 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

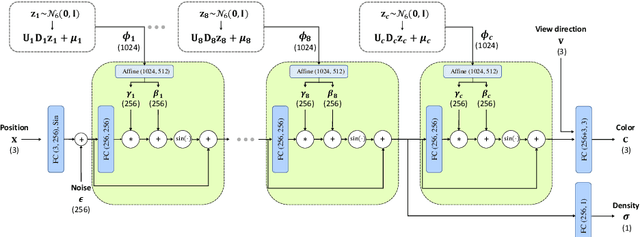
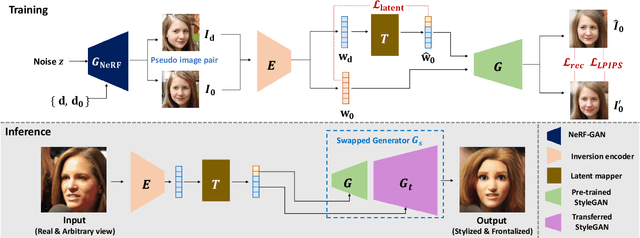
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022


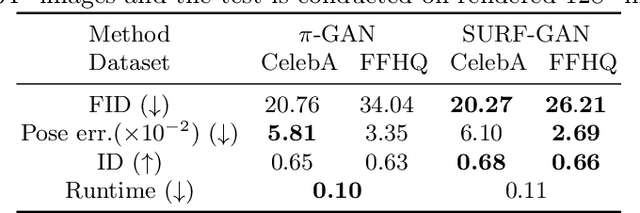
Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022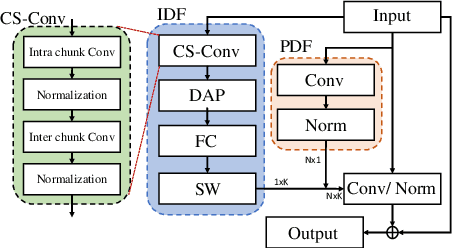
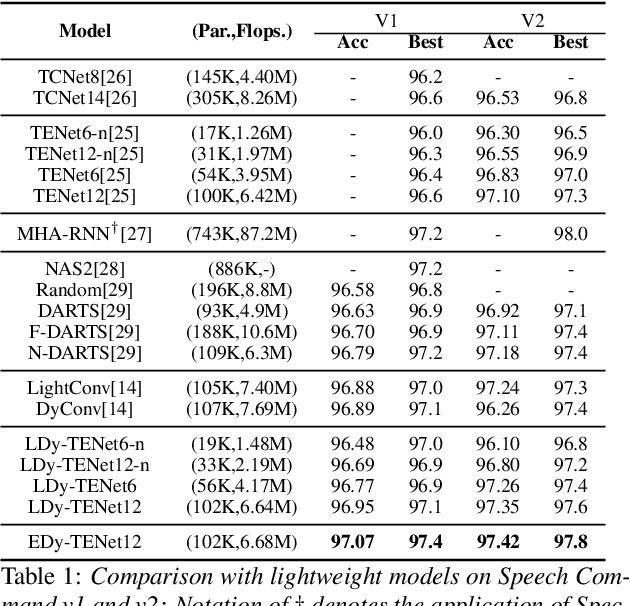
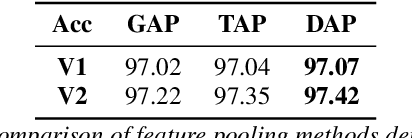
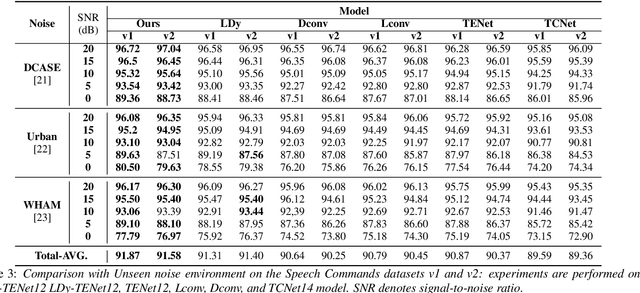
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
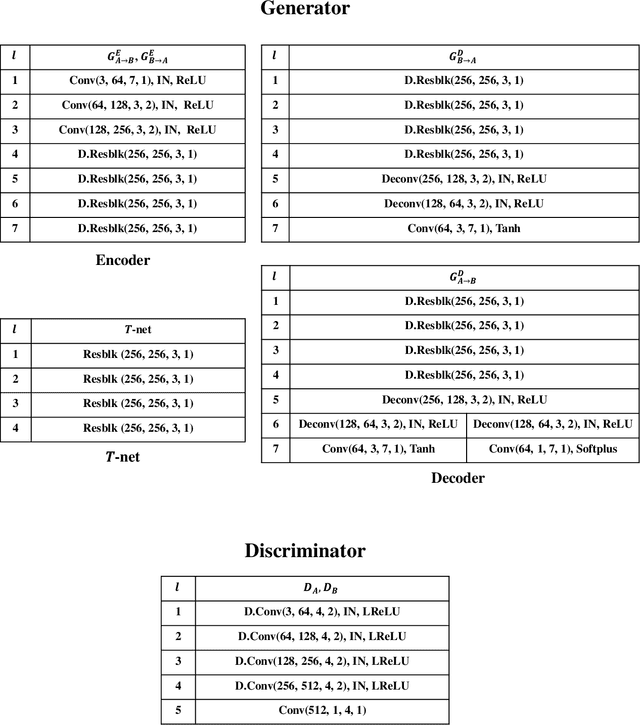


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
Action Recognition with Domain Invariant Features of Skeleton Image
Nov 19, 2021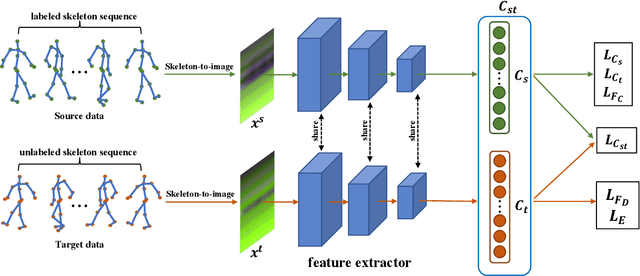
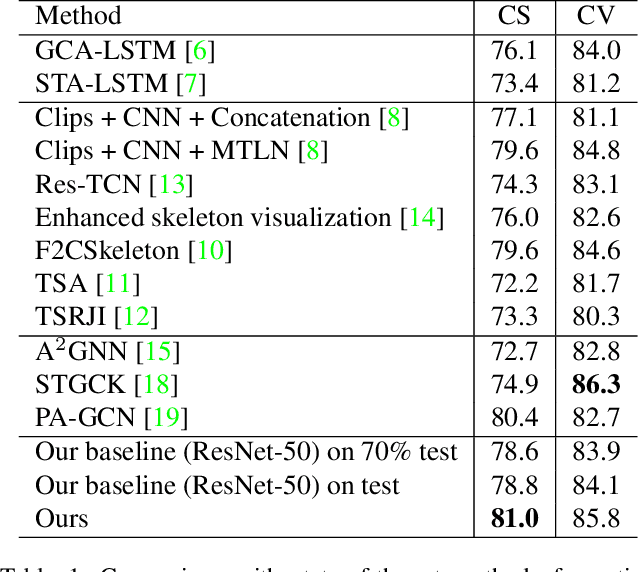
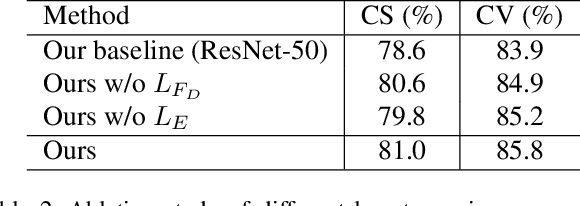
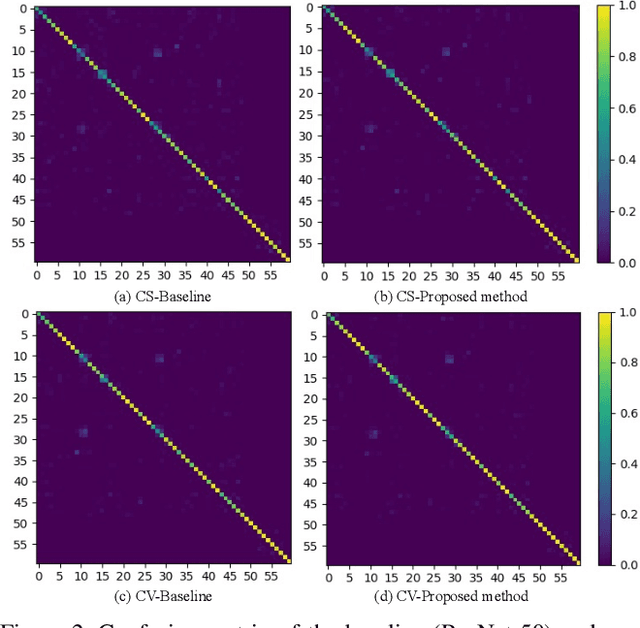
Due to the fast processing-speed and robustness it can achieve, skeleton-based action recognition has recently received the attention of the computer vision community. The recent Convolutional Neural Network (CNN)-based methods have shown commendable performance in learning spatio-temporal representations for skeleton sequence, which use skeleton image as input to a CNN. Since the CNN-based methods mainly encoding the temporal and skeleton joints simply as rows and columns, respectively, the latent correlation related to all joints may be lost caused by the 2D convolution. To solve this problem, we propose a novel CNN-based method with adversarial training for action recognition. We introduce a two-level domain adversarial learning to align the features of skeleton images from different view angles or subjects, respectively, thus further improve the generalization. We evaluated our proposed method on NTU RGB+D. It achieves competitive results compared with state-of-the-art methods and 2.4$\%$, 1.9$\%$ accuracy gain than the baseline for cross-subject and cross-view.
A Teacher-Student Framework with Fourier Augmentation for COVID-19 Infection Segmentation in CT Images
Oct 13, 2021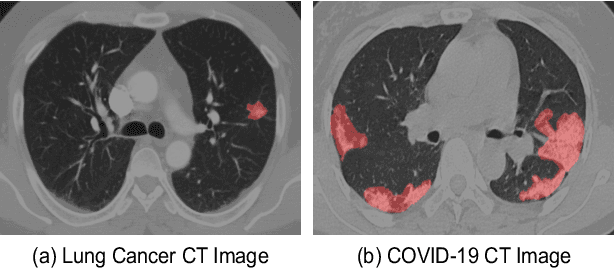
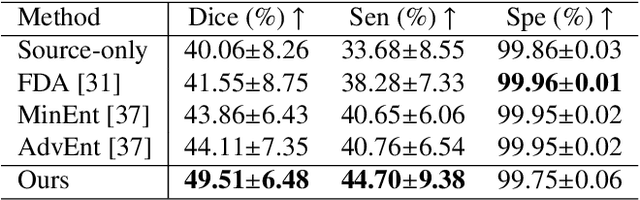
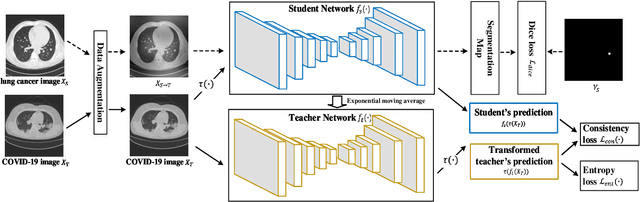
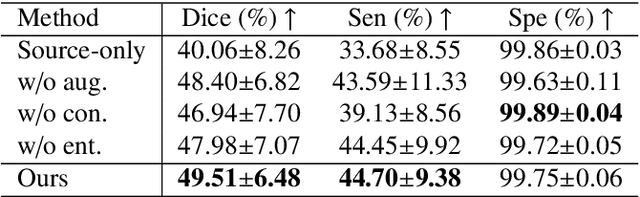
Automatic segmentation of infected regions in computed tomography (CT) images is necessary for the initial diagnosis of COVID-19. Deep-learning-based methods have the potential to automate this task but require a large amount of data with pixel-level annotations. Training a deep network with annotated lung cancer CT images, which are easier to obtain, can alleviate this problem to some extent. However, this approach may suffer from a reduction in performance when applied to unseen COVID-19 images during the testing phase due to the domain shift. In this paper, we propose a novel unsupervised method for COVID-19 infection segmentation that aims to learn the domain-invariant features from lung cancer and COVID-19 images to improve the generalization ability of the segmentation network for use with COVID-19 CT images. To overcome the intensity shift, our method first transforms annotated lung cancer data into the style of unlabeled COVID-19 data using an effective augmentation approach via a Fourier transform. Furthermore, to reduce the distribution shift, we design a teacher-student network to learn rotation-invariant features for segmentation. Experiments demonstrate that even without getting access to the annotations of COVID-19 CT during training, the proposed network can achieve a state-of-the-art segmentation performance on COVID-19 images.
Lightweight dynamic filter for keyword spotting
Sep 27, 2021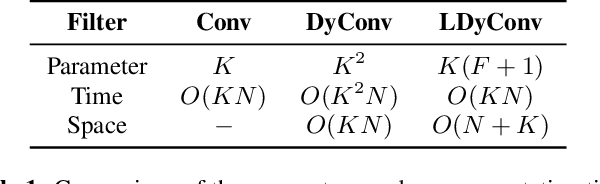
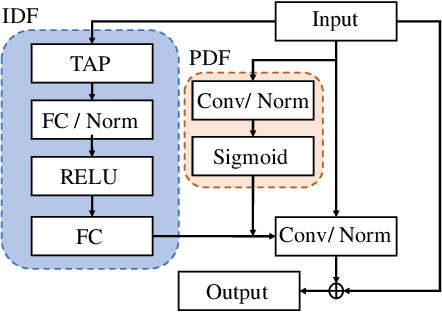
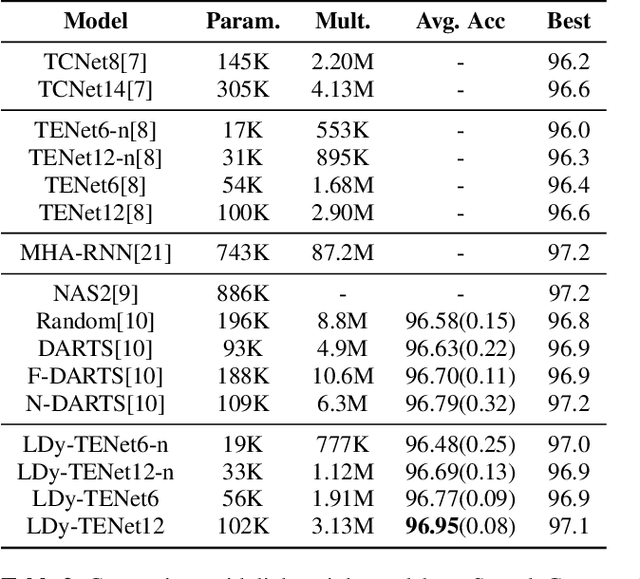
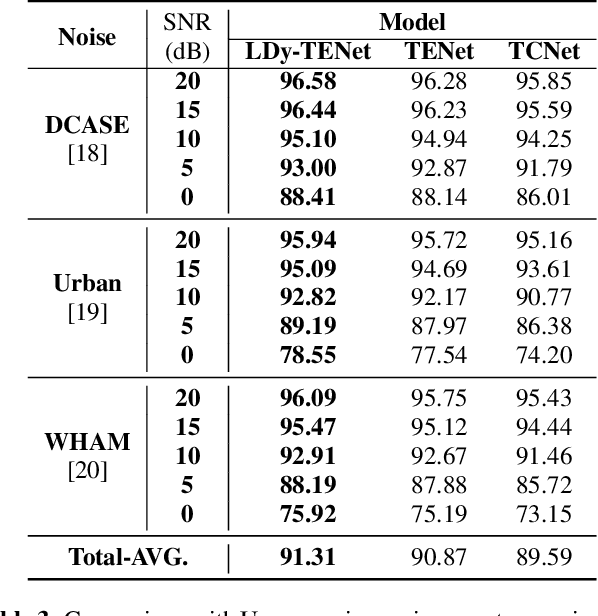
Keyword Spotting (KWS) from speech signal is widely applied for being fully hands free speech recognition. The KWS network is designed as a small footprint model to be constantly monitored. Recently, dynamic filter based models are applied in deep learning applications to enhance a system's robustness or accuracy. However, as a dynamic filter framework requires high computational cost, the usage is limited to the condition of the device. In this paper, we proposed a lightweight dynamic filter to improve the performance of KWS. Our proposed model divides dynamic filter as two branches to reduce the computational complexity. This lightweight dynamic filter is applied to the front-end of KWS to enhance the separability of the input data. The experiments show that our model is robustly working on unseen noise and small training data environment by using small computational resource.
Memory-based Semantic Segmentation for Off-road Unstructured Natural Environments
Aug 18, 2021

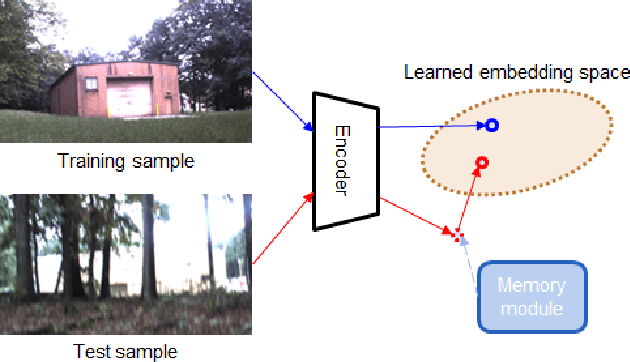
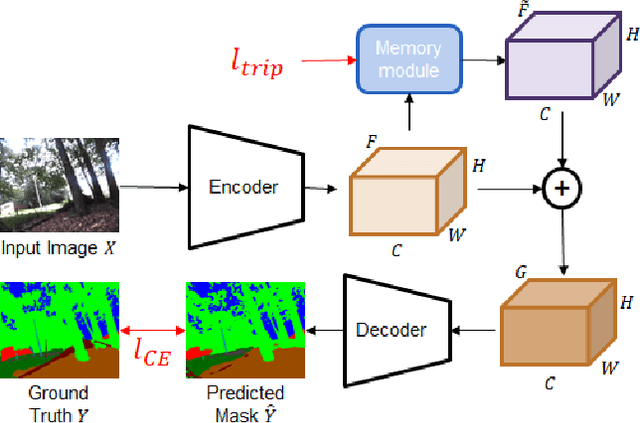
With the availability of many datasets tailored for autonomous driving in real-world urban scenes, semantic segmentation for urban driving scenes achieves significant progress. However, semantic segmentation for off-road, unstructured environments is not widely studied. Directly applying existing segmentation networks often results in performance degradation as they cannot overcome intrinsic problems in such environments, such as illumination changes. In this paper, a built-in memory module for semantic segmentation is proposed to overcome these problems. The memory module stores significant representations of training images as memory items. In addition to the encoder embedding like items together, the proposed memory module is specifically designed to cluster together instances of the same class even when there are significant variances in embedded features. Therefore, it makes segmentation networks better deal with unexpected illumination changes. A triplet loss is used in training to minimize redundancy in storing discriminative representations of the memory module. The proposed memory module is general so that it can be adopted in a variety of networks. We conduct experiments on the Robot Unstructured Ground Driving (RUGD) dataset and RELLIS dataset, which are collected from off-road, unstructured natural environments. Experimental results show that the proposed memory module improves the performance of existing segmentation networks and contributes to capturing unclear objects over various off-road, unstructured natural scenes with equivalent computational cost and network parameters. As the proposed method can be integrated into compact networks, it presents a viable approach for resource-limited small autonomous platforms.
CPNet: Cross-Parallel Network for Efficient Anomaly Detection
Aug 13, 2021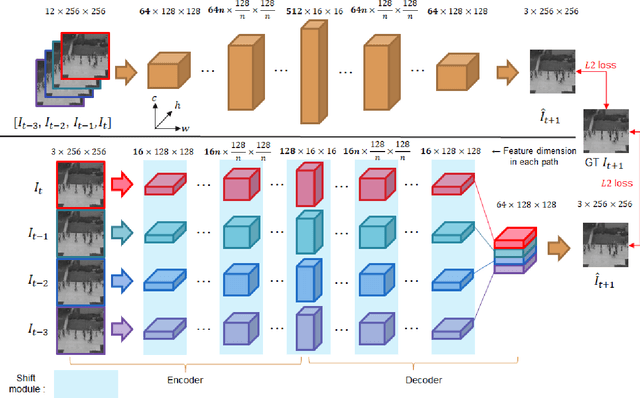
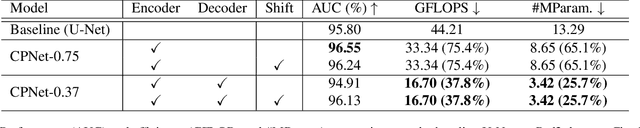
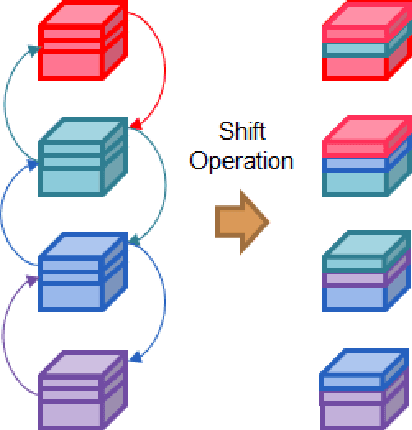
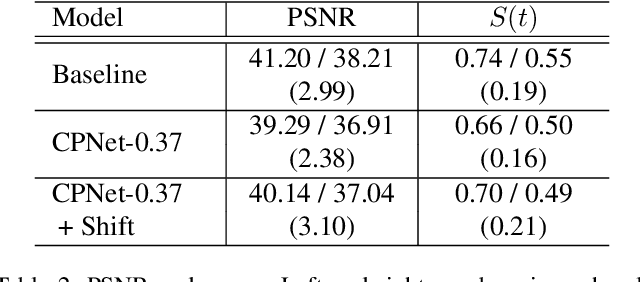
Anomaly detection in video streams is a challenging problem because of the scarcity of abnormal events and the difficulty of accurately annotating them. To alleviate these issues, unsupervised learning-based prediction methods have been previously applied. These approaches train the model with only normal events and predict a future frame from a sequence of preceding frames by use of encoder-decoder architectures so that they result in small prediction errors on normal events but large errors on abnormal events. The architecture, however, comes with the computational burden as some anomaly detection tasks require low computational cost without sacrificing performance. In this paper, Cross-Parallel Network (CPNet) for efficient anomaly detection is proposed here to minimize computations without performance drops. It consists of N smaller parallel U-Net, each of which is designed to handle a single input frame, to make the calculations significantly more efficient. Additionally, an inter-network shift module is incorporated to capture temporal relationships among sequential frames to enable more accurate future predictions.The quantitative results show that our model requires less computational cost than the baseline U-Net while delivering equivalent performance in anomaly detection.
Few-shot Learning for CT Scan based COVID-19 Diagnosis
Feb 01, 2021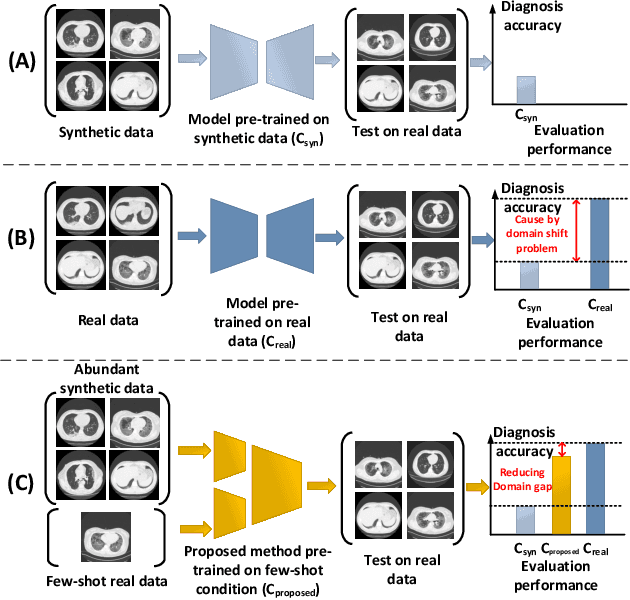
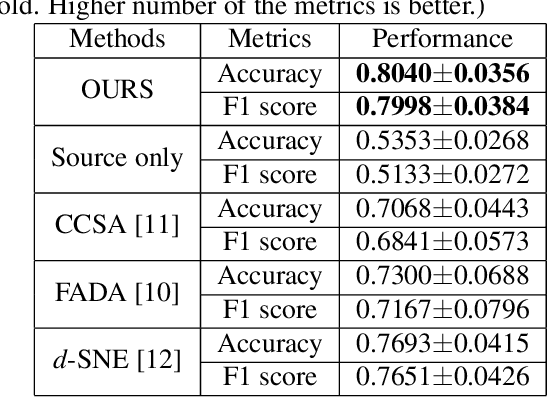
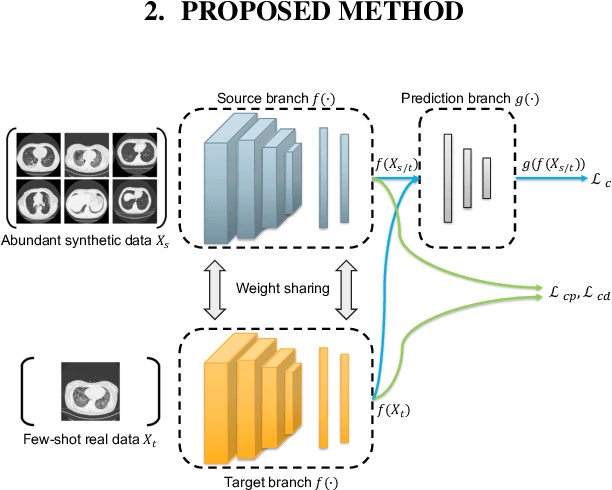
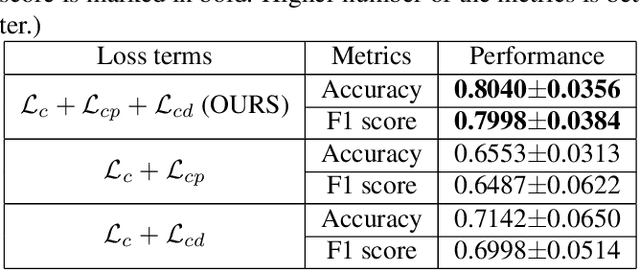
Coronavirus disease 2019 (COVID-19) is a Public Health Emergency of International Concern infecting more than 40 million people across 188 countries and territories. Chest computed tomography (CT) imaging technique benefits from its high diagnostic accuracy and robustness, it has become an indispensable way for COVID-19 mass testing. Recently, deep learning approaches have become an effective tool for automatic screening of medical images, and it is also being considered for COVID-19 diagnosis. However, the high infection risk involved with COVID-19 leads to relative sparseness of collected labeled data limiting the performance of such methodologies. Moreover, accurately labeling CT images require expertise of radiologists making the process expensive and time-consuming. In order to tackle the above issues, we propose a supervised domain adaption based COVID-19 CT diagnostic method which can perform effectively when only a small samples of labeled CT scans are available. To compensate for the sparseness of labeled data, the proposed method utilizes a large amount of synthetic COVID-19 CT images and adjusts the networks from the source domain (synthetic data) to the target domain (real data) with a cross-domain training mechanism. Experimental results show that the proposed method achieves state-of-the-art performance on few-shot COVID-19 CT imaging based diagnostic tasks.