 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Low-Rank Representations
Sep 27, 2012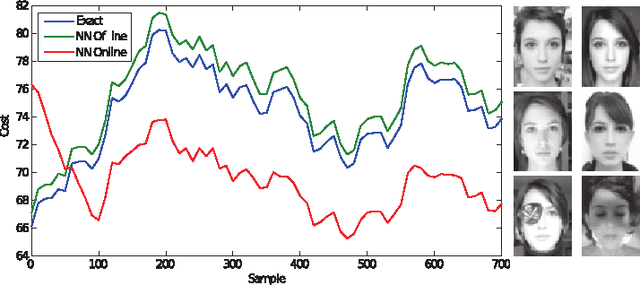


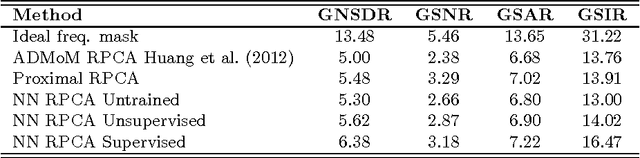
In this paper we present a comprehensive framework for learning robust low-rank representations by combining and extending recent ideas for learning fast sparse coding regressors with structured non-convex optimization techniques. This approach connects robust principal component analysis (RPCA) with dictionary learning techniques and allows its approximation via trainable encoders. We propose an efficient feed-forward architecture derived from an optimization algorithm designed to exactly solve robust low dimensional projections. This architecture, in combination with different training objective functions, allows the regressors to be used as online approximants of the exact offline RPCA problem or as RPCA-based neural networks. Simple modifications of these encoders can handle challenging extensions, such as the inclusion of geometric data transformations. We present several examples with real data from image, audio, and video processing. When used to approximate RPCA, our basic implementation shows several orders of magnitude speedup compared to the exact solvers with almost no performance degradation. We show the strength of the inclusion of learning to the RPCA approach on a music source separation application, where the encoders outperform the exact RPCA algorithms, which are already reported to produce state-of-the-art results on a benchmark database. Our preliminary implementation on an iPad shows faster-than-real-time performance with minimal latency.
Are You Imitating Me? Unsupervised Sparse Modeling for Group Activity Analysis from a Single Video
Aug 27, 2012
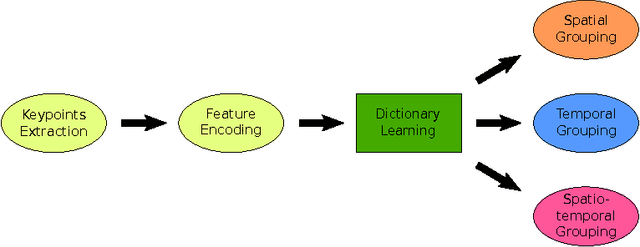
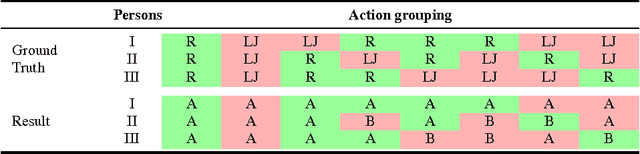
A framework for unsupervised group activity analysis from a single video is here presented. Our working hypothesis is that human actions lie on a union of low-dimensional subspaces, and thus can be efficiently modeled as sparse linear combinations of atoms from a learned dictionary representing the action's primitives. Contrary to prior art, and with the primary goal of spatio-temporal action grouping, in this work only one single video segment is available for both unsupervised learning and analysis without any prior training information. After extracting simple features at a single spatio-temporal scale, we learn a dictionary for each individual in the video during each short time lapse. These dictionaries allow us to compare the individuals' actions by producing an affinity matrix which contains sufficient discriminative information about the actions in the scene leading to grouping with simple and efficient tools. With diverse publicly available real videos, we demonstrate the effectiveness of the proposed framework and its robustness to cluttered backgrounds, changes of human appearance, and action variability.
Learning Efficient Structured Sparse Models
Jun 18, 2012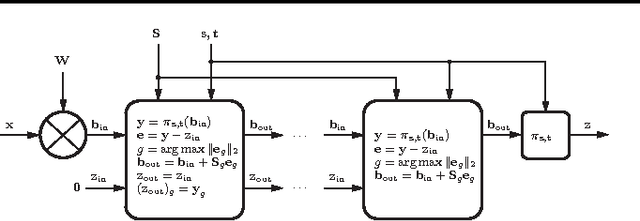
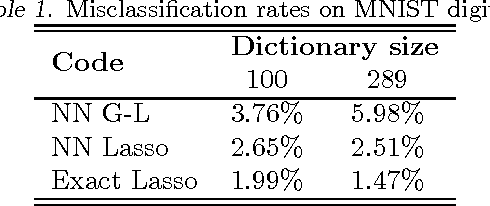
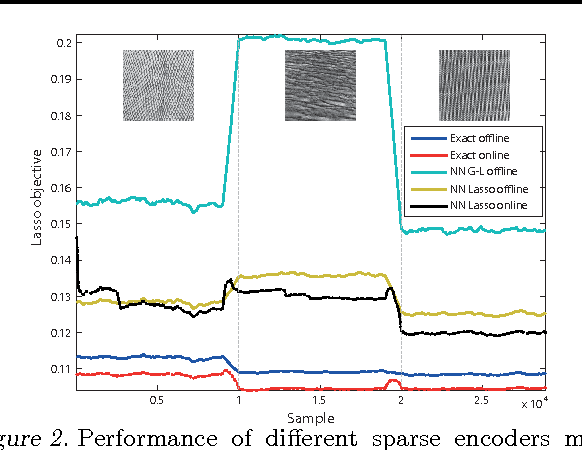

We present a comprehensive framework for structured sparse coding and modeling extending the recent ideas of using learnable fast regressors to approximate exact sparse codes. For this purpose, we develop a novel block-coordinate proximal splitting method for the iterative solution of hierarchical sparse coding problems, and show an efficient feed forward architecture derived from its iteration. This architecture faithfully approximates the exact structured sparse codes with a fraction of the complexity of the standard optimization methods. We also show that by using different training objective functions, learnable sparse encoders are no longer restricted to be mere approximants of the exact sparse code for a pre-given dictionary, as in earlier formulations, but can be rather used as full-featured sparse encoders or even modelers. A simple implementation shows several orders of magnitude speedup compared to the state-of-the-art at minimal performance degradation, making the proposed framework suitable for real time and large-scale applications.
Semi-Supervised Single- and Multi-Domain Regression with Multi-Domain Training
Mar 20, 2012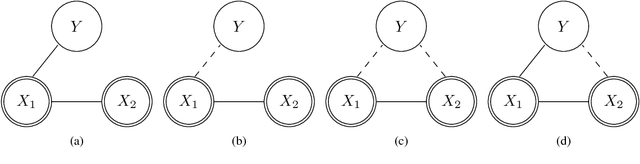
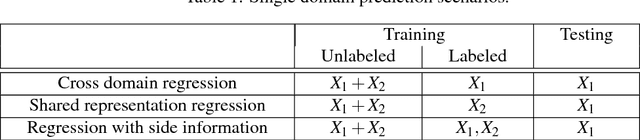
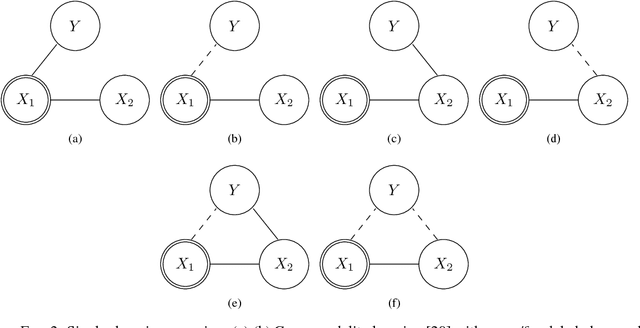

We address the problems of multi-domain and single-domain regression based on distinct and unpaired labeled training sets for each of the domains and a large unlabeled training set from all domains. We formulate these problems as a Bayesian estimation with partial knowledge of statistical relations. We propose a worst-case design strategy and study the resulting estimators. Our analysis explicitly accounts for the cardinality of the labeled sets and includes the special cases in which one of the labeled sets is very large or, in the other extreme, completely missing. We demonstrate our estimators in the context of removing expressions from facial images and in the context of audio-visual word recognition, and provide comparisons to several recently proposed multi-modal learning algorithms.
Task-Driven Adaptive Statistical Compressive Sensing of Gaussian Mixture Models
Jan 25, 2012
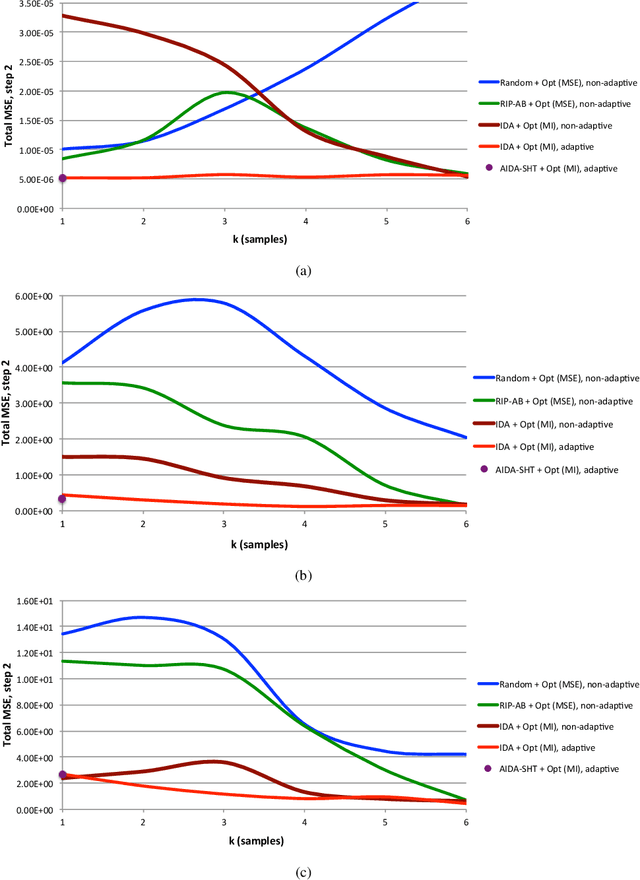
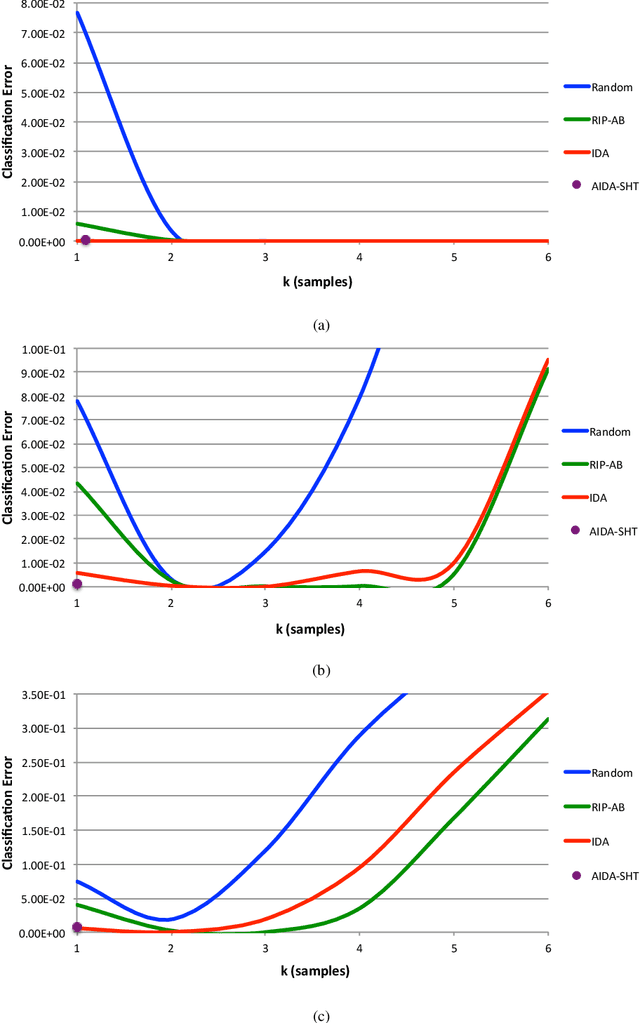
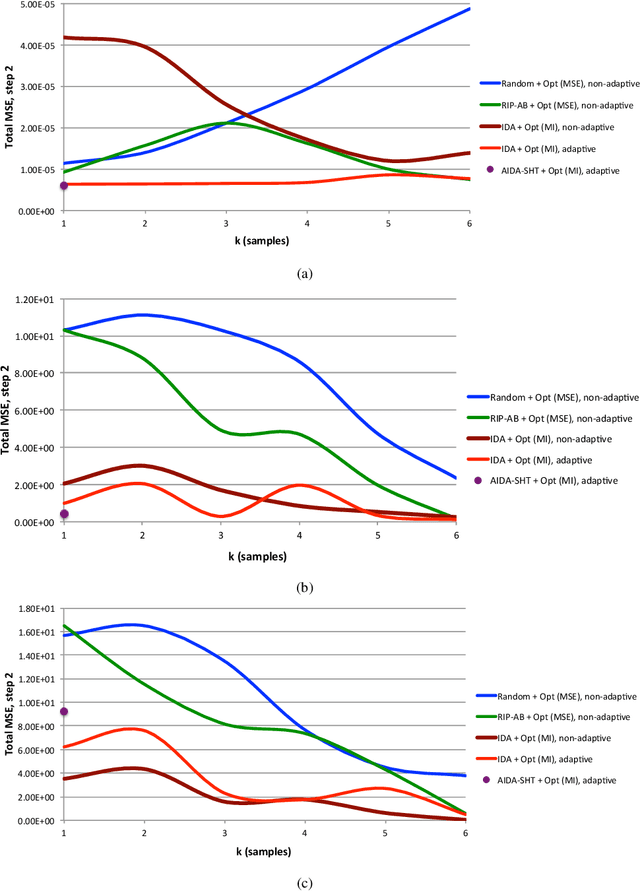
A framework for adaptive and non-adaptive statistical compressive sensing is developed, where a statistical model replaces the standard sparsity model of classical compressive sensing. We propose within this framework optimal task-specific sensing protocols specifically and jointly designed for classification and reconstruction. A two-step adaptive sensing paradigm is developed, where online sensing is applied to detect the signal class in the first step, followed by a reconstruction step adapted to the detected class and the observed samples. The approach is based on information theory, here tailored for Gaussian mixture models (GMMs), where an information-theoretic objective relationship between the sensed signals and a representation of the specific task of interest is maximized. Experimental results using synthetic signals, Landsat satellite attributes, and natural images of different sizes and with different noise levels show the improvements achieved using the proposed framework when compared to more standard sensing protocols. The underlying formulation can be applied beyond GMMs, at the price of higher mathematical and computational complexity.
Online Adaptive Statistical Compressed Sensing of Gaussian Mixture Models
Dec 26, 2011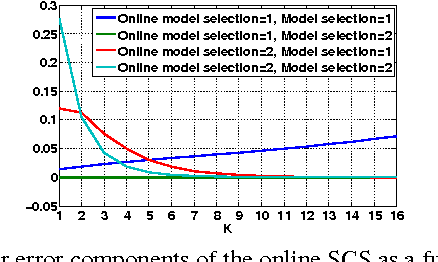
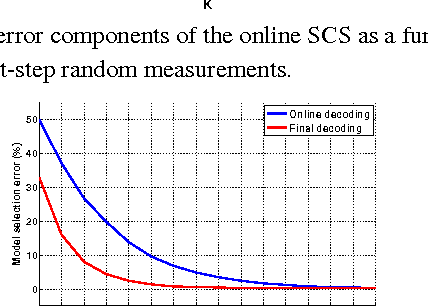
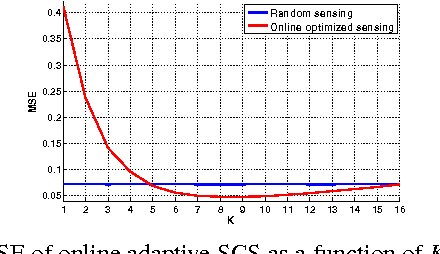

A framework of online adaptive statistical compressed sensing is introduced for signals following a mixture model. The scheme first uses non-adaptive measurements, from which an online decoding scheme estimates the model selection. As soon as a candidate model has been selected, an optimal sensing scheme for the selected model continues to apply. The final signal reconstruction is calculated from the ensemble of both the non-adaptive and the adaptive measurements. For signals generated from a Gaussian mixture model, the online adaptive sensing algorithm is given and its performance is analyzed. On both synthetic and real image data, the proposed adaptive scheme considerably reduces the average reconstruction error with respect to standard statistical compressed sensing that uses fully random measurements, at a marginally increased computational complexity.
An MDL framework for sparse coding and dictionary learning
Oct 11, 2011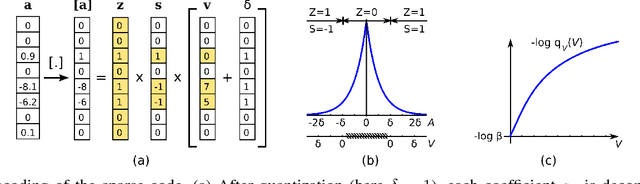
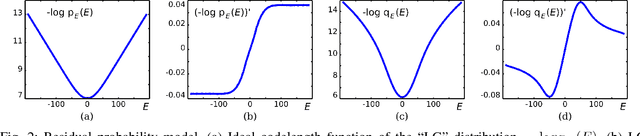
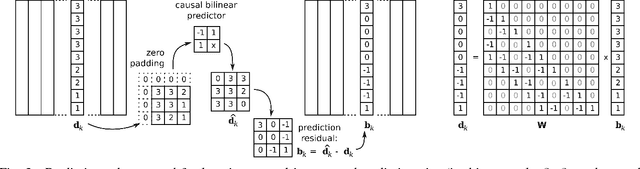
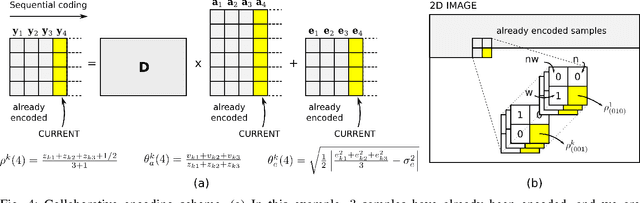
The power of sparse signal modeling with learned over-complete dictionaries has been demonstrated in a variety of applications and fields, from signal processing to statistical inference and machine learning. However, the statistical properties of these models, such as under-fitting or over-fitting given sets of data, are still not well characterized in the literature. As a result, the success of sparse modeling depends on hand-tuning critical parameters for each data and application. This work aims at addressing this by providing a practical and objective characterization of sparse models by means of the Minimum Description Length (MDL) principle -- a well established information-theoretic approach to model selection in statistical inference. The resulting framework derives a family of efficient sparse coding and dictionary learning algorithms which, by virtue of the MDL principle, are completely parameter free. Furthermore, such framework allows to incorporate additional prior information to existing models, such as Markovian dependencies, or to define completely new problem formulations, including in the matrix analysis area, in a natural way. These virtues will be demonstrated with parameter-free algorithms for the classic image denoising and classification problems, and for low-rank matrix recovery in video applications.
Low-rank data modeling via the Minimum Description Length principle
Sep 28, 2011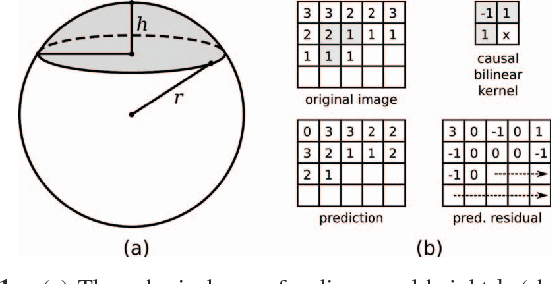
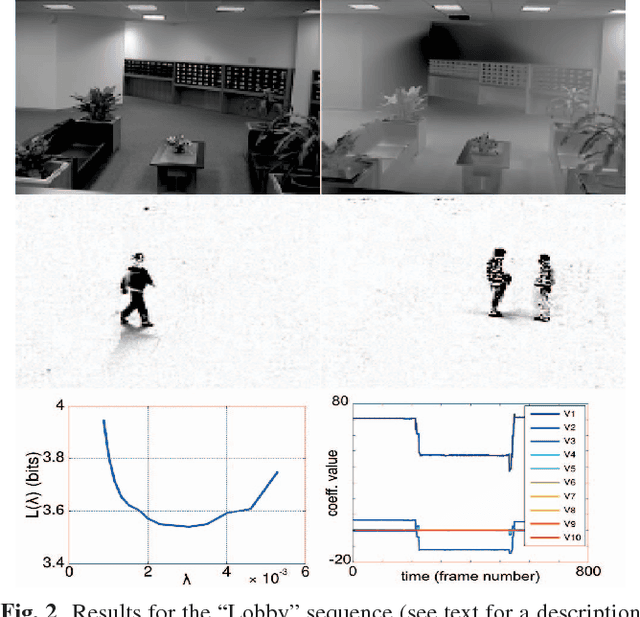
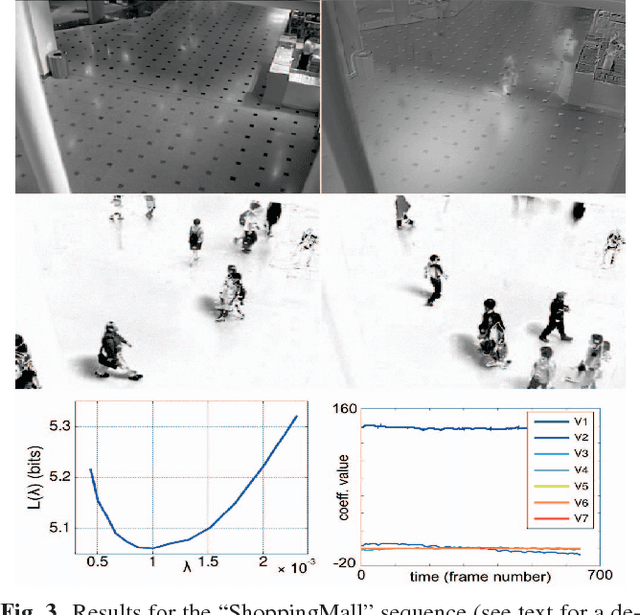
Robust low-rank matrix estimation is a topic of increasing interest, with promising applications in a variety of fields, from computer vision to data mining and recommender systems. Recent theoretical results establish the ability of such data models to recover the true underlying low-rank matrix when a large portion of the measured matrix is either missing or arbitrarily corrupted. However, if low rank is not a hypothesis about the true nature of the data, but a device for extracting regularity from it, no current guidelines exist for choosing the rank of the estimated matrix. In this work we address this problem by means of the Minimum Description Length (MDL) principle -- a well established information-theoretic approach to statistical inference -- as a guideline for selecting a model for the data at hand. We demonstrate the practical usefulness of our formal approach with results for complex background extraction in video sequences.
C-HiLasso: A Collaborative Hierarchical Sparse Modeling Framework
Mar 04, 2011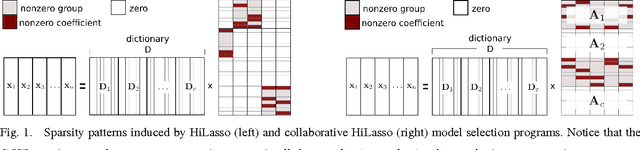
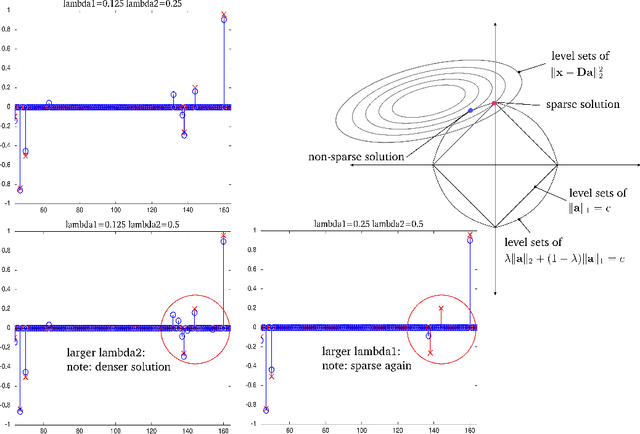
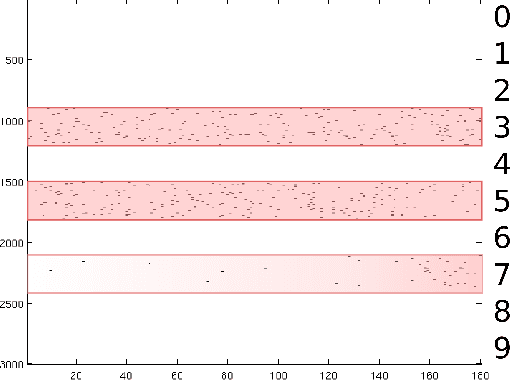
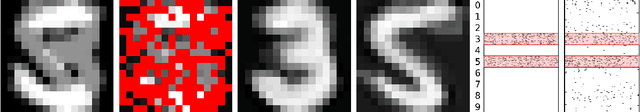
Sparse modeling is a powerful framework for data analysis and processing. Traditionally, encoding in this framework is performed by solving an L1-regularized linear regression problem, commonly referred to as Lasso or Basis Pursuit. In this work we combine the sparsity-inducing property of the Lasso model at the individual feature level, with the block-sparsity property of the Group Lasso model, where sparse groups of features are jointly encoded, obtaining a sparsity pattern hierarchically structured. This results in the Hierarchical Lasso (HiLasso), which shows important practical modeling advantages. We then extend this approach to the collaborative case, where a set of simultaneously coded signals share the same sparsity pattern at the higher (group) level, but not necessarily at the lower (inside the group) level, obtaining the collaborative HiLasso model (C-HiLasso). Such signals then share the same active groups, or classes, but not necessarily the same active set. This model is very well suited for applications such as source identification and separation. An efficient optimization procedure, which guarantees convergence to the global optimum, is developed for these new models. The underlying presentation of the new framework and optimization approach is complemented with experimental examples and theoretical results regarding recovery guarantees for the proposed models.
A convex model for non-negative matrix factorization and dimensionality reduction on physical space
Feb 04, 2011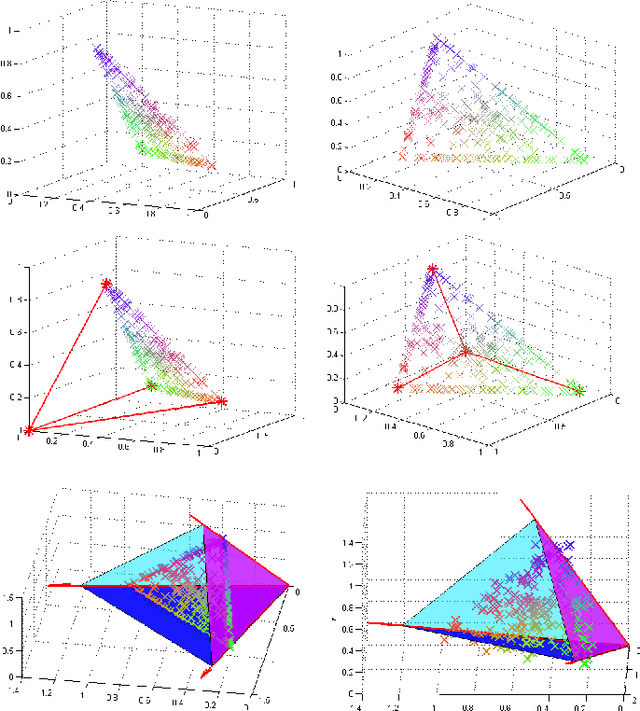
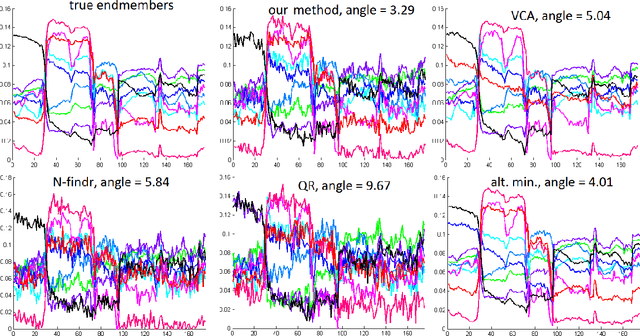
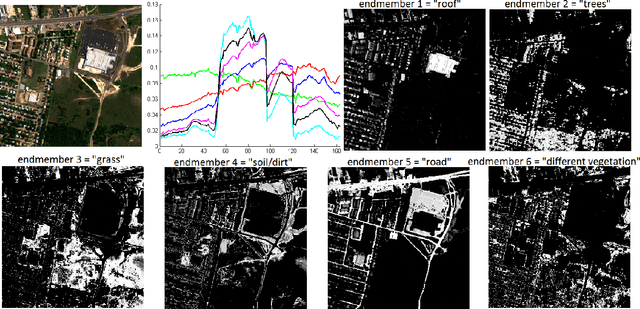
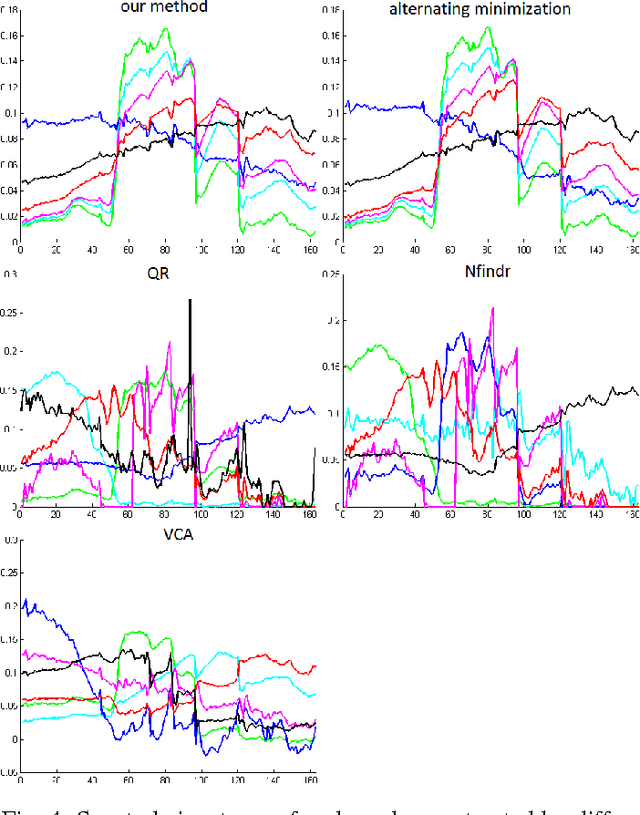
A collaborative convex framework for factoring a data matrix $X$ into a non-negative product $AS$, with a sparse coefficient matrix $S$, is proposed. We restrict the columns of the dictionary matrix $A$ to coincide with certain columns of the data matrix $X$, thereby guaranteeing a physically meaningful dictionary and dimensionality reduction. We use $l_{1,\infty}$ regularization to select the dictionary from the data and show this leads to an exact convex relaxation of $l_0$ in the case of distinct noise free data. We also show how to relax the restriction-to-$X$ constraint by initializing an alternating minimization approach with the solution of the convex model, obtaining a dictionary close to but not necessarily in $X$. We focus on applications of the proposed framework to hyperspectral endmember and abundances identification and also show an application to blind source separation of NMR data.