 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCostFilter-AD: Enhancing Anomaly Detection through Matching Cost Filtering
May 02, 2025



Unsupervised anomaly detection (UAD) seeks to localize the anomaly mask of an input image with respect to normal samples. Either by reconstructing normal counterparts (reconstruction-based) or by learning an image feature embedding space (embedding-based), existing approaches fundamentally rely on image-level or feature-level matching to derive anomaly scores. Often, such a matching process is inaccurate yet overlooked, leading to sub-optimal detection. To address this issue, we introduce the concept of cost filtering, borrowed from classical matching tasks, such as depth and flow estimation, into the UAD problem. We call this approach {\em CostFilter-AD}. Specifically, we first construct a matching cost volume between the input and normal samples, comprising two spatial dimensions and one matching dimension that encodes potential matches. To refine this, we propose a cost volume filtering network, guided by the input observation as an attention query across multiple feature layers, which effectively suppresses matching noise while preserving edge structures and capturing subtle anomalies. Designed as a generic post-processing plug-in, CostFilter-AD can be integrated with either reconstruction-based or embedding-based methods. Extensive experiments on MVTec-AD and VisA benchmarks validate the generic benefits of CostFilter-AD for both single- and multi-class UAD tasks. Code and models will be released at https://github.com/ZHE-SAPI/CostFilter-AD.
iFlame: Interleaving Full and Linear Attention for Efficient Mesh Generation
Mar 20, 2025This paper propose iFlame, a novel transformer-based network architecture for mesh generation. While attention-based models have demonstrated remarkable performance in mesh generation, their quadratic computational complexity limits scalability, particularly for high-resolution 3D data. Conversely, linear attention mechanisms offer lower computational costs but often struggle to capture long-range dependencies, resulting in suboptimal outcomes. To address this trade-off, we propose an interleaving autoregressive mesh generation framework that combines the efficiency of linear attention with the expressive power of full attention mechanisms. To further enhance efficiency and leverage the inherent structure of mesh representations, we integrate this interleaving approach into an hourglass architecture, which significantly boosts efficiency. Our approach reduces training time while achieving performance comparable to pure attention-based models. To improve inference efficiency, we implemented a caching algorithm that almost doubles the speed and reduces the KV cache size by seven-eighths compared to the original Transformer. We evaluate our framework on ShapeNet and Objaverse, demonstrating its ability to generate high-quality 3D meshes efficiently. Our results indicate that the proposed interleaving framework effectively balances computational efficiency and generative performance, making it a practical solution for mesh generation. The training takes only 2 days with 4 GPUs on 39k data with a maximum of 4k faces on Objaverse.
Autoregressive Generation of Static and Growing Trees
Feb 07, 2025We propose a transformer architecture and training strategy for tree generation. The architecture processes data at multiple resolutions and has an hourglass shape, with middle layers processing fewer tokens than outer layers. Similar to convolutional networks, we introduce longer range skip connections to completent this multi-resolution approach. The key advantage of this architecture is the faster processing speed and lower memory consumption. We are therefore able to process more complex trees than would be possible with a vanilla transformer architecture. Furthermore, we extend this approach to perform image-to-tree and point-cloud-to-tree conditional generation and to simulate the tree growth processes, generating 4D trees. Empirical results validate our approach in terms of speed, memory consumption, and generation quality.
On the Performance Analysis of Momentum Method: A Frequency Domain Perspective
Nov 29, 2024



Momentum-based optimizers are widely adopted for training neural networks. However, the optimal selection of momentum coefficients remains elusive. This uncertainty impedes a clear understanding of the role of momentum in stochastic gradient methods. In this paper, we present a frequency domain analysis framework that interprets the momentum method as a time-variant filter for gradients, where adjustments to momentum coefficients modify the filter characteristics. Our experiments support this perspective and provide a deeper understanding of the mechanism involved. Moreover, our analysis reveals the following significant findings: high-frequency gradient components are undesired in the late stages of training; preserving the original gradient in the early stages, and gradually amplifying low-frequency gradient components during training both enhance generalization performance. Based on these insights, we propose Frequency Stochastic Gradient Descent with Momentum (FSGDM), a heuristic optimizer that dynamically adjusts the momentum filtering characteristic with an empirically effective dynamic magnitude response. Experimental results demonstrate the superiority of FSGDM over conventional momentum optimizers.
KANs for Computer Vision: An Experimental Study
Nov 28, 2024



This paper presents an experimental study of Kolmogorov-Arnold Networks (KANs) applied to computer vision tasks, particularly image classification. KANs introduce learnable activation functions on edges, offering flexible non-linear transformations compared to traditional pre-fixed activation functions with specific neural work like Multi-Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs). While KANs have shown promise mostly in simplified or small-scale datasets, their effectiveness for more complex real-world tasks such as computer vision tasks remains less explored. To fill this gap, this experimental study aims to provide extended observations and insights into the strengths and limitations of KANs. We reveal that although KANs can perform well in specific vision tasks, they face significant challenges, including increased hyperparameter sensitivity and higher computational costs. These limitations suggest that KANs require architectural adaptations, such as integration with other architectures, to be practical for large-scale vision problems. This study focuses on empirical findings rather than proposing new methods, aiming to inform future research on optimizing KANs, in particular computer vision applications or alike.
E$^3$-Net: Efficient E-Equivariant Normal Estimation Network
Jun 01, 2024Point cloud normal estimation is a fundamental task in 3D geometry processing. While recent learning-based methods achieve notable advancements in normal prediction, they often overlook the critical aspect of equivariance. This results in inefficient learning of symmetric patterns. To address this issue, we propose E3-Net to achieve equivariance for normal estimation. We introduce an efficient random frame method, which significantly reduces the training resources required for this task to just 1/8 of previous work and improves the accuracy. Further, we design a Gaussian-weighted loss function and a receptive-aware inference strategy that effectively utilizes the local properties of point clouds. Our method achieves superior results on both synthetic and real-world datasets, and outperforms current state-of-the-art techniques by a substantial margin. We improve RMSE by 4% on the PCPNet dataset, 2.67% on the SceneNN dataset, and 2.44% on the FamousShape dataset.
Diffusion Deepfake
Apr 02, 2024Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
Dont Even Look Once: Synthesizing Features for Zero-Shot Detection
Nov 18, 2019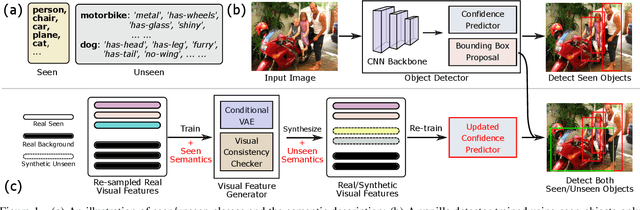
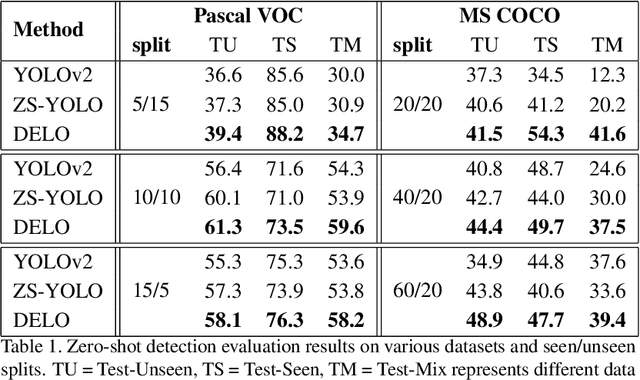
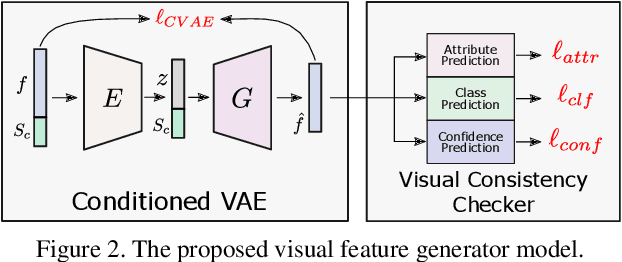
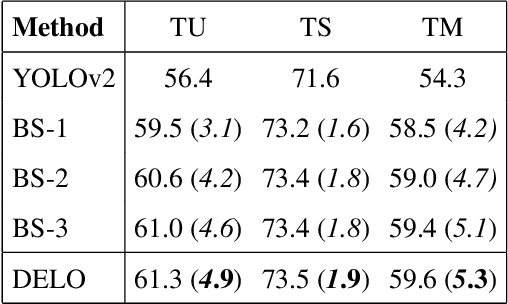
Zero-shot detection, namely, localizing both seen and unseen objects, increasingly gains importance for large-scale applications, with large number of object classes, since, collecting sufficient annotated data with ground truth bounding boxes is simply not scalable. While vanilla deep neural networks deliver high performance for objects available during training, unseen object detection degrades significantly. At a fundamental level, while vanilla detectors are capable of proposing bounding boxes, which include unseen objects, they are often incapable of assigning high-confidence to unseen objects, due to the inherent precision/recall tradeoffs that requires rejecting background objects. We propose a novel detection algorithm Dont Even Look Once (DELO), that synthesizes visual features for unseen objects and augments existing training algorithms to incorporate unseen object detection. Our proposed scheme is evaluated on Pascal VOC and MSCOCO, and we demonstrate significant improvements in test accuracy over vanilla and other state-of-art zero-shot detectors
Learning for New Visual Environments with Limited Labels
Jan 25, 2019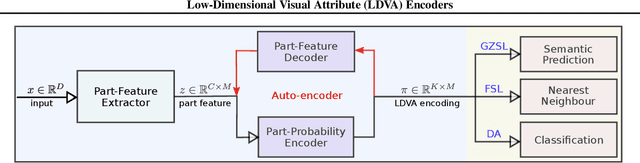

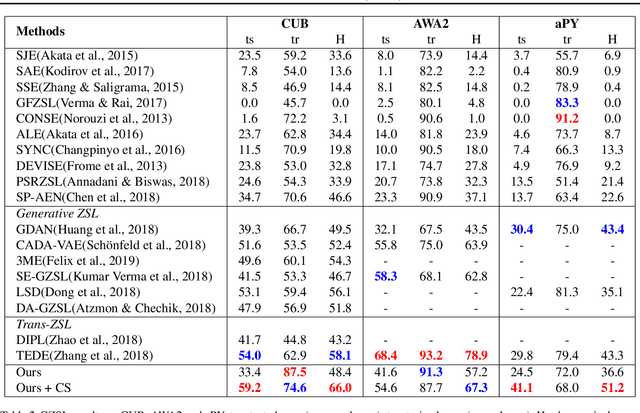
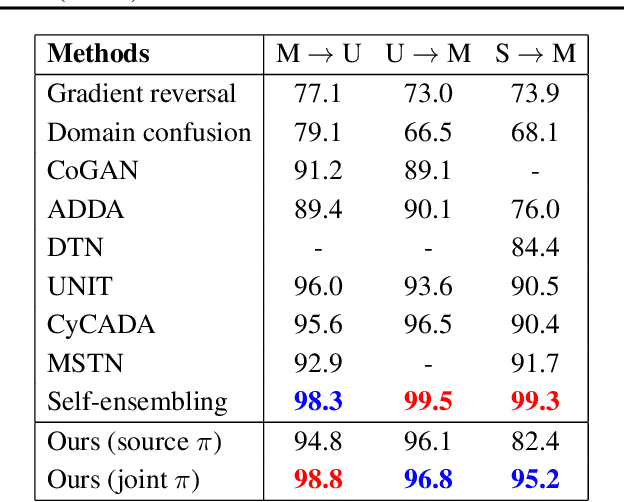
In computer vision applications, such as domain adaptation (DA), few shot learning (FSL) and zero-shot learning (ZSL), we encounter new objects and environments, for which insufficient examples exist to allow for training "models from scratch," and methods that adapt existing models, trained on the presented training environment, to the new scenario are required. We propose a novel visual attribute encoding method that encodes each image as a low-dimensional probability vector composed of prototypical part-type probabilities. The prototypes are learnt to be representative of all training data. At test-time we utilize this encoding as an input to a classifier. At test-time we freeze the encoder and only learn/adapt the classifier component to limited annotated labels in FSL; new semantic attributes in ZSL. We conduct extensive experiments on benchmark datasets. Our method outperforms state-of-art methods trained for the specific contexts (ZSL, FSL, DA).
Generalized Zero-Shot Recognition based on Visually Semantic Embedding
Nov 19, 2018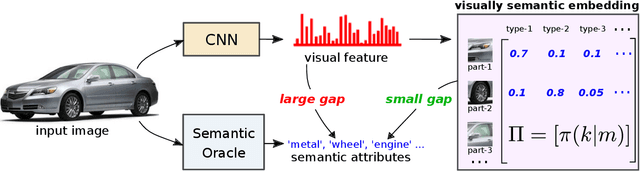
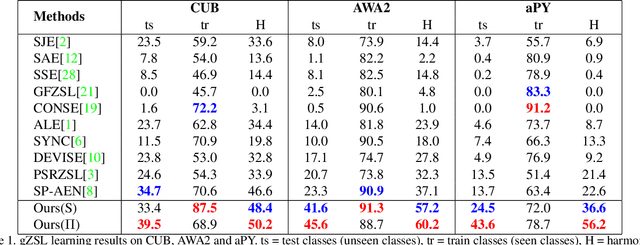
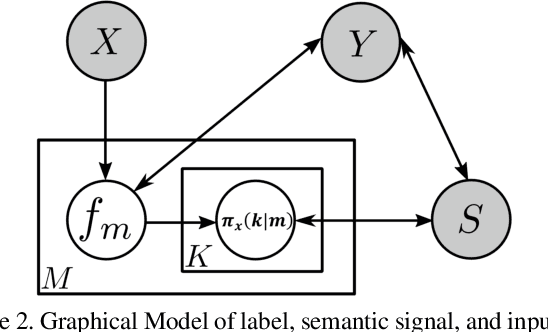

We propose a novel Generalized Zero-Shot learning (GZSL) method that is agnostic to both unseen images and unseen semantic vectors during training. Prior works in this context propose to map high-dimensional visual features to the semantic domain, we believe contributes to the semantic gap. To bridge the gap, we propose a novel low-dimensional embedding of visual instances that is "visually semantic." Analogous to semantic data that quantifies the existence of an attribute in the presented instance, components of our visual embedding quantifies existence of a prototypical part-type in the presented instance. In parallel, as a thought experiment, we quantify the impact of noisy semantic data by utilizing a novel visual oracle to visually supervise a learner. These factors, namely semantic noise, visual-semantic gap and label noise lead us to propose a new graphical model for inference with pairwise interactions between label, semantic data, and inputs. We tabulate results on a number of benchmark datasets demonstrating significant improvement in accuracy over state-of-the-art under both semantic and visual supervision.