 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast convolutional neural networks on FPGAs with hls4ml
Jan 13, 2021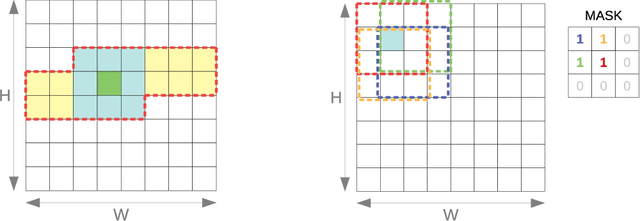

We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with large convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate how to achieve inference latency of $5\,\mu$s using convolutional architectures, while preserving state-of-the-art model performance. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be reduced by over 90% while maintaining the original model accuracy.
Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics
Aug 08, 2020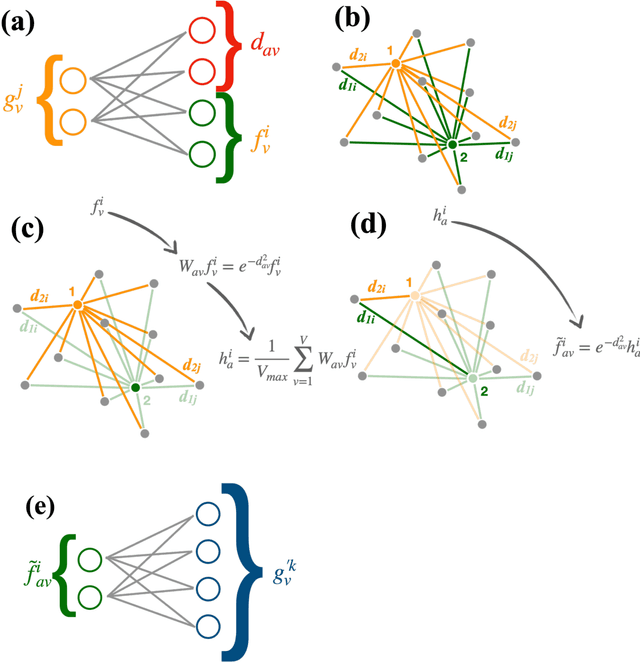


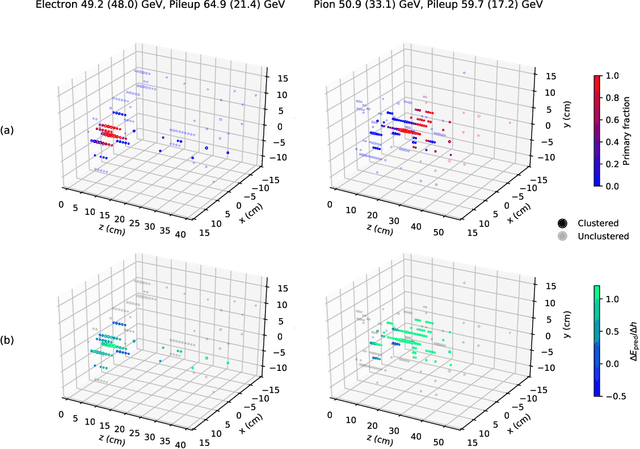
Graph neural networks have been shown to achieve excellent performance for several crucial tasks in particle physics, such as charged particle tracking, jet tagging, and clustering. An important domain for the application of these networks is the FGPA-based first layer of real-time data filtering at the CERN Large Hadron Collider, which has strict latency and resource constraints. We discuss how to design distance-weighted graph networks that can be executed with a latency of less than 1$\mu\mathrm{s}$ on an FPGA. To do so, we consider a representative task associated to particle reconstruction and identification in a next-generation calorimeter operating at a particle collider. We use a graph network architecture developed for such purposes, and apply additional simplifications to match the computing constraints of Level-1 trigger systems, including weight quantization. Using the $\mathtt{hls4ml}$ library, we convert the compressed models into firmware to be implemented on an FPGA. Performance of the synthesized models is presented both in terms of inference accuracy and resource usage.
Compressing deep neural networks on FPGAs to binary and ternary precision with HLS4ML
Mar 11, 2020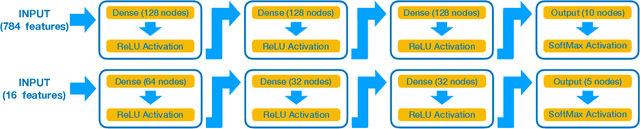
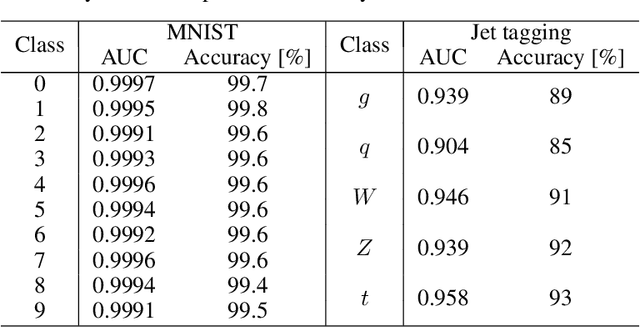
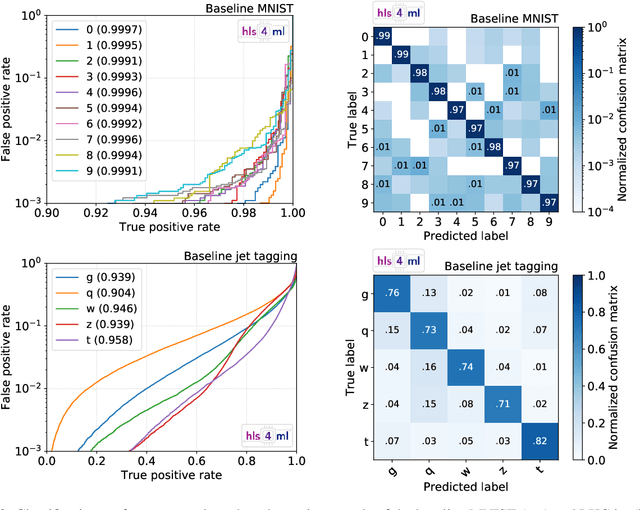

We present the implementation of binary and ternary neural networks in the hls4ml library, designed to automatically convert deep neural network models to digital circuits with FPGA firmware. Starting from benchmark models trained with floating point precision, we investigate different strategies to reduce the network's resource consumption by reducing the numerical precision of the network parameters to binary or ternary. We discuss the trade-off between model accuracy and resource consumption. In addition, we show how to balance between latency and accuracy by retaining full precision on a selected subset of network components. As an example, we consider two multiclass classification tasks: handwritten digit recognition with the MNIST data set and jet identification with simulated proton-proton collisions at the CERN Large Hadron Collider. The binary and ternary implementation has similar performance to the higher precision implementation while using drastically fewer FPGA resources.
Fast inference of Boosted Decision Trees in FPGAs for particle physics
Feb 19, 2020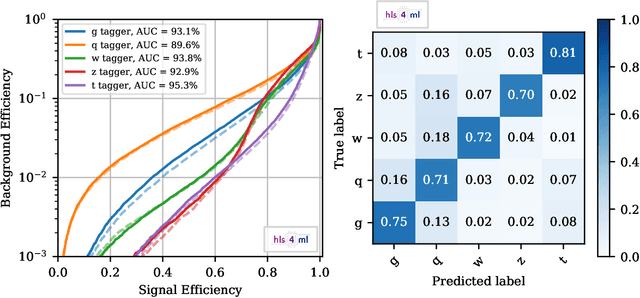

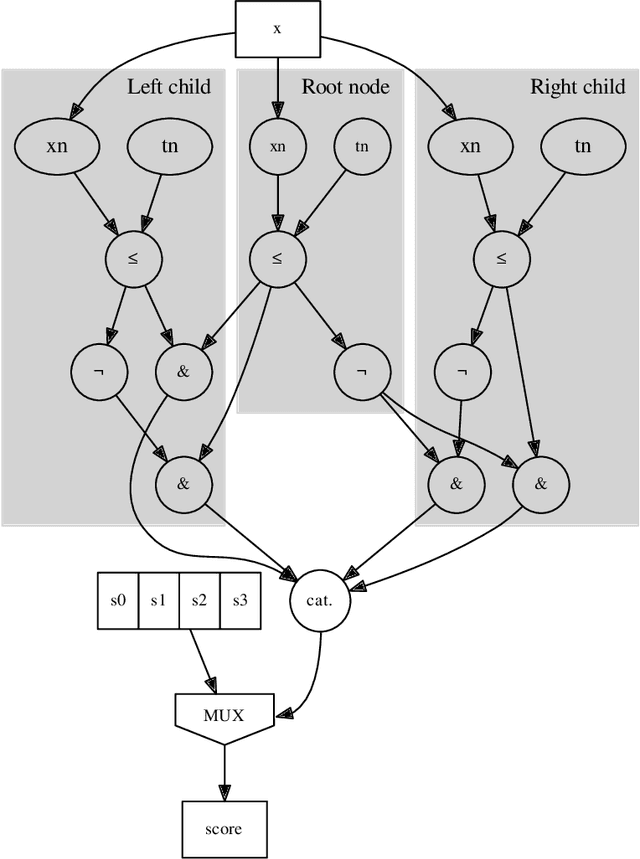
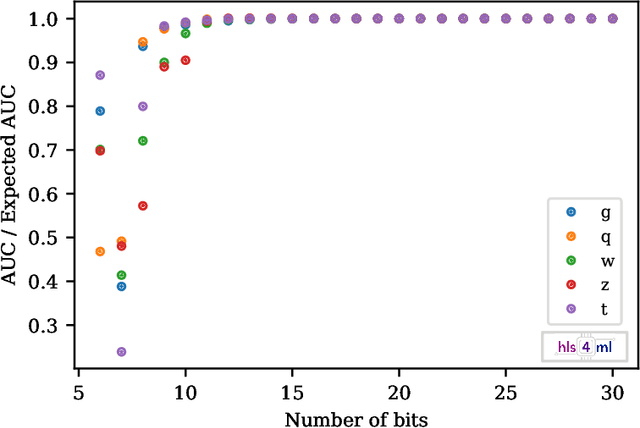
We describe the implementation of Boosted Decision Trees in the hls4ml library, which allows the translation of a trained model into FPGA firmware through an automated conversion process. Thanks to its fully on-chip implementation, hls4ml performs inference of Boosted Decision Tree models with extremely low latency. With a typical latency less than 100 ns, this solution is suitable for FPGA-based real-time processing, such as in the Level-1 Trigger system of a collider experiment. These developments open up prospects for physicists to deploy BDTs in FPGAs for identifying the origin of jets, better reconstructing the energies of muons, and enabling better selection of rare signal processes.