 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Deduction with Incomplete Information
Nov 01, 2022



A growing body of work studies how to answer a question or verify a claim by generating a natural language "proof": a chain of deductive inferences yielding the answer based on a set of premises. However, these methods can only make sound deductions when they follow from evidence that is given. We propose a new system that can handle the underspecified setting where not all premises are stated at the outset; that is, additional assumptions need to be materialized to prove a claim. By using a natural language generation model to abductively infer a premise given another premise and a conclusion, we can impute missing pieces of evidence needed for the conclusion to be true. Our system searches over two fringes in a bidirectional fashion, interleaving deductive (forward-chaining) and abductive (backward-chaining) generation steps. We sample multiple possible outputs for each step to achieve coverage of the search space, at the same time ensuring correctness by filtering low-quality generations with a round-trip validation procedure. Results on a modified version of the EntailmentBank dataset and a new dataset called Everyday Norms: Why Not? show that abductive generation with validation can recover premises across in- and out-of-domain settings.
Assessing Out-of-Domain Language Model Performance from Few Examples
Oct 13, 2022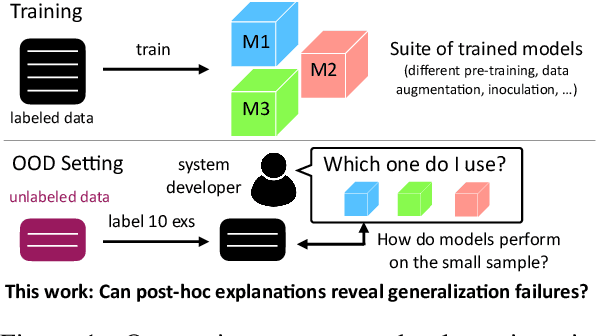
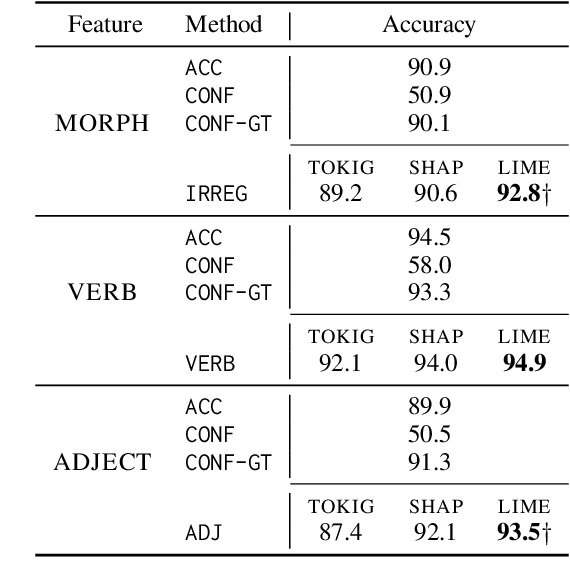

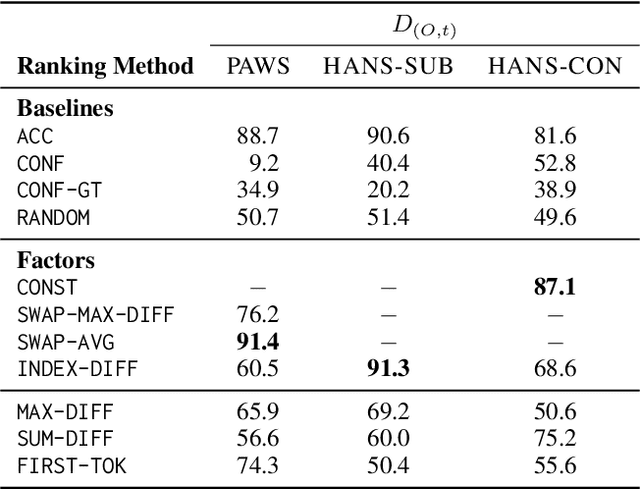
While pretrained language models have exhibited impressive generalization capabilities, they still behave unpredictably under certain domain shifts. In particular, a model may learn a reasoning process on in-domain training data that does not hold for out-of-domain test data. We address the task of predicting out-of-domain (OOD) performance in a few-shot fashion: given a few target-domain examples and a set of models with similar training performance, can we understand how these models will perform on OOD test data? We benchmark the performance on this task when looking at model accuracy on the few-shot examples, then investigate how to incorporate analysis of the models' behavior using feature attributions to better tackle this problem. Specifically, we explore a set of "factors" designed to reveal model agreement with certain pathological heuristics that may indicate worse generalization capabilities. On textual entailment, paraphrase recognition, and a synthetic classification task, we show that attribution-based factors can help rank relative model OOD performance. However, accuracy on a few-shot test set is a surprisingly strong baseline, particularly when the system designer does not have in-depth prior knowledge about the domain shift.
Shortcomings of Question Answering Based Factuality Frameworks for Error Localization
Oct 13, 2022
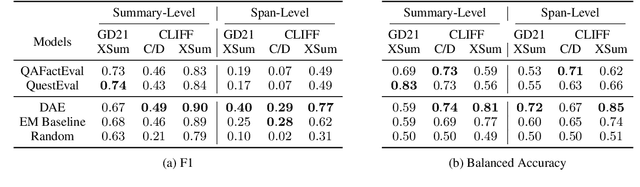

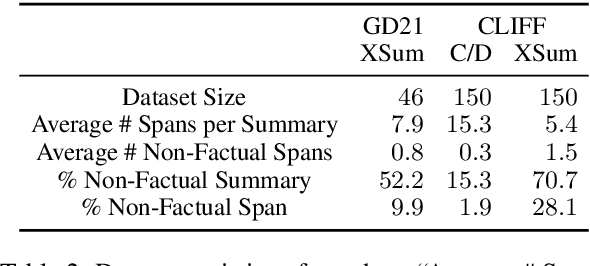
Despite recent progress in abstractive summarization, models often generate summaries with factual errors. Numerous approaches to detect these errors have been proposed, the most popular of which are question answering (QA)-based factuality metrics. These have been shown to work well at predicting summary-level factuality and have potential to localize errors within summaries, but this latter capability has not been systematically evaluated in past research. In this paper, we conduct the first such analysis and find that, contrary to our expectations, QA-based frameworks fail to correctly identify error spans in generated summaries and are outperformed by trivial exact match baselines. Our analysis reveals a major reason for such poor localization: questions generated by the QG module often inherit errors from non-factual summaries which are then propagated further into downstream modules. Moreover, even human-in-the-loop question generation cannot easily offset these problems. Our experiments conclusively show that there exist fundamental issues with localization using the QA framework which cannot be fixed solely by stronger QA and QG models.
Discourse Analysis via Questions and Answers: Parsing Dependency Structures of Questions Under Discussion
Oct 12, 2022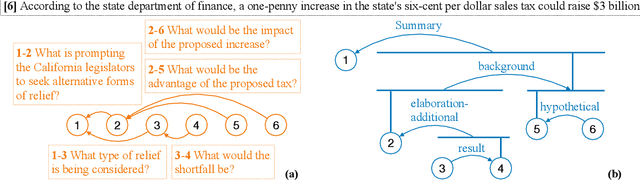

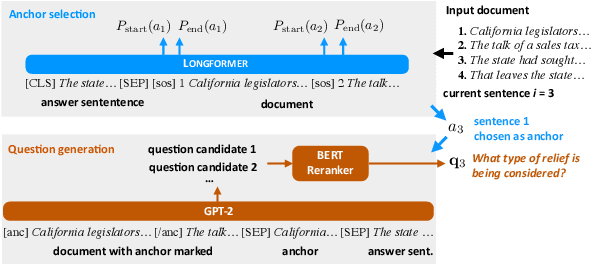
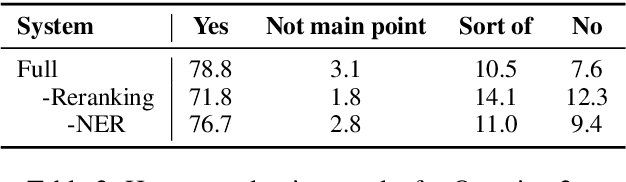
Automatic discourse processing, which can help understand how sentences connect to each other, is bottlenecked by data: current discourse formalisms pose highly demanding annotation tasks involving large taxonomies of discourse relations, making them inaccessible to lay annotators. This work instead adopts the linguistic framework of Questions Under Discussion (QUD) for discourse analysis and seeks to derive QUD structures automatically. QUD views each sentence as an answer to a question triggered in prior context; thus, we characterize relationships between sentences as free-form questions, in contrast to exhaustive fine-grained taxonomies. We develop the first-of-its-kind QUD parser that derives a dependency structure of questions over full documents, trained using a large question-answering dataset DCQA annotated in a manner consistent with the QUD framework. Importantly, data collection is easily crowdsourced using DCQA's paradigm. We show that this leads to a parser attaining strong performance according to human evaluation. We illustrate how our QUD structure is distinct from RST trees, and demonstrate the utility of QUD analysis in the context of document simplification. Our findings show that QUD parsing is an appealing alternative for automatic discourse processing.
News Summarization and Evaluation in the Era of GPT-3
Sep 26, 2022
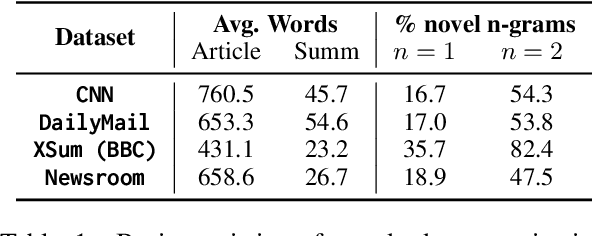
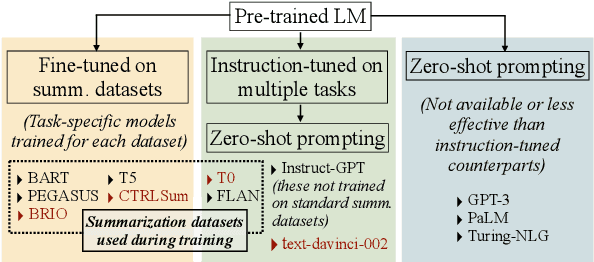
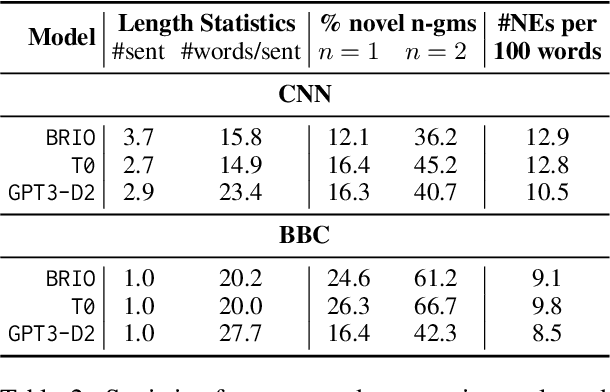
The recent success of zero- and few-shot prompting with models like GPT-3 has led to a paradigm shift in NLP research. In this paper, we study its impact on text summarization, focusing on the classic benchmark domain of news summarization. First, we investigate how zero-shot GPT-3 compares against fine-tuned models trained on large summarization datasets. We show that not only do humans overwhelmingly prefer GPT-3 summaries, but these also do not suffer from common dataset-specific issues such as poor factuality. Next, we study what this means for evaluation, particularly the role of gold standard test sets. Our experiments show that both reference-based and reference-free automatic metrics, e.g. recently proposed QA- or entailment-based factuality approaches, cannot reliably evaluate zero-shot summaries. Finally, we discuss future research challenges beyond generic summarization, specifically, keyword- and aspect-based summarization, showing how dominant fine-tuning approaches compare to zero-shot prompting. To support further research, we release: (a) a corpus of 10K generated summaries from fine-tuned and zero-shot models across 4 standard summarization benchmarks, (b) 1K human preference judgments and rationales comparing different systems for generic- and keyword-based summarization.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022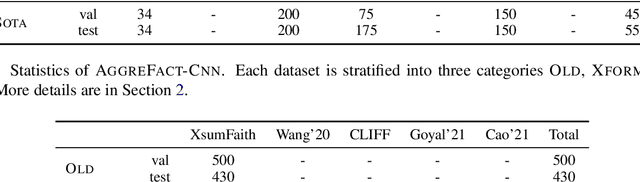
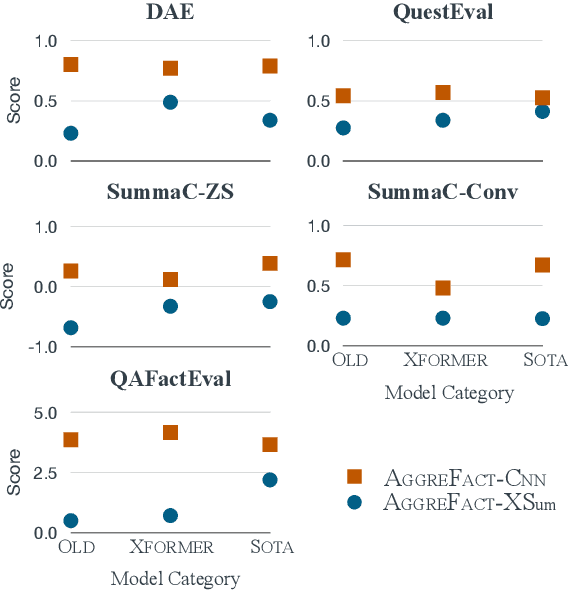
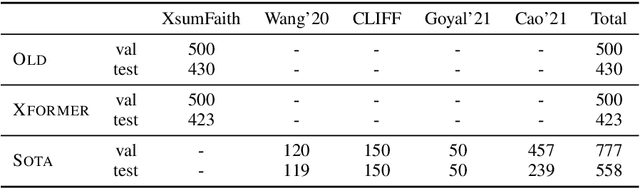
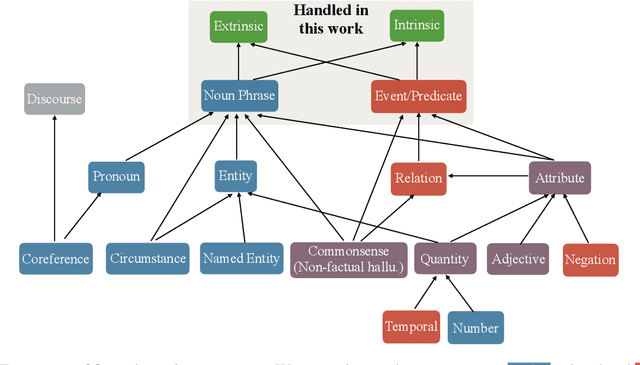
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.
SNaC: Coherence Error Detection for Narrative Summarization
May 19, 2022
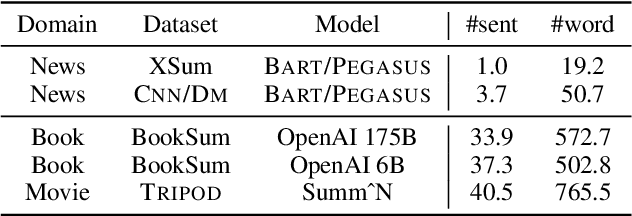

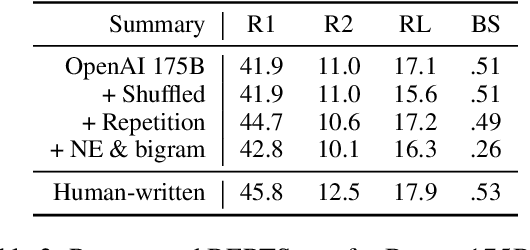
Progress in summarizing long texts is inhibited by the lack of appropriate evaluation frameworks. When a long summary must be produced to appropriately cover the facets of that text, that summary needs to present a coherent narrative to be understandable by a reader, but current automatic and human evaluation methods fail to identify gaps in coherence. In this work, we introduce SNaC, a narrative coherence evaluation framework rooted in fine-grained annotations for long summaries. We develop a taxonomy of coherence errors in generated narrative summaries and collect span-level annotations for 6.6k sentences across 150 book and movie screenplay summaries. Our work provides the first characterization of coherence errors generated by state-of-the-art summarization models and a protocol for eliciting coherence judgments from crowd annotators. Furthermore, we show that the collected annotations allow us to train a strong classifier for automatically localizing coherence errors in generated summaries as well as benchmarking past work in coherence modeling. Finally, our SNaC framework can support future work in long document summarization and coherence evaluation, including improved summarization modeling and post-hoc summary correction.
Generating Literal and Implied Subquestions to Fact-check Complex Claims
May 14, 2022



Verifying complex political claims is a challenging task, especially when politicians use various tactics to subtly misrepresent the facts. Automatic fact-checking systems fall short here, and their predictions like "half-true" are not very useful in isolation, since we have no idea which parts of the claim are true and which are not. In this work, we focus on decomposing a complex claim into a comprehensive set of yes-no subquestions whose answers influence the veracity of the claim. We present ClaimDecomp, a dataset of decompositions for over 1000 claims. Given a claim and its verification paragraph written by fact-checkers, our trained annotators write subquestions covering both explicit propositions of the original claim and its implicit facets, such as asking about additional political context that changes our view of the claim's veracity. We study whether state-of-the-art models can generate such subquestions, showing that these models generate reasonable questions to ask, but predicting the comprehensive set of subquestions from the original claim without evidence remains challenging. We further show that these subquestions can help identify relevant evidence to fact-check the full claim and derive the veracity through their answers, suggesting that they can be useful pieces of a fact-checking pipeline.
The Unreliability of Explanations in Few-Shot In-Context Learning
May 06, 2022



How can prompting a large language model like GPT-3 with explanations improve in-context learning? We focus specifically on two NLP tasks that involve reasoning over text, namely question answering and natural language inference. Including explanations in the prompt and having the model generate them does not consistently improve performance in the settings we study, contrary to recent results on symbolic reasoning tasks (Nye et al., 2021; Wei et al., 2022). Despite careful prompting, explanations generated by GPT-3 may not even be factually grounded in the input, even on simple tasks with straightforward extractive explanations. However, these flawed explanations can still be useful as a way to verify GPT-3's predictions post-hoc. Through analysis in three settings, we show that explanations judged as good by humans--those that are logically consistent with the input and the prediction--usually indicate more accurate predictions. Following these observations, we present a framework for calibrating model predictions based on the reliability of the explanations. Our framework trains calibrators using automatically extracted scores that approximately assess the reliability of explanations, which helps improve performance across three different datasets.
Entity Cloze By Date: What LMs Know About Unseen Entities
May 05, 2022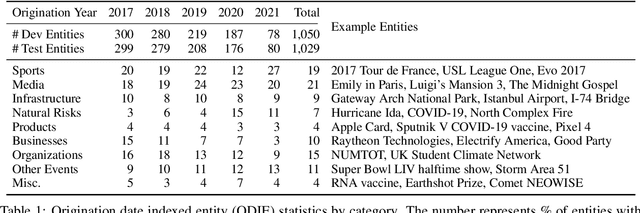

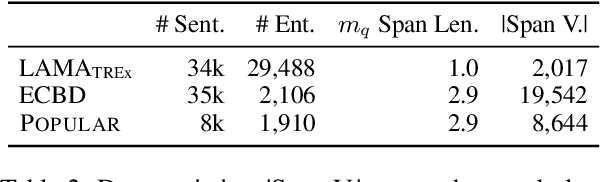
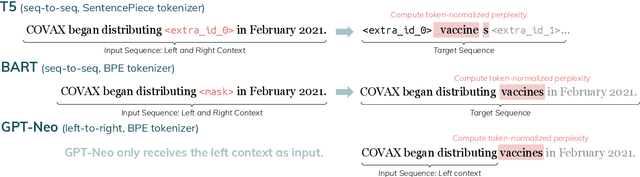
Language models (LMs) are typically trained once on a large-scale corpus and used for years without being updated. However, in a dynamic world, new entities constantly arise. We propose a framework to analyze what LMs can infer about new entities that did not exist when the LMs were pretrained. We derive a dataset of entities indexed by their origination date and paired with their English Wikipedia articles, from which we can find sentences about each entity. We evaluate LMs' perplexity on masked spans within these sentences. We show that models more informed about the entities, such as those with access to a textual definition of them, achieve lower perplexity on this benchmark. Our experimental results demonstrate that making inferences about new entities remains difficult for LMs. Given its wide coverage on entity knowledge and temporal indexing, our dataset can be used to evaluate LMs and techniques designed to modify or extend their knowledge. Our automatic data collection pipeline can be easily used to continually update our benchmark.