 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
KDSM: An uplift modeling framework based on knowledge distillation and sample matching
Mar 06, 2023



Uplift modeling aims to estimate the treatment effect on individuals, widely applied in the e-commerce platform to target persuadable customers and maximize the return of marketing activities. Among the existing uplift modeling methods, tree-based methods are adept at fitting increment and generalization, while neural-network-based models excel at predicting absolute value and precision, and these advantages have not been fully explored and combined. Also, the lack of counterfactual sample pairs is the root challenge in uplift modeling. In this paper, we proposed an uplift modeling framework based on Knowledge Distillation and Sample Matching (KDSM). The teacher model is the uplift decision tree (UpliftDT), whose structure is exploited to construct counterfactual sample pairs, and the pairwise incremental prediction is treated as another objective for the student model. Under the idea of multitask learning, the student model can achieve better performance on generalization and even surpass the teacher. Extensive offline experiments validate the universality of different combinations of teachers and student models and the superiority of KDSM measured against the baselines. In online A/B testing, the cost of each incremental room night is reduced by 6.5\%.
Hallucinated-IQA: No-Reference Image Quality Assessment via Adversarial Learning
Apr 05, 2018
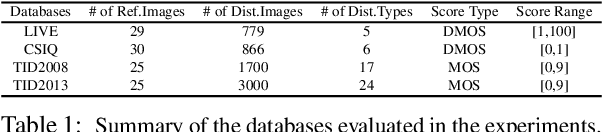
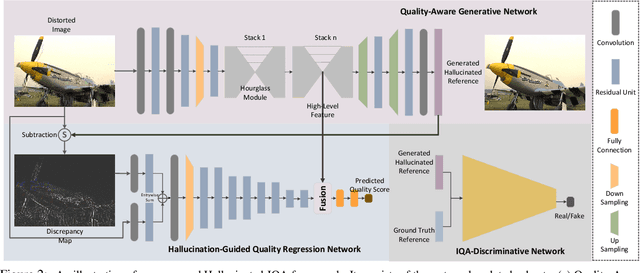
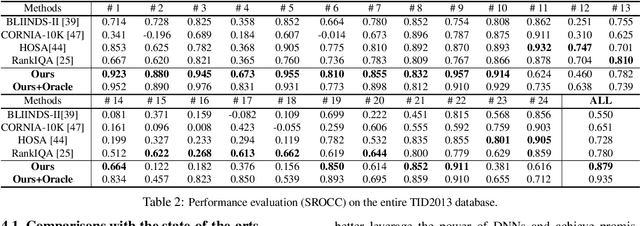
No-reference image quality assessment (NR-IQA) is a fundamental yet challenging task in low-level computer vision community. The difficulty is particularly pronounced for the limited information, for which the corresponding reference for comparison is typically absent. Although various feature extraction mechanisms have been leveraged from natural scene statistics to deep neural networks in previous methods, the performance bottleneck still exists. In this work, we propose a hallucination-guided quality regression network to address the issue. We firstly generate a hallucinated reference constrained on the distorted image, to compensate the absence of the true reference. Then, we pair the information of hallucinated reference with the distorted image, and forward them to the regressor to learn the perceptual discrepancy with the guidance of an implicit ranking relationship within the generator, and therefore produce the precise quality prediction. To demonstrate the effectiveness of our approach, comprehensive experiments are evaluated on four popular image quality assessment benchmarks. Our method significantly outperforms all the previous state-of-the-art methods by large margins. The code and model will be publicly available on the project page https://kwanyeelin.github.io/projects/HIQA/HIQA.html.