 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAL-Turn: Joint Acoustic-Linguistic Modeling for Real-Time and Robust Turn-Taking Detection in Full-Duplex Spoken Dialogue Systems
Mar 27, 2026Despite recent advances, efficient and robust turn-taking detection remains a significant challenge in industrial-grade Voice AI agent deployments. Many existing systems rely solely on acoustic or semantic cues, leading to suboptimal accuracy and stability, while recent attempts to endow large language models with full-duplex capabilities require costly full-duplex data and incur substantial training and deployment overheads, limiting real-time performance. In this paper, we propose JAL-Turn, a lightweight and efficient speech-only turn-taking framework that adopts a joint acoustic-linguistic modeling paradigm, in which a cross-attention module adaptively integrates pre-trained acoustic representations with linguistic features to support low-latency prediction of hold vs shift states. By sharing a frozen ASR encoder, JAL-Turn enables turn-taking prediction to run fully in parallel with speech recognition, introducing no additional end-to-end latency or computational overhead. In addition, we introduce a scalable data construction pipeline that automatically derives reliable turn-taking labels from large-scale real-world dialogue corpora. Extensive experiments on public multilingual benchmarks and an in-house Japanese customer-service dataset show that JAL-Turn consistently outperforms strong state-of-the-art baselines in detection accuracy while maintaining superior real-time performance.
Learning Image-Conditioned Dynamics Models for Control of Under-actuated Legged Millirobots
Mar 30, 2018
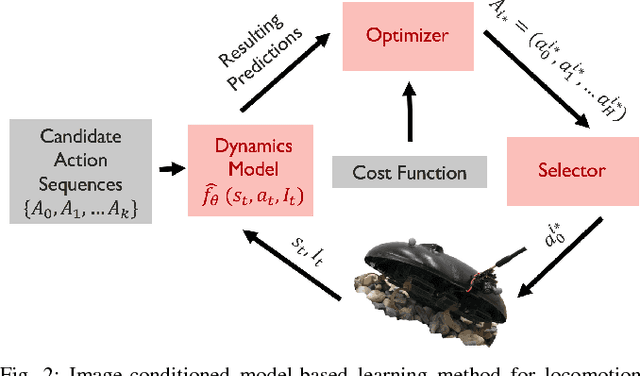


Millirobots are a promising robotic platform for many applications due to their small size and low manufacturing costs. Legged millirobots, in particular, can provide increased mobility in complex environments and improved scaling of obstacles. However, controlling these small, highly dynamic, and underactuated legged systems is difficult. Hand-engineered controllers can sometimes control these legged millirobots, but they have difficulties with dynamic maneuvers and complex terrains. We present an approach for controlling a real-world legged millirobot that is based on learned neural network models. Using less than 17 minutes of data, our method can learn a predictive model of the robot's dynamics that can enable effective gaits to be synthesized on the fly for following user-specified waypoints on a given terrain. Furthermore, by leveraging expressive, high-capacity neural network models, our approach allows for these predictions to be directly conditioned on camera images, endowing the robot with the ability to predict how different terrains might affect its dynamics. This enables sample-efficient and effective learning for locomotion of a dynamic legged millirobot on various terrains, including gravel, turf, carpet, and styrofoam. Experiment videos can be found at https://sites.google.com/view/imageconddyn