 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Abnormal Activity Detection on Multivariate Time Series Healthcare Data
Sep 11, 2023


Multivariate time series (MTS) data collected from multiple sensors provide the potential for accurate abnormal activity detection in smart healthcare scenarios. However, anomalies exhibit diverse patterns and become unnoticeable in MTS data. Consequently, achieving accurate anomaly detection is challenging since we have to capture both temporal dependencies of time series and inter-relationships among variables. To address this problem, we propose a Residual-based Anomaly Detection approach, Rs-AD, for effective representation learning and abnormal activity detection. We evaluate our scheme on a real-world gait dataset and the experimental results demonstrate an F1 score of 0.839.
A Study on the Reliability of Automatic Dysarthric Speech Assessments
Jun 07, 2023

Automating dysarthria assessments offers the opportunity to develop effective, low-cost tools that address the current limitations of manual and subjective assessments. Nonetheless, it is unclear whether current approaches rely on dysarthria-related speech patterns or external factors. We aim toward obtaining a clearer understanding of dysarthria patterns. To this extent, we study the effects of noise in recordings, both through addition and reduction. We design and implement a new method for visualizing and comparing feature extractors and models, at a patient level, in a more interpretable way. We use the UA-Speech dataset with a speaker-based split of the dataset. Results reported in the literature appear to have been done irrespective of such split, leading to models that may be overconfident due to data-leakage. We hope that these results raise awareness in the research community regarding the requirements for establishing reliable automatic dysarthria assessment systems.
Evaluating The Robustness of Self-Supervised Representations to Background/Foreground Removal
Jun 02, 2023Despite impressive empirical advances of SSL in solving various tasks, the problem of understanding and characterizing SSL representations learned from input data remains relatively under-explored. We provide a comparative analysis of how the representations produced by SSL models differ when masking parts of the input. Specifically, we considered state-of-the-art SSL pretrained models, such as DINOv2, MAE, and SwaV, and analyzed changes at the representation levels across 4 Image Classification datasets. First, we generate variations of the datasets by applying foreground and background segmentation. Then, we conduct statistical analysis using Canonical Correlation Analysis (CCA) and Centered Kernel Alignment (CKA) to evaluate the robustness of the representations learned in SSL models. Empirically, we show that not all models lead to representations that separate foreground, background, and complete images. Furthermore, we test different masking strategies by occluding the center regions of the images to address cases where foreground and background are difficult. For example, the DTD dataset that focuses on texture rather specific objects.
Towards Machine Learning and Inference for Resource-constrained MCUs
May 30, 2023


Machine learning (ML) is moving towards edge devices. However, ML models with high computational demands and energy consumption pose challenges for ML inference in resource-constrained environments, such as the deep sea. To address these challenges, we propose a battery-free ML inference and model personalization pipeline for microcontroller units (MCUs). As an example, we performed fish image recognition in the ocean. We evaluated and compared the accuracy, runtime, power, and energy consumption of the model before and after optimization. The results demonstrate that, our pipeline can achieve 97.78% accuracy with 483.82 KB Flash, 70.32 KB RAM, 118 ms runtime, 4.83 mW power, and 0.57 mJ energy consumption on MCUs, reducing by 64.17%, 12.31%, 52.42%, 63.74%, and 82.67%, compared to the baseline. The results indicate the feasibility of battery-free ML inference on MCUs.
Survey of Federated Learning Models for Spatial-Temporal Mobility Applications
May 10, 2023Federated learning involves training statistical models over edge devices such as mobile phones such that the training data is kept local. Federated Learning (FL) can serve as an ideal candidate for training spatial temporal models that rely on heterogeneous and potentially massive numbers of participants while preserving the privacy of highly sensitive location data. However, there are unique challenges involved with transitioning existing spatial temporal models to decentralized learning. In this survey paper, we review the existing literature that has proposed FL-based models for predicting human mobility, traffic prediction, community detection, location-based recommendation systems, and other spatial-temporal tasks. We describe the metrics and datasets these works have been using and create a baseline of these approaches in comparison to the centralized settings. Finally, we discuss the challenges of applying spatial-temporal models in a decentralized setting and by highlighting the gaps in the literature we provide a road map and opportunities for the research community.
Federated and distributed learning applications for electronic health records and structured medical data: A scoping review
Apr 14, 2023


Federated learning (FL) has gained popularity in clinical research in recent years to facilitate privacy-preserving collaboration. Structured data, one of the most prevalent forms of clinical data, has experienced significant growth in volume concurrently, notably with the widespread adoption of electronic health records in clinical practice. This review examines FL applications on structured medical data, identifies contemporary limitations and discusses potential innovations. We searched five databases, SCOPUS, MEDLINE, Web of Science, Embase, and CINAHL, to identify articles that applied FL to structured medical data and reported results following the PRISMA guidelines. Each selected publication was evaluated from three primary perspectives, including data quality, modeling strategies, and FL frameworks. Out of the 1160 papers screened, 34 met the inclusion criteria, with each article consisting of one or more studies that used FL to handle structured clinical/medical data. Of these, 24 utilized data acquired from electronic health records, with clinical predictions and association studies being the most common clinical research tasks that FL was applied to. Only one article exclusively explored the vertical FL setting, while the remaining 33 explored the horizontal FL setting, with only 14 discussing comparisons between single-site (local) and FL (global) analysis. The existing FL applications on structured medical data lack sufficient evaluations of clinically meaningful benefits, particularly when compared to single-site analyses. Therefore, it is crucial for future FL applications to prioritize clinical motivations and develop designs and methodologies that can effectively support and aid clinical practice and research.
Analysing Fairness of Privacy-Utility Mobility Models
Apr 10, 2023



Preserving the individuals' privacy in sharing spatial-temporal datasets is critical to prevent re-identification attacks based on unique trajectories. Existing privacy techniques tend to propose ideal privacy-utility tradeoffs, however, largely ignore the fairness implications of mobility models and whether such techniques perform equally for different groups of users. The quantification between fairness and privacy-aware models is still unclear and there barely exists any defined sets of metrics for measuring fairness in the spatial-temporal context. In this work, we define a set of fairness metrics designed explicitly for human mobility, based on structural similarity and entropy of the trajectories. Under these definitions, we examine the fairness of two state-of-the-art privacy-preserving models that rely on GAN and representation learning to reduce the re-identification rate of users for data sharing. Our results show that while both models guarantee group fairness in terms of demographic parity, they violate individual fairness criteria, indicating that users with highly similar trajectories receive disparate privacy gain. We conclude that the tension between the re-identification task and individual fairness needs to be considered for future spatial-temporal data analysis and modelling to achieve a privacy-preserving fairness-aware setting.
Information Theory Inspired Pattern Analysis for Time-series Data
Feb 22, 2023



Current methods for pattern analysis in time series mainly rely on statistical features or probabilistic learning and inference methods to identify patterns and trends in the data. Such methods do not generalize well when applied to multivariate, multi-source, state-varying, and noisy time-series data. To address these issues, we propose a highly generalizable method that uses information theory-based features to identify and learn from patterns in multivariate time-series data. To demonstrate the proposed approach, we analyze pattern changes in human activity data. For applications with stochastic state transitions, features are developed based on Shannon's entropy of Markov chains, entropy rates of Markov chains, entropy production of Markov chains, and von Neumann entropy of Markov chains. For applications where state modeling is not applicable, we utilize five entropy variants, including approximate entropy, increment entropy, dispersion entropy, phase entropy, and slope entropy. The results show the proposed information theory-based features improve the recall rate, F1 score, and accuracy on average by up to 23.01\% compared with the baseline models and a simpler model structure, with an average reduction of 18.75 times in the number of model parameters.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022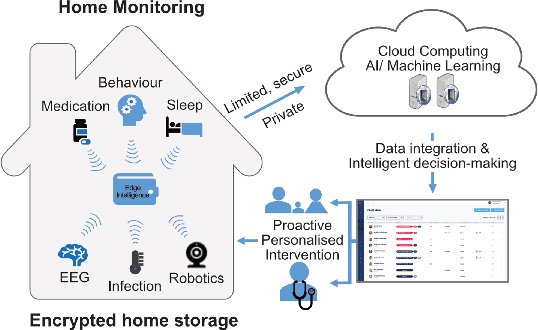
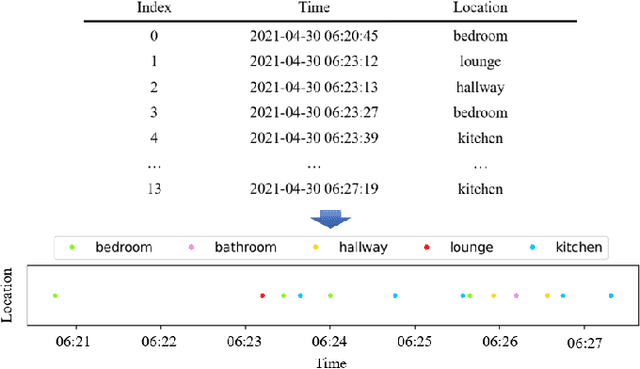
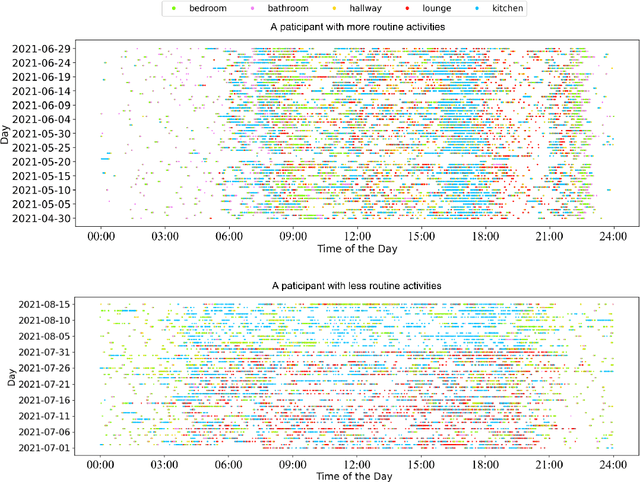
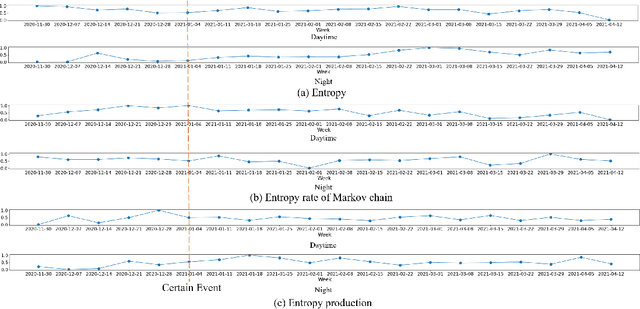
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
SoK: Machine Learning with Confidential Computing
Aug 22, 2022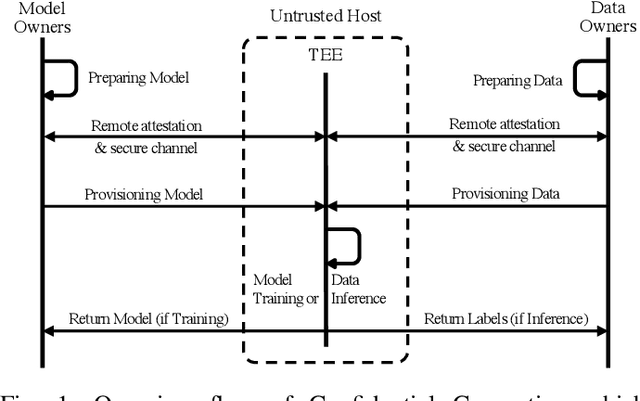
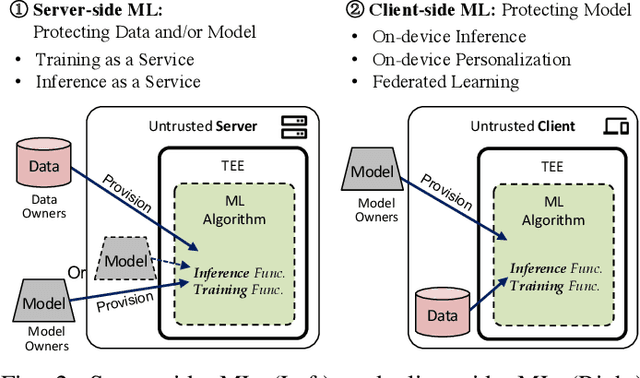
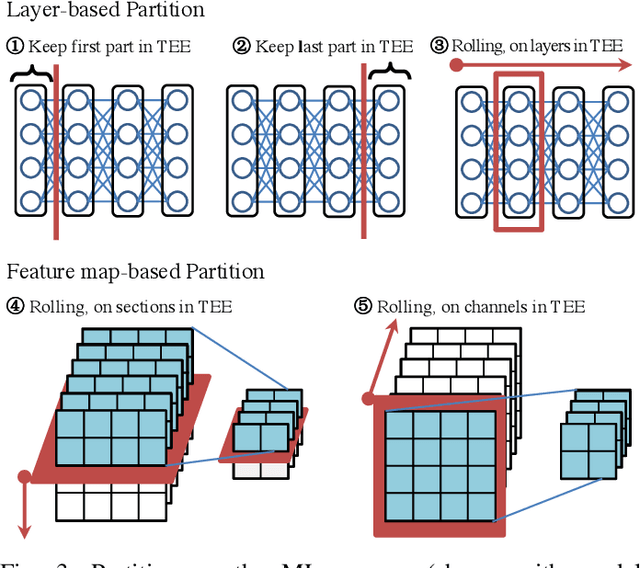
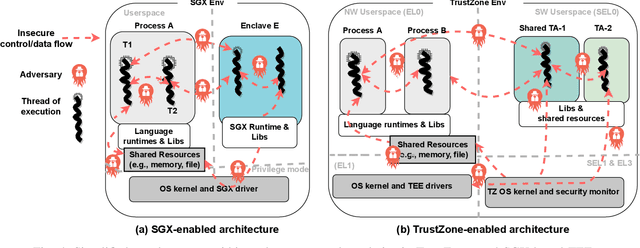
Privacy and security challenges in Machine Learning (ML) have become a critical topic to address, along with ML's pervasive development and the recent demonstration of large attack surfaces. As a mature system-oriented approach, confidential computing has been increasingly utilized in both academia and industry to improve privacy and security in various ML scenarios. In this paper, we systematize the findings on confidential computing-assisted ML security and privacy techniques for providing i) confidentiality guarantees and ii) integrity assurances. We further identify key challenges and provide dedicated analyses of the limitations in existing Trusted Execution Environment (TEE) systems for ML use cases. We discuss prospective works, including grounded privacy definitions, partitioned ML executions, dedicated TEE designs for ML, TEE-aware ML, and ML full pipeline guarantee. These potential solutions can help achieve a much strong TEE-enabled ML for privacy guarantees without introducing computation and system costs.