 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporal Attention in Dynamic Graphs with Bilinear Interactions
Sep 23, 2019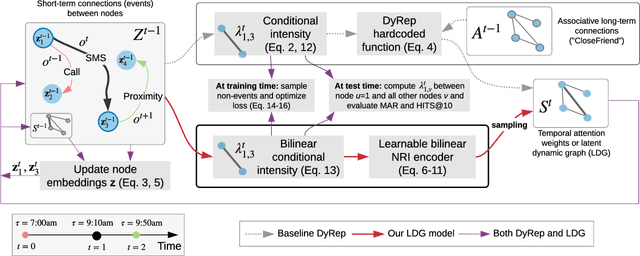
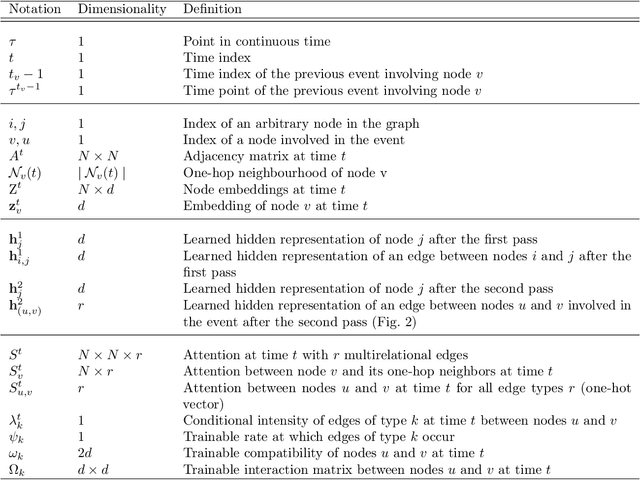

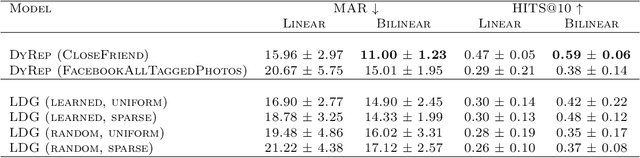
Graphs evolving over time are a natural way to represent data in many domains, such as social networks, bioinformatics, physics and finance. Machine learning methods for graphs, which leverage such data for various prediction tasks, have seen a recent surge of interest and capability. In practice, ground truth edges between nodes in these graphs can be unknown or suboptimal, which hurts the quality of features propagated through the network. Building on recent progress in modeling temporal graphs and learning latent graphs, we extend two methods, Dynamic Representation (DyRep) and Neural Relational Inference (NRI), for the task of dynamic link prediction. We explore the effect of learning temporal attention edges using NRI without requiring the ground truth graph. In experiments on the Social Evolution dataset, we show semantic interpretability of learned attention, often outperforming the baseline DyRep model that uses a ground truth graph to compute attention. In addition, we consider functions acting on pairs of nodes, which are used to predict link or edge representations. We demonstrate that in all cases, our bilinear transformation is superior to feature concatenation, typically employed in prior work. Source code is available at https://github.com/uoguelph-mlrg/LDG.
Image Classification with Hierarchical Multigraph Networks
Jul 21, 2019
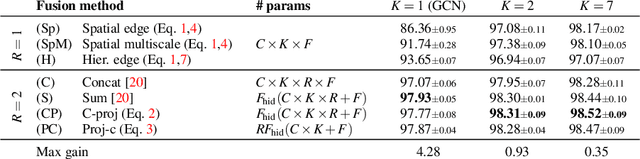
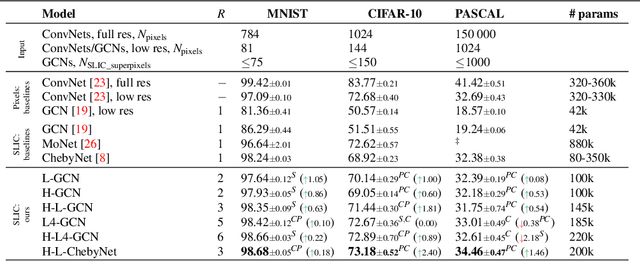
Graph Convolutional Networks (GCNs) are a class of general models that can learn from graph structured data. Despite being general, GCNs are admittedly inferior to convolutional neural networks (CNNs) when applied to vision tasks, mainly due to the lack of domain knowledge that is hardcoded into CNNs, such as spatially oriented translation invariant filters. However, a great advantage of GCNs is the ability to work on irregular inputs, such as superpixels of images. This could significantly reduce the computational cost of image reasoning tasks. Another key advantage inherent to GCNs is the natural ability to model multirelational data. Building upon these two promising properties, in this work, we show best practices for designing GCNs for image classification; in some cases even outperforming CNNs on the MNIST, CIFAR-10 and PASCAL image datasets.
On the Evaluation of Conditional GANs
Jul 11, 2019

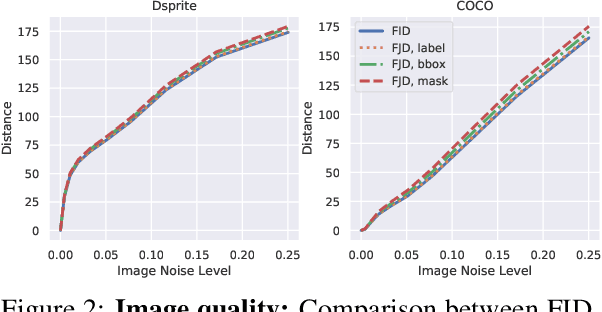
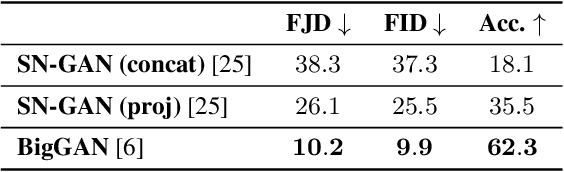
Conditional Generative Adversarial Networks (cGANs) are finding increasingly widespread use in many application domains. Despite outstanding progress, quantitative evaluation of such models often involves multiple distinct metrics to assess different desirable properties such as image quality, intra-conditioning diversity, and conditional consistency, making model benchmarking challenging. In this paper, we propose the Frechet Joint Distance (FJD), which implicitly captures the above mentioned properties in a single metric. FJD is defined as the Frechet Distance of the joint distribution of images and conditionings, making it less sensitive to the often limited per-conditioning sample size. As a result, it scales more gracefully to stronger forms of conditioning such as pixel-wise or multi-modal conditioning. We evaluate FJD on a modified version of the dSprite dataset as well as on the large scale COCO-Stuff dataset, and consistently highlight its benefits when compared to currently established metrics. Moreover, we use the newly introduced metric to compare existing cGAN-based models, with varying conditioning strengths, and show that FJD can be used as a promising single metric for model benchmarking.
Batch Normalization is a Cause of Adversarial Vulnerability
May 29, 2019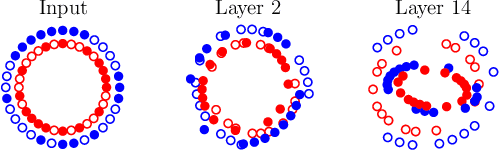

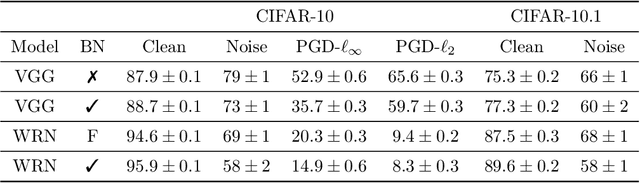
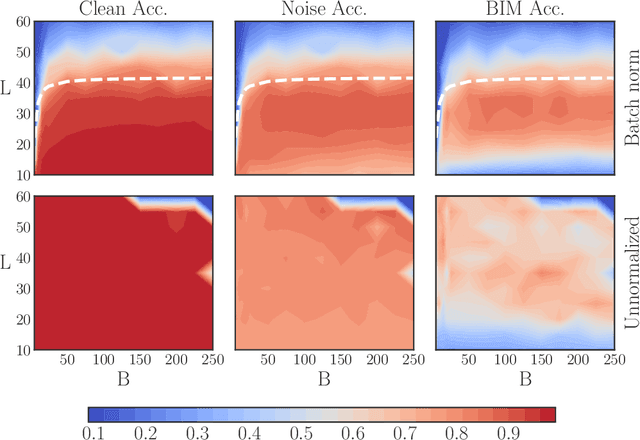
Batch normalization (batch norm) is often used in an attempt to stabilize and accelerate training in deep neural networks. In many cases it indeed decreases the number of parameter updates required to achieve low training error. However, it also reduces robustness to small adversarial input perturbations and noise by double-digit percentages, as we show on five standard datasets. Furthermore, substituting weight decay for batch norm is sufficient to nullify the relationship between adversarial vulnerability and the input dimension. Our work is consistent with a mean-field analysis that found that batch norm causes exploding gradients.
Understanding attention in graph neural networks
May 08, 2019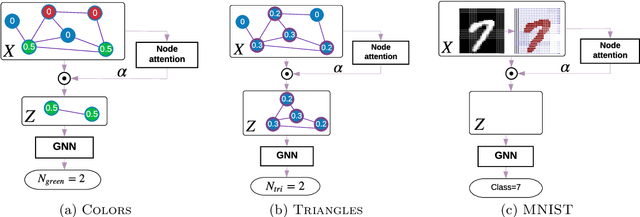
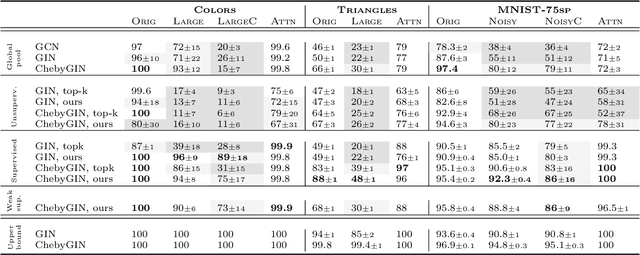
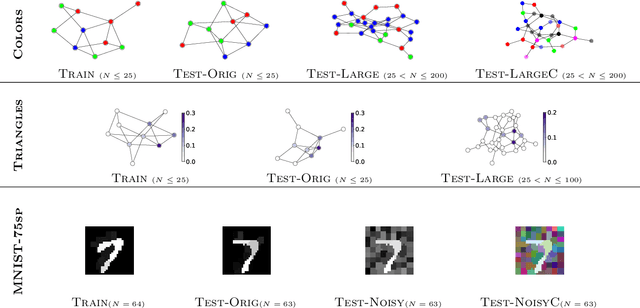
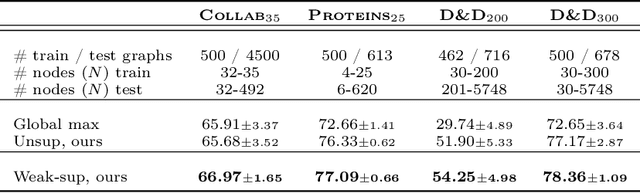
We aim to better understand attention over nodes in graph neural networks and identify factors influencing its effectiveness. Motivated by insights from the work on Graph Isomorphism Networks (Xu et al., 2019), we design simple graph reasoning tasks that allow us to study attention in a controlled environment. We find that under typical conditions the effect of attention is negligible or even harmful, but under certain conditions it provides an exceptional gain in performance of more than 40% in some of our classification tasks. However, we have yet to satisfy these conditions in practice.
Similarity Learning Networks for Animal Individual Re-Identification - Beyond the Capabilities of a Human Observer
Feb 21, 2019
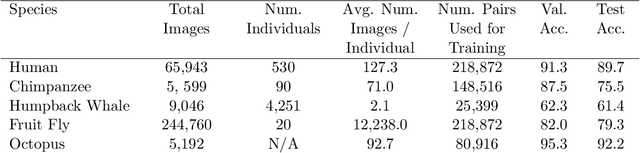


The ability of a researcher to re-identify (re-ID) an animal individual upon re-encounter is fundamental for addressing a broad range of questions in the study of ecosystem function, community and population dynamics, and behavioural ecology. Tagging animals during mark and recapture studies is the most common method for reliable animal re-ID however camera traps are a desirable alternative, requiring less labour, much less intrusion, and prolonged and continuous monitoring into an environment. Despite these advantages, the analyses of camera traps and video for re-ID by humans are criticized for their biases related to human judgment and inconsistencies between analyses. Recent years have witnessed the emergence of deep learning systems which re-ID humans based on image and video data with near perfect accuracy. Despite this success, there are limited examples of this approach for animal re-ID. Here, we demonstrate the viability of novel deep similarity learning methods on five species: humans, chimpanzees, humpback whales, octopus and fruit flies. Our implementation demonstrates the generality of this framework as the same process provides accurate results beyond the capabilities of a human observer. In combination with a species object detection model, this methodology will allow ecologists with camera/video trap data to re-identify individuals that exit and re-enter the camera frame. Our expectation is that this is just the beginning of a major trend that could stand to revolutionize the analysis of camera trap data and, ultimately, our approach to animal ecology.
SISC: End-to-end Interpretable Discovery Radiomics-Driven Lung Cancer Prediction via Stacked Interpretable Sequencing Cells
Jan 15, 2019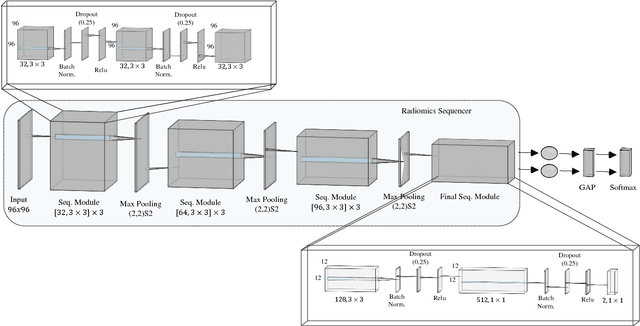
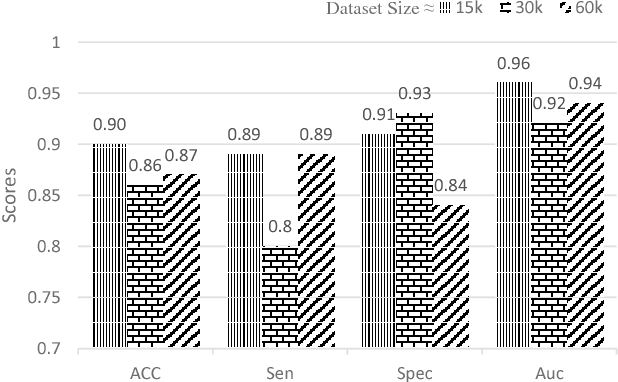
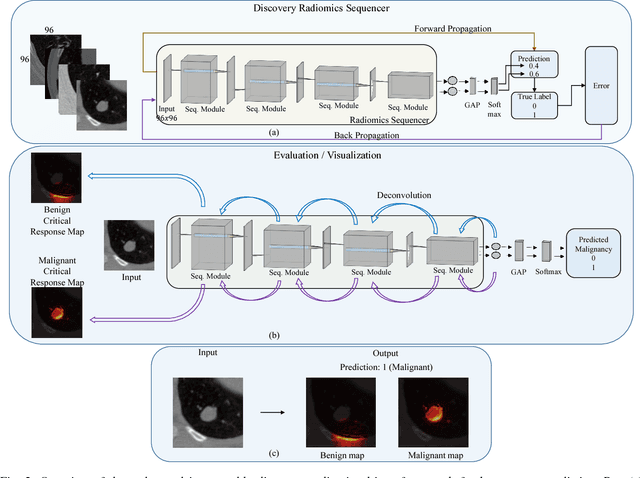
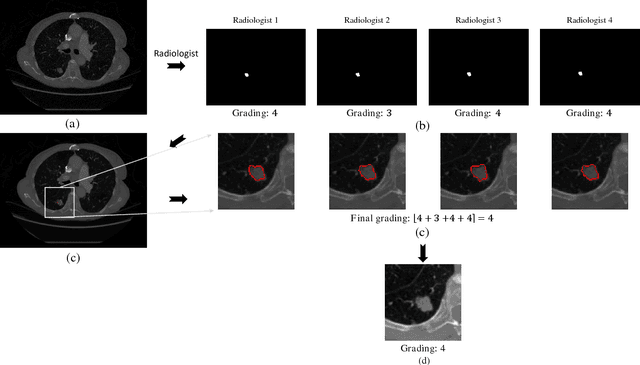
Objective: Lung cancer is the leading cause of cancer-related death worldwide. Computer-aided diagnosis (CAD) systems have shown significant promise in recent years for facilitating the effective detection and classification of abnormal lung nodules in computed tomography (CT) scans. While hand-engineered radiomic features have been traditionally used for lung cancer prediction, there have been significant recent successes achieving state-of-the-art results in the area of discovery radiomics. Here, radiomic sequencers comprising of highly discriminative radiomic features are discovered directly from archival medical data. However, the interpretation of predictions made using such radiomic sequencers remains a challenge. Method: A novel end-to-end interpretable discovery radiomics-driven lung cancer prediction pipeline has been designed, build, and tested. The radiomic sequencer being discovered possesses a deep architecture comprised of stacked interpretable sequencing cells (SISC). Results: The SISC architecture is shown to outperform previous approaches while providing more insight in to its decision making process. Conclusion: The SISC radiomic sequencer is able to achieve state-of-the-art results in lung cancer prediction, and also offers prediction interpretability in the form of critical response maps. Significance: The critical response maps are useful for not only validating the predictions of the proposed SISC radiomic sequencer, but also provide improved radiologist-machine collaboration for effective diagnosis.
Adversarial Examples as an Input-Fault Tolerance Problem
Nov 30, 2018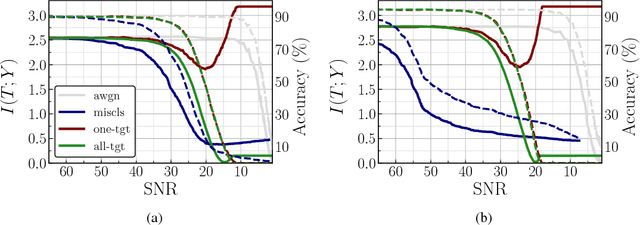
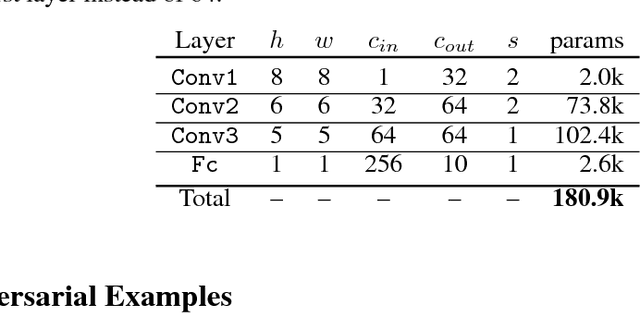

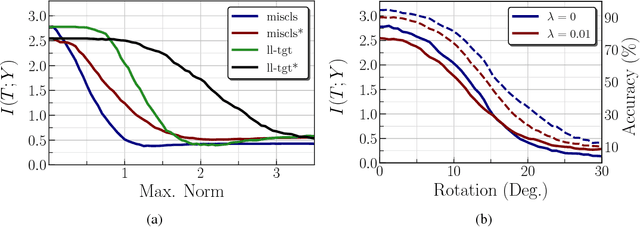
We analyze the adversarial examples problem in terms of a model's fault tolerance with respect to its input. Whereas previous work focuses on arbitrarily strict threat models, i.e., $\epsilon$-perturbations, we consider arbitrary valid inputs and propose an information-based characteristic for evaluating tolerance to diverse input faults.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018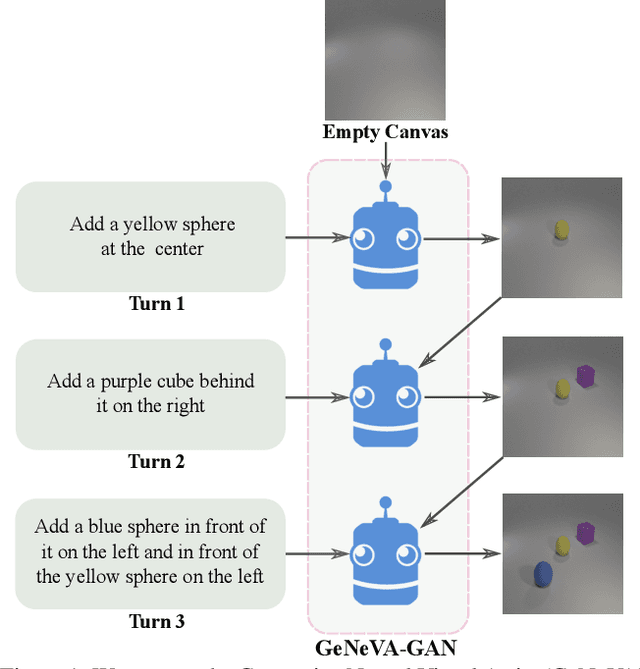
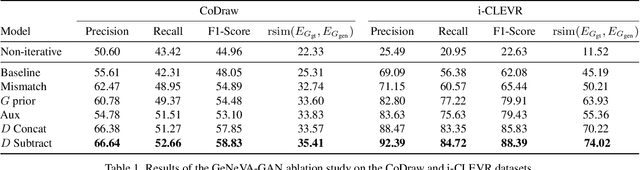

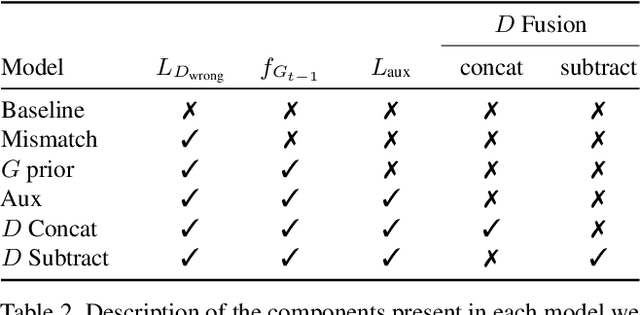
Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
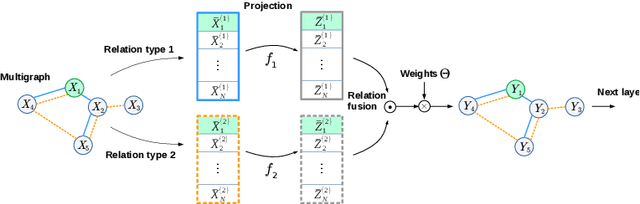
Spectral Multigraph Networks for Discovering and Fusing Relationships in Molecules
Nov 23, 2018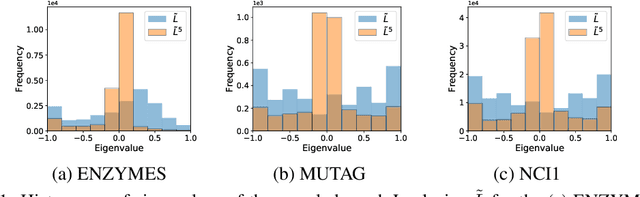
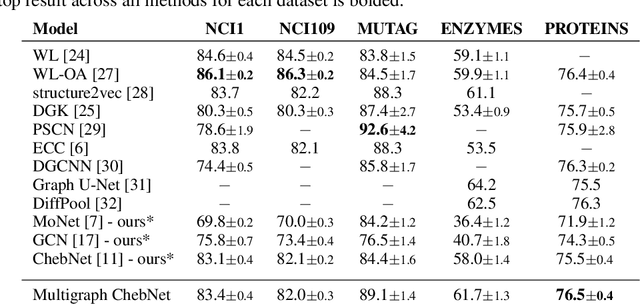
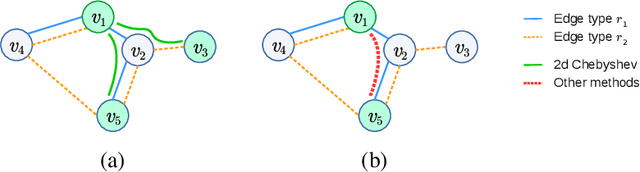

Spectral Graph Convolutional Networks (GCNs) are a generalization of convolutional networks to learning on graph-structured data. Applications of spectral GCNs have been successful, but limited to a few problems where the graph is fixed, such as shape correspondence and node classification. In this work, we address this limitation by revisiting a particular family of spectral graph networks, Chebyshev GCNs, showing its efficacy in solving graph classification tasks with a variable graph structure and size. Chebyshev GCNs restrict graphs to have at most one edge between any pair of nodes. To this end, we propose a novel multigraph network that learns from multi-relational graphs. We model learned edges with abstract meaning and experiment with different ways to fuse the representations extracted from annotated and learned edges, achieving competitive results on a variety of chemical classification benchmarks.