 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrick-by-Brick: Combinatorial Construction with Deep Reinforcement Learning
Oct 29, 2021
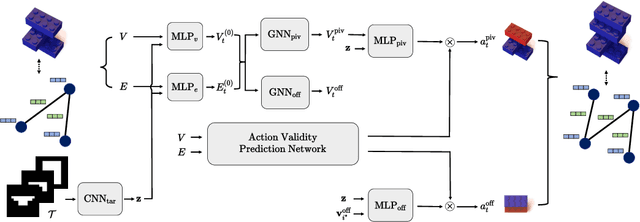
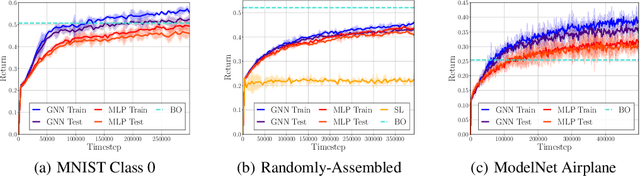
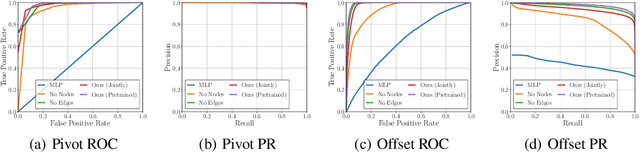
Discovering a solution in a combinatorial space is prevalent in many real-world problems but it is also challenging due to diverse complex constraints and the vast number of possible combinations. To address such a problem, we introduce a novel formulation, combinatorial construction, which requires a building agent to assemble unit primitives (i.e., LEGO bricks) sequentially -- every connection between two bricks must follow a fixed rule, while no bricks mutually overlap. To construct a target object, we provide incomplete knowledge about the desired target (i.e., 2D images) instead of exact and explicit volumetric information to the agent. This problem requires a comprehensive understanding of partial information and long-term planning to append a brick sequentially, which leads us to employ reinforcement learning. The approach has to consider a variable-sized action space where a large number of invalid actions, which would cause overlap between bricks, exist. To resolve these issues, our model, dubbed Brick-by-Brick, adopts an action validity prediction network that efficiently filters invalid actions for an actor-critic network. We demonstrate that the proposed method successfully learns to construct an unseen object conditioned on a single image or multiple views of a target object.
Parameter Prediction for Unseen Deep Architectures
Oct 25, 2021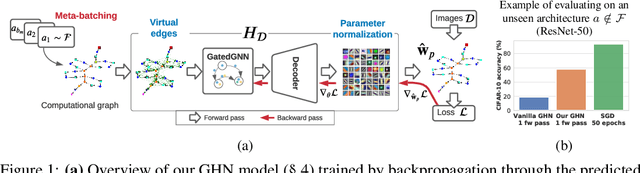
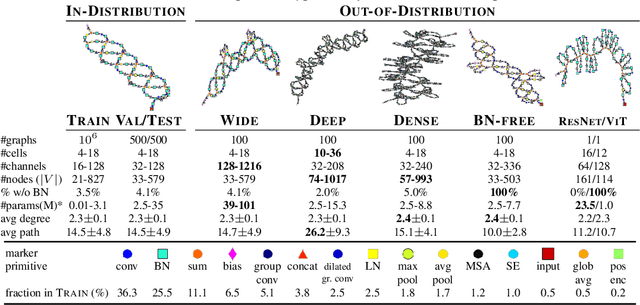


Deep learning has been successful in automating the design of features in machine learning pipelines. However, the algorithms optimizing neural network parameters remain largely hand-designed and computationally inefficient. We study if we can use deep learning to directly predict these parameters by exploiting the past knowledge of training other networks. We introduce a large-scale dataset of diverse computational graphs of neural architectures - DeepNets-1M - and use it to explore parameter prediction on CIFAR-10 and ImageNet. By leveraging advances in graph neural networks, we propose a hypernetwork that can predict performant parameters in a single forward pass taking a fraction of a second, even on a CPU. The proposed model achieves surprisingly good performance on unseen and diverse networks. For example, it is able to predict all 24 million parameters of a ResNet-50 achieving a 60% accuracy on CIFAR-10. On ImageNet, top-5 accuracy of some of our networks approaches 50%. Our task along with the model and results can potentially lead to a new, more computationally efficient paradigm of training networks. Our model also learns a strong representation of neural architectures enabling their analysis.
Unconstrained Scene Generation with Locally Conditioned Radiance Fields
Apr 01, 2021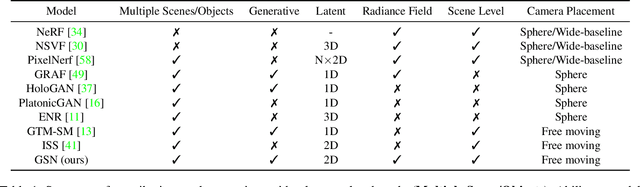
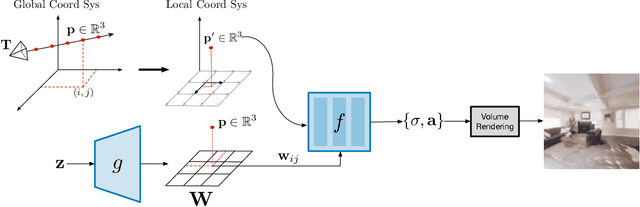

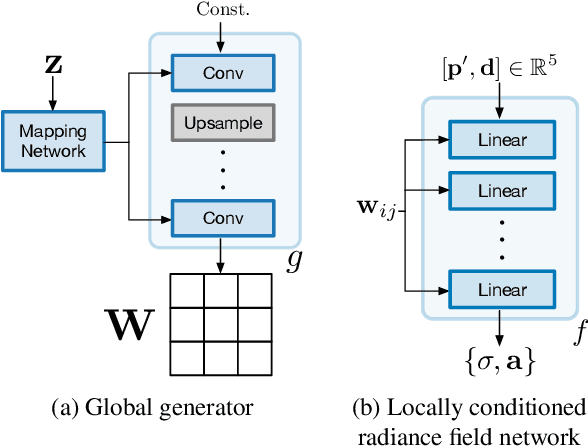
We tackle the challenge of learning a distribution over complex, realistic, indoor scenes. In this paper, we introduce Generative Scene Networks (GSN), which learns to decompose scenes into a collection of many local radiance fields that can be rendered from a free moving camera. Our model can be used as a prior to generate new scenes, or to complete a scene given only sparse 2D observations. Recent work has shown that generative models of radiance fields can capture properties such as multi-view consistency and view-dependent lighting. However, these models are specialized for constrained viewing of single objects, such as cars or faces. Due to the size and complexity of realistic indoor environments, existing models lack the representational capacity to adequately capture them. Our decomposition scheme scales to larger and more complex scenes while preserving details and diversity, and the learned prior enables high-quality rendering from viewpoints that are significantly different from observed viewpoints. When compared to existing models, GSN produces quantitatively higher-quality scene renderings across several different scene datasets.
The GIST and RIST of Iterative Self-Training for Semi-Supervised Segmentation
Mar 31, 2021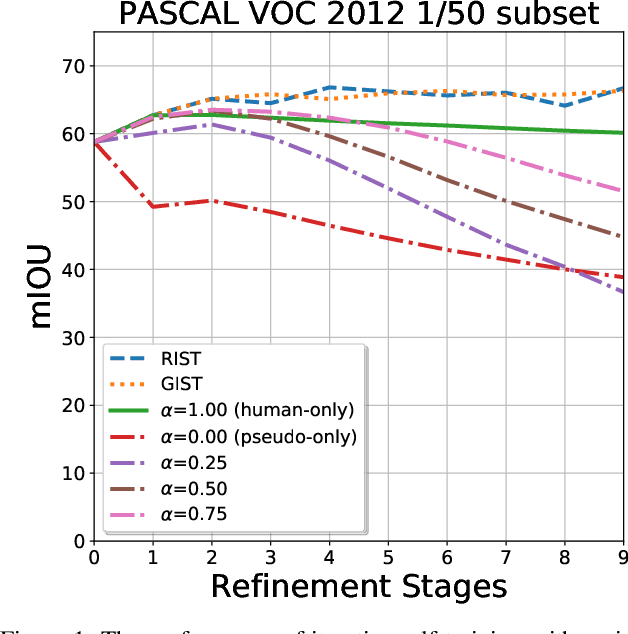
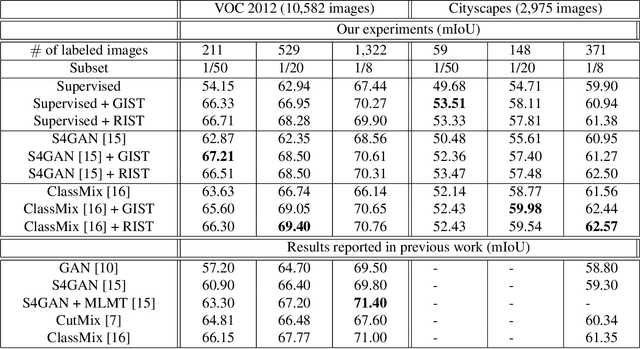

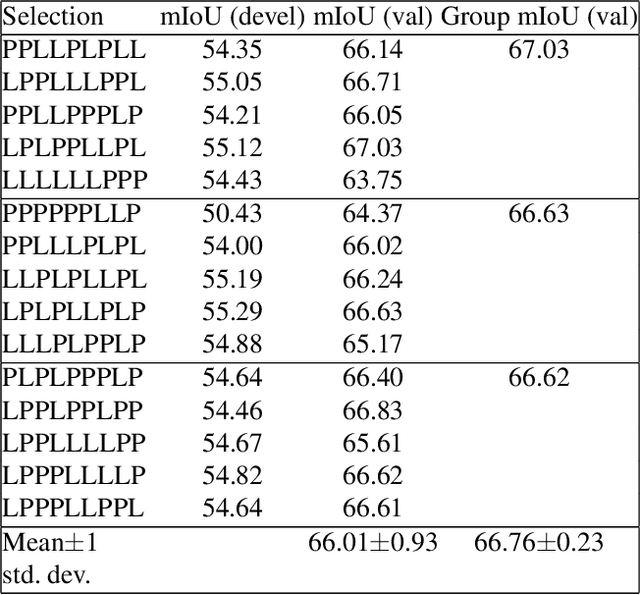
We consider the task of semi-supervised semantic segmentation, where we aim to produce pixel-wise semantic object masks given only a small number of human-labeled training examples. We focus on iterative self-training methods in which we explore the behavior of self-training over multiple refinement stages. We show that iterative self-training leads to performance degradation if done naively with a fixed ratio of human-labeled to pseudo-labeled training examples. We propose Greedy Iterative Self-Training (GIST) and Random Iterative Self-Training (RIST) strategies that alternate between training on either human-labeled data or pseudo-labeled data at each refinement stage, resulting in a performance boost rather than degradation. We further show that GIST and RIST can be combined with existing SOTA methods to boost performance, yielding new SOTA results in Pascal VOC 2012 and Cityscapes dataset across five out of six subsets.
LOHO: Latent Optimization of Hairstyles via Orthogonalization
Mar 10, 2021
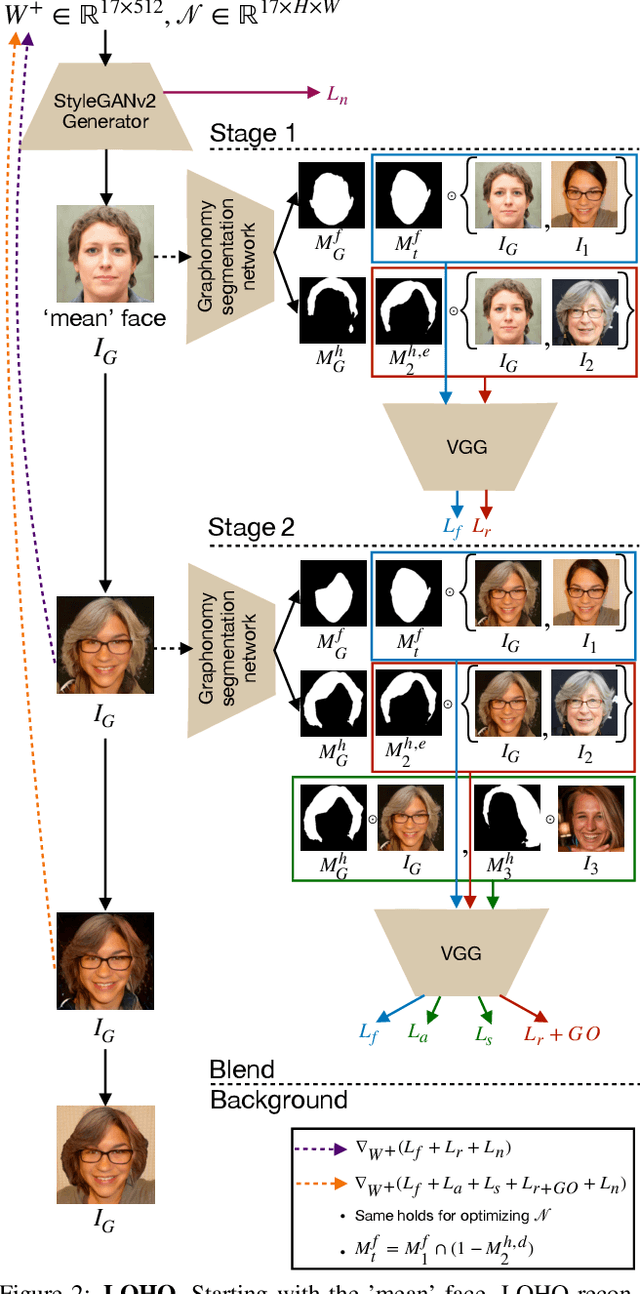


Hairstyle transfer is challenging due to hair structure differences in the source and target hair. Therefore, we propose Latent Optimization of Hairstyles via Orthogonalization (LOHO), an optimization-based approach using GAN inversion to infill missing hair structure details in latent space during hairstyle transfer. Our approach decomposes hair into three attributes: perceptual structure, appearance, and style, and includes tailored losses to model each of these attributes independently. Furthermore, we propose two-stage optimization and gradient orthogonalization to enable disentangled latent space optimization of our hair attributes. Using LOHO for latent space manipulation, users can synthesize novel photorealistic images by manipulating hair attributes either individually or jointly, transferring the desired attributes from reference hairstyles. LOHO achieves a superior FID compared with the current state-of-the-art (SOTA) for hairstyle transfer. Additionally, LOHO preserves the subject's identity comparably well according to PSNR and SSIM when compared to SOTA image embedding pipelines. Code is available at https://github.com/dukebw/LOHO.
SSTVOS: Sparse Spatiotemporal Transformers for Video Object Segmentation
Jan 21, 2021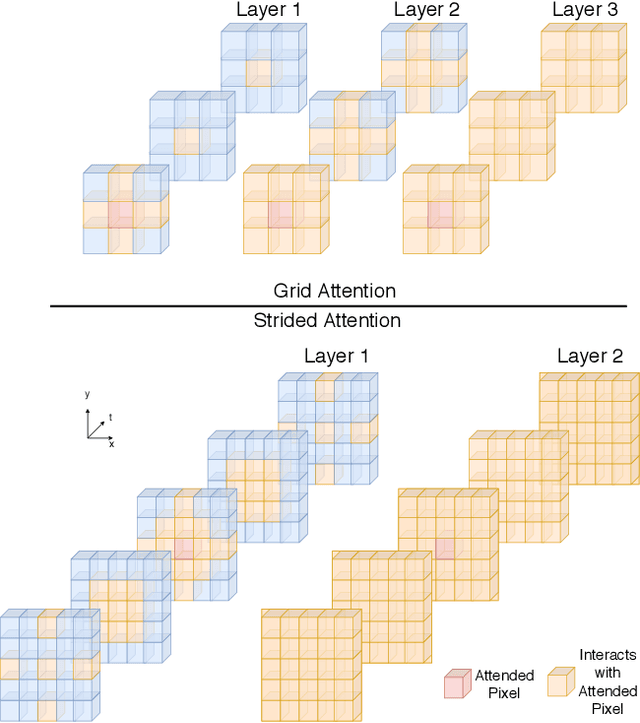
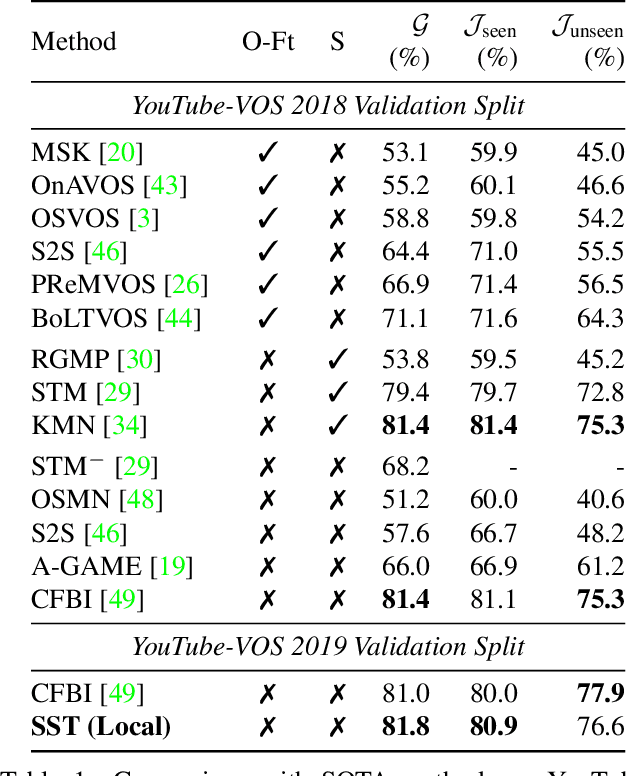
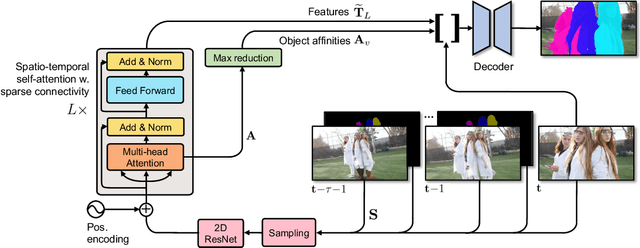
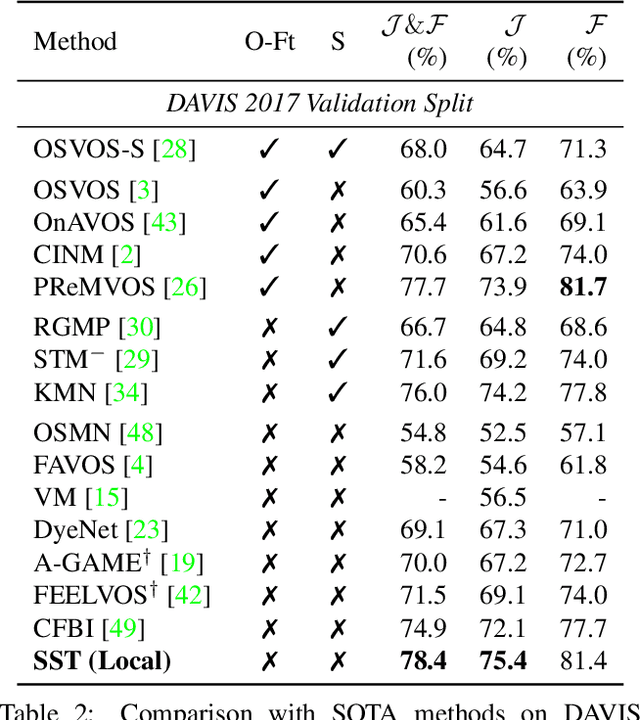
In this paper we introduce a Transformer-based approach to video object segmentation (VOS). To address compounding error and scalability issues of prior work, we propose a scalable, end-to-end method for VOS called Sparse Spatiotemporal Transformers (SST). SST extracts per-pixel representations for each object in a video using sparse attention over spatiotemporal features. Our attention-based formulation for VOS allows a model to learn to attend over a history of multiple frames and provides suitable inductive bias for performing correspondence-like computations necessary for solving motion segmentation. We demonstrate the effectiveness of attention-based over recurrent networks in the spatiotemporal domain. Our method achieves competitive results on YouTube-VOS and DAVIS 2017 with improved scalability and robustness to occlusions compared with the state of the art.
Building LEGO Using Deep Generative Models of Graphs
Dec 21, 2020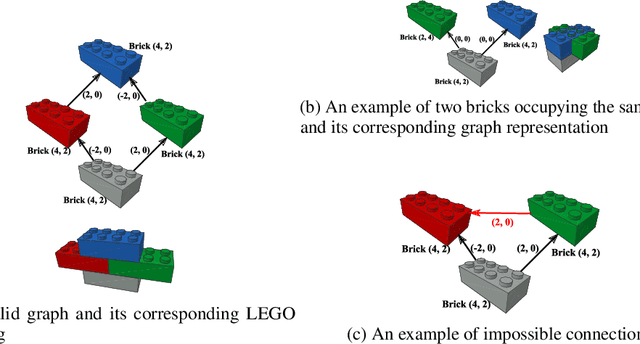
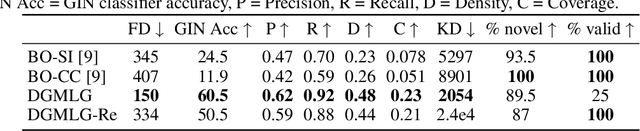
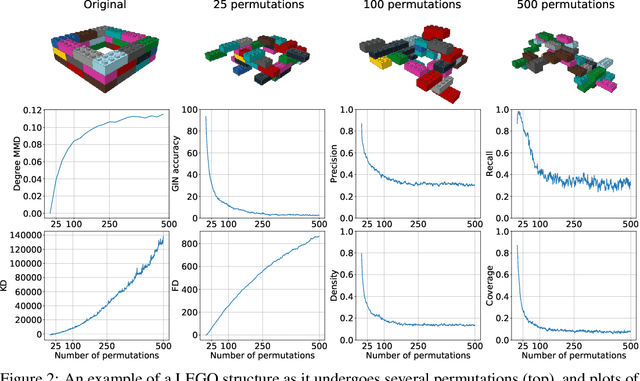
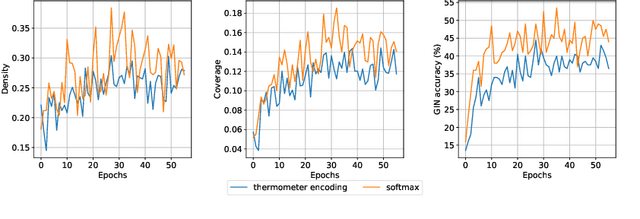
Generative models are now used to create a variety of high-quality digital artifacts. Yet their use in designing physical objects has received far less attention. In this paper, we advocate for the construction toy, LEGO, as a platform for developing generative models of sequential assembly. We develop a generative model based on graph-structured neural networks that can learn from human-built structures and produce visually compelling designs. Our code is released at: https://github.com/uoguelph-mlrg/GenerativeLEGO.
Evaluating Curriculum Learning Strategies in Neural Combinatorial Optimization
Nov 12, 2020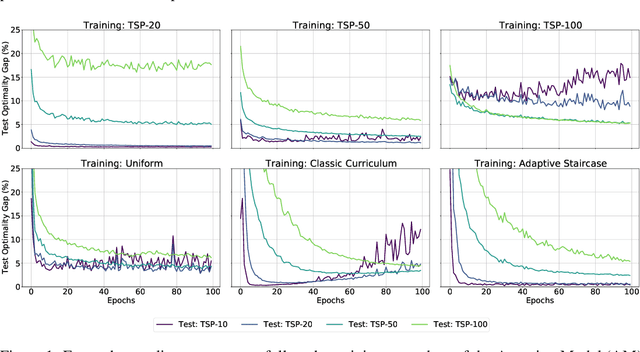
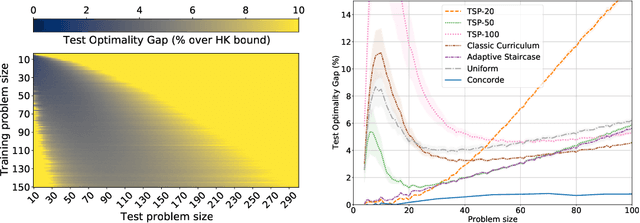
Neural combinatorial optimization (NCO) aims at designing problem-independent and efficient neural network-based strategies for solving combinatorial problems. The field recently experienced growth by successfully adapting architectures originally designed for machine translation. Even though the results are promising, a large gap still exists between NCO models and classic deterministic solvers, both in terms of accuracy and efficiency. One of the drawbacks of current approaches is the inefficiency of training on multiple problem sizes. Curriculum learning strategies have been shown helpful in increasing performance in the multi-task setting. In this work, we focus on designing a curriculum learning-based training procedure that can help existing architectures achieve competitive performance on a large range of problem sizes simultaneously. We provide a systematic investigation of several training procedures and use the insights gained to motivate application of a psychologically-inspired approach to improve upon the classic curriculum method.
Identifying and interpreting tuning dimensions in deep networks
Nov 05, 2020



In neuroscience, a tuning dimension is a stimulus attribute that accounts for much of the activation variance of a group of neurons. These are commonly used to decipher the responses of such groups. While researchers have attempted to manually identify an analogue to these tuning dimensions in deep neural networks, we are unaware of an automatic way to discover them. This work contributes an unsupervised framework for identifying and interpreting "tuning dimensions" in deep networks. Our method correctly identifies the tuning dimensions of a synthetic Gabor filter bank and tuning dimensions of the first two layers of InceptionV1 trained on ImageNet.
Instance Selection for GANs
Jul 30, 2020
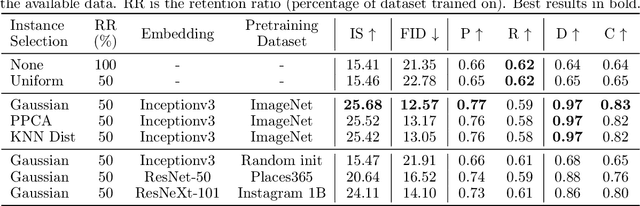
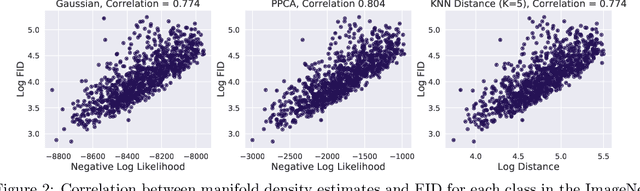
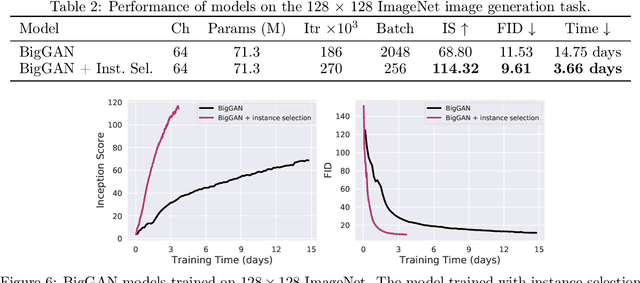
Recent advances in Generative Adversarial Networks (GANs) have led to their widespread adoption for the purposes of generating high quality synthetic imagery. While capable of generating photo-realistic images, these models often produce unrealistic samples which fall outside of the data manifold. Several recently proposed techniques attempt to avoid spurious samples, either by rejecting them after generation, or by truncating the model's latent space. While effective, these methods are inefficient, as large portions of model capacity are dedicated towards representing samples that will ultimately go unused. In this work we propose a novel approach to improve sample quality: altering the training dataset via instance selection before model training has taken place. To this end, we embed data points into a perceptual feature space and use a simple density model to remove low density regions from the data manifold. By refining the empirical data distribution before training we redirect model capacity towards high-density regions, which ultimately improves sample fidelity. We evaluate our method by training a Self-Attention GAN on ImageNet at 64x64 resolution, where we outperform the current state-of-the-art models on this task while using 1/2 of the parameters. We also highlight training time savings by training a BigGAN on ImageNet at 128x128 resolution, achieving a 66% increase in Inception Score and a 16% improvement in FID over the baseline model with less than 1/4 the training time.