 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
Mar 19, 2020
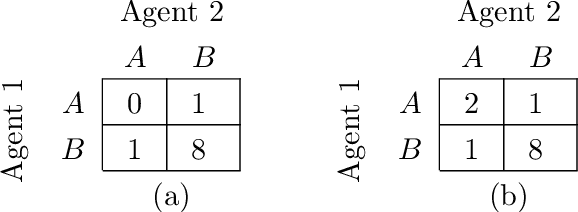
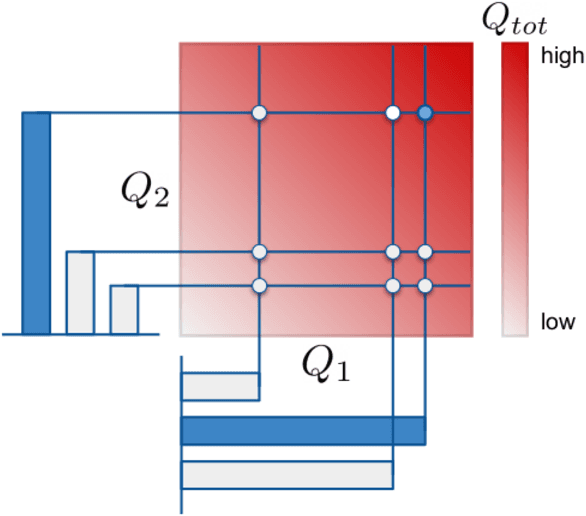
In many real-world settings, a team of agents must coordinate its behaviour while acting in a decentralised fashion. At the same time, it is often possible to train the agents in a centralised fashion where global state information is available and communication constraints are lifted. Learning joint action-values conditioned on extra state information is an attractive way to exploit centralised learning, but the best strategy for then extracting decentralised policies is unclear. Our solution is QMIX, a novel value-based method that can train decentralised policies in a centralised end-to-end fashion. QMIX employs a mixing network that estimates joint action-values as a monotonic combination of per-agent values. We structurally enforce that the joint-action value is monotonic in the per-agent values, through the use of non-negative weights in the mixing network, which guarantees consistency between the centralised and decentralised policies. To evaluate the performance of QMIX, we propose the StarCraft Multi-Agent Challenge (SMAC) as a new benchmark for deep multi-agent reinforcement learning. We evaluate QMIX on a challenging set of SMAC scenarios and show that it significantly outperforms existing multi-agent reinforcement learning methods.
Loaded DiCE: Trading off Bias and Variance in Any-Order Score Function Estimators for Reinforcement Learning
Sep 23, 2019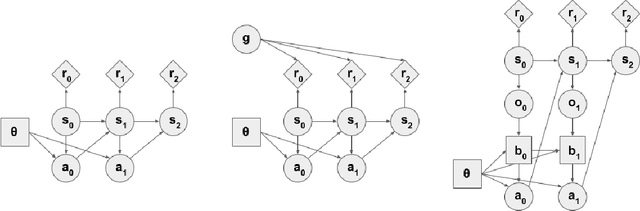
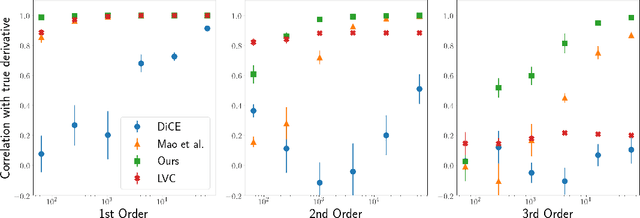
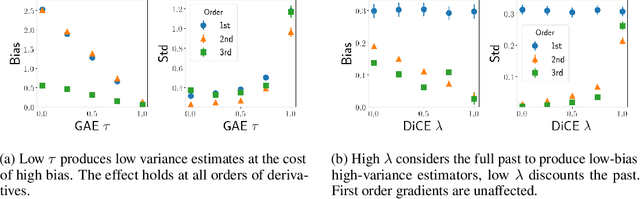
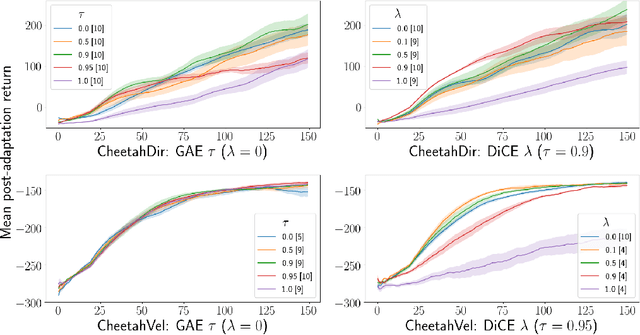
Gradient-based methods for optimisation of objectives in stochastic settings with unknown or intractable dynamics require estimators of derivatives. We derive an objective that, under automatic differentiation, produces low-variance unbiased estimators of derivatives at any order. Our objective is compatible with arbitrary advantage estimators, which allows the control of the bias and variance of any-order derivatives when using function approximation. Furthermore, we propose a method to trade off bias and variance of higher order derivatives by discounting the impact of more distant causal dependencies. We demonstrate the correctness and utility of our objective in analytically tractable MDPs and in meta-reinforcement-learning for continuous control.
Growing Action Spaces
Jun 28, 2019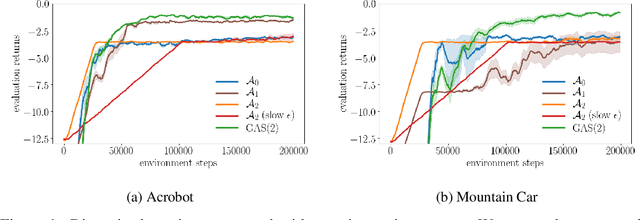
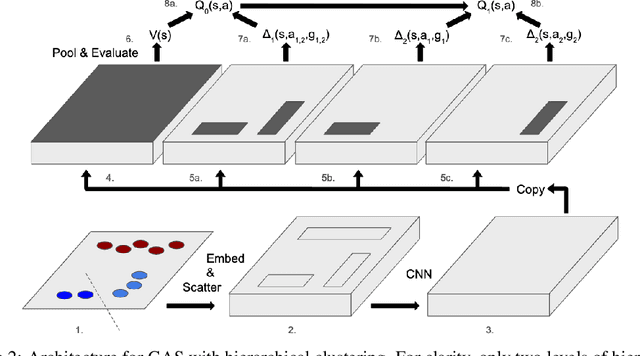
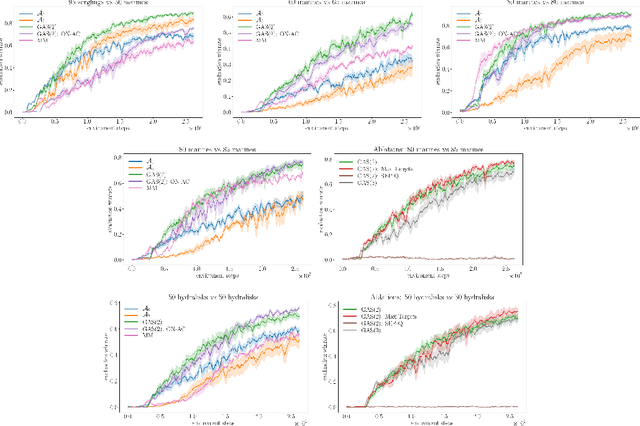

In complex tasks, such as those with large combinatorial action spaces, random exploration may be too inefficient to achieve meaningful learning progress. In this work, we use a curriculum of progressively growing action spaces to accelerate learning. We assume the environment is out of our control, but that the agent may set an internal curriculum by initially restricting its action space. Our approach uses off-policy reinforcement learning to estimate optimal value functions for multiple action spaces simultaneously and efficiently transfers data, value estimates, and state representations from restricted action spaces to the full task. We show the efficacy of our approach in proof-of-concept control tasks and on challenging large-scale StarCraft micromanagement tasks with large, multi-agent action spaces.
A Survey of Reinforcement Learning Informed by Natural Language
Jun 10, 2019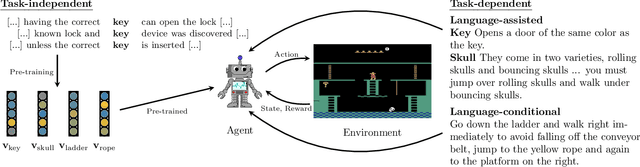
To be successful in real-world tasks, Reinforcement Learning (RL) needs to exploit the compositional, relational, and hierarchical structure of the world, and learn to transfer it to the task at hand. Recent advances in representation learning for language make it possible to build models that acquire world knowledge from text corpora and integrate this knowledge into downstream decision making problems. We thus argue that the time is right to investigate a tight integration of natural language understanding into RL in particular. We survey the state of the field, including work on instruction following, text games, and learning from textual domain knowledge. Finally, we call for the development of new environments as well as further investigation into the potential uses of recent Natural Language Processing (NLP) techniques for such tasks.
The StarCraft Multi-Agent Challenge
Feb 26, 2019
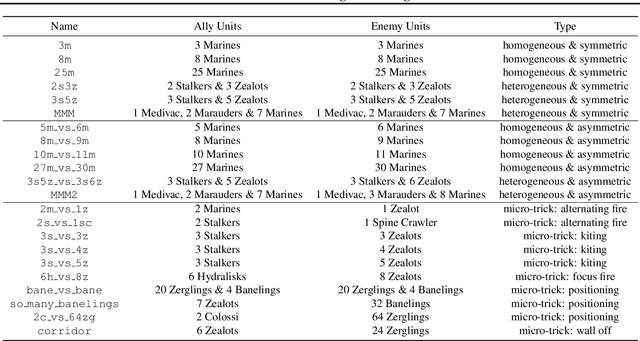

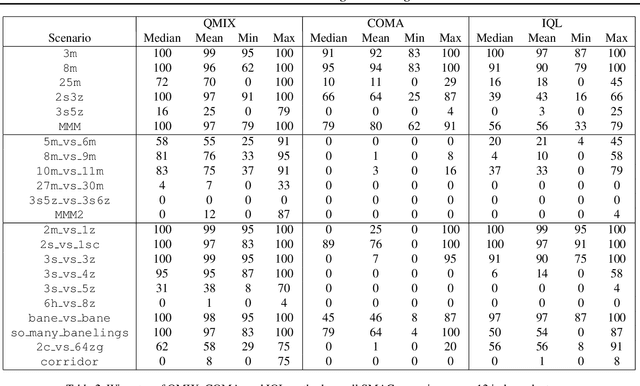
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: https://youtu.be/VZ7zmQ_obZ0.
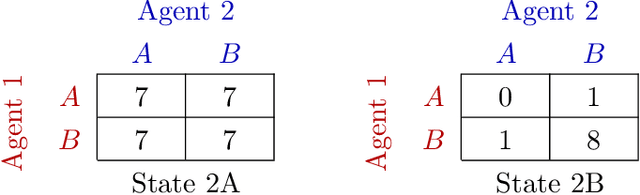
Multi-Agent Common Knowledge Reinforcement Learning
Nov 05, 2018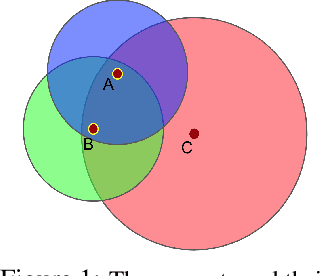

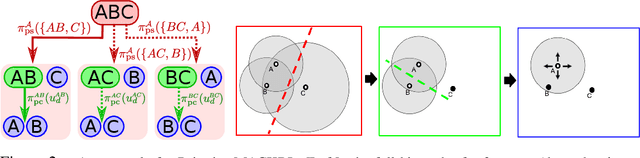
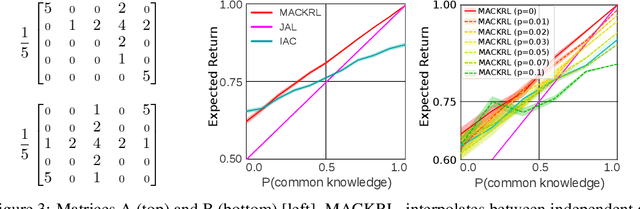
In multi-agent reinforcement learning, centralised policies can only be executed if agents have access to either the global state or an instantaneous communication channel. An alternative approach that circumvents this limitation is to use centralised training of a set of decentralised policies. However, such policies severely limit the agents' ability to coordinate. We propose multi-agent common knowledge reinforcement learning (MACKRL), which strikes a middle ground between these two extremes. Our approach is based on the insight that, even in partially observable settings, subsets of agents often have some common knowledge that they can exploit to coordinate their behaviour. Common knowledge can arise, e.g., if all agents can reliably observe things in their own field of view and know the field of view of other agents. Using this additional information, it is possible to find a centralised policy that conditions only on agents' common knowledge and that can be executed in a decentralised fashion. A resulting challenge is then to determine at what level agents should coordinate. While the common knowledge shared among all agents may not contain much valuable information, there may be subgroups of agents that share common knowledge useful for coordination. MACKRL addresses this challenge using a hierarchical approach: at each level, a controller can either select a joint action for the agents in a given subgroup, or propose a partition of the agents into smaller subgroups whose actions are then selected by controllers at the next level. While action selection involves sampling hierarchically, learning updates are based on the probability of the joint action, calculated by marginalising across the possible decisions of the hierarchy. We show promising results on both a proof-of-concept matrix game and a multi-agent version of StarCraft II Micromanagement.
DiCE: The Infinitely Differentiable Monte-Carlo Estimator
Sep 19, 2018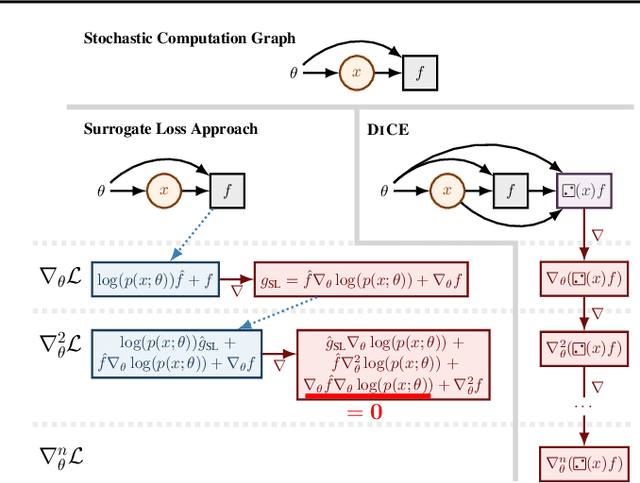
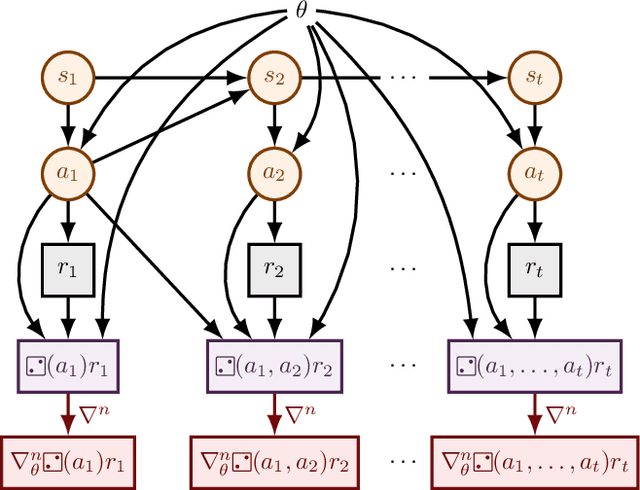
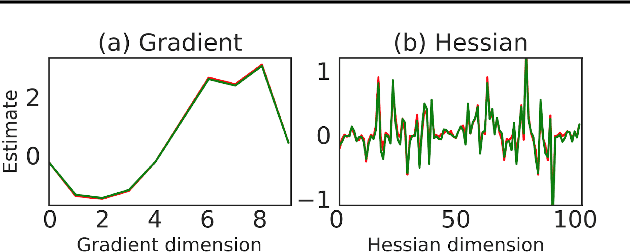
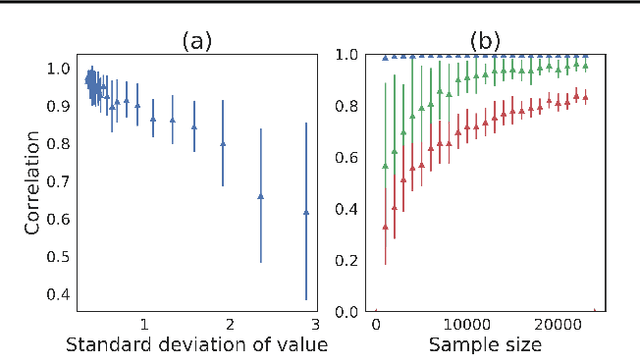
The score function estimator is widely used for estimating gradients of stochastic objectives in stochastic computation graphs (SCG), eg, in reinforcement learning and meta-learning. While deriving the first-order gradient estimators by differentiating a surrogate loss (SL) objective is computationally and conceptually simple, using the same approach for higher-order derivatives is more challenging. Firstly, analytically deriving and implementing such estimators is laborious and not compliant with automatic differentiation. Secondly, repeatedly applying SL to construct new objectives for each order derivative involves increasingly cumbersome graph manipulations. Lastly, to match the first-order gradient under differentiation, SL treats part of the cost as a fixed sample, which we show leads to missing and wrong terms for estimators of higher-order derivatives. To address all these shortcomings in a unified way, we introduce DiCE, which provides a single objective that can be differentiated repeatedly, generating correct estimators of derivatives of any order in SCGs. Unlike SL, DiCE relies on automatic differentiation for performing the requisite graph manipulations. We verify the correctness of DiCE both through a proof and numerical evaluation of the DiCE derivative estimates. We also use DiCE to propose and evaluate a novel approach for multi-agent learning. Our code is available at https://www.github.com/alshedivat/lola.
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
Jun 06, 2018
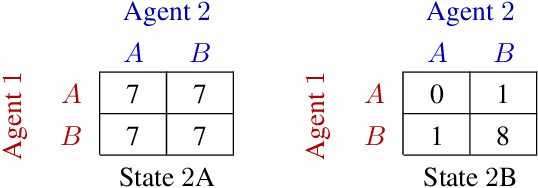
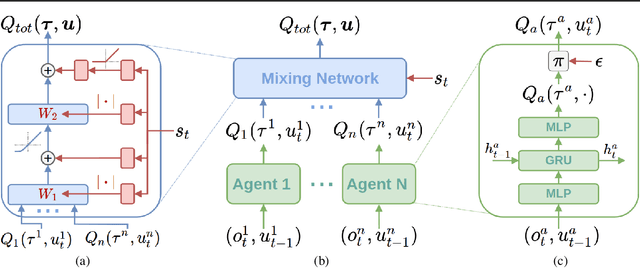
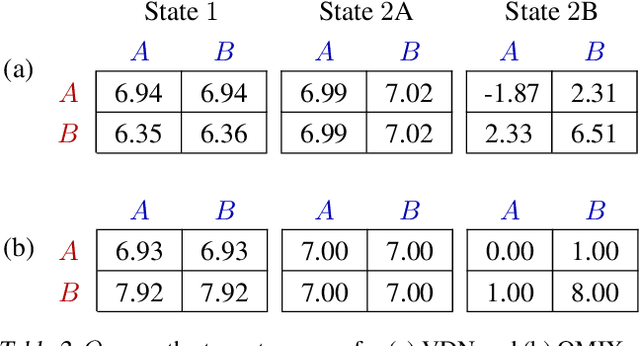
In many real-world settings, a team of agents must coordinate their behaviour while acting in a decentralised way. At the same time, it is often possible to train the agents in a centralised fashion in a simulated or laboratory setting, where global state information is available and communication constraints are lifted. Learning joint action-values conditioned on extra state information is an attractive way to exploit centralised learning, but the best strategy for then extracting decentralised policies is unclear. Our solution is QMIX, a novel value-based method that can train decentralised policies in a centralised end-to-end fashion. QMIX employs a network that estimates joint action-values as a complex non-linear combination of per-agent values that condition only on local observations. We structurally enforce that the joint-action value is monotonic in the per-agent values, which allows tractable maximisation of the joint action-value in off-policy learning, and guarantees consistency between the centralised and decentralised policies. We evaluate QMIX on a challenging set of StarCraft II micromanagement tasks, and show that QMIX significantly outperforms existing value-based multi-agent reinforcement learning methods.
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
May 21, 2018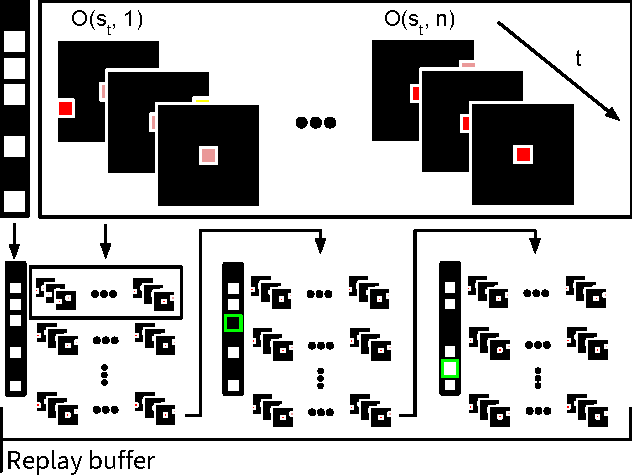

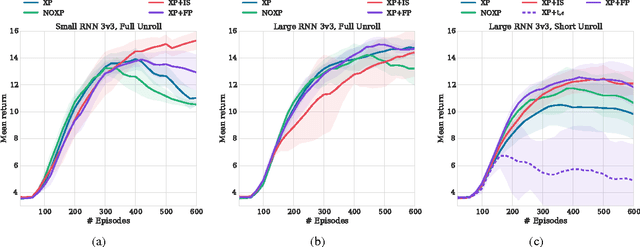
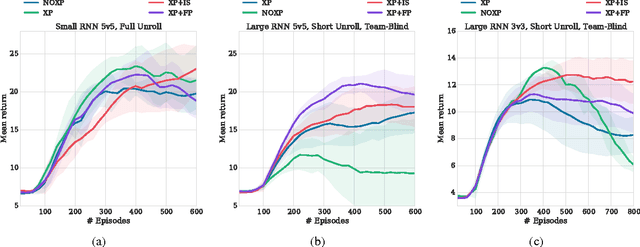
Many real-world problems, such as network packet routing and urban traffic control, are naturally modeled as multi-agent reinforcement learning (RL) problems. However, existing multi-agent RL methods typically scale poorly in the problem size. Therefore, a key challenge is to translate the success of deep learning on single-agent RL to the multi-agent setting. A major stumbling block is that independent Q-learning, the most popular multi-agent RL method, introduces nonstationarity that makes it incompatible with the experience replay memory on which deep Q-learning relies. This paper proposes two methods that address this problem: 1) using a multi-agent variant of importance sampling to naturally decay obsolete data and 2) conditioning each agent's value function on a fingerprint that disambiguates the age of the data sampled from the replay memory. Results on a challenging decentralised variant of StarCraft unit micromanagement confirm that these methods enable the successful combination of experience replay with multi-agent RL.
TreeQN and ATreeC: Differentiable Tree-Structured Models for Deep Reinforcement Learning
Mar 08, 2018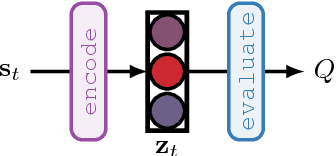
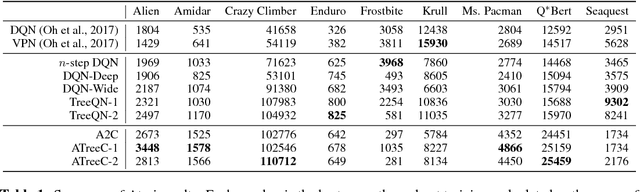
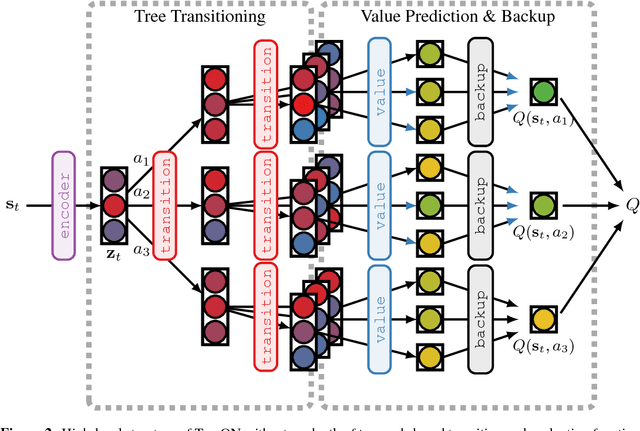
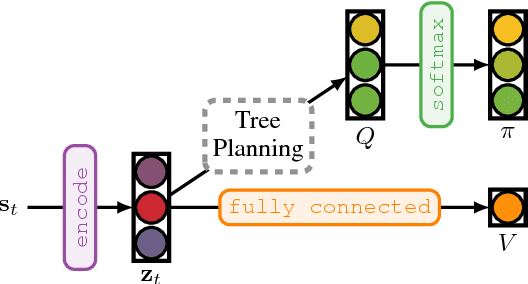
Combining deep model-free reinforcement learning with on-line planning is a promising approach to building on the successes of deep RL. On-line planning with look-ahead trees has proven successful in environments where transition models are known a priori. However, in complex environments where transition models need to be learned from data, the deficiencies of learned models have limited their utility for planning. To address these challenges, we propose TreeQN, a differentiable, recursive, tree-structured model that serves as a drop-in replacement for any value function network in deep RL with discrete actions. TreeQN dynamically constructs a tree by recursively applying a transition model in a learned abstract state space and then aggregating predicted rewards and state-values using a tree backup to estimate Q-values. We also propose ATreeC, an actor-critic variant that augments TreeQN with a softmax layer to form a stochastic policy network. Both approaches are trained end-to-end, such that the learned model is optimised for its actual use in the tree. We show that TreeQN and ATreeC outperform n-step DQN and A2C on a box-pushing task, as well as n-step DQN and value prediction networks (Oh et al. 2017) on multiple Atari games. Furthermore, we present ablation studies that demonstrate the effect of different auxiliary losses on learning transition models.