 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Activation Network and Functional Regularization for Efficient and Flexible Deep Multi-Task Learning
Nov 19, 2019
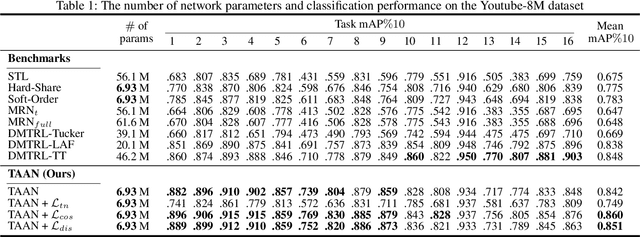
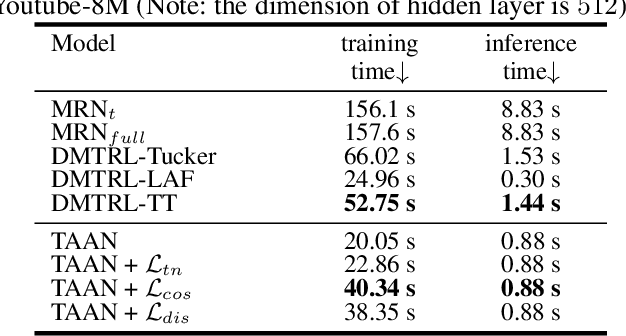
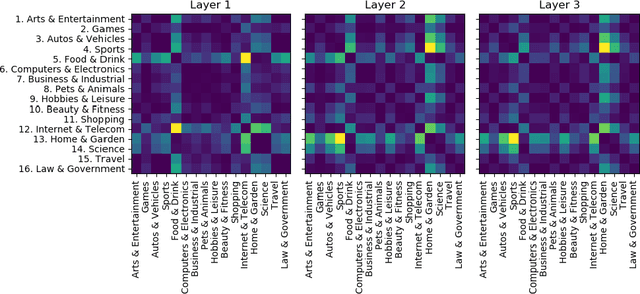
Multi-task learning (MTL) is a common paradigm that seeks to improve the generalization performance of task learning by training related tasks simultaneously. However, it is still a challenging problem to search the flexible and accurate architecture that can be shared among multiple tasks. In this paper, we propose a novel deep learning model called Task Adaptive Activation Network (TAAN) that can automatically learn the optimal network architecture for MTL. The main principle of TAAN is to derive flexible activation functions for different tasks from the data with other parameters of the network fully shared. We further propose two functional regularization methods that improve the MTL performance of TAAN. The improved performance of both TAAN and the regularization methods is demonstrated by comprehensive experiments.
Temporally Coherent Video Harmonization Using Adversarial Networks
Sep 05, 2018
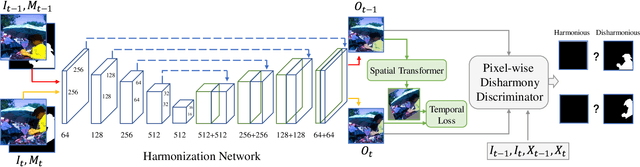


Compositing is one of the most important editing operations for images and videos. The process of improving the realism of composite results is often called harmonization. Previous approaches for harmonization mainly focus on images. In this work, we take one step further to attack the problem of video harmonization. Specifically, we train a convolutional neural network in an adversarial way, exploiting a pixel-wise disharmony discriminator to achieve more realistic harmonized results and introducing a temporal loss to increase temporal consistency between consecutive harmonized frames. Thanks to the pixel-wise disharmony discriminator, we are also able to relieve the need of input foreground masks. Since existing video datasets which have ground-truth foreground masks and optical flows are not sufficiently large, we propose a simple yet efficient method to build up a synthetic dataset supporting supervised training of the proposed adversarial network. Experiments show that training on our synthetic dataset generalizes well to the real-world composite dataset. Also, our method successfully incorporates temporal consistency during training and achieves more harmonious results than previous methods.
Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks
Jul 28, 2018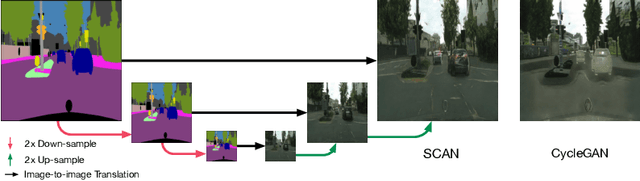
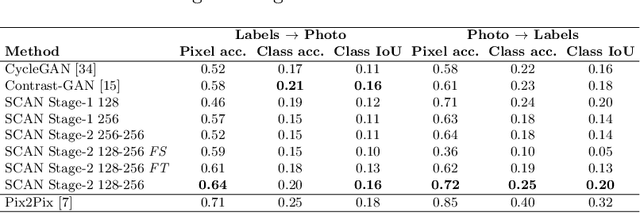
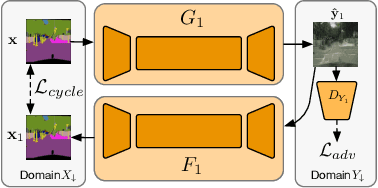
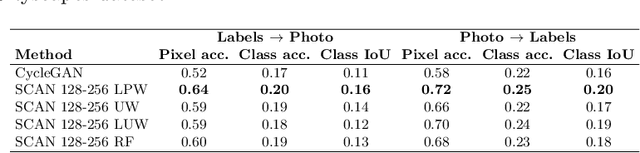
Recent studies on unsupervised image-to-image translation have made a remarkable progress by training a pair of generative adversarial networks with a cycle-consistent loss. However, such unsupervised methods may generate inferior results when the image resolution is high or the two image domains are of significant appearance differences, such as the translations between semantic layouts and natural images in the Cityscapes dataset. In this paper, we propose novel Stacked Cycle-Consistent Adversarial Networks (SCANs) by decomposing a single translation into multi-stage transformations, which not only boost the image translation quality but also enable higher resolution image-to-image translations in a coarse-to-fine manner. Moreover, to properly exploit the information from the previous stage, an adaptive fusion block is devised to learn a dynamic integration of the current stage's output and the previous stage's output. Experiments on multiple datasets demonstrate that our proposed approach can improve the translation quality compared with previous single-stage unsupervised methods.
Neural Stereoscopic Image Style Transfer
Jul 27, 2018



Neural style transfer is an emerging technique which is able to endow daily-life images with attractive artistic styles. Previous work has succeeded in applying convolutional neural networks (CNNs) to style transfer for monocular images or videos. However, style transfer for stereoscopic images is still a missing piece. Different from processing a monocular image, the two views of a stylized stereoscopic pair are required to be consistent to provide observers a comfortable visual experience. In this paper, we propose a novel dual path network for view-consistent style transfer on stereoscopic images. While each view of the stereoscopic pair is processed in an individual path, a novel feature aggregation strategy is proposed to effectively share information between the two paths. Besides a traditional perceptual loss being used for controlling the style transfer quality in each view, a multi-layer view loss is leveraged to enforce the network to coordinate the learning of both the paths to generate view-consistent stylized results. Extensive experiments show that, compared against previous methods, our proposed model can produce stylized stereoscopic images which achieve decent view consistency.
Pose2Seg: Human Instance Segmentation Without Detection
Mar 28, 2018
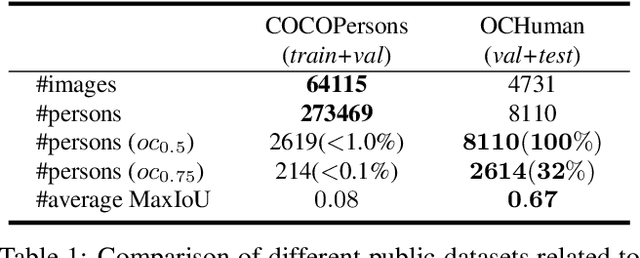


The general method of image instance segmentation is to perform the object detection first, and then segment the object from the detection bounding-box. More recently, deep learning methods like Mask R-CNN perform them jointly. However, little research takes into account the uniqueness of the "1human" category, which can be well defined by the pose skeleton. In this paper, we present a brand new pose-based instance segmentation framework for humans which separates instances based on human pose, not proposal region detection. We demonstrate that our pose-based framework can achieve similar accuracy to the detection-based approach, and can moreover better handle occlusion, which is the most challenging problem in the detection-based framework.