 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAST: A Primary-Auxiliary Spatio-Temporal Network for Traffic Time Series Imputation
Nov 17, 2025



Traffic time series imputation is crucial for the safety and reliability of intelligent transportation systems, while diverse types of missing data, including random, fiber, and block missing make the imputation task challenging. Existing models often focus on disentangling and separately modeling spatial and temporal patterns based on relationships between data points. However, these approaches struggle to adapt to the random missing positions, and fail to learn long-term and large-scale dependencies, which are essential in extensive missing conditions. In this paper, patterns are categorized into two types to handle various missing data conditions: primary patterns, which originate from internal relationships between data points, and auxiliary patterns, influenced by external factors like timestamps and node attributes. Accordingly, we propose the Primary-Auxiliary Spatio-Temporal network (PAST). It comprises a graph-integrated module (GIM) and a cross-gated module (CGM). GIM captures primary patterns via dynamic graphs with interval-aware dropout and multi-order convolutions, and CGM extracts auxiliary patterns through bidirectional gating on embedded external features. The two modules interact via shared hidden vectors and are trained under an ensemble self-supervised framework. Experiments on three datasets under 27 missing data conditions demonstrate that the imputation accuracy of PAST outperforms seven state-of-the-art baselines by up to 26.2% in RMSE and 31.6% in MAE.
EDGC: Entropy-driven Dynamic Gradient Compression for Efficient LLM Training
Nov 13, 2025Training large language models (LLMs) poses significant challenges regarding computational resources and memory capacity. Although distributed training techniques help mitigate these issues, they still suffer from considerable communication overhead. Existing approaches primarily rely on static gradient compression to enhance communication efficiency; however, these methods neglect the dynamic nature of evolving gradients during training, leading to performance degradation. Accelerating LLM training via compression without sacrificing performance remains a challenge. In this paper, we propose an entropy-driven dynamic gradient compression framework called EDGC. The core concept is to adjust the compression rate during LLM training based on the evolving trends of gradient entropy, taking into account both compression efficiency and error. EDGC consists of three key components.First, it employs a down-sampling method to efficiently estimate gradient entropy, reducing computation overhead. Second, it establishes a theoretical model linking compression rate with gradient entropy, enabling more informed compression decisions. Lastly, a window-based adjustment mechanism dynamically adapts the compression rate across pipeline stages, improving communication efficiency and maintaining model performance. We implemented EDGC on a 32-NVIDIA-V100 cluster and a 64-NVIDIA-H100 cluster to train GPT2-2.5B and GPT2-12.1B, respectively. The results show that EDGC significantly reduces communication latency and training time by up to 46.45% and 16.13% while preserving LLM accuracy.
EdgeStereo: An Effective Multi-Task Learning Network for Stereo Matching and Edge Detection
Mar 05, 2019
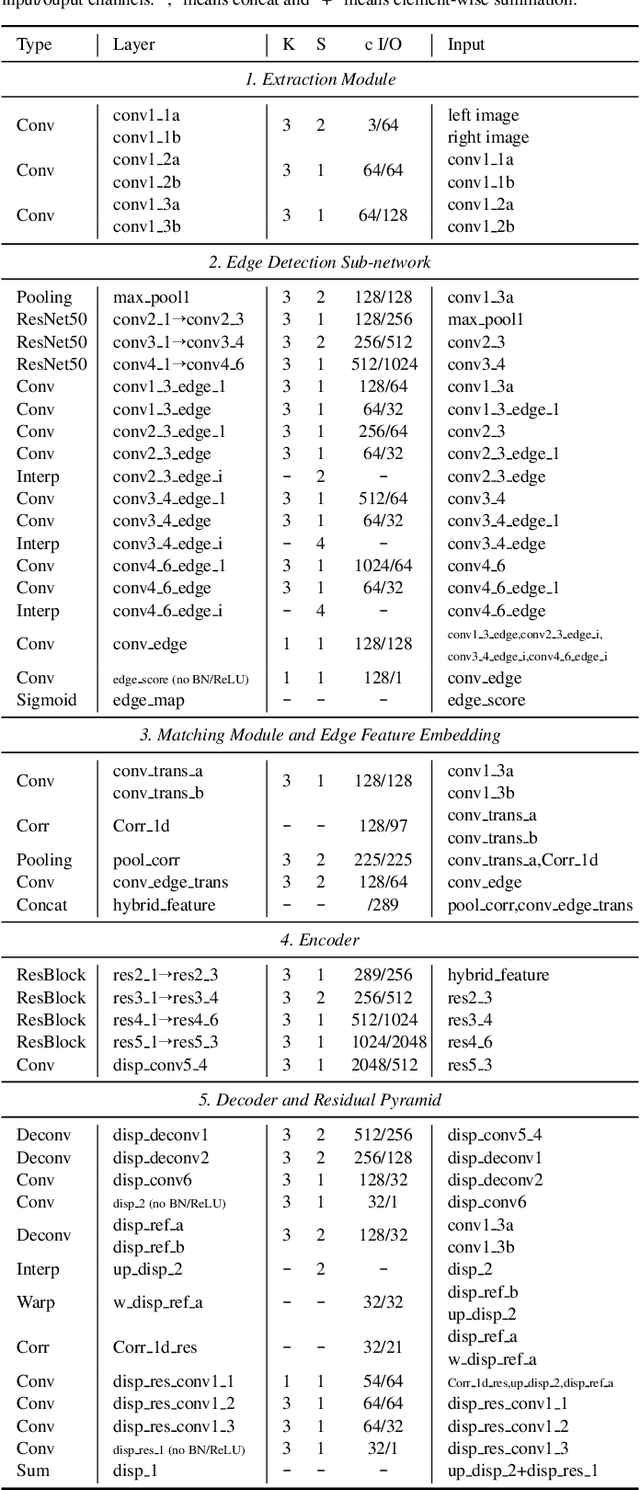
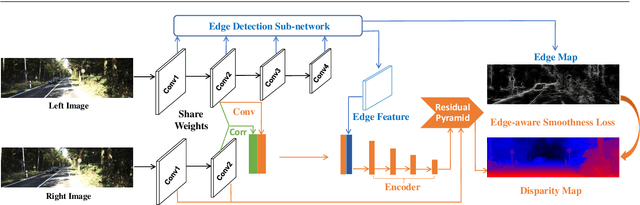

Recently, leveraging on the development of end-to-end convolutional neural networks, deep stereo matching networks achieve remarkable performance far exceeding traditional approaches. However, state-of-the-art stereo methods still have difficulties finding correct correspondences in texture-less regions, detailed structures, small objects and near boundaries, which could be alleviated by geometric clues such as edge contours and corresponding constraints. To improve the quality of disparity estimates in these challenging areas, we propose an effective multi-task learning network EdgeStereo composed of a disparity estimation sub-network and an edge detection sub-network, which enables end-to-end predictions of both disparity map and edge map. To effectively incorporates edge cues, we propose the edge-aware smoothness loss and edge feature embedding for inter-task interactions. It is demonstrated that based on our unified model, edge detection task and stereo matching task can promote each other. In addition, we design a compact module called residual pyramid to replace the commonly-used multi-stage cascaded structures or 3-D convolution based regularization modules in current stereo matching networks. By the time of the paper submission, EdgeStereo achieves state-of-the-art performance on the FlyingThings3D dataset, KITTI 2012 and KITTI 2015 stereo benchmarks, outperforming other published stereo matching methods by a noteworthy margin. EdgeStereo also has a better generalization capability for disparity estimation because of the incorporation of edge cues.
EdgeStereo: A Context Integrated Residual Pyramid Network for Stereo Matching
Sep 23, 2018
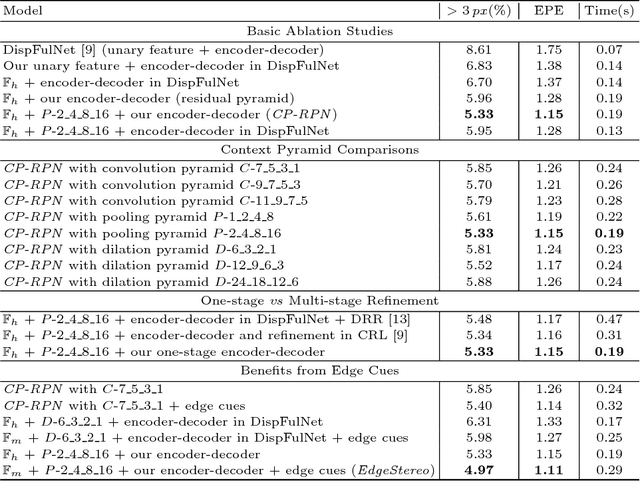
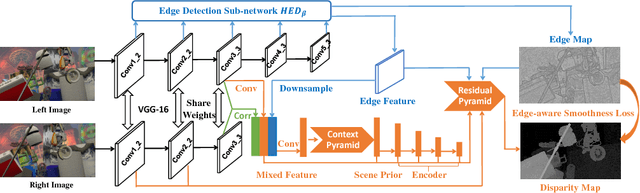
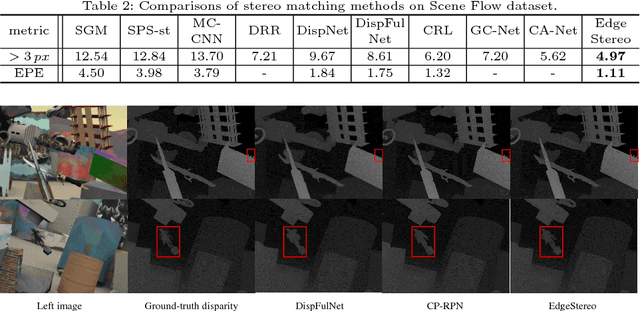
Recent convolutional neural networks, especially end-to-end disparity estimation models, achieve remarkable performance on stereo matching task. However, existed methods, even with the complicated cascade structure, may fail in the regions of non-textures, boundaries and tiny details. Focus on these problems, we propose a multi-task network EdgeStereo that is composed of a backbone disparity network and an edge sub-network. Given a binocular image pair, our model enables end-to-end prediction of both disparity map and edge map. Basically, we design a context pyramid to encode multi-scale context information in disparity branch, followed by a compact residual pyramid for cascaded refinement. To further preserve subtle details, our EdgeStereo model integrates edge cues by feature embedding and edge-aware smoothness loss regularization. Comparative results demonstrates that stereo matching and edge detection can help each other in the unified model. Furthermore, our method achieves state-of-art performance on both KITTI Stereo and Scene Flow benchmarks, which proves the effectiveness of our design.