 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Anomaly Detection for Polyp Frames from Colonoscopy
Jun 26, 2020

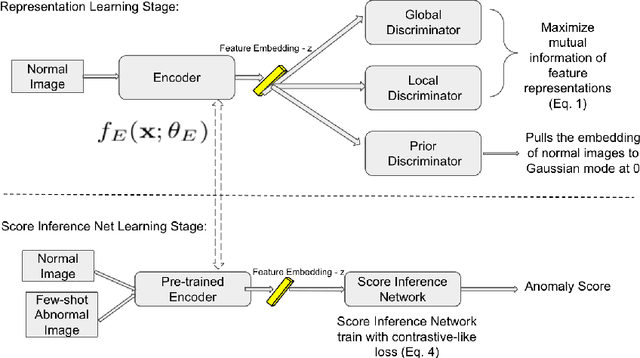
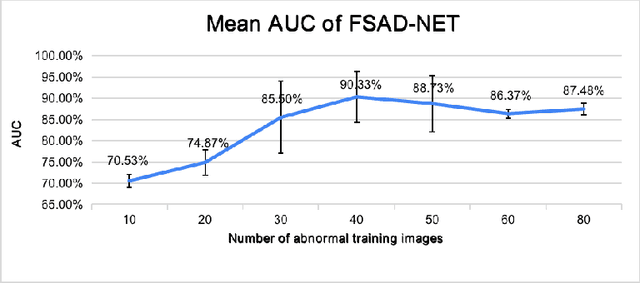
Anomaly detection methods generally target the learning of a normal image distribution (i.e., inliers showing healthy cases) and during testing, samples relatively far from the learned distribution are classified as anomalies (i.e., outliers showing disease cases). These approaches tend to be sensitive to outliers that lie relatively close to inliers (e.g., a colonoscopy image with a small polyp). In this paper, we address the inappropriate sensitivity to outliers by also learning from inliers. We propose a new few-shot anomaly detection method based on an encoder trained to maximise the mutual information between feature embeddings and normal images, followed by a few-shot score inference network, trained with a large set of inliers and a substantially smaller set of outliers. We evaluate our proposed method on the clinical problem of detecting frames containing polyps from colonoscopy video sequences, where the training set has 13350 normal images (i.e., without polyps) and less than 100 abnormal images (i.e., with polyps). The results of our proposed model on this data set reveal a state-of-the-art detection result, while the performance based on different number of anomaly samples is relatively stable after approximately 40 abnormal training images.
Region Proposals for Saliency Map Refinement for Weakly-supervised Disease Localisation and Classification
May 22, 2020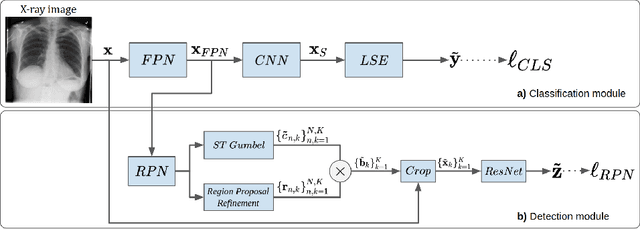
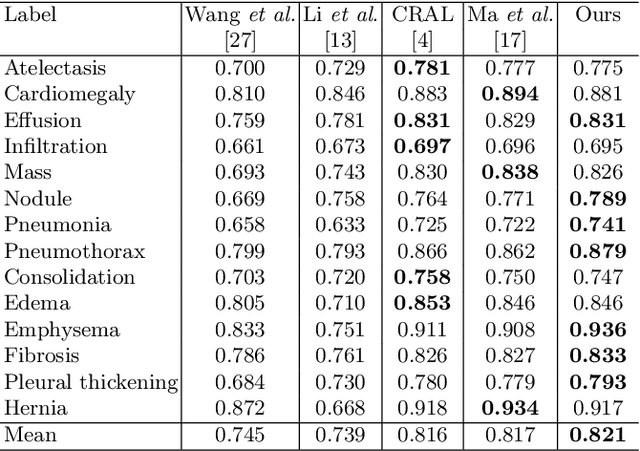
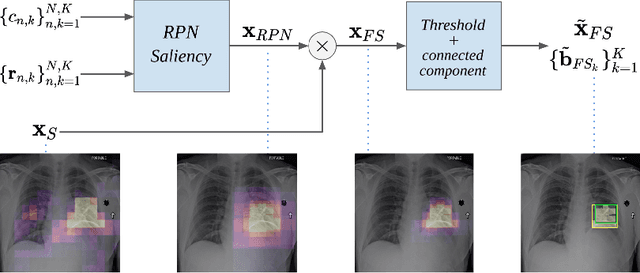
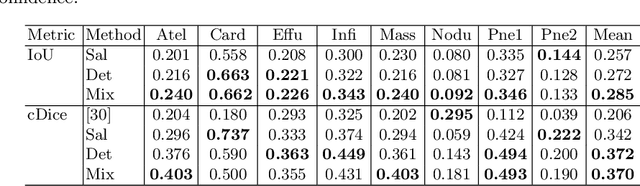
The deployment of automated systems to diagnose diseases from medical images is challenged by the requirement to localise the diagnosed diseases to justify or explain the classification decision. This requirement is hard to fulfil because most of the training sets available to develop these systems only contain global annotations, making the localisation of diseases a weakly supervised approach. The main methods designed for weakly supervised disease classification and localisation rely on saliency or attention maps that are not specifically trained for localisation, or on region proposals that can not be refined to produce accurate detections. In this paper, we introduce a new model that combines region proposal and saliency detection to overcome both limitations for weakly supervised disease classification and localisation. Using the ChestX-ray14 data set, we show that our proposed model establishes the new state-of-the-art for weakly-supervised disease diagnosis and localisation.
Self-supervised Monocular Trained Depth Estimation using Self-attention and Discrete Disparity Volume
Mar 31, 2020
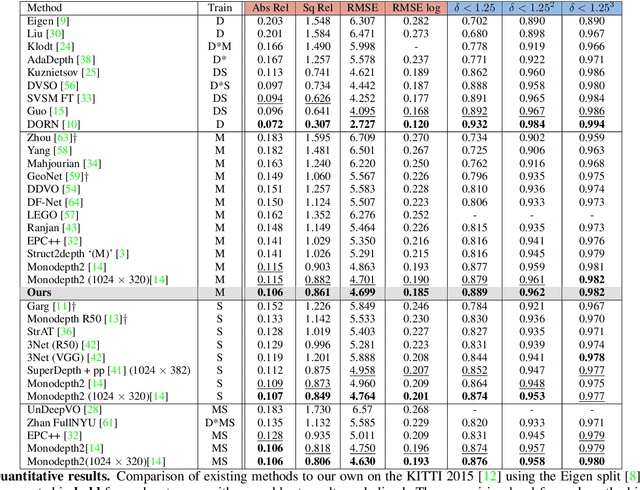
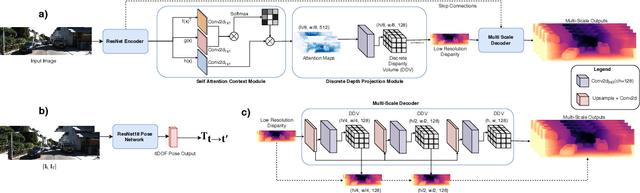
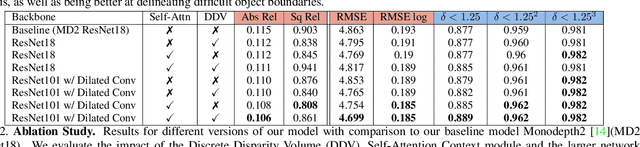
Monocular depth estimation has become one of the most studied applications in computer vision, where the most accurate approaches are based on fully supervised learning models. However, the acquisition of accurate and large ground truth data sets to model these fully supervised methods is a major challenge for the further development of the area. Self-supervised methods trained with monocular videos constitute one the most promising approaches to mitigate the challenge mentioned above due to the wide-spread availability of training data. Consequently, they have been intensively studied, where the main ideas explored consist of different types of model architectures, loss functions, and occlusion masks to address non-rigid motion. In this paper, we propose two new ideas to improve self-supervised monocular trained depth estimation: 1) self-attention, and 2) discrete disparity prediction. Compared with the usual localised convolution operation, self-attention can explore a more general contextual information that allows the inference of similar disparity values at non-contiguous regions of the image. Discrete disparity prediction has been shown by fully supervised methods to provide a more robust and sharper depth estimation than the more common continuous disparity prediction, besides enabling the estimation of depth uncertainty. We show that the extension of the state-of-the-art self-supervised monocular trained depth estimator Monodepth2 with these two ideas allows us to design a model that produces the best results in the field in KITTI 2015 and Make3D, closing the gap with respect self-supervised stereo training and fully supervised approaches.
PAC-Bayesian Meta-learning with Implicit Prior
Mar 05, 2020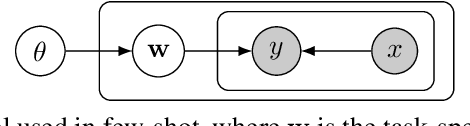
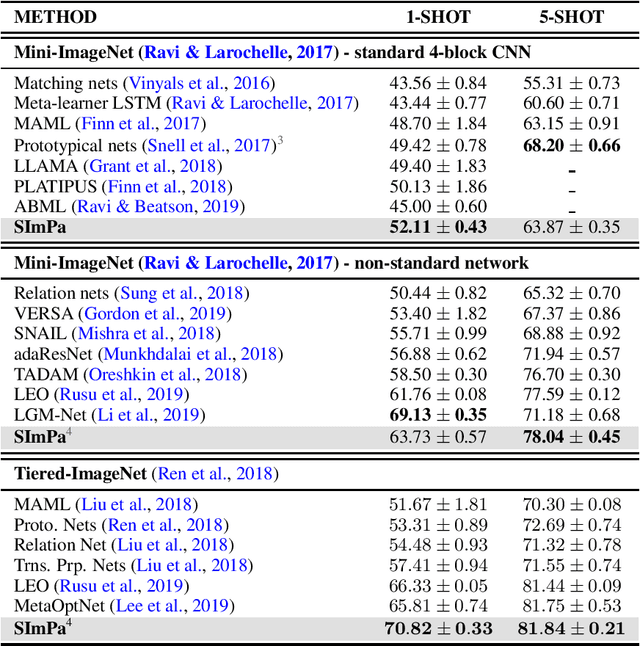
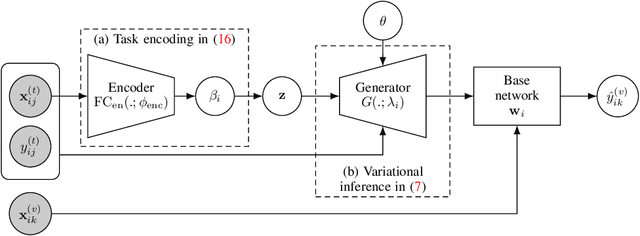
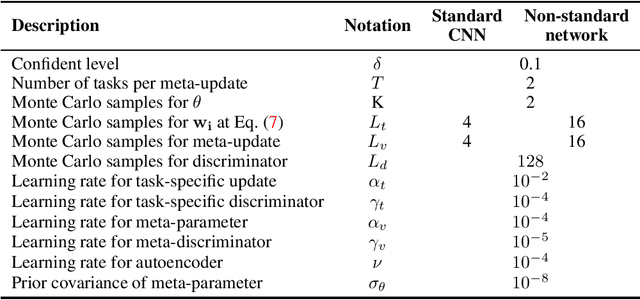
We introduce a new and rigorously-formulated PAC-Bayes few-shot meta-learning algorithm that implicitly learns a prior distribution of the model of interest. Our proposed method extends the PAC-Bayes framework from a single task setting to the few-shot learning setting to upper-bound generalisation errors on unseen tasks and samples. We also propose a generative-based approach to model the shared prior and the posterior of task-specific model parameters more expressively compared to the usual diagonal Gaussian assumption. We show that the models trained with our proposed meta-learning algorithm are well calibrated and accurate, with state-of-the-art calibration and classification results on few-shot classification (mini-ImageNet and tiered-ImageNet) and regression (multi-modal task-distribution regression) benchmarks.
Semi-supervised Multi-domain Multi-task Training for Metastatic Colon Lymph Node Diagnosis From Abdominal CT
Oct 23, 2019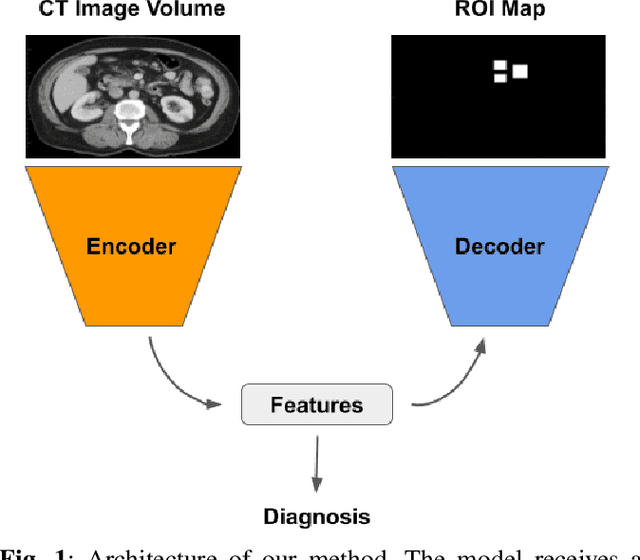
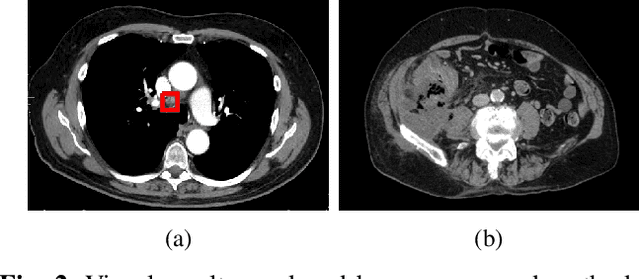

The diagnosis of the presence of metastatic lymph nodes from abdominal computed tomography (CT) scans is an essential task performed by radiologists to guide radiation and chemotherapy treatment. State-of-the-art deep learning classifiers trained for this task usually rely on a training set containing CT volumes and their respective image-level (i.e., global) annotation. However, the lack of annotations for the localisation of the regions of interest (ROIs) containing lymph nodes can limit classification accuracy due to the small size of the relevant ROIs in this problem. The use of lymph node ROIs together with global annotations in a multi-task training process has the potential to improve classification accuracy, but the high cost involved in obtaining the ROI annotation for the same samples that have global annotations is a roadblock for this alternative. We address this limitation by introducing a new training strategy from two data sets: one containing the global annotations, and another (publicly available) containing only the lymph node ROI localisation. We term our new strategy semi-supervised multi-domain multi-task training, where the goal is to improve the diagnosis accuracy on the globally annotated data set by incorporating the ROI annotations from a different domain. Using a private data set containing global annotations and a public data set containing lymph node ROI localisation, we show that our proposed training mechanism improves the area under the ROC curve for the classification task compared to several training method baselines.
Photoshopping Colonoscopy Video Frames
Oct 23, 2019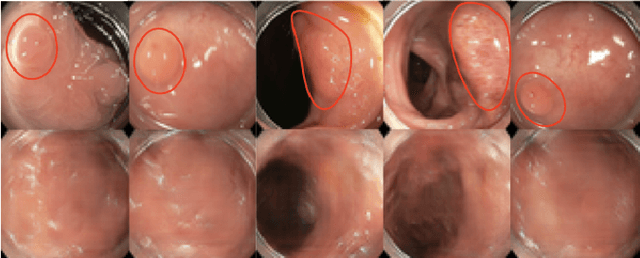
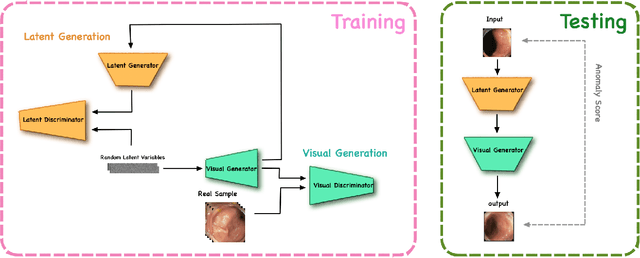
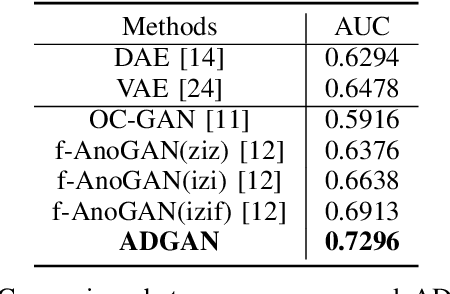
The automatic detection of frames containing polyps from a colonoscopy video sequence is an important first step for a fully automated colonoscopy analysis tool. Typically, such detection system is built using a large annotated data set of frames with and without polyps, which is expensive to be obtained. In this paper, we introduce a new system that detects frames containing polyps as anomalies from a distribution of frames from exams that do not contain any polyps. The system is trained using a one-class training set consisting of colonoscopy frames without polyps -- such training set is considerably less expensive to obtain, compared to the 2-class data set mentioned above. During inference, the system is only able to reconstruct frames without polyps, and when it tries to reconstruct a frame with polyp, it automatically removes (i.e., photoshop) it from the frame -- the difference between the input and reconstructed frames is used to detect frames with polyps. We name our proposed model as anomaly detection generative adversarial network (ADGAN), comprising a dual GAN with two generators and two discriminators. We show that our proposed approach achieves the state-of-the-art result on this data set, compared with recently proposed anomaly detection systems.
Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging
Sep 27, 2019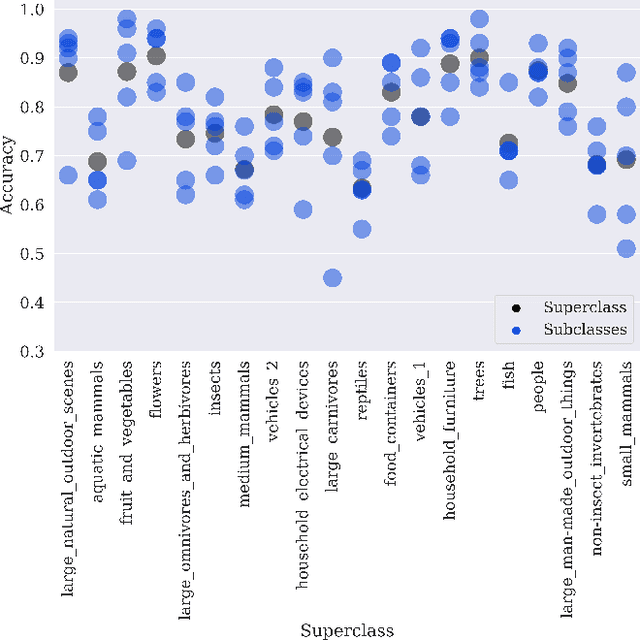

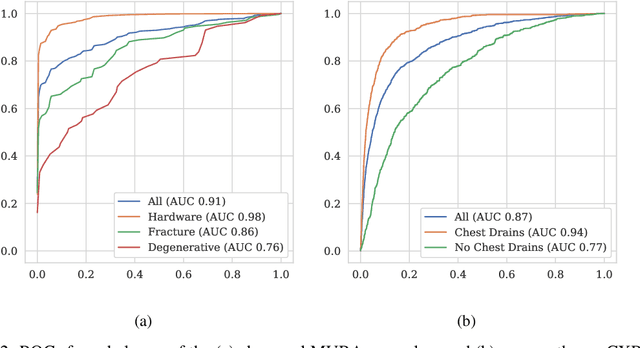
Machine learning models for medical image analysis often suffer from poor performance on important subsets of a population that are not identified during training or testing. For example, overall performance of a cancer detection model may be high, but the model still consistently misses a rare but aggressive cancer subtype. We refer to this problem as hidden stratification, and observe that it results from incompletely describing the meaningful variation in a dataset. While hidden stratification can substantially reduce the clinical efficacy of machine learning models, its effects remain difficult to measure. In this work, we assess the utility of several possible techniques for measuring and describing hidden stratification effects, and characterize these effects both on multiple medical imaging datasets and via synthetic experiments on the well-characterised CIFAR-100 benchmark dataset. We find evidence that hidden stratification can occur in unidentified imaging subsets with low prevalence, low label quality, subtle distinguishing features, or spurious correlates, and that it can result in relative performance differences of over 20% on clinically important subsets. Finally, we explore the clinical implications of our findings, and suggest that evaluation of hidden stratification should be a critical component of any machine learning deployment in medical imaging.
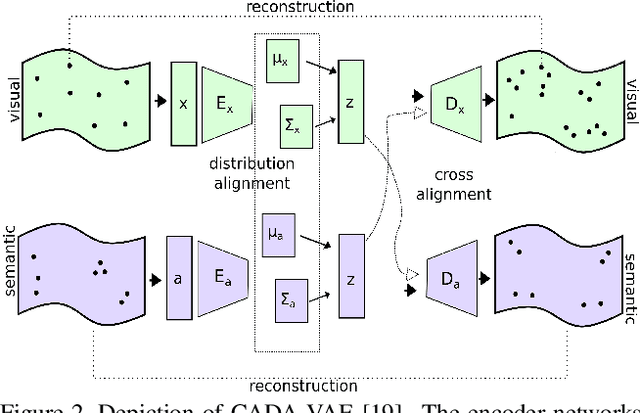
Generalised Zero-Shot Learning with Domain Classification in a Joint Semantic and Visual Space
Aug 14, 2019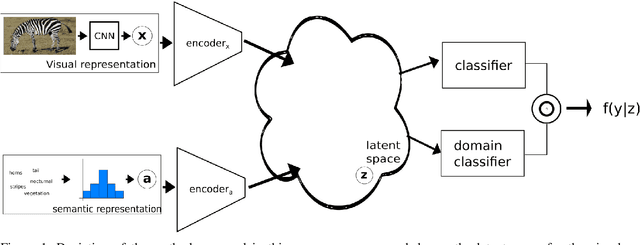
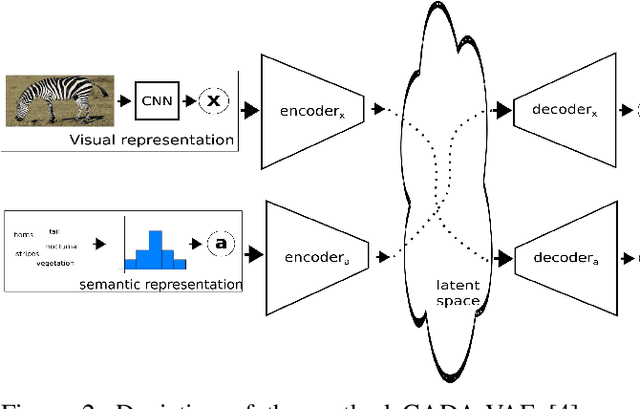
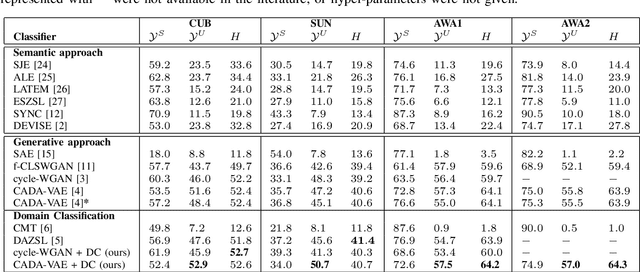
Generalised zero-shot learning (GZSL) is a classification problem where the learning stage relies on a set of seen visual classes and the inference stage aims to identify both the seen visual classes and a new set of unseen visual classes. Critically, both the learning and inference stages can leverage a semantic representation that is available for the seen and unseen classes. Most state-of-the-art GZSL approaches rely on a mapping between latent visual and semantic spaces without considering if a particular sample belongs to the set of seen or unseen classes. In this paper, we propose a novel GZSL method that learns a joint latent representation that combines both visual and semantic information. This mitigates the need for learning a mapping between the two spaces. Our method also introduces a domain classification that estimates whether a sample belongs to a seen or an unseen class. Our classifier then combines a class discriminator with this domain classifier with the goal of reducing the natural bias that GZSL approaches have toward the seen classes. Experiments show that our method achieves state-of-the-art results in terms of harmonic mean, the area under the seen and unseen curve and unseen classification accuracy on public GZSL benchmark data sets. Our code will be available upon acceptance of this paper.
Generalised Zero-Shot Learning with a Classifier Ensemble over Multi-Modal Embedding Spaces
Aug 06, 2019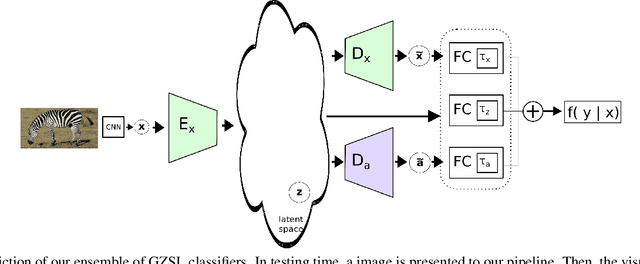
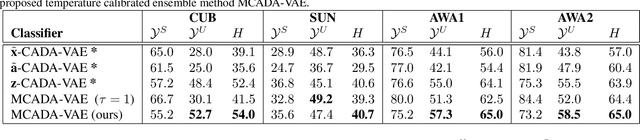
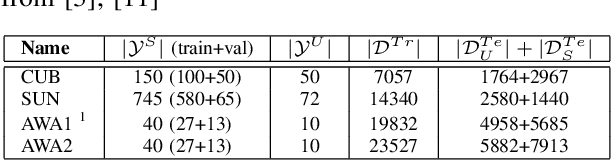
Generalised zero-shot learning (GZSL) methods aim to classify previously seen and unseen visual classes by leveraging the semantic information of those classes. In the context of GZSL, semantic information is non-visual data such as a text description of both seen and unseen classes. Previous GZSL methods have utilised transformations between visual and semantic embedding spaces, as well as the learning of joint spaces that include both visual and semantic information. In either case, classification is then performed on a single learned space. We argue that each embedding space contains complementary information for the GZSL problem. By using just a visual, semantic or joint space some of this information will invariably be lost. In this paper, we demonstrate the advantages of our new GZSL method that combines the classification of visual, semantic and joint spaces. Most importantly, this ensembling allows for more information from the source domains to be seen during classification. An additional contribution of our work is the application of a calibration procedure for each classifier in the ensemble. This calibration mitigates the problem of model selection when combining the classifiers. Lastly, our proposed method achieves state-of-the-art results on the CUB, AWA1 and AWA2 benchmark data sets and provides competitive performance on the SUN data set.
Few-Shot Meta-Denoising
Jul 31, 2019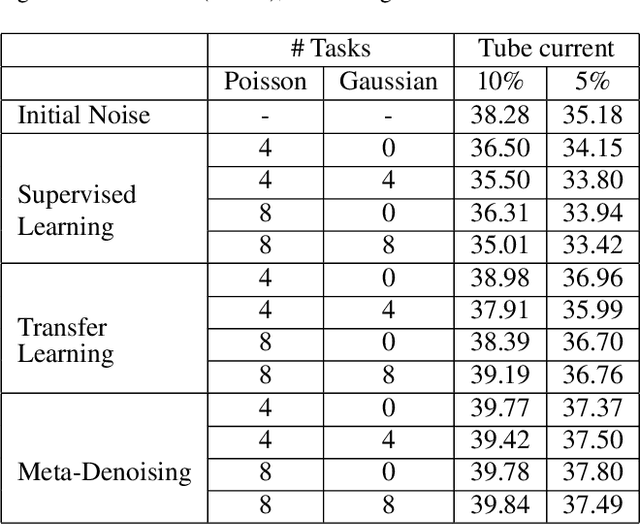
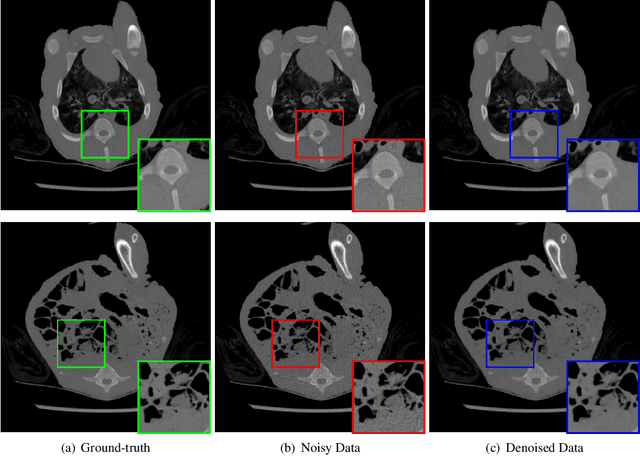
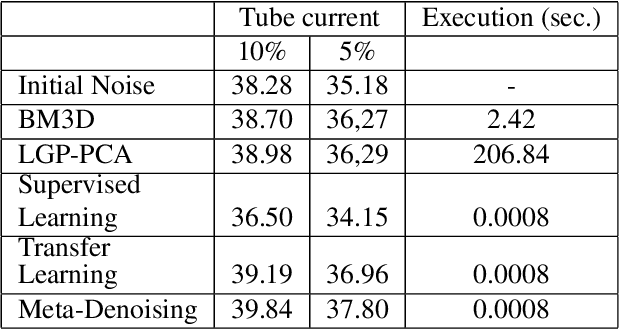

We study the problem of learning-based denoising where the training set contains just a handful of clean and noisy samples. A solution to mitigate the small training set issue is to train a denoising model with pairs of clean and synthesized noisy signals, produced from empirical noise priors; and finally only fine-tune on the available small training set. While transfer learning suits well to this pipeline, it does not generalize with the limited amount of training data. In this work, we propose a new training approach, based on meta-learning, for few-shot learning-based denoising problems. Our model is meta-trained using known synthetic noise models, and then fine-tuned with the small training set, with the real noise, as a few-shot learning task. Learning from synthetic data during meta-training gives us the ability to generate an infinite number of training data. Our approach is empirically shown to produce more accurate denoising results than supervised learning and transfer learning in three denoising evaluations for images and 1-D signals. Interestingly, our study provides strong indications that meta-learning has the potential to become the main learning algorithm for the denoising.