 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Pareto Fairness: A Multi Objective Perspective
Nov 03, 2020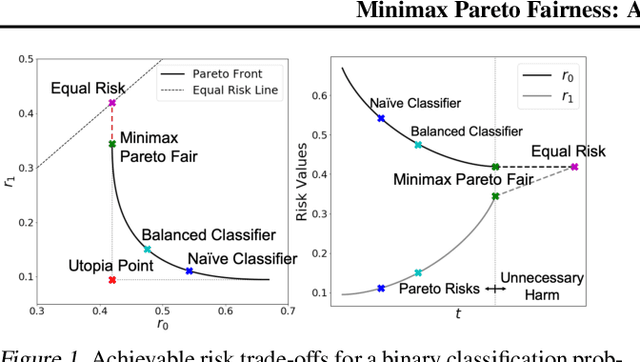
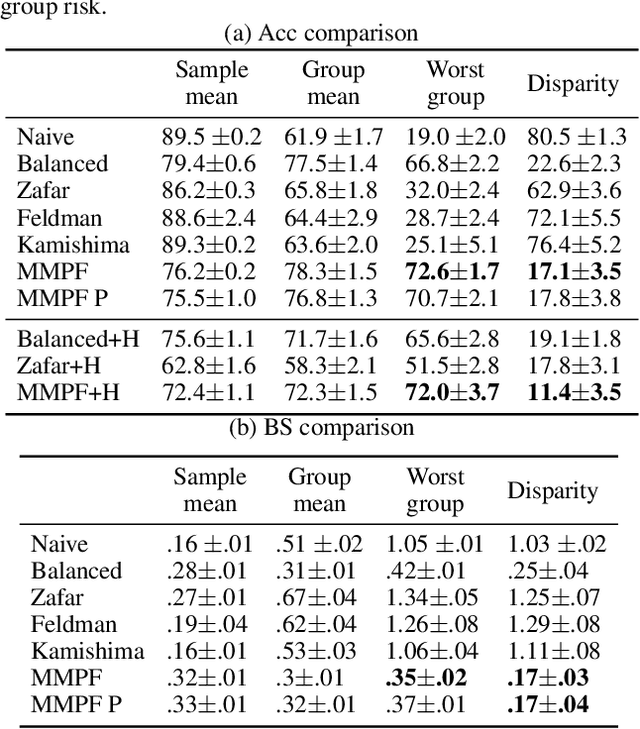
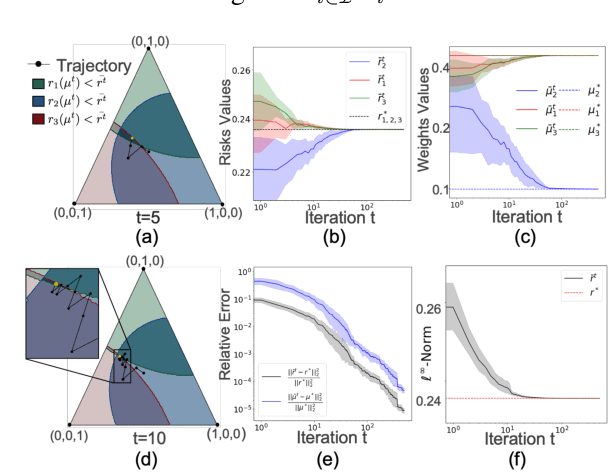
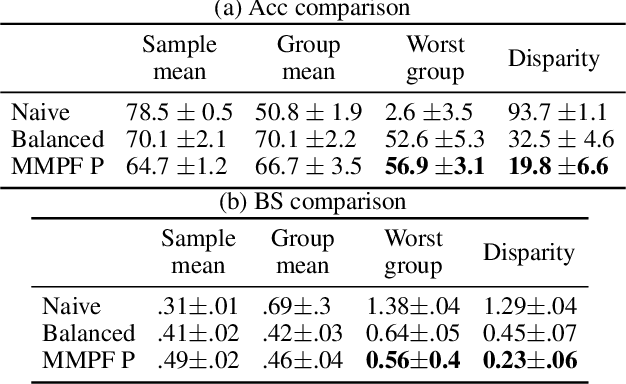
In this work we formulate and formally characterize group fairness as a multi-objective optimization problem, where each sensitive group risk is a separate objective. We propose a fairness criterion where a classifier achieves minimax risk and is Pareto-efficient w.r.t. all groups, avoiding unnecessary harm, and can lead to the best zero-gap model if policy dictates so. We provide a simple optimization algorithm compatible with deep neural networks to satisfy these constraints. Since our method does not require test-time access to sensitive attributes, it can be applied to reduce worst-case classification errors between outcomes in unbalanced classification problems. We test the proposed methodology on real case-studies of predicting income, ICU patient mortality, skin lesions classification, and assessing credit risk, demonstrating how our framework compares favorably to other approaches.
Instance based Generalization in Reinforcement Learning
Nov 02, 2020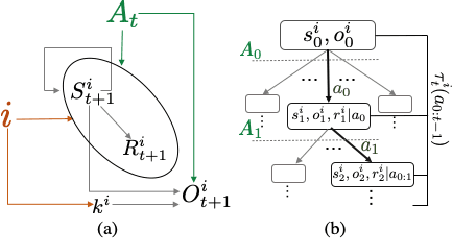
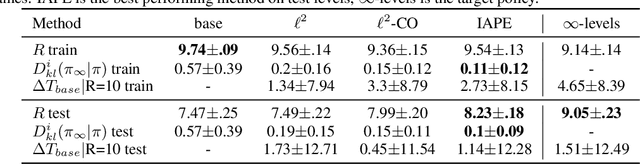
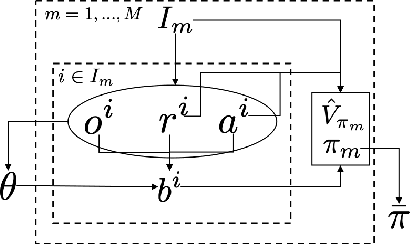

Agents trained via deep reinforcement learning (RL) routinely fail to generalize to unseen environments, even when these share the same underlying dynamics as the training levels. Understanding the generalization properties of RL is one of the challenges of modern machine learning. Towards this goal, we analyze policy learning in the context of Partially Observable Markov Decision Processes (POMDPs) and formalize the dynamics of training levels as instances. We prove that, independently of the exploration strategy, reusing instances introduces significant changes on the effective Markov dynamics the agent observes during training. Maximizing expected rewards impacts the learned belief state of the agent by inducing undesired instance specific speedrunning policies instead of generalizeable ones, which are suboptimal on the training set. We provide generalization bounds to the value gap in train and test environments based on the number of training instances, and use insights based on these to improve performance on unseen levels. We propose training a shared belief representation over an ensemble of specialized policies, from which we compute a consensus policy that is used for data collection, disallowing instance specific exploitation. We experimentally validate our theory, observations, and the proposed computational solution over the CoinRun benchmark.
ACDC: Weight Sharing in Atom-Coefficient Decomposed Convolution
Sep 04, 2020
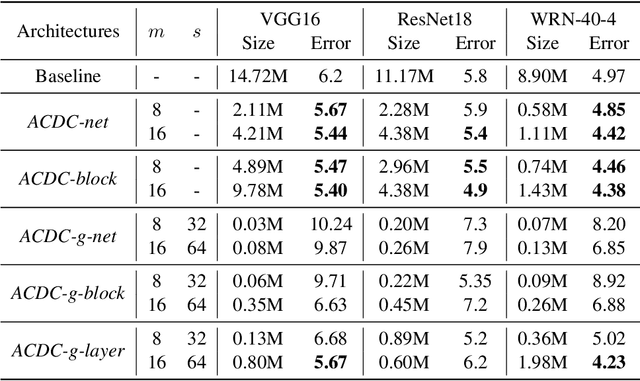
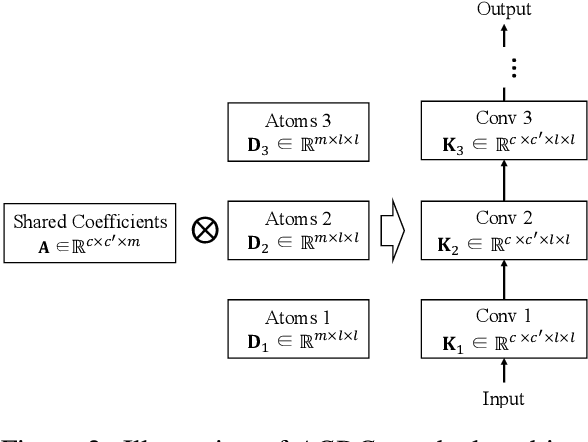
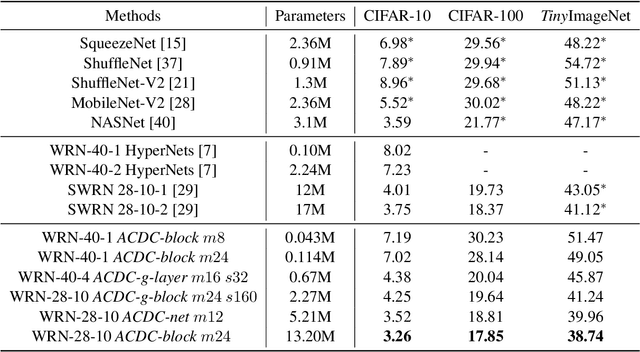
Convolutional Neural Networks (CNNs) are known to be significantly over-parametrized, and difficult to interpret, train and adapt. In this paper, we introduce a structural regularization across convolutional kernels in a CNN. In our approach, each convolution kernel is first decomposed as 2D dictionary atoms linearly combined by coefficients. The widely observed correlation and redundancy in a CNN hint a common low-rank structure among the decomposed coefficients, which is here further supported by our empirical observations. We then explicitly regularize CNN kernels by enforcing decomposed coefficients to be shared across sub-structures, while leaving each sub-structure only its own dictionary atoms, a few hundreds of parameters typically, which leads to dramatic model reductions. We explore models with sharing across different sub-structures to cover a wide range of trade-offs between parameter reduction and expressiveness. Our proposed regularized network structures open the door to better interpreting, training and adapting deep models. We validate the flexibility and compatibility of our method by image classification experiments on multiple datasets and underlying network structures, and show that CNNs now maintain performance with dramatic reduction in parameters and computations, e.g., only 5\% parameters are used in a ResNet-18 to achieve comparable performance. Further experiments on few-shot classification show that faster and more robust task adaptation is obtained in comparison with models with standard convolutions.
Nested Learning For Multi-Granular Tasks
Jul 13, 2020
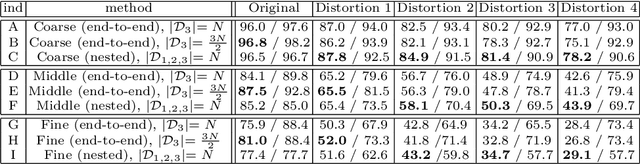
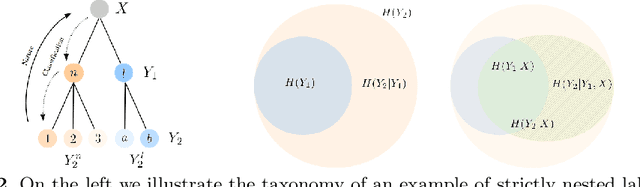

Standard deep neural networks (DNNs) are commonly trained in an end-to-end fashion for specific tasks such as object recognition, face identification, or character recognition, among many examples. This specificity often leads to overconfident models that generalize poorly to samples that are not from the original training distribution. Moreover, such standard DNNs do not allow to leverage information from heterogeneously annotated training data, where for example, labels may be provided with different levels of granularity. Furthermore, DNNs do not produce results with simultaneous different levels of confidence for different levels of detail, they are most commonly an all or nothing approach. To address these challenges, we introduce the concept of nested learning: how to obtain a hierarchical representation of the input such that a coarse label can be extracted first, and sequentially refine this representation, if the sample permits, to obtain successively refined predictions, all of them with the corresponding confidence. We explicitly enforce this behavior by creating a sequence of nested information bottlenecks. Looking at the problem of nested learning from an information theory perspective, we design a network topology with two important properties. First, a sequence of low dimensional (nested) feature embeddings are enforced. Then we show how the explicit combination of nested outputs can improve both the robustness and the accuracy of finer predictions. Experimental results on Cifar-10, Cifar-100, MNIST, Fashion-MNIST, Dbpedia, and Plantvillage demonstrate that nested learning outperforms the same network trained in the standard end-to-end fashion.
Differential 3D Facial Recognition: Adding 3D to Your State-of-the-Art 2D Method
Apr 03, 2020
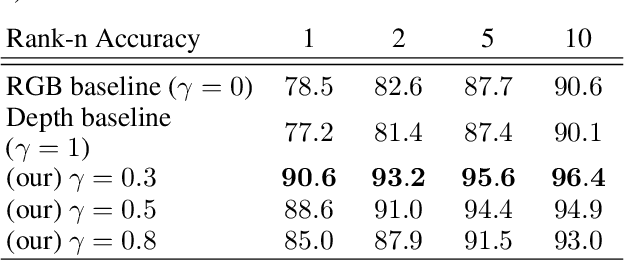
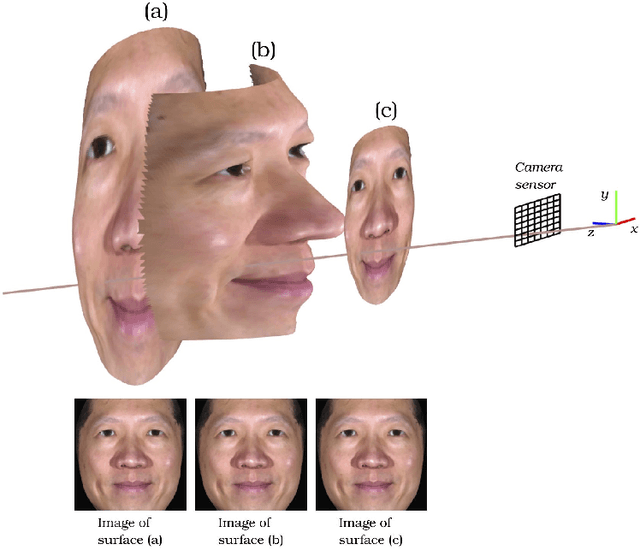
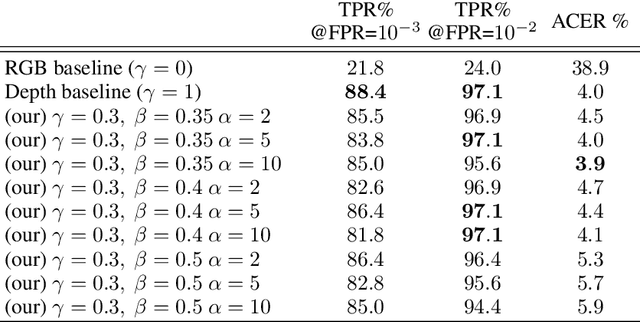
Active illumination is a prominent complement to enhance 2D face recognition and make it more robust, e.g., to spoofing attacks and low-light conditions. In the present work we show that it is possible to adopt active illumination to enhance state-of-the-art 2D face recognition approaches with 3D features, while bypassing the complicated task of 3D reconstruction. The key idea is to project over the test face a high spatial frequency pattern, which allows us to simultaneously recover real 3D information plus a standard 2D facial image. Therefore, state-of-the-art 2D face recognition solution can be transparently applied, while from the high frequency component of the input image, complementary 3D facial features are extracted. Experimental results on ND-2006 dataset show that the proposed ideas can significantly boost face recognition performance and dramatically improve the robustness to spoofing attacks.
Fairness With Minimal Harm: A Pareto-Optimal Approach For Healthcare
Nov 16, 2019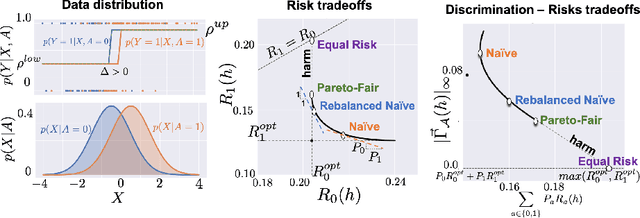

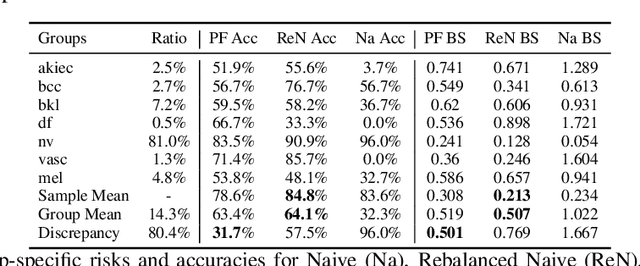
Common fairness definitions in machine learning focus on balancing notions of disparity and utility. In this work, we study fairness in the context of risk disparity among sub-populations. We are interested in learning models that minimize performance discrepancies across sensitive groups without causing unnecessary harm. This is relevant to high-stakes domains such as healthcare, where non-maleficence is a core principle. We formalize this objective using Pareto frontiers, and provide analysis, based on recent works in fairness, to exemplify scenarios were perfect fairness might not be feasible without doing unnecessary harm. We present a methodology for training neural networks that achieve our goal by dynamically re-balancing subgroups risks. We argue that even in domains where fairness at cost is required, finding a non-unnecessary-harm fairness model is the optimal initial step. We demonstrate this methodology on real case-studies of predicting ICU patient mortality, and classifying skin lesions from dermatoscopic images.
SalGaze: Personalizing Gaze Estimation Using Visual Saliency
Oct 23, 2019
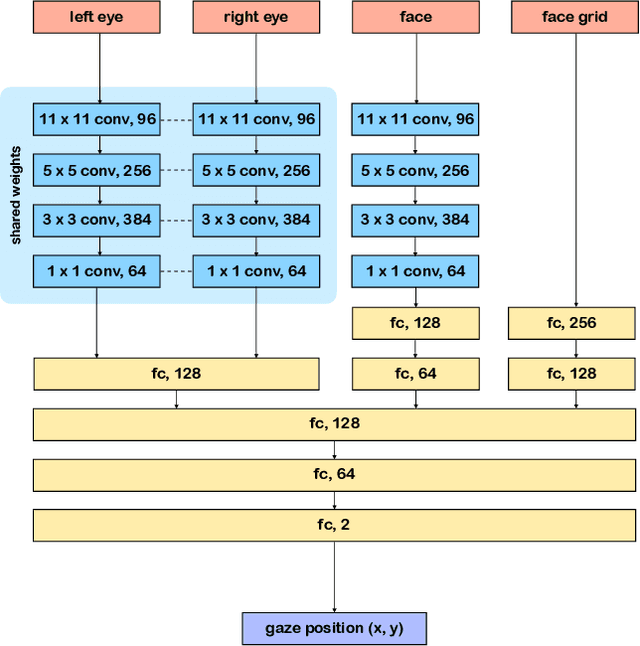
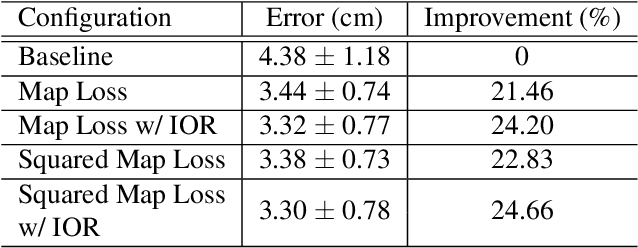
Traditional gaze estimation methods typically require explicit user calibration to achieve high accuracy. This process is cumbersome and recalibration is often required when there are changes in factors such as illumination and pose. To address this challenge, we introduce SalGaze, a framework that utilizes saliency information in the visual content to transparently adapt the gaze estimation algorithm to the user without explicit user calibration. We design an algorithm to transform a saliency map into a differentiable loss map that can be used for the optimization of CNN-based models. SalGaze is also able to greatly augment standard point calibration data with implicit video saliency calibration data using a unified framework. We show accuracy improvements over 24% using our technique on existing methods.
Range Adaptation for 3D Object Detection in LiDAR
Sep 26, 2019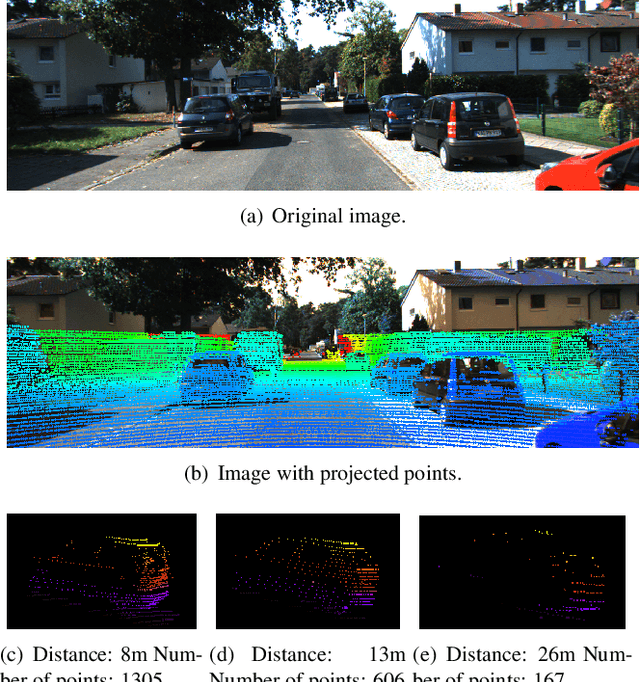
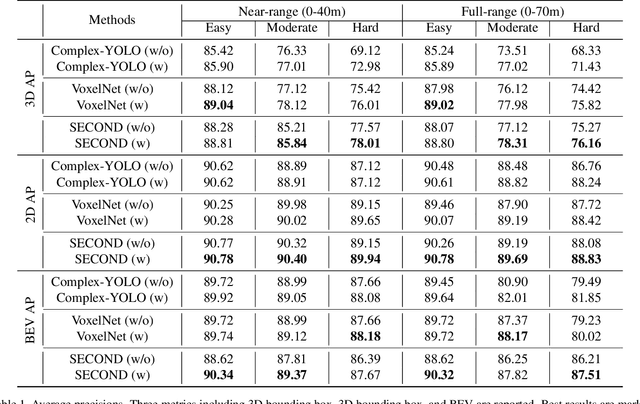
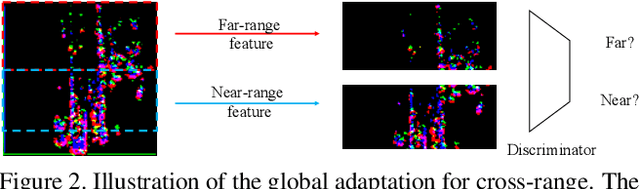

LiDAR-based 3D object detection plays a crucial role in modern autonomous driving systems. LiDAR data often exhibit severe changes in properties across different observation ranges. In this paper, we explore cross-range adaptation for 3D object detection using LiDAR, i.e., far-range observations are adapted to near-range. This way, far-range detection is optimized for similar performance to near-range one. We adopt a bird-eyes view (BEV) detection framework to perform the proposed model adaptation. Our model adaptation consists of an adversarial global adaptation, and a fine-grained local adaptation. The proposed cross range adaptation framework is validated on three state-of-the-art LiDAR based object detection networks, and we consistently observe performance improvement on the far-range objects, without adding any auxiliary parameters to the model. To the best of our knowledge, this paper is the first attempt to study cross-range LiDAR adaptation for object detection in point clouds. To demonstrate the generality of the proposed adaptation framework, experiments on more challenging cross-device adaptation are further conducted, and a new LiDAR dataset with high-quality annotated point clouds is released to promote future research.
Stochastic Conditional Generative Networks with Basis Decomposition
Sep 25, 2019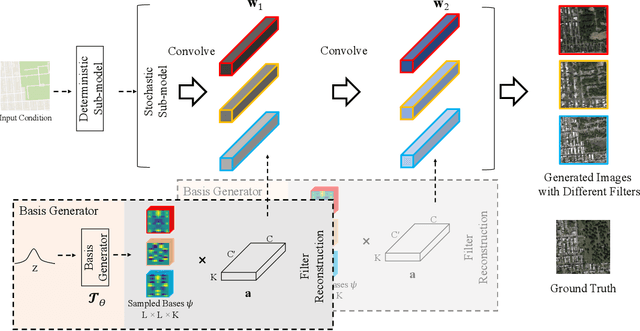
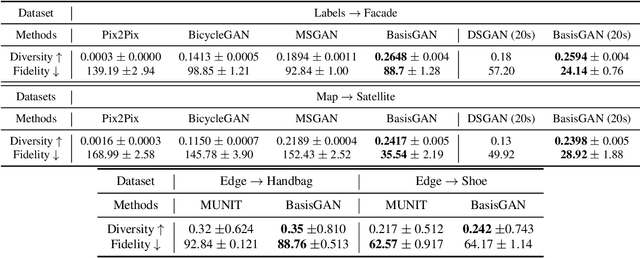


While generative adversarial networks (GANs) have revolutionized machine learning, a number of open questions remain to fully understand them and exploit their power. One of these questions is how to efficiently achieve proper diversity and sampling of the multi-mode data space. To address this, we introduce BasisGAN, a stochastic conditional multi-mode image generator. By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we learn a plug-and-played basis generator to stochastically generate basis elements, with just a few hundred of parameters, to fully embed stochasticity into convolutional filters. By sampling basis elements instead of filters, we dramatically reduce the cost of modeling the parameter space with no sacrifice on either image diversity or fidelity. To illustrate this proposed plug-and-play framework, we construct variants of BasisGAN based on state-of-the-art conditional image generation networks, and train the networks by simply plugging in a basis generator, without additional auxiliary components, hyperparameters, or training objectives. The experimental success is complemented with theoretical results indicating how the perturbations introduced by the proposed sampling of basis elements can propagate to the appearance of generated images.
Domain-invariant Learning using Adaptive Filter Decomposition
Sep 25, 2019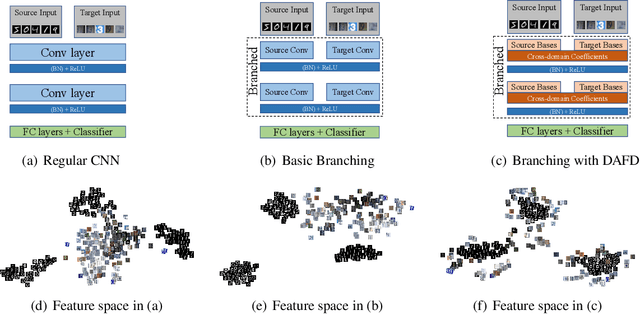
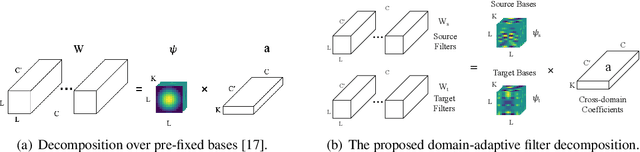

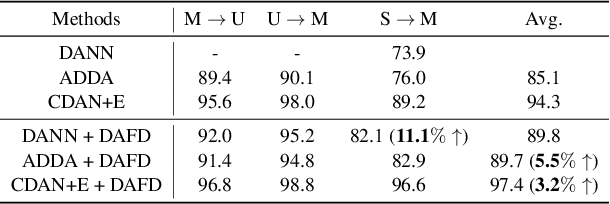
Domain shifts are frequently encountered in real-world scenarios. In this paper, we consider the problem of domain-invariant deep learning by explicitly modeling domain shifts with only a small amount of domain-specific parameters in a Convolutional Neural Network (CNN). By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we show for the first time, both empirically and theoretically, that domain shifts can be effectively handled by decomposing a regular convolutional layer into a domain-specific basis layer and a domain-shared basis coefficient layer, while both remain convolutional. An input channel will now first convolve spatially only with each respective domain-specific basis to "absorb" domain variations, and then output channels are linearly combined using common basis coefficients trained to promote shared semantics across domains. We use toy examples, rigorous analysis, and real-world examples to show the framework's effectiveness in cross-domain performance and domain adaptation. With the proposed architecture, we need only a small set of basis elements to model each additional domain, which brings a negligible amount of additional parameters, typically a few hundred.