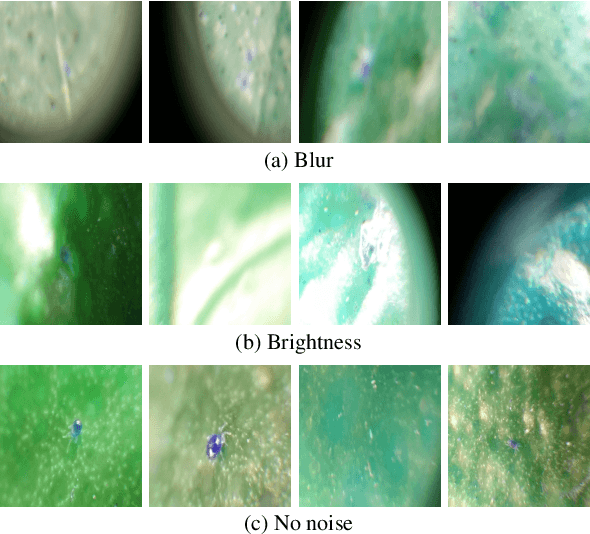
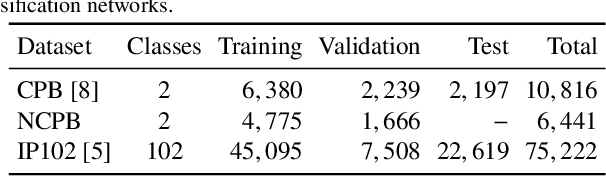

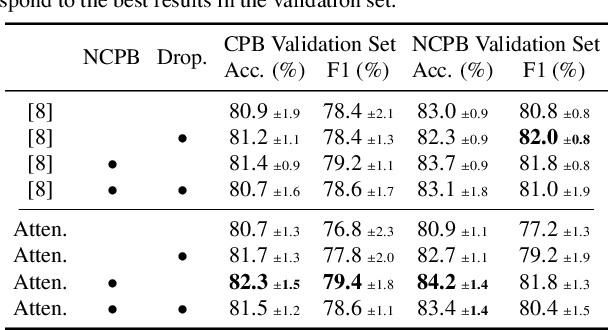
Citrus juices and fruits are commodities with great economic potential in the international market, but productivity losses caused by mites and other pests are still far from being a good mark. Despite the integrated pest mechanical aspect, only a few works on automatic classification have handled images with orange mite characteristics, which means tiny and noisy regions of interest. On the computational side, attention-based models have gained prominence in deep learning research, and, along with weakly supervised learning algorithms, they have improved tasks performed with some label restrictions. In agronomic research of pests and diseases, these techniques can improve classification performance while pointing out the location of mites and insects without specific labels, reducing deep learning development costs related to generating bounding boxes. In this context, this work proposes an attention-based activation map approach developed to improve the classification of tiny regions called Two-Weighted Activation Mapping, which also produces locations using feature map scores learned from class labels. We apply our method in a two-stage network process called Attention-based Multiple Instance Learning Guided by Saliency Maps. We analyze the proposed approach in two challenging datasets, the Citrus Pest Benchmark, which was captured directly in the field using magnifying glasses, and the Insect Pest, a large pest image benchmark. In addition, we evaluate and compare our models with weakly supervised methods, such as Attention-based Deep MIL and WILDCAT. The results show that our classifier is superior to literature methods that use tiny regions in their classification tasks, surpassing them in all scenarios by at least 16 percentage points. Moreover, our approach infers bounding box locations for salient insects, even training without any location labels.