 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Aggregation Query and Index Generation for Multidimensional Resource Space Mode
May 04, 2025



Organizing resources in a multidimensional classification space is an approach to efficiently managing and querying large-scale resources. This paper defines an aggregation query on subspace defined by a range on the partial order on coordinate tree at each dimension, where each point contains resources aggregated along the paths of partial order relations on the points so that aggregated resources at each point within the subspace can be measured, ranked and selected. To efficiently locate non-empty points in a large subspace, an approach to generating graph index is proposed to build inclusion links with partial order relations on coordinates of dimensions to enable a subspace query to reach non-empty points by following indexing links and aggregate resources along indexing paths back to their super points. Generating such an index is costly as the number of children of an index node can be very large so that the total number of indexing nodes is unbounded. The proposed approach adopts the following strategies to reduce the cost: (1) adding intersection links between two indexing nodes, which can better reduce query processing costs while controlling the number of nodes of the graph index; (2) intersection links are added between two nodes according to the probabilistic distribution calculated for estimating the costs of adding intersection between two nodes; (3) coordinates at one dimension having more resources are split by coordinates at another dimension to balance the number of resources hold by indexing nodes; and, (4) short-cut links are added between sibling coordinates of coordinate trees to make an efficient query on linear order coordinates. Analysis and experiments verified the effectiveness of the generated index in supporting subspace aggregation query. This work makes significant contributions to the development of data model based on multi-dimensional classification.
What Makes it Difficult to Understand a Scientific Literature?
Dec 04, 2015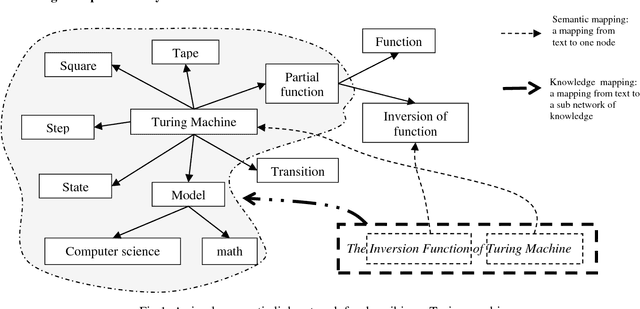
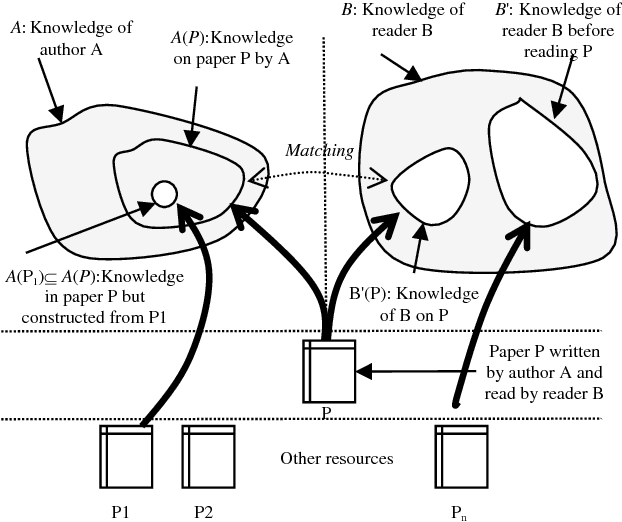
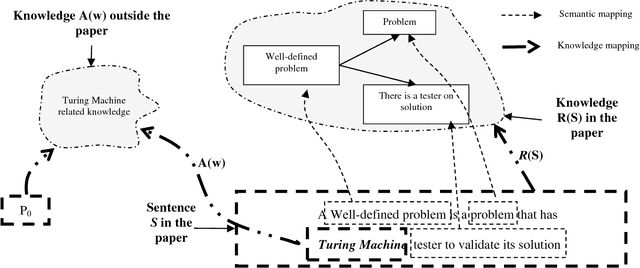
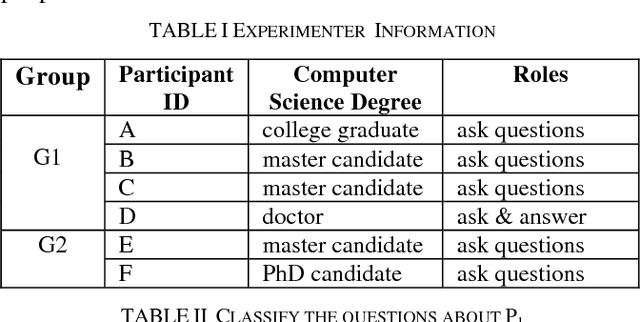
In the artificial intelligence area, one of the ultimate goals is to make computers understand human language and offer assistance. In order to achieve this ideal, researchers of computer science have put forward a lot of models and algorithms attempting at enabling the machine to analyze and process human natural language on different levels of semantics. Although recent progress in this field offers much hope, we still have to ask whether current research can provide assistance that people really desire in reading and comprehension. To this end, we conducted a reading comprehension test on two scientific papers which are written in different styles. We use the semantic link models to analyze the understanding obstacles that people will face in the process of reading and figure out what makes it difficult for human to understand a scientific literature. Through such analysis, we summarized some characteristics and problems which are reflected by people with different levels of knowledge on the comprehension of difficult science and technology literature, which can be modeled in semantic link network. We believe that these characteristics and problems will help us re-examine the existing machine models and are helpful in the designing of new one.