 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNR: A Similarity and Transformer-Based Approachto Detect Multi-Modal FakeNews in Social Media
Dec 02, 2021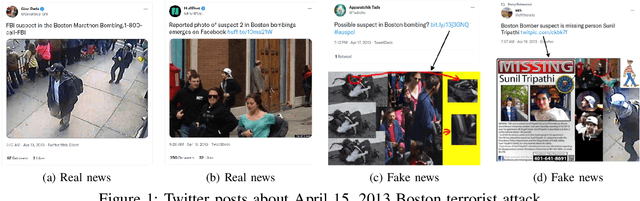
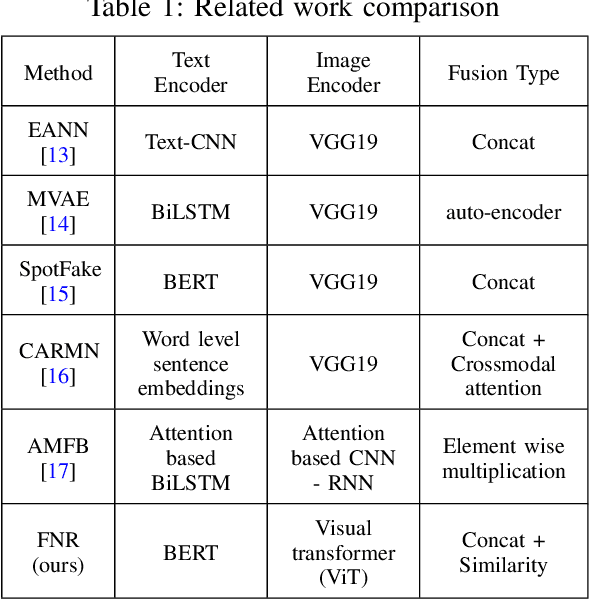
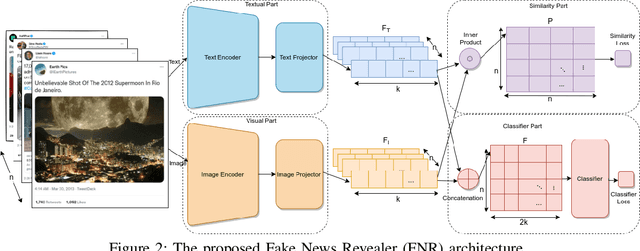
The availability and interactive nature of social media have made them the primary source of news around the globe. The popularity of social media tempts criminals to pursue their immoral intentions by producing and disseminating fake news using seductive text and misleading images. Therefore, verifying social media news and spotting fakes is crucial. This work aims to analyze multi-modal features from texts and images in social media for detecting fake news. We propose a Fake News Revealer (FNR) method that utilizes transform learning to extract contextual and semantic features and contrastive loss to determine the similarity between image and text. We applied FNR on two real social media datasets. The results show the proposed method achieves higher accuracies in detecting fake news compared to the previous works.
CCGG: A Deep Autoregressive Model for Class-Conditional Graph Generation
Oct 07, 2021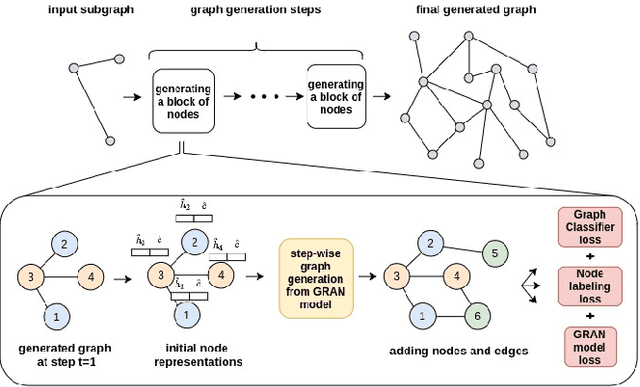
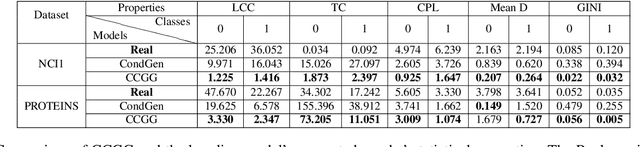
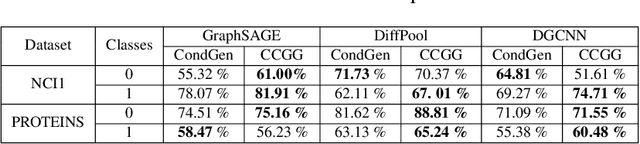

Graph data structures are fundamental for studying connected entities. With an increase in the number of applications where data is represented as graphs, the problem of graph generation has recently become a hot topic in many signal processing areas. However, despite its significance, conditional graph generation that creates graphs with desired features is relatively less explored in previous studies. This paper addresses the problem of class-conditional graph generation that uses class labels as generation constraints by introducing the Class Conditioned Graph Generator (CCGG). We built CCGG by adding the class information as an additional input to a graph generator model and including a classification loss in its total loss along with a gradient passing trick. Our experiments show that CCGG outperforms existing conditional graph generation methods on various datasets. It also manages to maintain the quality of the generated graphs in terms of distribution-based evaluation metrics.
Distributed Detection and Mitigation of Biasing Attacks over Multi-Agent Networks
Sep 20, 2021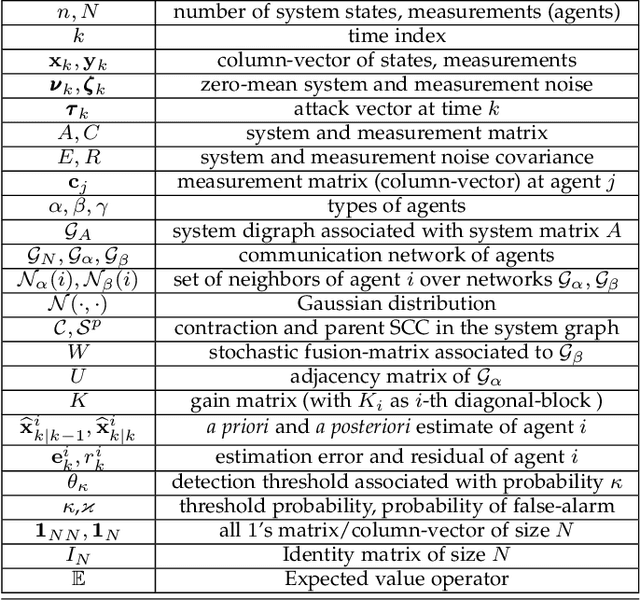
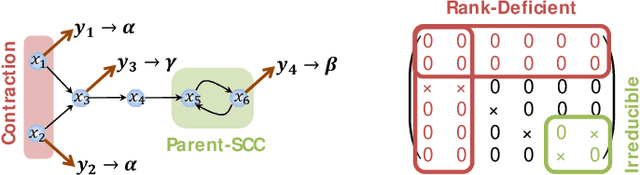
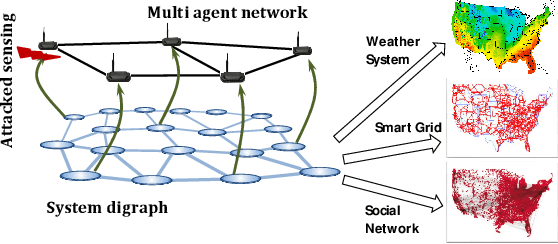
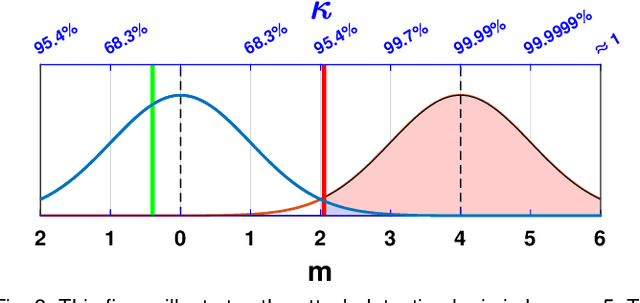
This paper proposes a distributed attack detection and mitigation technique based on distributed estimation over a multi-agent network, where the agents take partial system measurements susceptible to (possible) biasing attacks. In particular, we assume that the system is not locally observable via the measurements in the direct neighborhood of any agent. First, for performance analysis in the attack-free case, we show that the proposed distributed estimation is unbiased with bounded mean-square deviation in steady-state. Then, we propose a residual-based strategy to locally detect possible attacks at agents. In contrast to the deterministic thresholds in the literature assuming an upper bound on the noise support, we define the thresholds on the residuals in a probabilistic sense. After detecting and isolating the attacked agent, a system-digraph-based mitigation strategy is proposed to replace the attacked measurement with a new observationally-equivalent one to recover potential observability loss. We adopt a graph-theoretic method to classify the agents based on their measurements, to distinguish between the agents recovering the system rank-deficiency and the ones recovering output-connectivity of the system digraph. The attack detection/mitigation strategy is specifically described for each type, which is of polynomial-order complexity for large-scale applications. Illustrative simulations support our theoretical results.
SINA-BERT: A pre-trained Language Model for Analysis of Medical Texts in Persian
Apr 15, 2021
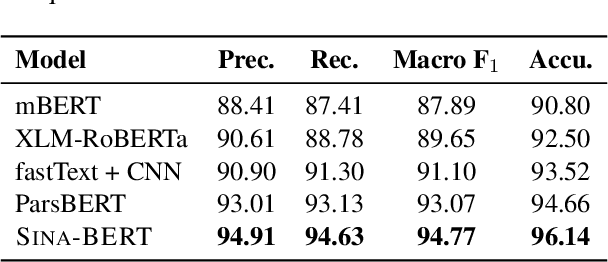
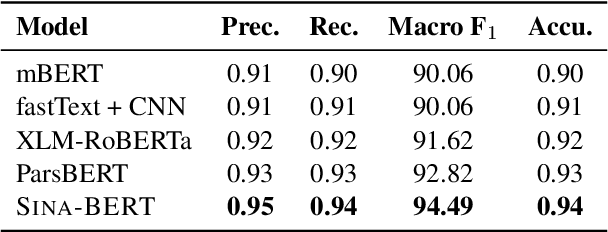
We have released Sina-BERT, a language model pre-trained on BERT (Devlin et al., 2018) to address the lack of a high-quality Persian language model in the medical domain. SINA-BERT utilizes pre-training on a large-scale corpus of medical contents including formal and informal texts collected from a variety of online resources in order to improve the performance on health-care related tasks. We employ SINA-BERT to complete following representative tasks: categorization of medical questions, medical sentiment analysis, and medical question retrieval. For each task, we have developed Persian annotated data sets for training and evaluation and learnt a representation for the data of each task especially complex and long medical questions. With the same architecture being used across tasks, SINA-BERT outperforms BERT-based models that were previously made available in the Persian language.
GKD: Semi-supervised Graph Knowledge Distillation for Graph-Independent Inference
Apr 08, 2021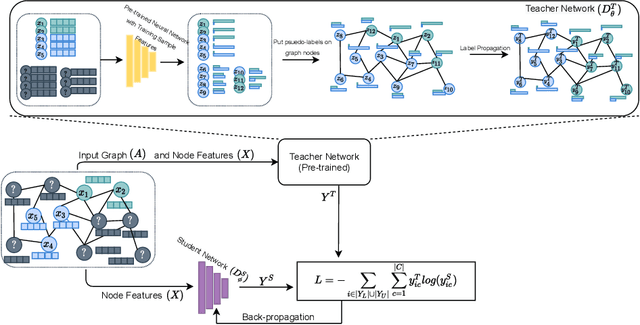
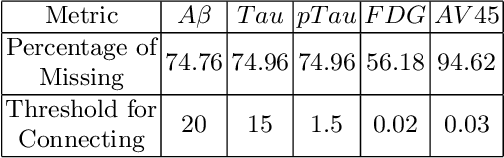
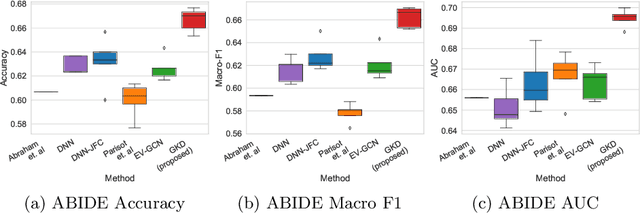
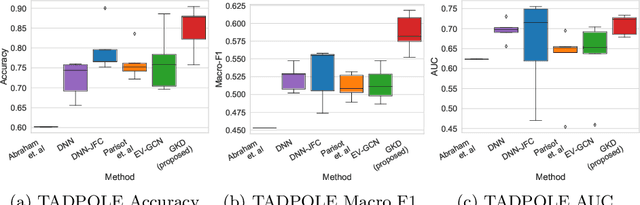
The increased amount of multi-modal medical data has opened the opportunities to simultaneously process various modalities such as imaging and non-imaging data to gain a comprehensive insight into the disease prediction domain. Recent studies using Graph Convolutional Networks (GCNs) provide novel semi-supervised approaches for integrating heterogeneous modalities while investigating the patients' associations for disease prediction. However, when the meta-data used for graph construction is not available at inference time (e.g., coming from a distinct population), the conventional methods exhibit poor performance. To address this issue, we propose a novel semi-supervised approach named GKD based on knowledge distillation. We train a teacher component that employs the label-propagation algorithm besides a deep neural network to benefit from the graph and non-graph modalities only in the training phase. The teacher component embeds all the available information into the soft pseudo-labels. The soft pseudo-labels are then used to train a deep student network for disease prediction of unseen test data for which the graph modality is unavailable. We perform our experiments on two public datasets for diagnosing Autism spectrum disorder, and Alzheimer's disease, along with a thorough analysis on synthetic multi-modal datasets. According to these experiments, GKD outperforms the previous graph-based deep learning methods in terms of accuracy, AUC, and Macro F1.
Dementia Severity Classification under Small Sample Size and Weak Supervision in Thick Slice MRI
Mar 18, 2021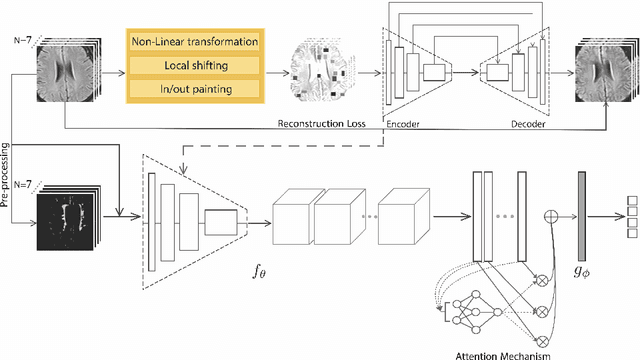
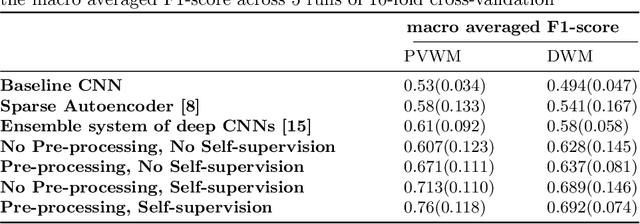
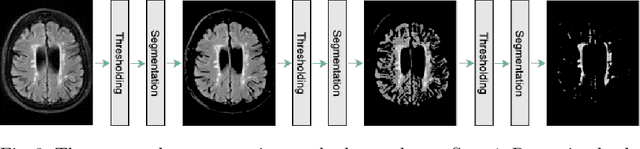
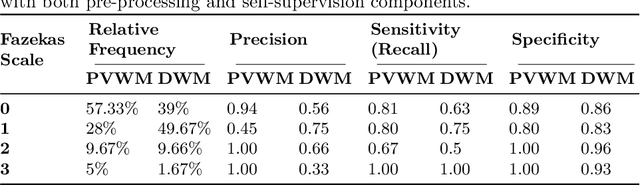
Early detection of dementia through specific biomarkers in MR images plays a critical role in developing support strategies proactively. Fazekas scale facilitates an accurate quantitative assessment of the severity of white matter lesions and hence the disease. Imaging Biomarkers of dementia are multiple and comprehensive documentation of them is time-consuming. Therefore, any effort to automatically extract these biomarkers will be of clinical value while reducing inter-rater discrepancies. To tackle this problem, we propose to classify the disease severity based on the Fazekas scale through the visual biomarkers, namely the Periventricular White Matter (PVWM) and the Deep White Matter (DWM) changes, in the real-world setting of thick-slice MRI. Small training sample size and weak supervision in form of assigning severity labels to the whole MRI stack are among the main challenges. To combat the mentioned issues, we have developed a deep learning pipeline that employs self-supervised representation learning, multiple instance learning, and appropriate pre-processing steps. We use pretext tasks such as non-linear transformation, local shuffling, in- and out-painting for self-supervised learning of useful features in this domain. Furthermore, an attention model is used to determine the relevance of each MRI slice for predicting the Fazekas scale in an unsupervised manner. We show the significant superiority of our method in distinguishing different classes of dementia compared to state-of-the-art methods in our mentioned setting, which improves the macro averaged F1-score of state-of-the-art from 61% to 76% in PVWM, and from 58% to 69.2% in DWM.
RA-GCN: Graph Convolutional Network for Disease Prediction Problems with Imbalanced Data
Feb 27, 2021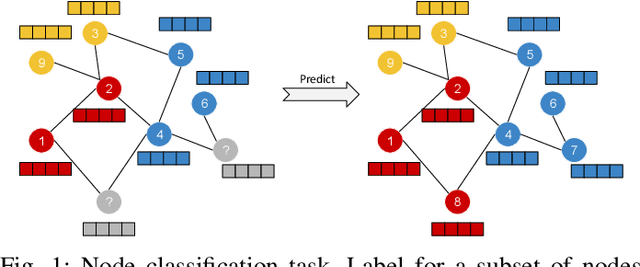
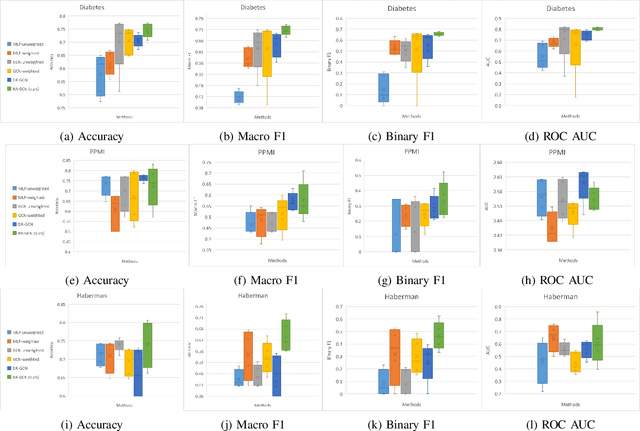
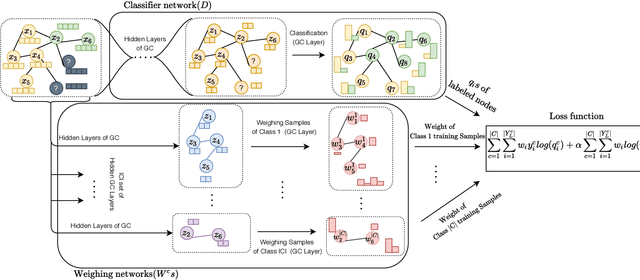
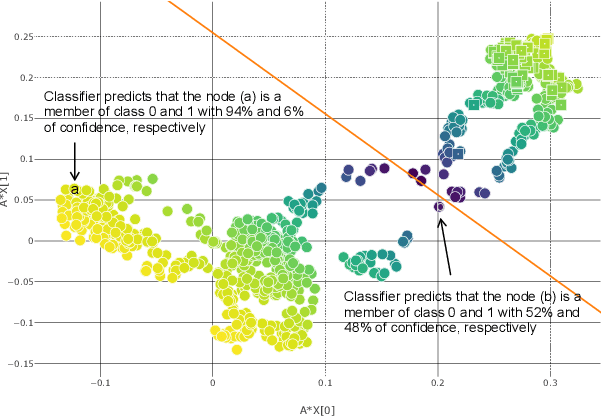
Disease prediction is a well-known classification problem in medical applications. Graph neural networks provide a powerful tool for analyzing the patients' features relative to each other. Recently, Graph Convolutional Networks (GCNs) have particularly been studied in the field of disease prediction. Due to the nature of such medical datasets, the class imbalance is a familiar issue in the field of disease prediction. When the class imbalance is present in the data, the existing graph-based classifiers tend to be biased towards the major class(es). Meanwhile, the correct diagnosis of the rare true-positive cases among all the patients is vital. In conventional methods, such imbalance is tackled by assigning appropriate weights to classes in the loss function; however, this solution is still dependent on the relative values of weights, sensitive to outliers, and in some cases biased towards the minor class(es). In this paper, we propose Re-weighted Adversarial Graph Convolutional Network (RA-GCN) to enhance the performance of the graph-based classifier and prevent it from emphasizing the samples of any particular class. This is accomplished by automatically learning to weigh the samples of the classes. For this purpose, a graph-based network is associated with each class, which is responsible for weighing the class samples and informing the classifier about the importance of each sample. Therefore, the classifier adjusts itself and determines the boundary between classes with more attention to the important samples. The parameters of the classifier and weighing networks are trained by an adversarial approach. At the end of the adversarial training process, the boundary of the classifier is more accurate and unbiased. We show the superiority of RA-GCN on synthetic and three publicly available medical datasets compared to the recent method.
Deep Graph Generators: A Survey
Dec 31, 2020
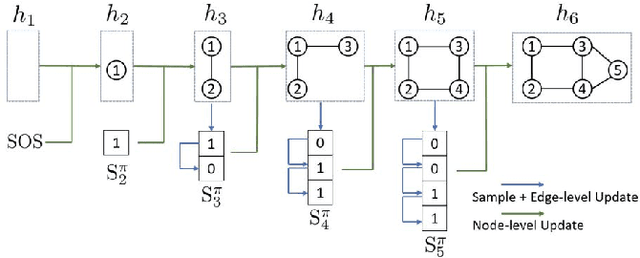
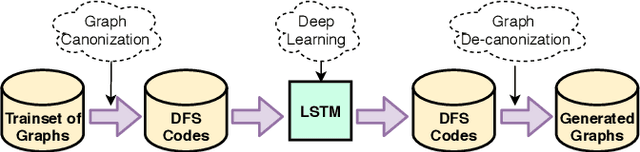
Deep generative models have achieved great success in areas such as image, speech, and natural language processing in the past few years. Thanks to the advances in graph-based deep learning, and in particular graph representation learning, deep graph generation methods have recently emerged with new applications ranging from discovering novel molecular structures to modeling social networks. This paper conducts a comprehensive survey on deep learning-based graph generation approaches and classifies them into five broad categories, namely, autoregressive, autoencoder-based, RL-based, adversarial, and flow-based graph generators, providing the readers a detailed description of the methods in each class. We also present publicly available source codes, commonly used datasets, and the most widely utilized evaluation metrics. Finally, we highlight the existing challenges and discuss future research directions.
Accurate and Rapid Diagnosis of COVID-19 Pneumonia with Batch Effect Removal of Chest CT-Scans and Interpretable Artificial Intelligence
Nov 23, 2020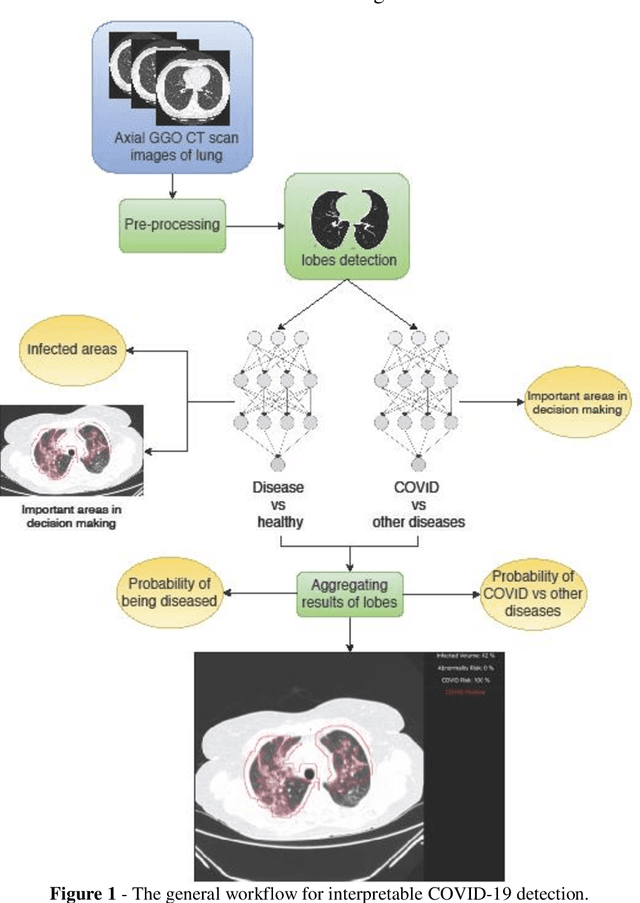

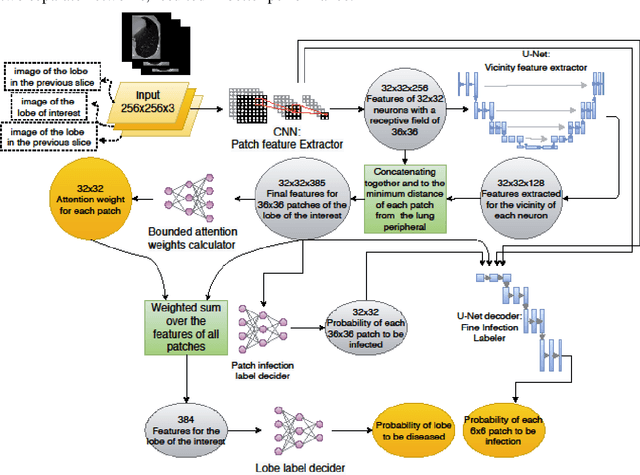

Since late 2019, COVID-19 has been spreading over the world and caused the death of many people. The high transmission rate of the virus demands the rapid identification of infected patients to reduce the spread of the disease. The current gold-standard test, Reverse-Transcription Polymerase Chain Reaction (RT-PCR), suffers from a high rate of false negatives. Diagnosis from CT-scan images as an alternative with higher accuracy and sensitivity has the challenge of distinguishing COVID-19 from other lung diseases which demand expert radiologists. In peak times, artificial intelligence (AI) based diagnostic systems can help radiologists to accelerate the process of diagnosis, increase the accuracy, and understand the severity of the disease. We designed an interpretable deep neural network to distinguish healthy people, patients with COVID-19, and patients with other lung diseases from chest CT-scan images. Our model also detects the infected areas of the lung and is able to calculate the percentage of the infected volume. We preprocessed the images to eliminate the batch effect related to CT-scan devices and medical centers and then adopted a weakly supervised method to train the model without having any label for infected parts and any tags for the slices of the CT-scan images that had signs of disease. We trained and evaluated the model on a large dataset of 3359 CT-scan images from 6 medical centers. The model reached a sensitivity of 97.75% and a specificity of 87% in separating healthy people from the diseased and a sensitivity of 98.15% and a specificity of 81.03% in distinguishing COVID-19 from other diseases. The model also reached similar metrics in 1435 samples from 6 unseen medical centers that prove its generalizability. The performance of the model on a large diverse dataset, its generalizability, and interpretability makes it suitable to be used as a diagnostic system.
Multiresolution Knowledge Distillation for Anomaly Detection
Nov 22, 2020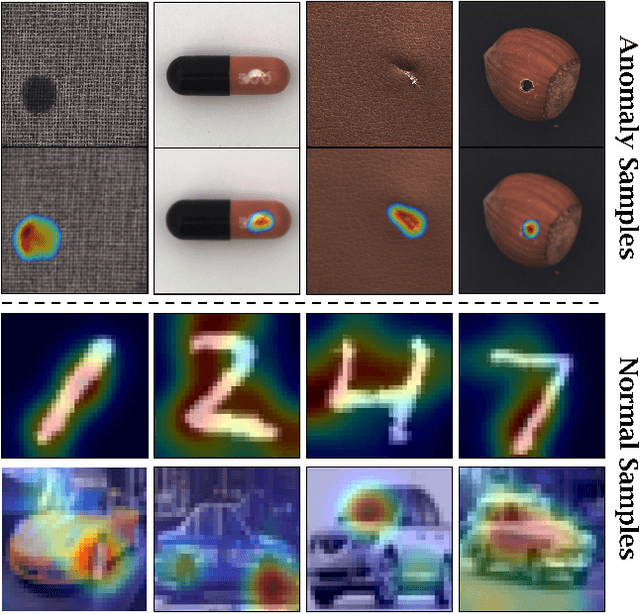
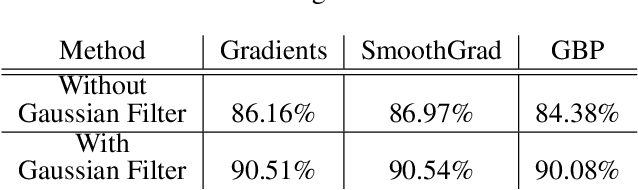
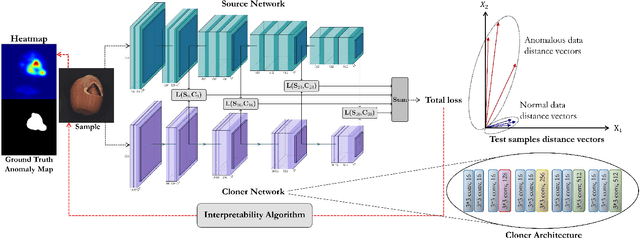
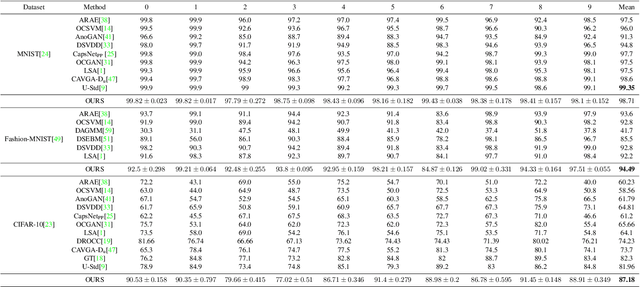
Unsupervised representation learning has proved to be a critical component of anomaly detection/localization in images. The challenges to learn such a representation are two-fold. Firstly, the sample size is not often large enough to learn a rich generalizable representation through conventional techniques. Secondly, while only normal samples are available at training, the learned features should be discriminative of normal and anomalous samples. Here, we propose to use the "distillation" of features at various layers of an expert network, pre-trained on ImageNet, into a simpler cloner network to tackle both issues. We detect and localize anomalies using the discrepancy between the expert and cloner networks' intermediate activation values given the input data. We show that considering multiple intermediate hints in distillation leads to better exploiting the expert's knowledge and more distinctive discrepancy compared to solely utilizing the last layer activation values. Notably, previous methods either fail in precise anomaly localization or need expensive region-based training. In contrast, with no need for any special or intensive training procedure, we incorporate interpretability algorithms in our novel framework for the localization of anomalous regions. Despite the striking contrast between some test datasets and ImageNet, we achieve competitive or significantly superior results compared to the SOTA methods on MNIST, F-MNIST, CIFAR-10, MVTecAD, Retinal-OCT, and two Medical datasets on both anomaly detection and localization.