 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperTree Proof Search for Neural Theorem Proving
May 23, 2022

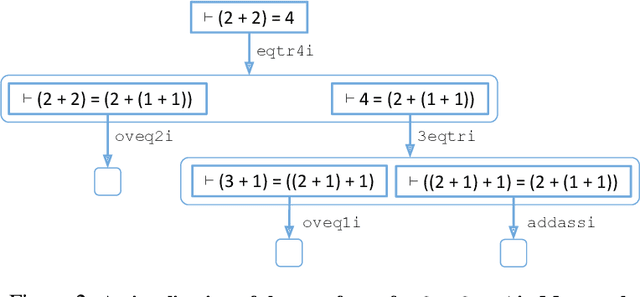
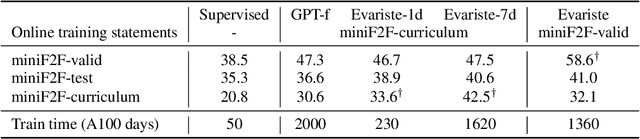
We propose an online training procedure for a transformer-based automated theorem prover. Our approach leverages a new search algorithm, HyperTree Proof Search (HTPS), inspired by the recent success of AlphaZero. Our model learns from previous proof searches through online training, allowing it to generalize to domains far from the training distribution. We report detailed ablations of our pipeline's main components by studying performance on three environments of increasing complexity. In particular, we show that with HTPS alone, a model trained on annotated proofs manages to prove 65.4% of a held-out set of Metamath theorems, significantly outperforming the previous state of the art of 56.5% by GPT-f. Online training on these unproved theorems increases accuracy to 82.6%. With a similar computational budget, we improve the state of the art on the Lean-based miniF2F-curriculum dataset from 31% to 42% proving accuracy.
End-to-end symbolic regression with transformers
Apr 22, 2022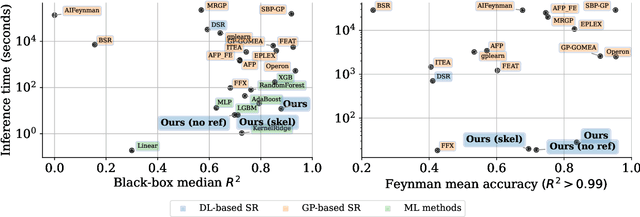

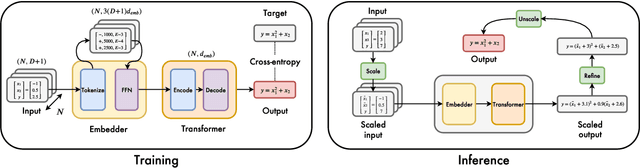
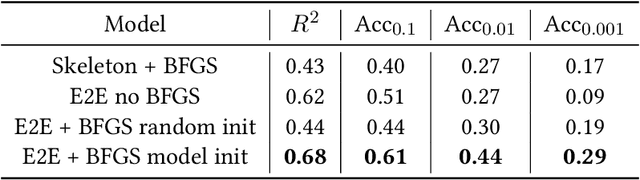
Symbolic regression, the task of predicting the mathematical expression of a function from the observation of its values, is a difficult task which usually involves a two-step procedure: predicting the "skeleton" of the expression up to the choice of numerical constants, then fitting the constants by optimizing a non-convex loss function. The dominant approach is genetic programming, which evolves candidates by iterating this subroutine a large number of times. Neural networks have recently been tasked to predict the correct skeleton in a single try, but remain much less powerful. In this paper, we challenge this two-step procedure, and task a Transformer to directly predict the full mathematical expression, constants included. One can subsequently refine the predicted constants by feeding them to the non-convex optimizer as an informed initialization. We present ablations to show that this end-to-end approach yields better results, sometimes even without the refinement step. We evaluate our model on problems from the SRBench benchmark and show that our model approaches the performance of state-of-the-art genetic programming with several orders of magnitude faster inference.
Deep Symbolic Regression for Recurrent Sequences
Jan 12, 2022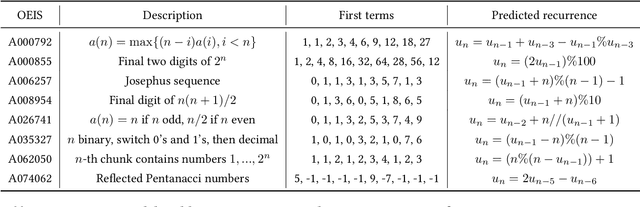
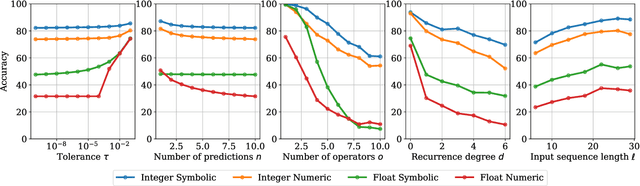
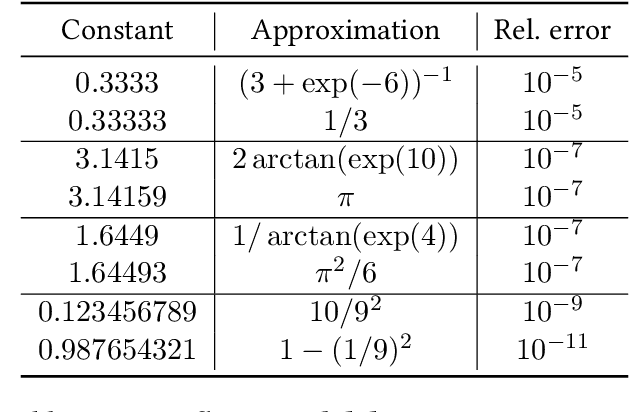
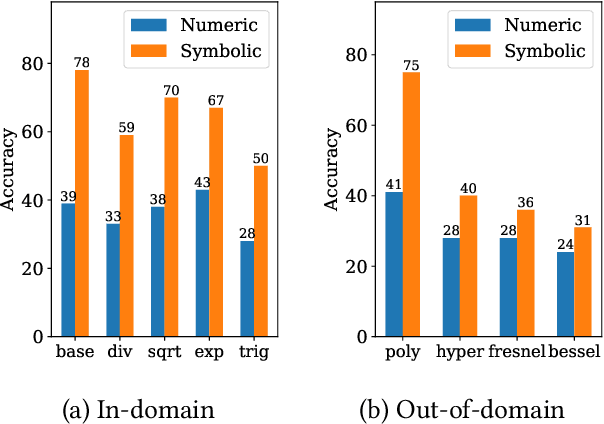
Symbolic regression, i.e. predicting a function from the observation of its values, is well-known to be a challenging task. In this paper, we train Transformers to infer the function or recurrence relation underlying sequences of integers or floats, a typical task in human IQ tests which has hardly been tackled in the machine learning literature. We evaluate our integer model on a subset of OEIS sequences, and show that it outperforms built-in Mathematica functions for recurrence prediction. We also demonstrate that our float model is able to yield informative approximations of out-of-vocabulary functions and constants, e.g. $\operatorname{bessel0}(x)\approx \frac{\sin(x)+\cos(x)}{\sqrt{\pi x}}$ and $1.644934\approx \pi^2/6$. An interactive demonstration of our models is provided at https://bit.ly/3niE5FS.
Leveraging Automated Unit Tests for Unsupervised Code Translation
Oct 13, 2021
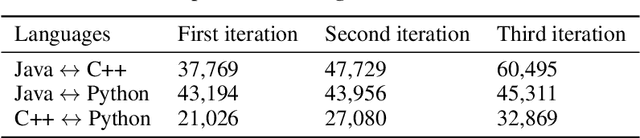
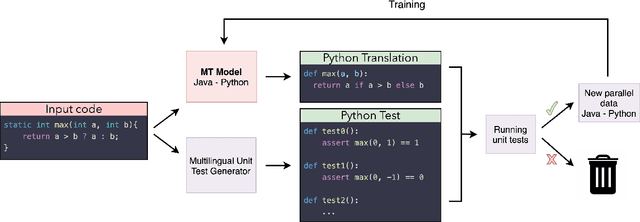
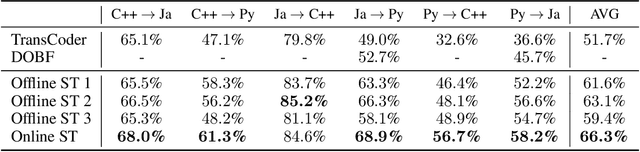
With little to no parallel data available for programming languages, unsupervised methods are well-suited to source code translation. However, the majority of unsupervised machine translation approaches rely on back-translation, a method developed in the context of natural language translation and one that inherently involves training on noisy inputs. Unfortunately, source code is highly sensitive to small changes; a single token can result in compilation failures or erroneous programs, unlike natural languages where small inaccuracies may not change the meaning of a sentence. To address this issue, we propose to leverage an automated unit-testing system to filter out invalid translations, thereby creating a fully tested parallel corpus. We found that fine-tuning an unsupervised model with this filtered data set significantly reduces the noise in the translations so-generated, comfortably outperforming the state-of-the-art for all language pairs studied. In particular, for Java $\to$ Python and Python $\to$ C++ we outperform the best previous methods by more than 16% and 24% respectively, reducing the error rate by more than 35%.
DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
Feb 16, 2021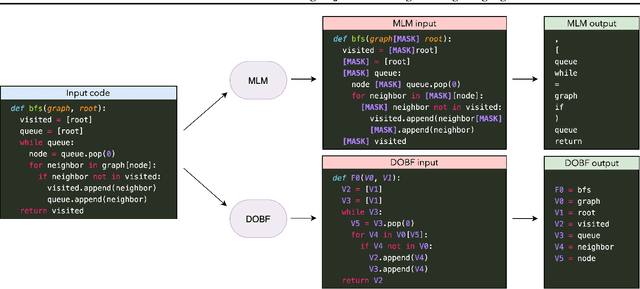


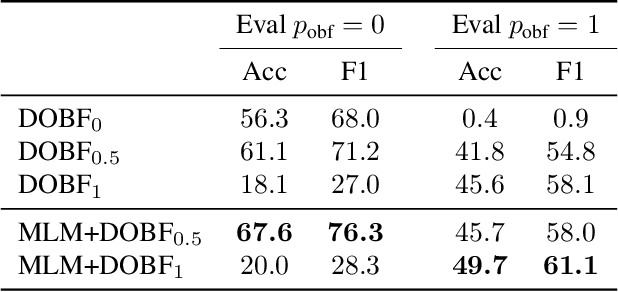
Recent advances in self-supervised learning have dramatically improved the state of the art on a wide variety of tasks. However, research in language model pre-training has mostly focused on natural languages, and it is unclear whether models like BERT and its variants provide the best pre-training when applied to other modalities, such as source code. In this paper, we introduce a new pre-training objective, DOBF, that leverages the structural aspect of programming languages and pre-trains a model to recover the original version of obfuscated source code. We show that models pre-trained with DOBF significantly outperform existing approaches on multiple downstream tasks, providing relative improvements of up to 13% in unsupervised code translation, and 24% in natural language code search. Incidentally, we found that our pre-trained model is able to de-obfuscate fully obfuscated source files, and to suggest descriptive variable names.
Target Conditioning for One-to-Many Generation
Sep 21, 2020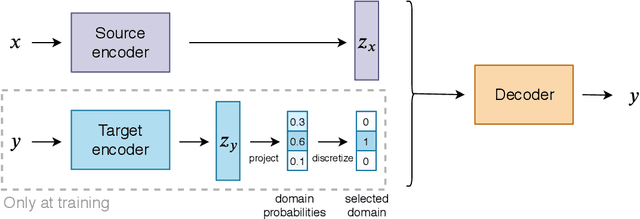
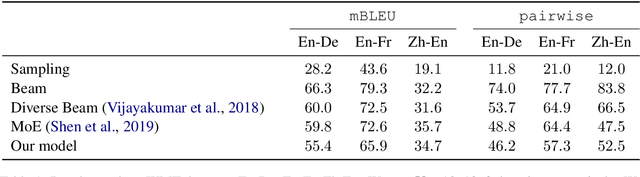
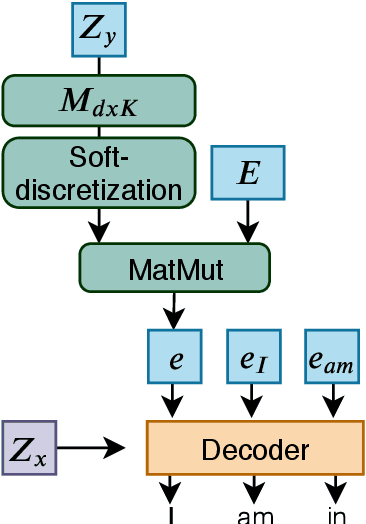
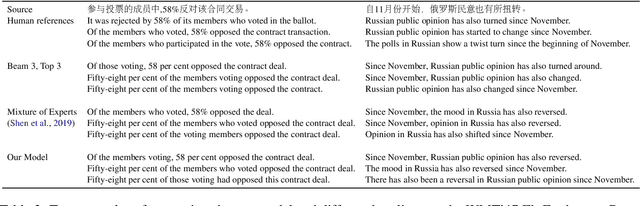
Neural Machine Translation (NMT) models often lack diversity in their generated translations, even when paired with search algorithm, like beam search. A challenge is that the diversity in translations are caused by the variability in the target language, and cannot be inferred from the source sentence alone. In this paper, we propose to explicitly model this one-to-many mapping by conditioning the decoder of a NMT model on a latent variable that represents the domain of target sentences. The domain is a discrete variable generated by a target encoder that is jointly trained with the NMT model. The predicted domain of target sentences are given as input to the decoder during training. At inference, we can generate diverse translations by decoding with different domains. Unlike our strongest baseline (Shen et al., 2019), our method can scale to any number of domains without affecting the performance or the training time. We assess the quality and diversity of translations generated by our model with several metrics, on three different datasets.
Deep Differential System Stability -- Learning advanced computations from examples
Jun 11, 2020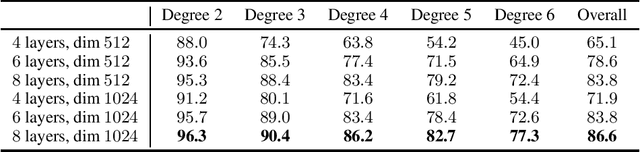

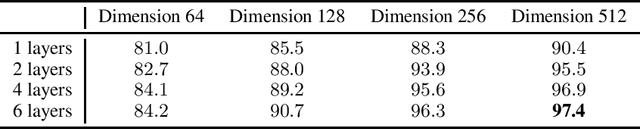
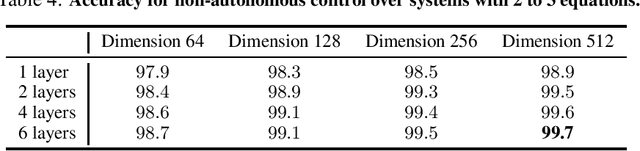
Can advanced mathematical computations be learned from examples? Using transformers over large generated datasets, we train models to learn properties of differential systems, such as local stability, behavior at infinity and controllability. We achieve near perfect estimates of qualitative characteristics of the systems, and good approximations of numerical quantities, demonstrating that neural networks can learn advanced theorems and complex computations without built-in mathematical knowledge.
Unsupervised Translation of Programming Languages
Jun 05, 2020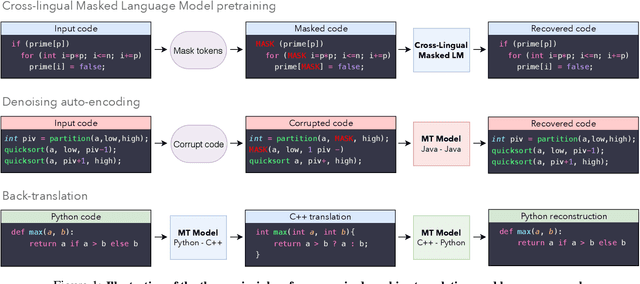



A transcompiler, also known as source-to-source translator, is a system that converts source code from a high-level programming language (such as C++ or Python) to another. Transcompilers are primarily used for interoperability, and to port codebases written in an obsolete or deprecated language (e.g. COBOL, Python 2) to a modern one. They typically rely on handcrafted rewrite rules, applied to the source code abstract syntax tree. Unfortunately, the resulting translations often lack readability, fail to respect the target language conventions, and require manual modifications in order to work properly. The overall translation process is timeconsuming and requires expertise in both the source and target languages, making code-translation projects expensive. Although neural models significantly outperform their rule-based counterparts in the context of natural language translation, their applications to transcompilation have been limited due to the scarcity of parallel data in this domain. In this paper, we propose to leverage recent approaches in unsupervised machine translation to train a fully unsupervised neural transcompiler. We train our model on source code from open source GitHub projects, and show that it can translate functions between C++, Java, and Python with high accuracy. Our method relies exclusively on monolingual source code, requires no expertise in the source or target languages, and can easily be generalized to other programming languages. We also build and release a test set composed of 852 parallel functions, along with unit tests to check the correctness of translations. We show that our model outperforms rule-based commercial baselines by a significant margin.
Deep Learning for Symbolic Mathematics
Dec 02, 2019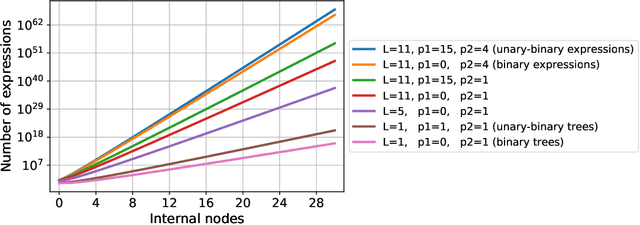
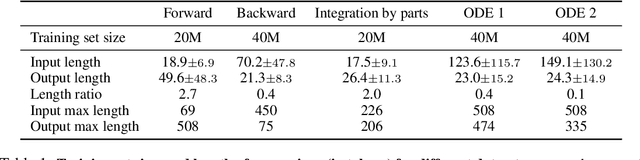

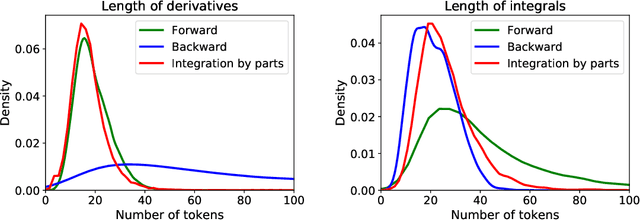
Neural networks have a reputation for being better at solving statistical or approximate problems than at performing calculations or working with symbolic data. In this paper, we show that they can be surprisingly good at more elaborated tasks in mathematics, such as symbolic integration and solving differential equations. We propose a syntax for representing mathematical problems, and methods for generating large datasets that can be used to train sequence-to-sequence models. We achieve results that outperform commercial Computer Algebra Systems such as Matlab or Mathematica.
Large Memory Layers with Product Keys
Jul 10, 2019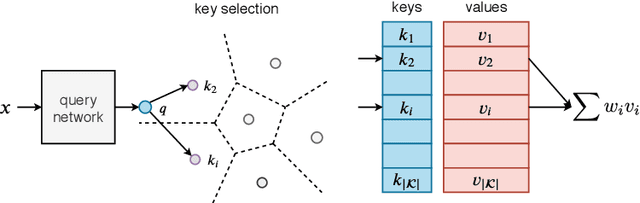
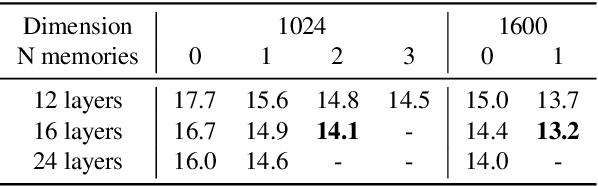
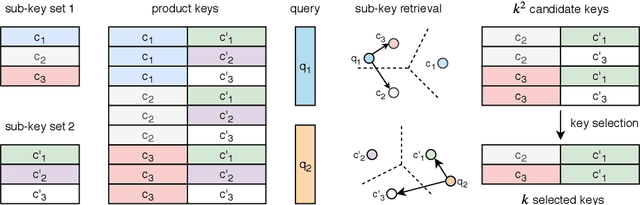

This paper introduces a structured memory which can be easily integrated into a neural network. The memory is very large by design and therefore significantly increases the capacity of the architecture, by up to a billion parameters with a negligible computational overhead. Its design and access pattern is based on product keys, which enable fast and exact nearest neighbor search. The ability to increase the number of parameters while keeping the same computational budget lets the overall system strike a better trade-off between prediction accuracy and computation efficiency both at training and test time. This memory layer allows us to tackle very large scale language modeling tasks. In our experiments we consider a dataset with up to 30 billion words, and we plug our memory layer in a state-of-the-art transformer-based architecture. In particular, we found that a memory augmented model with only 12 layers outperforms a baseline transformer model with 24 layers, while being twice faster at inference time. We release our code for reproducibility purposes.