 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Learning for Conditional Adversarial Networks
Jan 21, 2018

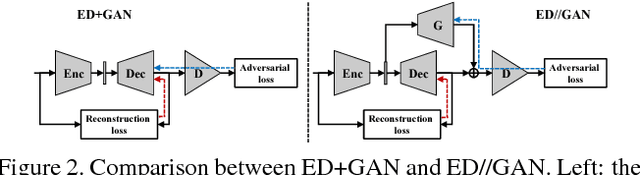
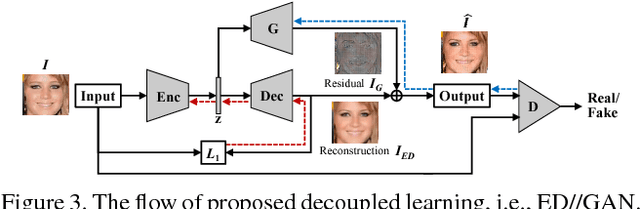
Incorporating encoding-decoding nets with adversarial nets has been widely adopted in image generation tasks. We observe that the state-of-the-art achievements were obtained by carefully balancing the reconstruction loss and adversarial loss, and such balance shifts with different network structures, datasets, and training strategies. Empirical studies have demonstrated that an inappropriate weight between the two losses may cause instability, and it is tricky to search for the optimal setting, especially when lacking prior knowledge on the data and network. This paper gives the first attempt to relax the need of manual balancing by proposing the concept of \textit{decoupled learning}, where a novel network structure is designed that explicitly disentangles the backpropagation paths of the two losses. Experimental results demonstrate the effectiveness, robustness, and generality of the proposed method. The other contribution of the paper is the design of a new evaluation metric to measure the image quality of generative models. We propose the so-called \textit{normalized relative discriminative score} (NRDS), which introduces the idea of relative comparison, rather than providing absolute estimates like existing metrics.
r-BTN: Cross-domain Face Composite and Synthesis from Limited Facial Patches
Dec 06, 2017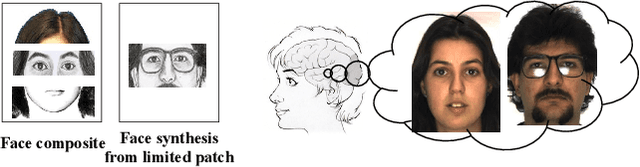
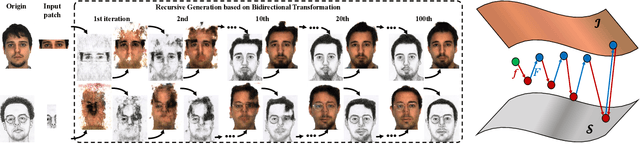
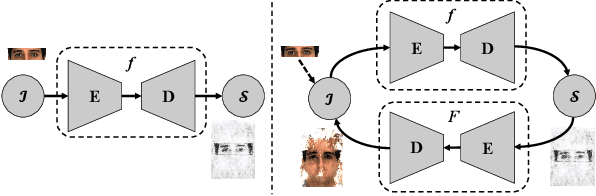
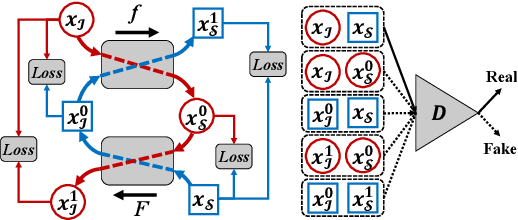
We start by asking an interesting yet challenging question, "If an eyewitness can only recall the eye features of the suspect, such that the forensic artist can only produce a sketch of the eyes (e.g., the top-left sketch shown in Fig. 1), can advanced computer vision techniques help generate the whole face image?" A more generalized question is that if a large proportion (e.g., more than 50%) of the face/sketch is missing, can a realistic whole face sketch/image still be estimated. Existing face completion and generation methods either do not conduct domain transfer learning or can not handle large missing area. For example, the inpainting approach tends to blur the generated region when the missing area is large (i.e., more than 50%). In this paper, we exploit the potential of deep learning networks in filling large missing region (e.g., as high as 95% missing) and generating realistic faces with high-fidelity in cross domains. We propose the recursive generation by bidirectional transformation networks (r-BTN) that recursively generates a whole face/sketch from a small sketch/face patch. The large missing area and the cross domain challenge make it difficult to generate satisfactory results using a unidirectional cross-domain learning structure. On the other hand, a forward and backward bidirectional learning between the face and sketch domains would enable recursive estimation of the missing region in an incremental manner (Fig. 1) and yield appealing results. r-BTN also adopts an adversarial constraint to encourage the generation of realistic faces/sketches. Extensive experiments have been conducted to demonstrate the superior performance from r-BTN as compared to existing potential solutions.
Feature Encoding in Band-limited Distributed Surveillance Systems
Jun 06, 2017

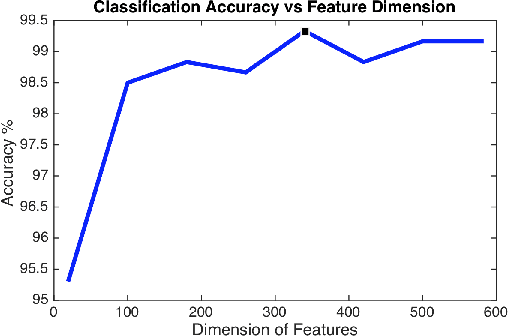
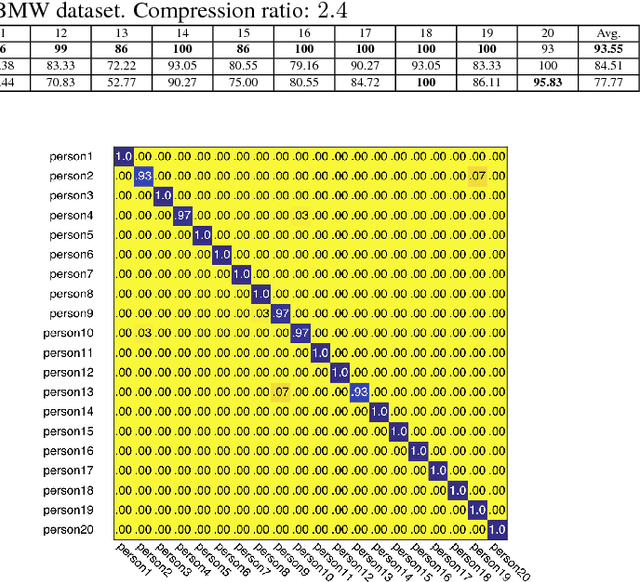
Distributed surveillance systems have become popular in recent years due to security concerns. However, transmitting high dimensional data in bandwidth-limited distributed systems becomes a major challenge. In this paper, we address this issue by proposing a novel probabilistic algorithm based on the divergence between the probability distributions of the visual features in order to reduce their dimensionality and thus save the network bandwidth in distributed wireless smart camera networks. We demonstrate the effectiveness of the proposed approach through extensive experiments on two surveillance recognition tasks.
End-to-end Binary Representation Learning via Direct Binary Embedding
Jun 04, 2017
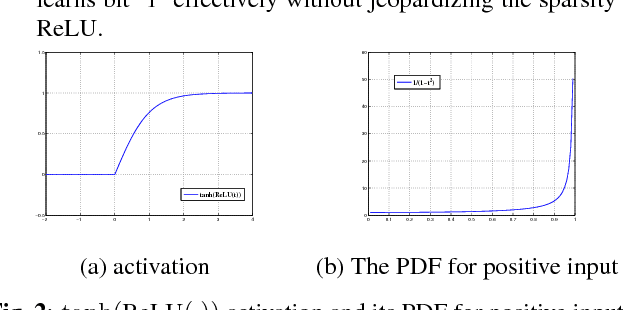

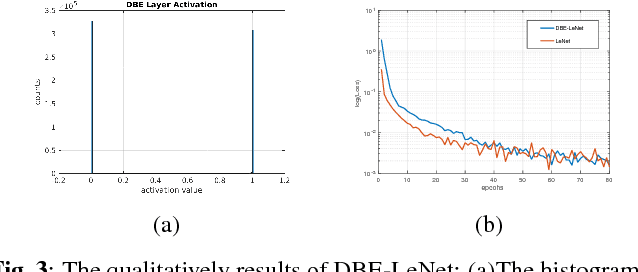
Learning binary representation is essential to large-scale computer vision tasks. Most existing algorithms require a separate quantization constraint to learn effective hashing functions. In this work, we present Direct Binary Embedding (DBE), a simple yet very effective algorithm to learn binary representation in an end-to-end fashion. By appending an ingeniously designed DBE layer to the deep convolutional neural network (DCNN), DBE learns binary code directly from the continuous DBE layer activation without quantization error. By employing the deep residual network (ResNet) as DCNN component, DBE captures rich semantics from images. Furthermore, in the effort of handling multilabel images, we design a joint cross entropy loss that includes both softmax cross entropy and weighted binary cross entropy in consideration of the correlation and independence of labels, respectively. Extensive experiments demonstrate the significant superiority of DBE over state-of-the-art methods on tasks of natural object recognition, image retrieval and image annotation.
Multi-View Task-Driven Recognition in Visual Sensor Networks
May 31, 2017


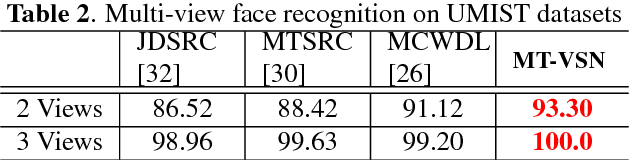
Nowadays, distributed smart cameras are deployed for a wide set of tasks in several application scenarios, ranging from object recognition, image retrieval, and forensic applications. Due to limited bandwidth in distributed systems, efficient coding of local visual features has in fact been an active topic of research. In this paper, we propose a novel approach to obtain a compact representation of high-dimensional visual data using sensor fusion techniques. We convert the problem of visual analysis in resource-limited scenarios to a multi-view representation learning, and we show that the key to finding properly compressed representation is to exploit the position of cameras with respect to each other as a norm-based regularization in the particular signal representation of sparse coding. Learning the representation of each camera is viewed as an individual task and a multi-task learning with joint sparsity for all nodes is employed. The proposed representation learning scheme is referred to as the multi-view task-driven learning for visual sensor network (MT-VSN). We demonstrate that MT-VSN outperforms state-of-the-art in various surveillance recognition tasks.
Addressing Ambiguity in Multi-target Tracking by Hierarchical Strategy
May 30, 2017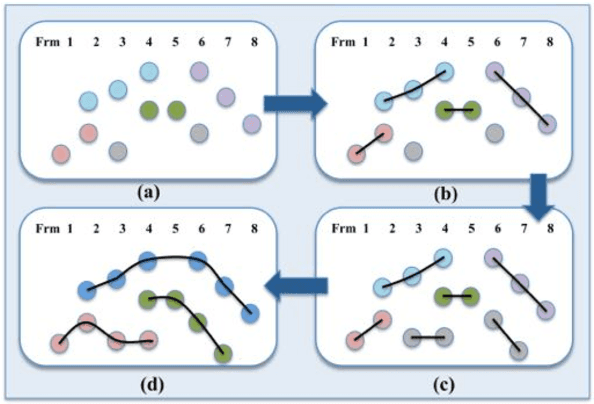
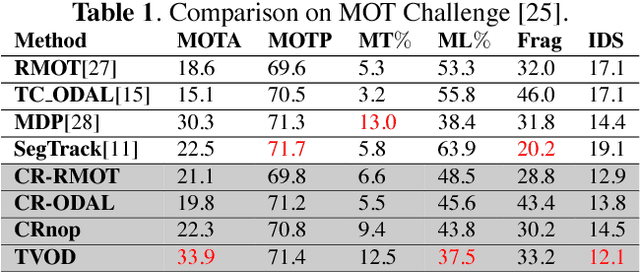
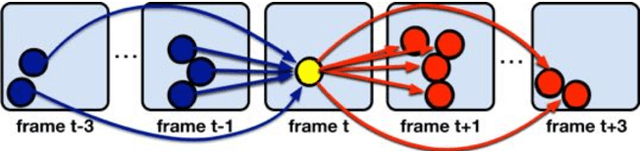
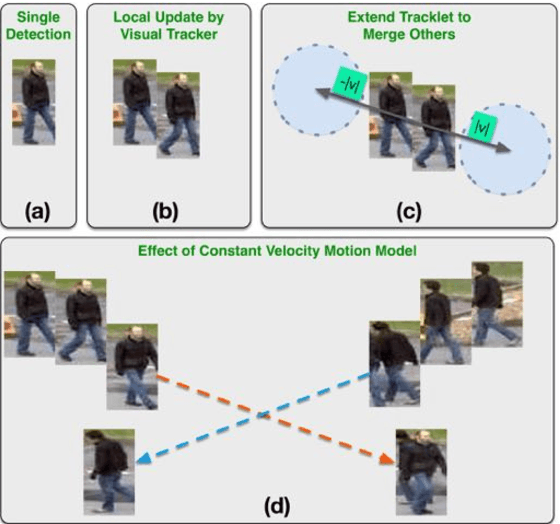
This paper presents a novel hierarchical approach for the simultaneous tracking of multiple targets in a video. We use a network flow approach to link detections in low-level and tracklets in high-level. At each step of the hierarchy, the confidence of candidates is measured by using a new scoring system, ConfRank, that considers the quality and the quantity of its neighborhood. The output of the first stage is a collection of safe tracklets and unlinked high-confidence detections. For each individual detection, we determine if it belongs to an existing or is a new tracklet. We show the effect of our framework to recover missed detections and reduce switch identity. The proposed tracker is referred to as TVOD for multi-target tracking using the visual tracker and generic object detector. We achieve competitive results with lower identity switches on several datasets comparing to state-of-the-art.
Age Progression/Regression by Conditional Adversarial Autoencoder
Mar 28, 2017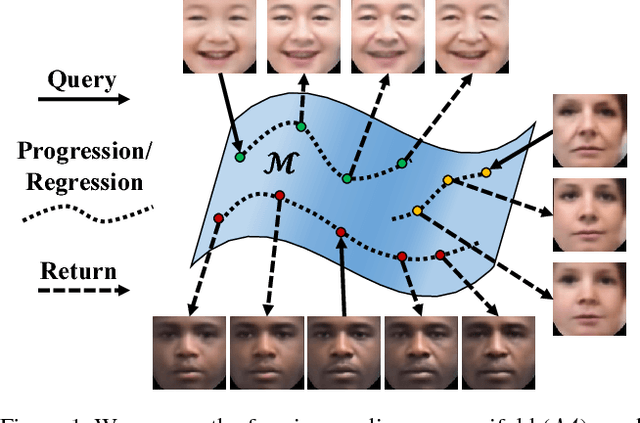
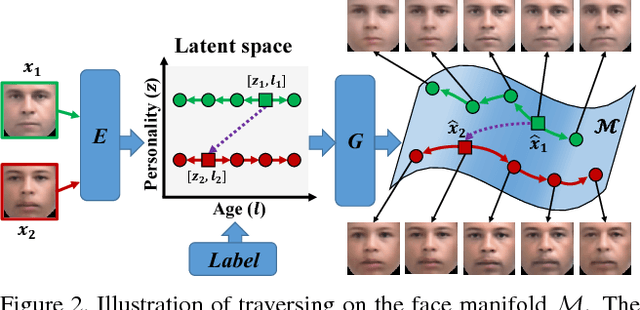
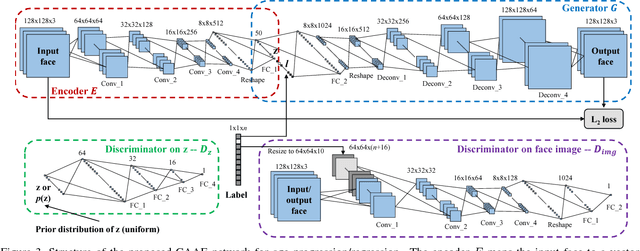

"If I provide you a face image of mine (without telling you the actual age when I took the picture) and a large amount of face images that I crawled (containing labeled faces of different ages but not necessarily paired), can you show me what I would look like when I am 80 or what I was like when I was 5?" The answer is probably a "No." Most existing face aging works attempt to learn the transformation between age groups and thus would require the paired samples as well as the labeled query image. In this paper, we look at the problem from a generative modeling perspective such that no paired samples is required. In addition, given an unlabeled image, the generative model can directly produce the image with desired age attribute. We propose a conditional adversarial autoencoder (CAAE) that learns a face manifold, traversing on which smooth age progression and regression can be realized simultaneously. In CAAE, the face is first mapped to a latent vector through a convolutional encoder, and then the vector is projected to the face manifold conditional on age through a deconvolutional generator. The latent vector preserves personalized face features (i.e., personality) and the age condition controls progression vs. regression. Two adversarial networks are imposed on the encoder and generator, respectively, forcing to generate more photo-realistic faces. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.
Derivative Delay Embedding: Online Modeling of Streaming Time Series
Sep 24, 2016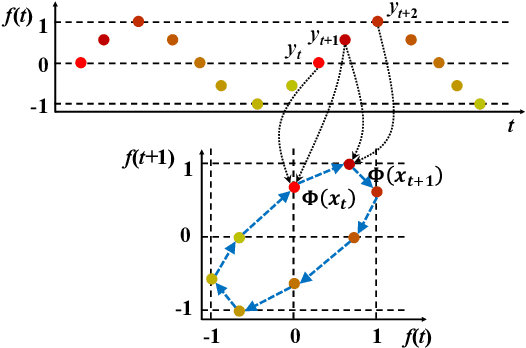
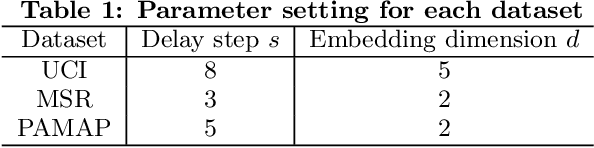
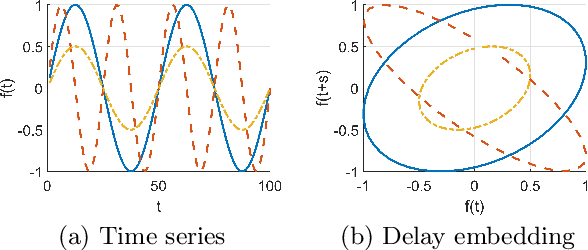
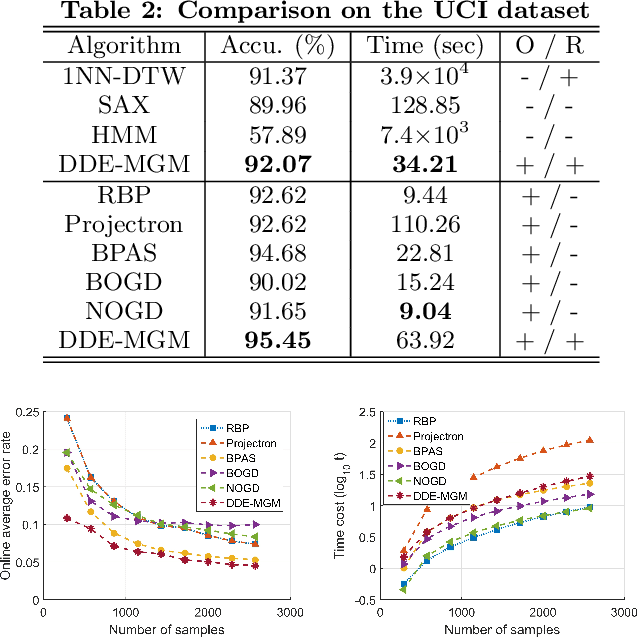
The staggering amount of streaming time series coming from the real world calls for more efficient and effective online modeling solution. For time series modeling, most existing works make some unrealistic assumptions such as the input data is of fixed length or well aligned, which requires extra effort on segmentation or normalization of the raw streaming data. Although some literature claim their approaches to be invariant to data length and misalignment, they are too time-consuming to model a streaming time series in an online manner. We propose a novel and more practical online modeling and classification scheme, DDE-MGM, which does not make any assumptions on the time series while maintaining high efficiency and state-of-the-art performance. The derivative delay embedding (DDE) is developed to incrementally transform time series to the embedding space, where the intrinsic characteristics of data is preserved as recursive patterns regardless of the stream length and misalignment. Then, a non-parametric Markov geographic model (MGM) is proposed to both model and classify the pattern in an online manner. Experimental results demonstrate the effectiveness and superior classification accuracy of the proposed DDE-MGM in an online setting as compared to the state-of-the-art.
Image color transfer to evoke different emotions based on color combinations
Nov 02, 2014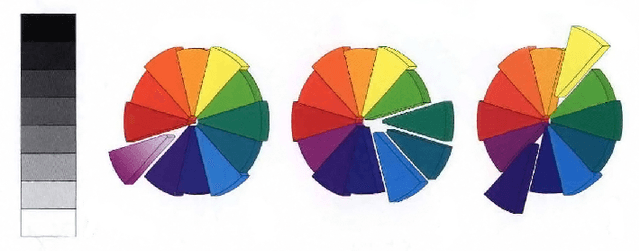

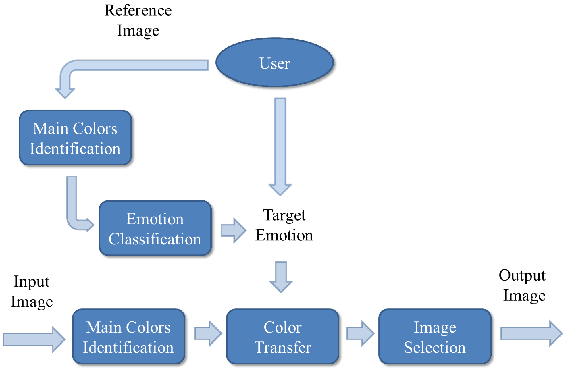
In this paper, a color transfer framework to evoke different emotions for images based on color combinations is proposed. The purpose of this color transfer is to change the "look and feel" of images, i.e., evoking different emotions. Colors are confirmed as the most attractive factor in images. In addition, various studies in both art and science areas have concluded that other than single color, color combinations are necessary to evoke specific emotions. Therefore, we propose a novel framework to transfer color of images based on color combinations, using a predefined color emotion model. The contribution of this new framework is three-fold. First, users do not need to provide reference images as used in traditional color transfer algorithms. In most situations, users may not have enough aesthetic knowledge or path to choose desired reference images. Second, because of the usage of color combinations instead of single color for emotions, a new color transfer algorithm that does not require an image library is proposed. Third, again because of the usage of color combinations, artifacts that are normally seen in traditional frameworks using single color are avoided. We present encouraging results generated from this new framework and its potential in several possible applications including color transfer of photos and paintings.