 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Construction of Multiple Classification Dimensions for Managing Approaches in Scientific Papers
May 29, 2025



Approaches form the foundation for conducting scientific research. Querying approaches from a vast body of scientific papers is extremely time-consuming, and without a well-organized management framework, researchers may face significant challenges in querying and utilizing relevant approaches. Constructing multiple dimensions on approaches and managing them from these dimensions can provide an efficient solution. Firstly, this paper identifies approach patterns using a top-down way, refining the patterns through four distinct linguistic levels: semantic level, discourse level, syntactic level, and lexical level. Approaches in scientific papers are extracted based on approach patterns. Additionally, five dimensions for categorizing approaches are identified using these patterns. This paper proposes using tree structure to represent step and measuring the similarity between different steps with a tree-structure-based similarity measure that focuses on syntactic-level similarities. A collection similarity measure is proposed to compute the similarity between approaches. A bottom-up clustering algorithm is proposed to construct class trees for approach components within each dimension by merging each approach component or class with its most similar approach component or class in each iteration. The class labels generated during the clustering process indicate the common semantics of the step components within the approach components in each class and are used to manage the approaches within the class. The class trees of the five dimensions collectively form a multi-dimensional approach space. The application of approach queries on the multi-dimensional approach space demonstrates that querying within this space ensures strong relevance between user queries and results and rapidly reduces search space through a class-based query mechanism.
Subspace Aggregation Query and Index Generation for Multidimensional Resource Space Mode
May 04, 2025



Organizing resources in a multidimensional classification space is an approach to efficiently managing and querying large-scale resources. This paper defines an aggregation query on subspace defined by a range on the partial order on coordinate tree at each dimension, where each point contains resources aggregated along the paths of partial order relations on the points so that aggregated resources at each point within the subspace can be measured, ranked and selected. To efficiently locate non-empty points in a large subspace, an approach to generating graph index is proposed to build inclusion links with partial order relations on coordinates of dimensions to enable a subspace query to reach non-empty points by following indexing links and aggregate resources along indexing paths back to their super points. Generating such an index is costly as the number of children of an index node can be very large so that the total number of indexing nodes is unbounded. The proposed approach adopts the following strategies to reduce the cost: (1) adding intersection links between two indexing nodes, which can better reduce query processing costs while controlling the number of nodes of the graph index; (2) intersection links are added between two nodes according to the probabilistic distribution calculated for estimating the costs of adding intersection between two nodes; (3) coordinates at one dimension having more resources are split by coordinates at another dimension to balance the number of resources hold by indexing nodes; and, (4) short-cut links are added between sibling coordinates of coordinate trees to make an efficient query on linear order coordinates. Analysis and experiments verified the effectiveness of the generated index in supporting subspace aggregation query. This work makes significant contributions to the development of data model based on multi-dimensional classification.
Extracting Abstraction Dimensions by Identifying Syntax Pattern from Texts
Apr 26, 2025This paper proposed an approach to automatically discovering subject dimension, action dimension, object dimension and adverbial dimension from texts to efficiently operate texts and support query in natural language. The high quality of trees guarantees that all subjects, actions, objects and adverbials and their subclass relations within texts can be represented. The independency of trees ensures that there is no redundant representation between trees. The expressiveness of trees ensures that the majority of sentences can be accessed from each tree and the rest of sentences can be accessed from at least one tree so that the tree-based search mechanism can support querying in natural language. Experiments show that the average precision, recall and F1-score of the abstraction trees constructed by the subclass relations of subject, action, object and adverbial are all greater than 80%. The application of the proposed approach to supporting query in natural language demonstrates that different types of question patterns for querying subject or object have high coverage of texts, and searching multiple trees on subject, action, object and adverbial according to the question pattern can quickly reduce search space to locate target sentences, which can support precise operation on texts.
Discovering Patterns of Definitions and Methods from Scientific Documents
Jul 01, 2023



The difficulties of automatic extraction of definitions and methods from scientific documents lie in two aspects: (1) the complexity and diversity of natural language texts, which requests an analysis method to support the discovery of pattern; and, (2) a complete definition or method represented by a scientific paper is usually distributed within text, therefore an effective approach should not only extract single sentence definitions and methods but also integrate the sentences to obtain a complete definition or method. This paper proposes an analysis method for discovering patterns of definition and method and uses the method to discover patterns of definition and method. Completeness of the patterns at the semantic level is guaranteed by a complete set of semantic relations that identify definitions and methods respectively. The completeness of the patterns at the syntactic and lexical levels is guaranteed by syntactic and lexical constraints. Experiments on the self-built dataset and two public definition datasets show that the discovered patterns are effective. The patterns can be used to extract definitions and methods from scientific documents and can be tailored or extended to suit other applications.
Mapping Big Data into Knowledge Space with Cognitive Cyber-Infrastructure
Jul 18, 2015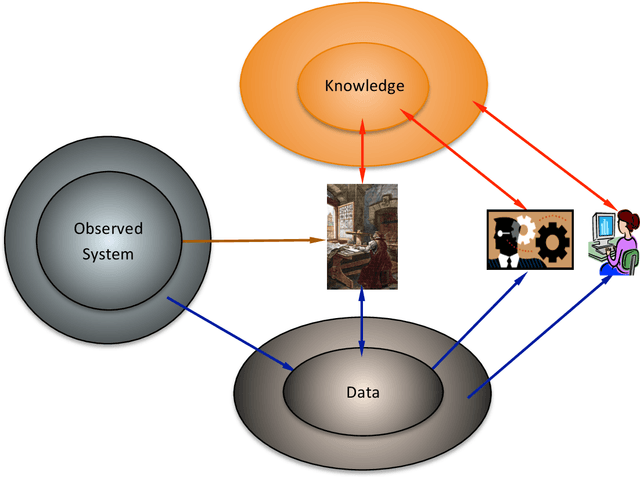
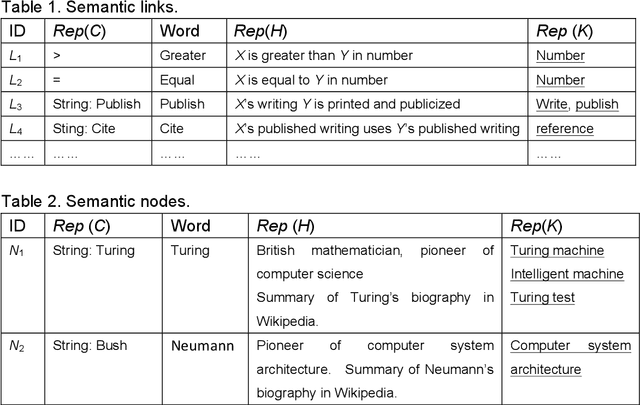

Big data research has attracted great attention in science, technology, industry and society. It is developing with the evolving scientific paradigm, the fourth industrial revolution, and the transformational innovation of technologies. However, its nature and fundamental challenge have not been recognized, and its own methodology has not been formed. This paper explores and answers the following questions: What is big data? What are the basic methods for representing, managing and analyzing big data? What is the relationship between big data and knowledge? Can we find a mapping from big data into knowledge space? What kind of infrastructure is required to support not only big data management and analysis but also knowledge discovery, sharing and management? What is the relationship between big data and science paradigm? What is the nature and fundamental challenge of big data computing? A multi-dimensional perspective is presented toward a methodology of big data computing.
Dimensionality on Summarization
Jul 01, 2015



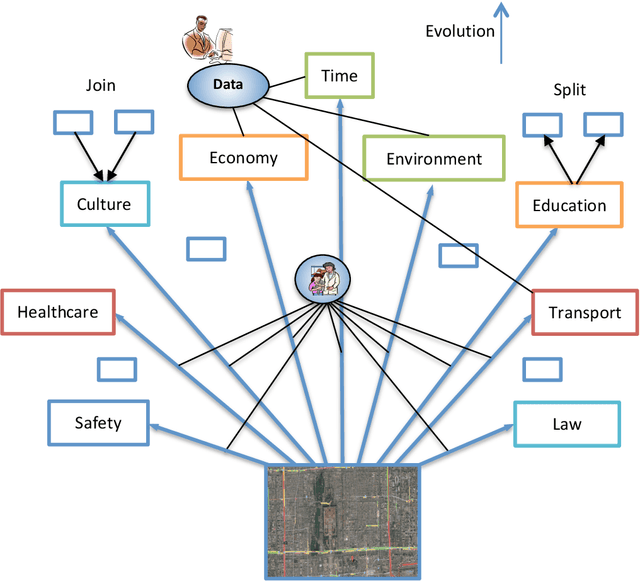
Summarization is one of the key features of human intelligence. It plays an important role in understanding and representation. With rapid and continual expansion of texts, pictures and videos in cyberspace, automatic summarization becomes more and more desirable. Text summarization has been studied for over half century, but it is still hard to automatically generate a satisfied summary. Traditional methods process texts empirically and neglect the fundamental characteristics and principles of language use and understanding. This paper summarizes previous text summarization approaches in a multi-dimensional classification space, introduces a multi-dimensional methodology for research and development, unveils the basic characteristics and principles of language use and understanding, investigates some fundamental mechanisms of summarization, studies the dimensions and forms of representations, and proposes a multi-dimensional evaluation mechanisms. Investigation extends to the incorporation of pictures into summary and to the summarization of videos, graphs and pictures, and then reaches a general summarization framework.
Topological Centrality and Its Applications
Feb 11, 2009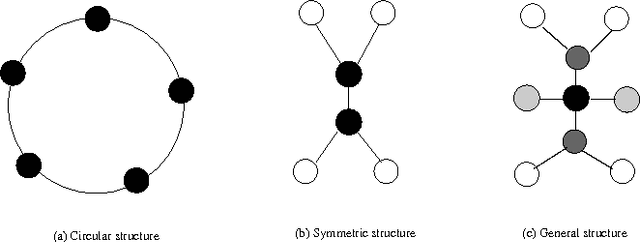
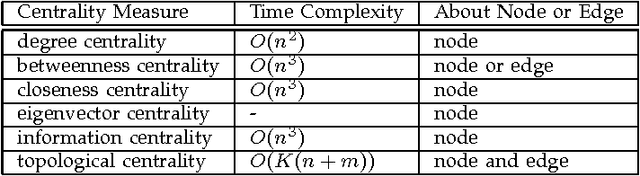
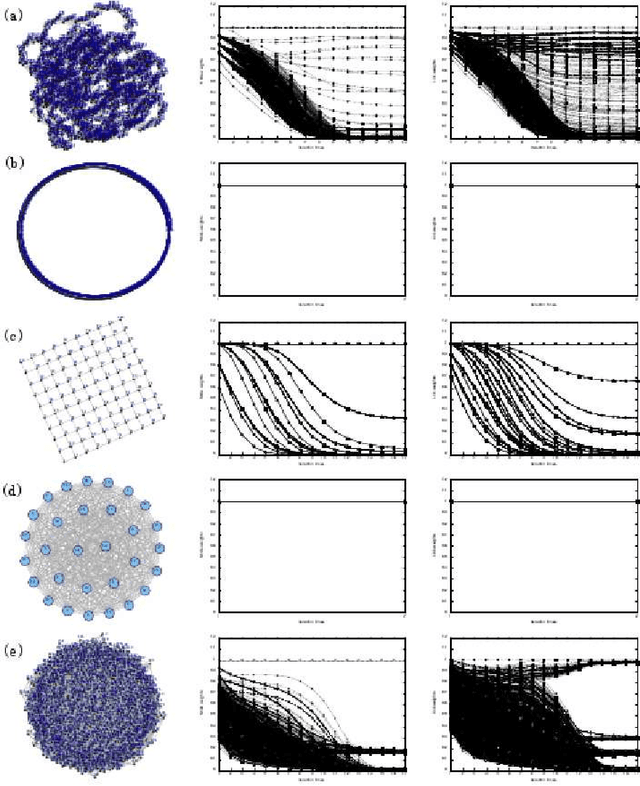
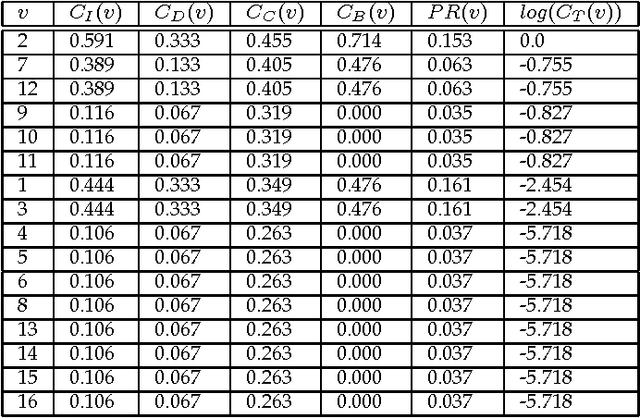
Recent development of network structure analysis shows that it plays an important role in characterizing complex system of many branches of sciences. Different from previous network centrality measures, this paper proposes the notion of topological centrality (TC) reflecting the topological positions of nodes and edges in general networks, and proposes an approach to calculating the topological centrality. The proposed topological centrality is then used to discover communities and build the backbone network. Experiments and applications on research network show the significance of the proposed approach.