 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralAnnot: Neural Annotator for in-the-wild Expressive 3D Human Pose and Mesh Training Sets
Nov 28, 2020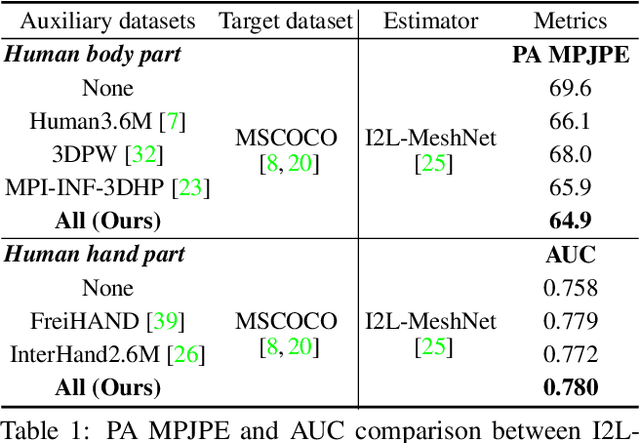
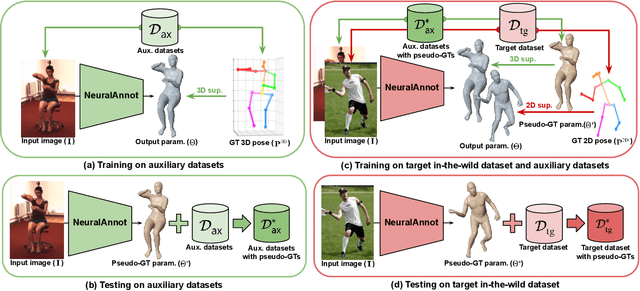

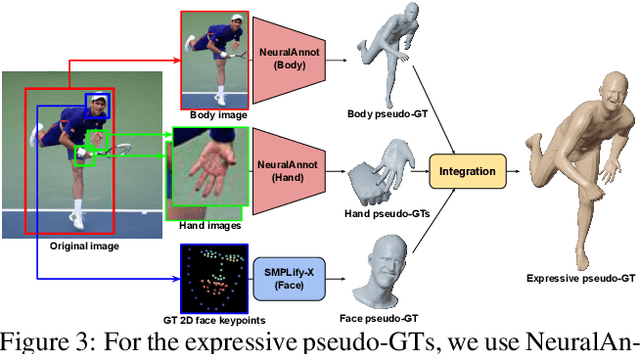
Recovering expressive 3D human pose and mesh from in-the-wild images is greatly challenging due to the absence of the training data. Several optimization-based methods have been used to obtain pseudo-groundtruth (GT) 3D poses and meshes from GT 2D poses. However, they often produce bad ones with long running time because their frameworks are optimized on each sample only using 2D supervisions in a sequential way. To overcome the limitations, we present NeuralAnnot, a neural annotator that learns to construct in-the-wild expressive 3D human pose and mesh training sets. Our NeuralAnnot is trained on a large number of samples by 2D supervisions from a target in-the-wild dataset and 3D supervisions from auxiliary datasets with GT 3D poses in a parallel way. We show that our NeuralAnnot produces far better 3D pseudo-GTs with much shorter running time than the optimization-based methods, and the newly obtained training set brings great performance gain. The newly obtained training sets and codes will be publicly available.
Pose2Pose: 3D Positional Pose-Guided 3D Rotational Pose Prediction for Expressive 3D Human Pose and Mesh Estimation
Nov 28, 2020
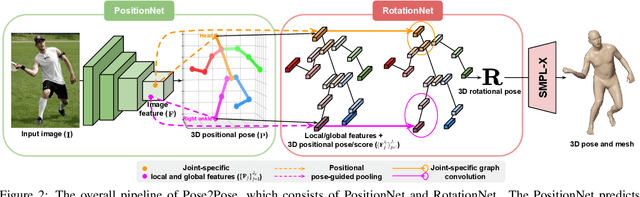

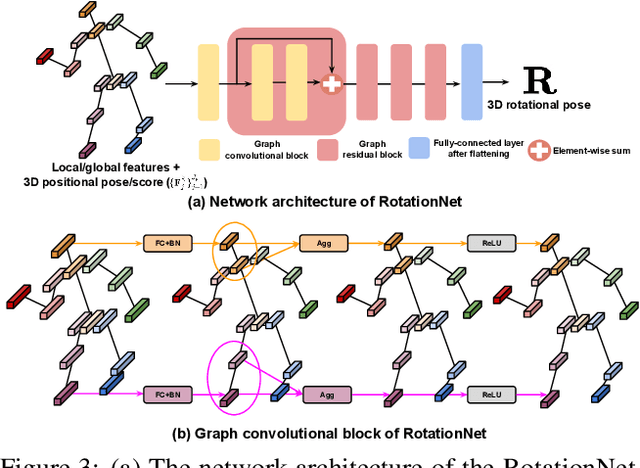
Previous 3D human pose and mesh estimation methods mostly rely on only global image feature to predict 3D rotations of human joints (i.e., 3D rotational pose) from an input image. However, local features on the position of human joints (i.e., positional pose) can provide joint-specific information, which is essential to understand human articulation. To effectively utilize both local and global features, we present Pose2Pose, a 3D positional pose-guided 3D rotational pose prediction network, along with a positional pose-guided pooling and joint-specific graph convolution. The positional pose-guided pooling extracts useful joint-specific local and global features. Also, the joint-specific graph convolution effectively processes the joint-specific features by learning joint-specific characteristics and different relationships between different joints. We use Pose2Pose for expressive 3D human pose and mesh estimation and show that it outperforms all previous part-specific and expressive methods by a large margin. The codes will be publicly available.
Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video
Nov 26, 2020
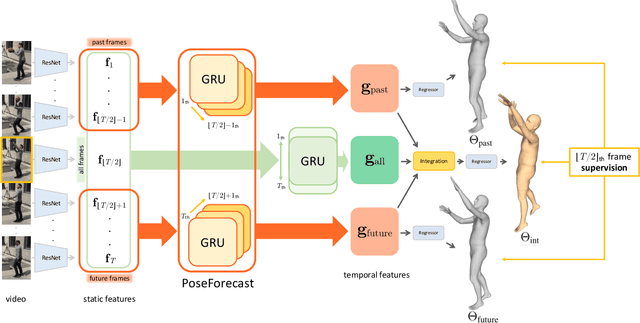

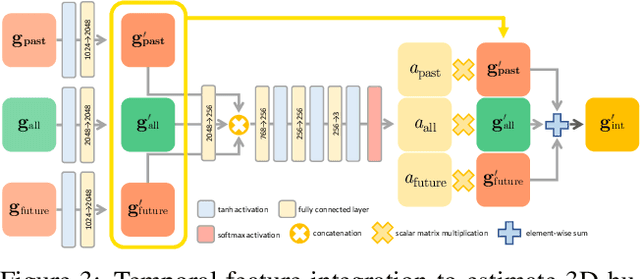
Despite the recent success of single image-based 3D human pose and shape estimation methods, recovering temporally consistent and smooth 3D human motion from a video is still challenging. Several video-based methods have been proposed; however, they fail to resolve the single image-based methods' temporal inconsistency issue due to a strong dependency on a static feature of the current frame. In this regard, we present a temporally consistent mesh recovery system (TCMR). It effectively focuses on the past and future frames' temporal information without being dominated by the current static feature. Our TCMR significantly outperforms previous video-based methods in temporal consistency with better per-frame 3D pose and shape accuracy. We will release the codes. Demo video: https://www.youtube.com/watch?v=WB3nTnSQDII&t=7s&ab_channel=%EC%B5%9C%ED%99%8D%EC%84%9D
InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image
Aug 21, 2020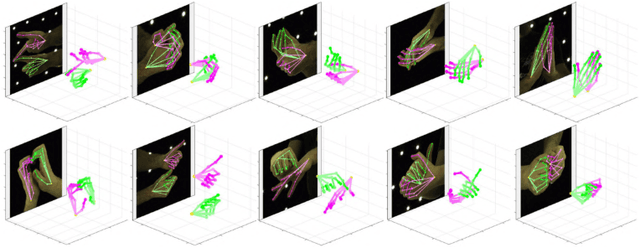
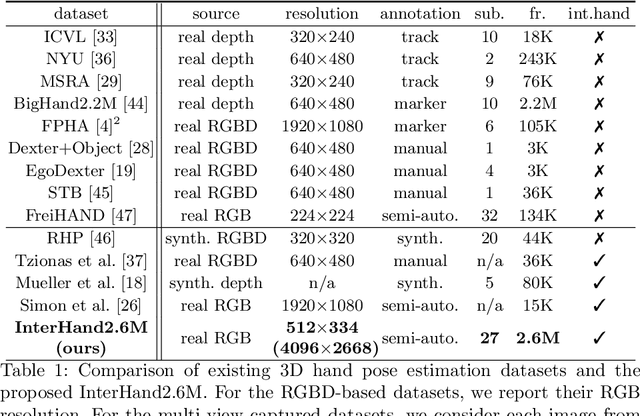

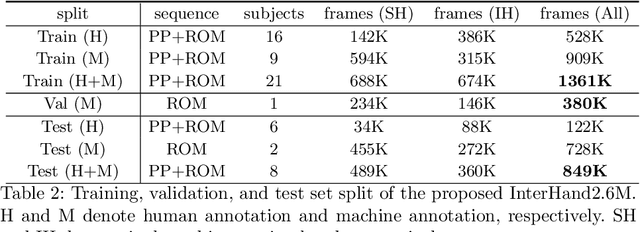
Analysis of hand-hand interactions is a crucial step towards better understanding human behavior. However, most researches in 3D hand pose estimation have focused on the isolated single hand case. Therefore, we firstly propose (1) a large-scale dataset, InterHand2.6M, and (2) a baseline network, InterNet, for 3D interacting hand pose estimation from a single RGB image. The proposed InterHand2.6M consists of \textbf{2.6M labeled single and interacting hand frames} under various poses from multiple subjects. Our InterNet simultaneously performs 3D single and interacting hand pose estimation. In our experiments, we demonstrate big gains in 3D interacting hand pose estimation accuracy when leveraging the interacting hand data in InterHand2.6M. We also report the accuracy of InterNet on InterHand2.6M, which serves as a strong baseline for this new dataset. Finally, we show 3D interacting hand pose estimation results from general images. Our code and dataset are available at https://mks0601.github.io/InterHand2.6M/.
Pose2Mesh: Graph Convolutional Network for 3D Human Pose and Mesh Recovery from a 2D Human Pose
Aug 20, 2020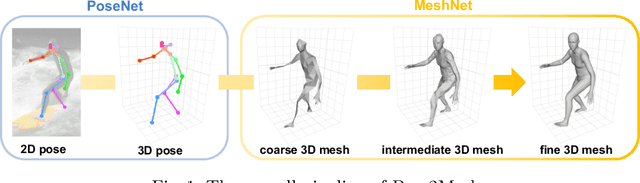



Most of the recent deep learning-based 3D human pose and mesh estimation methods regress the pose and shape parameters of human mesh models, such as SMPL and MANO, from an input image. The first weakness of these methods is an appearance domain gap problem, due to different image appearance between train data from controlled environments, such as a laboratory, and test data from in-the-wild environments. The second weakness is that the estimation of the pose parameters is quite challenging owing to the representation issues of 3D rotations. To overcome the above weaknesses, we propose Pose2Mesh, a novel graph convolutional neural network (GraphCNN)-based system that estimates the 3D coordinates of human mesh vertices directly from the 2D human pose. The 2D human pose as input provides essential human body articulation information, while having a relatively homogeneous geometric property between the two domains. Also, the proposed system avoids the representation issues, while fully exploiting the mesh topology using a GraphCNN in a coarse-to-fine manner. We show that our Pose2Mesh outperforms the previous 3D human pose and mesh estimation methods on various benchmark datasets. The codes are publicly available https://github.com/hongsukchoi/Pose2Mesh_RELEASE.
DeepHandMesh: A Weakly-supervised Deep Encoder-Decoder Framework for High-fidelity Hand Mesh Modeling
Aug 19, 2020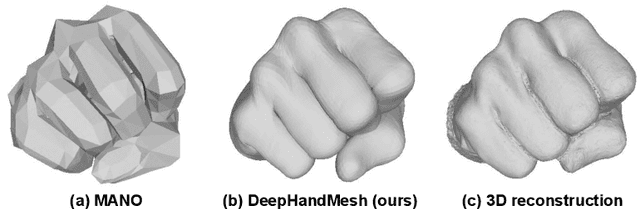

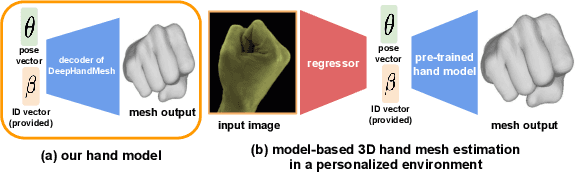
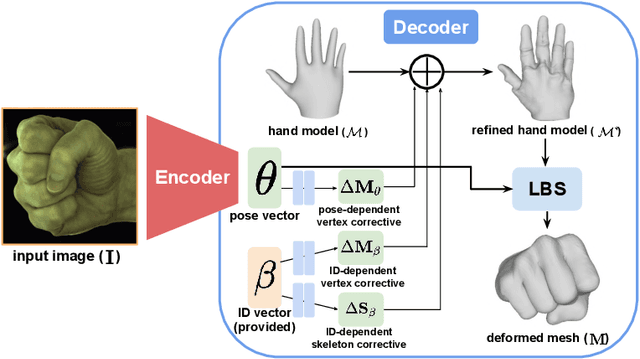
Human hands play a central role in interacting with other people and objects. For realistic replication of such hand motions, high-fidelity hand meshes have to be reconstructed. In this study, we firstly propose DeepHandMesh, a weakly-supervised deep encoder-decoder framework for high-fidelity hand mesh modeling. We design our system to be trained in an end-to-end and weakly-supervised manner; therefore, it does not require groundtruth meshes. Instead, it relies on weaker supervisions such as 3D joint coordinates and multi-view depth maps, which are easier to get than groundtruth meshes and do not dependent on the mesh topology. Although the proposed DeepHandMesh is trained in a weakly-supervised way, it provides significantly more realistic hand mesh than previous fully-supervised hand models. Our newly introduced penetration avoidance loss further improves results by replicating physical interaction between hand parts. Finally, we demonstrate that our system can also be applied successfully to the 3D hand mesh estimation from general images. Our hand model, dataset, and codes are publicly available at https://mks0601.github.io/DeepHandMesh/.
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image
Aug 09, 2020
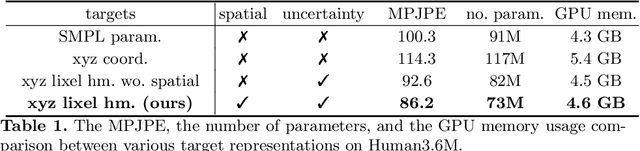
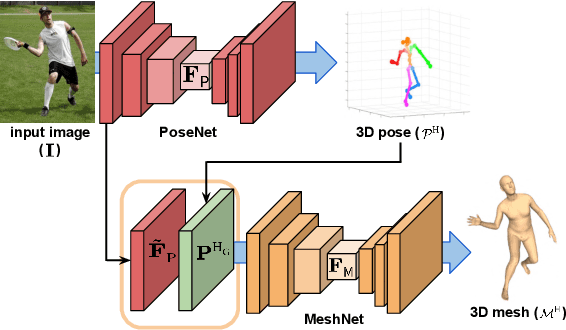
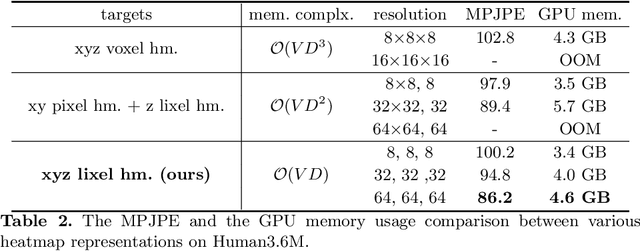
Most of the previous image-based 3D human pose and mesh estimation methods estimate parameters of the human mesh model from an input image. However, directly regressing the parameters from the input image is a highly non-linear mapping because it breaks the spatial relationship between pixels in the input image. In addition, it cannot model the prediction uncertainty, which can make training harder. To resolve the above issues, we propose I2L-MeshNet, an image-to-lixel (line+pixel) prediction network. The proposed I2L-MeshNet predicts the per-lixel likelihood on 1D heatmaps for each mesh vertex coordinate instead of directly regressing the parameters. Our lixel-based 1D heatmap preserves the spatial relationship in the input image and models the prediction uncertainty. We demonstrate the benefit of the image-to-lixel prediction and show that the proposed I2L-MeshNet outperforms previous methods. The code is publicly available \footnote{\url{https://github.com/mks0601/I2L-MeshNet_RELEASE}}.
IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos
Jul 13, 2020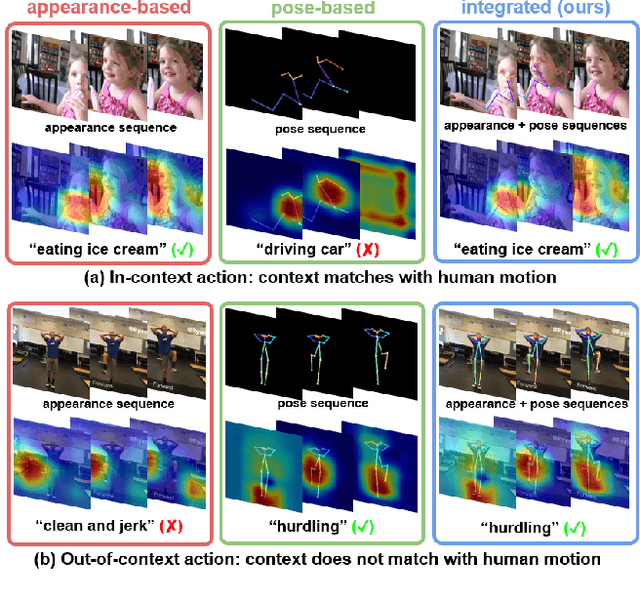
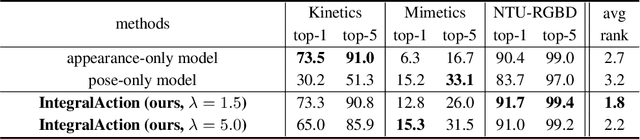
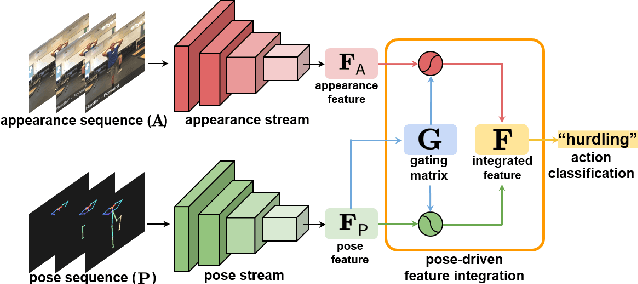
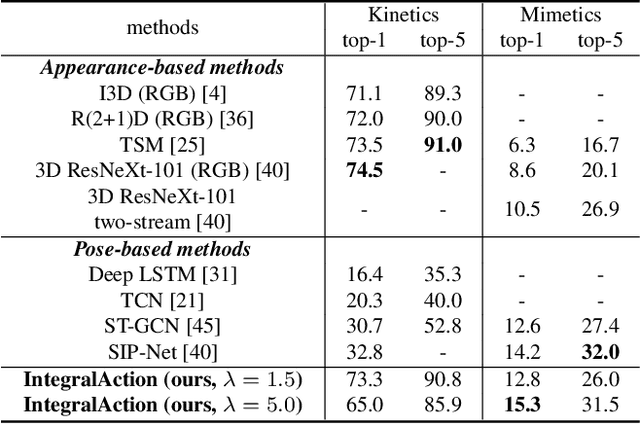
Most current action recognition methods heavily rely on appearance information by taking an RGB sequence of entire image regions as input. While being effective in exploiting contextual information around humans, e.g., human appearance and scene category, they are easily fooled by out-of-context action videos where the contexts do not exactly match with target actions. In contrast, pose-based methods, which takes a sequence of human skeletons only as input, suffer from inaccurate pose estimation or ambiguity of human pose per se. Integrating these two approaches has turned out to be non-trivial; training a model with both appearance and pose ends up with a strong bias towards appearance and does not generalize well to unseen videos. To address this problem, we propose to learn pose-driven feature integration that dynamically combines appearance and pose streams by observing pose features on the fly. The main idea is to let the pose stream decide how much and which appearance information is used in integration based on whether the given pose information is reliable or not. We show that the proposed IntegralAction achieves highly robust performance across in-context and out-of-context action video datasets.
AbsPoseLifter: Absolute 3D Human Pose Lifting Network from a Single Noisy 2D Human Pose
Oct 26, 2019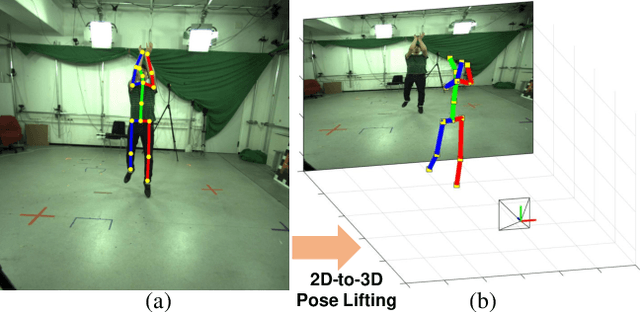
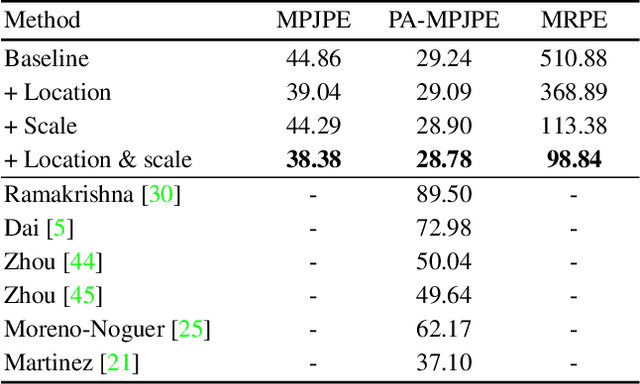
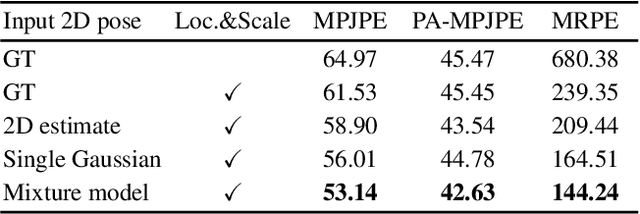
This study presents a new network (i.e., AbsPoseLifter) that lifts a 2D human pose to an absolute 3D pose in a camera coordinate system. The proposed network estimates the absolute 3D location of a target subject and also outputs a considerably improved 3D relative pose estimation compared with those of existing pose lifting methods. We also propose using our AbsPoseLifter with a 2D pose estimator in a cascade fashion to estimate 3D human pose from a single RGB image. In this case, we empirically prove that using realistic 2D poses synthesized with the real error distribution of 2D body joints considerably improves the performance of our AbsPoseLifter. The proposed method is applied to public datasets to achieve state-of-the-art 2D-to-3D pose lifting and 3D human pose estimation.
Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
Aug 17, 2019
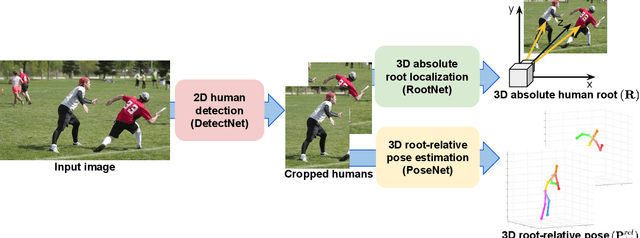
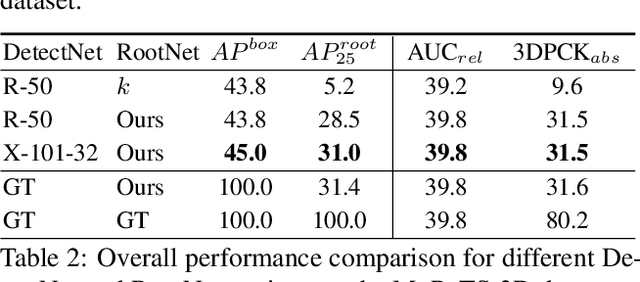
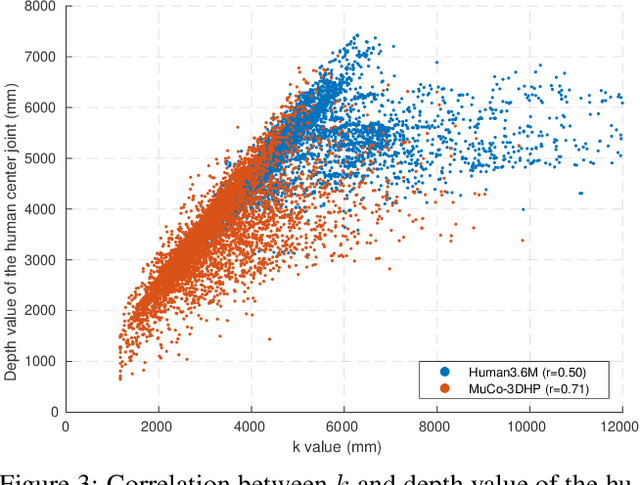
Although significant improvement has been achieved recently in 3D human pose estimation, most of the previous methods only treat a single-person case. In this work, we firstly propose a fully learning-based, camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. The pipeline of the proposed system consists of human detection, absolute 3D human root localization, and root-relative 3D single-person pose estimation modules. Our system achieves comparable results with the state-of-the-art 3D single-person pose estimation models without any groundtruth information and significantly outperforms previous 3D multi-person pose estimation methods on publicly available datasets. The code is available in https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE , https://github.com/mks0601/3DMPPE_POSENET_RELEASE.