 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Linear-Experts for Long-term Time Series Forecasting
Dec 11, 2023



Long-term time series forecasting (LTSF) aims to predict future values of a time series given the past values. The current state-of-the-art (SOTA) on this problem is attained in some cases by linear-centric models, which primarily feature a linear mapping layer. However, due to their inherent simplicity, they are not able to adapt their prediction rules to periodic changes in time series patterns. To address this challenge, we propose a Mixture-of-Experts-style augmentation for linear-centric models and propose Mixture-of-Linear-Experts (MoLE). Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE reduces forecasting error of linear-centric models, including DLinear, RLinear, and RMLP, in over 78% of the datasets and settings we evaluated. By using MoLE existing linear-centric models can achieve SOTA LTSF results in 68% of the experiments that PatchTST reports and we compare to, whereas existing single-head linear-centric models achieve SOTA results in only 25% of cases. Additionally, MoLE models achieve SOTA in all settings for the newly released Weather2K datasets.
Pretrained deep models outperform GBDTs in Learning-To-Rank under label scarcity
Jul 31, 2023



While deep learning (DL) models are state-of-the-art in text and image domains, they have not yet consistently outperformed Gradient Boosted Decision Trees (GBDTs) on tabular Learning-To-Rank (LTR) problems. Most of the recent performance gains attained by DL models in text and image tasks have used unsupervised pretraining, which exploits orders of magnitude more unlabeled data than labeled data. To the best of our knowledge, unsupervised pretraining has not been applied to the LTR problem, which often produces vast amounts of unlabeled data. In this work, we study whether unsupervised pretraining can improve LTR performance over GBDTs and other non-pretrained models. Using simple design choices--including SimCLR-Rank, our ranking-specific modification of SimCLR (an unsupervised pretraining method for images)--we produce pretrained deep learning models that soundly outperform GBDTs (and other non-pretrained models) in the case where labeled data is vastly outnumbered by unlabeled data. We also show that pretrained models also often achieve significantly better robustness than non-pretrained models (GBDTs or DL models) in ranking outlier data.
Summary Statistic Privacy in Data Sharing
Mar 03, 2023



Data sharing between different parties has become increasingly common across industry and academia. An important class of privacy concerns that arises in data sharing scenarios regards the underlying distribution of data. For example, the total traffic volume of data from a networking company can reveal the scale of its business, which may be considered a trade secret. Unfortunately, existing privacy frameworks (e.g., differential privacy, anonymization) do not adequately address such concerns. In this paper, we propose summary statistic privacy, a framework for analyzing and protecting these summary statistic privacy concerns. We propose a class of quantization mechanisms that can be tailored to various data distributions and statistical secrets, and analyze their privacy-distortion trade-offs under our framework. We prove corresponding lower bounds on the privacy-utility tradeoff, which match the tradeoffs of the quantization mechanism under certain regimes, up to small constant factors. Finally, we demonstrate that the proposed quantization mechanisms achieve better privacy-distortion tradeoffs than alternative privacy mechanisms on real-world datasets.
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023



In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
On the Privacy Properties of GAN-generated Samples
Jun 03, 2022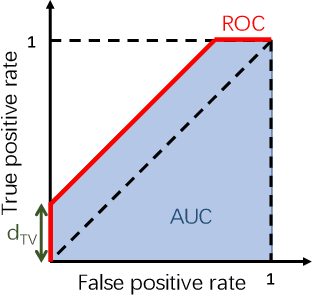
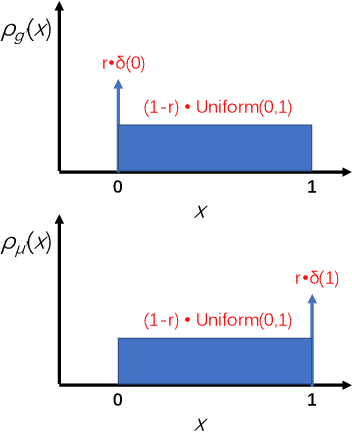
The privacy implications of generative adversarial networks (GANs) are a topic of great interest, leading to several recent algorithms for training GANs with privacy guarantees. By drawing connections to the generalization properties of GANs, we prove that under some assumptions, GAN-generated samples inherently satisfy some (weak) privacy guarantees. First, we show that if a GAN is trained on m samples and used to generate n samples, the generated samples are (epsilon, delta)-differentially-private for (epsilon, delta) pairs where delta scales as O(n/m). We show that under some special conditions, this upper bound is tight. Next, we study the robustness of GAN-generated samples to membership inference attacks. We model membership inference as a hypothesis test in which the adversary must determine whether a given sample was drawn from the training dataset or from the underlying data distribution. We show that this adversary can achieve an area under the ROC curve that scales no better than O(m^{-1/4}).
Towards a Defense against Backdoor Attacks in Continual Federated Learning
May 28, 2022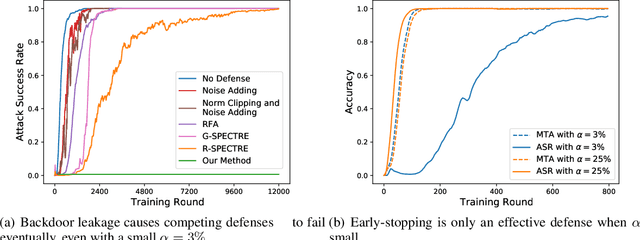

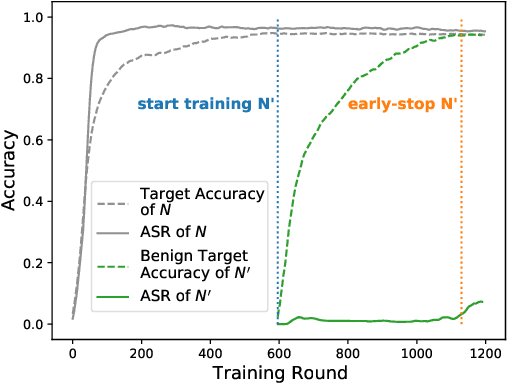

Backdoor attacks are a major concern in federated learning (FL) pipelines where training data is sourced from untrusted clients over long periods of time (i.e., continual learning). Preventing such attacks is difficult because defenders in FL do not have access to raw training data. Moreover, in a phenomenon we call backdoor leakage, models trained continuously eventually suffer from backdoors due to cumulative errors in backdoor defense mechanisms. We propose a novel framework for defending against backdoor attacks in the federated continual learning setting. Our framework trains two models in parallel: a backbone model and a shadow model. The backbone is trained without any defense mechanism to obtain good performance on the main task. The shadow model combines recent ideas from robust covariance estimation-based filters with early-stopping to control the attack success rate even as the data distribution changes. We provide theoretical motivation for this design and show experimentally that our framework significantly improves upon existing defenses against backdoor attacks.
RareGAN: Generating Samples for Rare Classes
Mar 20, 2022
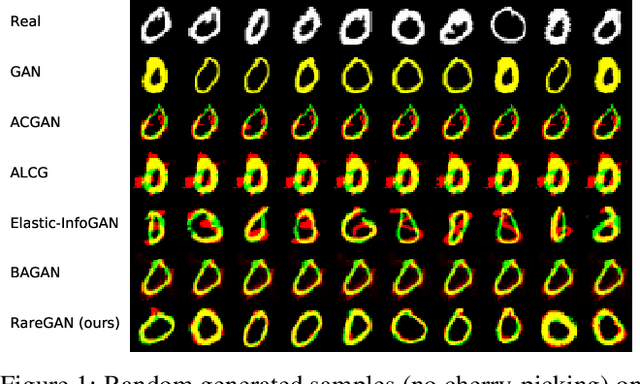

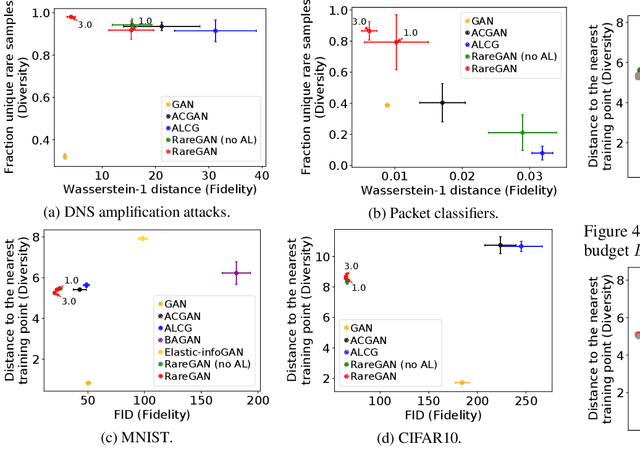
We study the problem of learning generative adversarial networks (GANs) for a rare class of an unlabeled dataset subject to a labeling budget. This problem is motivated from practical applications in domains including security (e.g., synthesizing packets for DNS amplification attacks), systems and networking (e.g., synthesizing workloads that trigger high resource usage), and machine learning (e.g., generating images from a rare class). Existing approaches are unsuitable, either requiring fully-labeled datasets or sacrificing the fidelity of the rare class for that of the common classes. We propose RareGAN, a novel synthesis of three key ideas: (1) extending conditional GANs to use labelled and unlabelled data for better generalization; (2) an active learning approach that requests the most useful labels; and (3) a weighted loss function to favor learning the rare class. We show that RareGAN achieves a better fidelity-diversity tradeoff on the rare class than prior work across different applications, budgets, rare class fractions, GAN losses, and architectures.
Reducing the Communication Cost of Federated Learning through Multistage Optimization
Aug 16, 2021
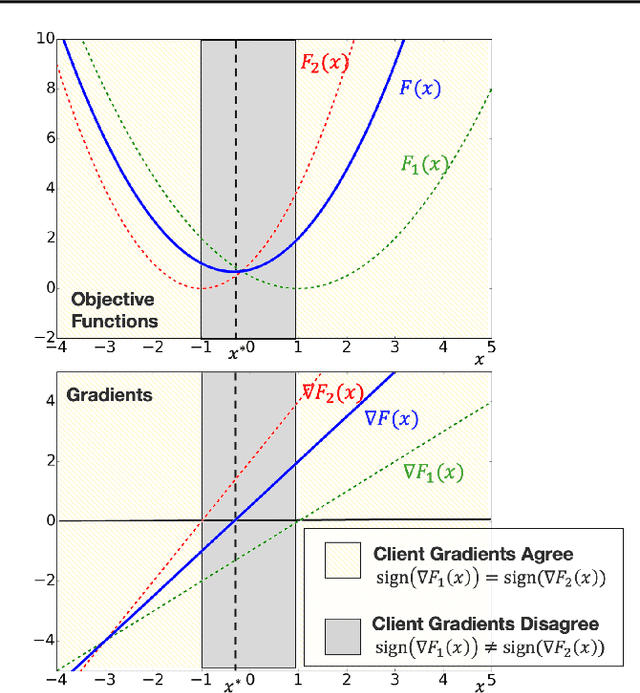

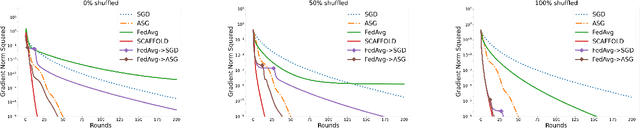
A central question in federated learning (FL) is how to design optimization algorithms that minimize the communication cost of training a model over heterogeneous data distributed across many clients. A popular technique for reducing communication is the use of local steps, where clients take multiple optimization steps over local data before communicating with the server (e.g., FedAvg, SCAFFOLD). This contrasts with centralized methods, where clients take one optimization step per communication round (e.g., Minibatch SGD). A recent lower bound on the communication complexity of first-order methods shows that centralized methods are optimal over highly-heterogeneous data, whereas local methods are optimal over purely homogeneous data [Woodworth et al., 2020]. For intermediate heterogeneity levels, no algorithm is known to match the lower bound. In this paper, we propose a multistage optimization scheme that nearly matches the lower bound across all heterogeneity levels. The idea is to first run a local method up to a heterogeneity-induced error floor; next, we switch to a centralized method for the remaining steps. Our analysis may help explain empirically-successful stepsize decay methods in FL [Charles et al., 2020; Reddi et al., 2020]. We demonstrate the scheme's practical utility in image classification tasks.
Abusive Language Detection in Heterogeneous Contexts: Dataset Collection and the Role of Supervised Attention
May 24, 2021
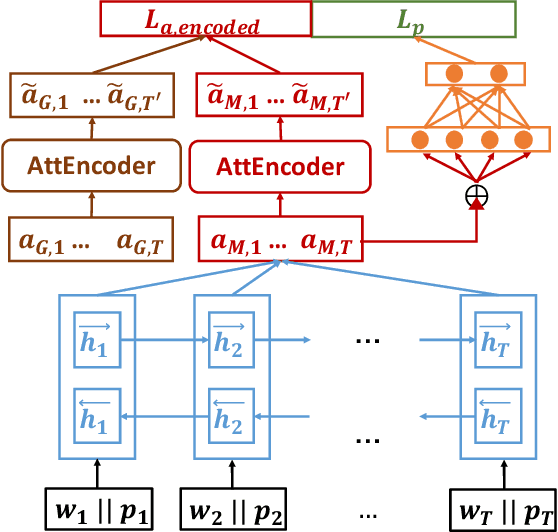
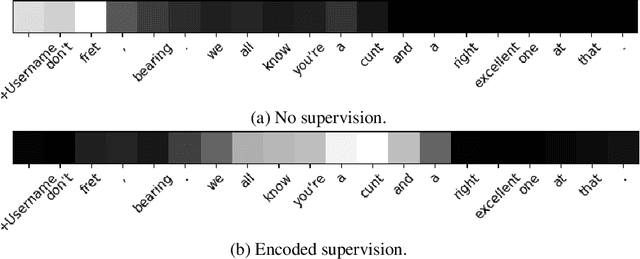

Abusive language is a massive problem in online social platforms. Existing abusive language detection techniques are particularly ill-suited to comments containing heterogeneous abusive language patterns, i.e., both abusive and non-abusive parts. This is due in part to the lack of datasets that explicitly annotate heterogeneity in abusive language. We tackle this challenge by providing an annotated dataset of abusive language in over 11,000 comments from YouTube. We account for heterogeneity in this dataset by separately annotating both the comment as a whole and the individual sentences that comprise each comment. We then propose an algorithm that uses a supervised attention mechanism to detect and categorize abusive content using multi-task learning. We empirically demonstrate the challenges of using traditional techniques on heterogeneous content and the comparative gains in performance of the proposed approach over state-of-the-art methods.
Self-Supervised Euphemism Detection and Identification for Content Moderation
Mar 31, 2021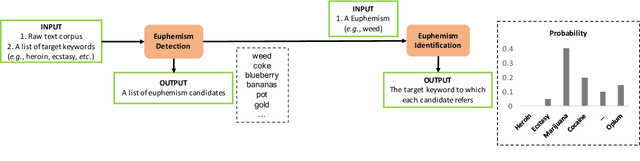
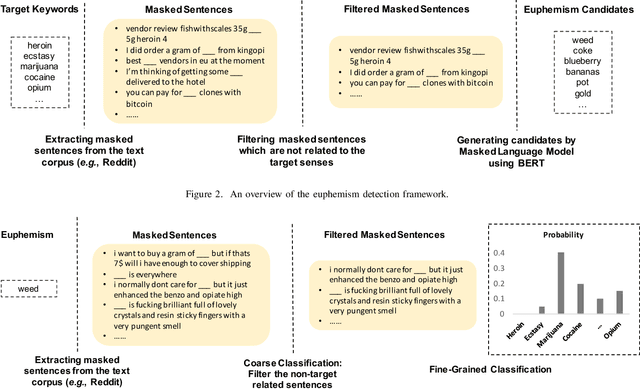
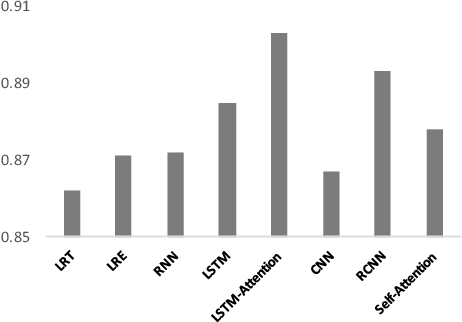
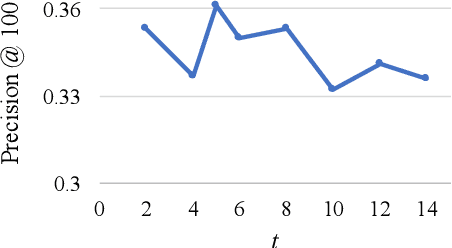
Fringe groups and organizations have a long history of using euphemisms--ordinary-sounding words with a secret meaning--to conceal what they are discussing. Nowadays, one common use of euphemisms is to evade content moderation policies enforced by social media platforms. Existing tools for enforcing policy automatically rely on keyword searches for words on a "ban list", but these are notoriously imprecise: even when limited to swearwords, they can still cause embarrassing false positives. When a commonly used ordinary word acquires a euphemistic meaning, adding it to a keyword-based ban list is hopeless: consider "pot" (storage container or marijuana?) or "heater" (household appliance or firearm?) The current generation of social media companies instead hire staff to check posts manually, but this is expensive, inhumane, and not much more effective. It is usually apparent to a human moderator that a word is being used euphemistically, but they may not know what the secret meaning is, and therefore whether the message violates policy. Also, when a euphemism is banned, the group that used it need only invent another one, leaving moderators one step behind. This paper will demonstrate unsupervised algorithms that, by analyzing words in their sentence-level context, can both detect words being used euphemistically, and identify the secret meaning of each word. Compared to the existing state of the art, which uses context-free word embeddings, our algorithm for detecting euphemisms achieves 30-400% higher detection accuracies of unlabeled euphemisms in a text corpus. Our algorithm for revealing euphemistic meanings of words is the first of its kind, as far as we are aware. In the arms race between content moderators and policy evaders, our algorithms may help shift the balance in the direction of the moderators.