 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning
Sep 29, 2023Automatic speech recognition (ASR) models are typically trained on large datasets of transcribed speech. As language evolves and new terms come into use, these models can become outdated and stale. In the context of models trained on the server but deployed on edge devices, errors may result from the mismatch between server training data and actual on-device usage. In this work, we seek to continually learn from on-device user corrections through Federated Learning (FL) to address this issue. We explore techniques to target fresh terms that the model has not previously encountered, learn long-tail words, and mitigate catastrophic forgetting. In experimental evaluations, we find that the proposed techniques improve model recognition of fresh terms, while preserving quality on the overall language distribution.
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022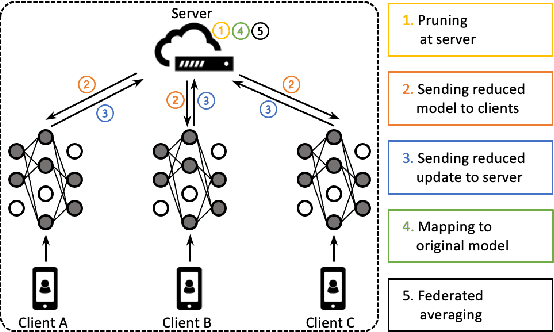
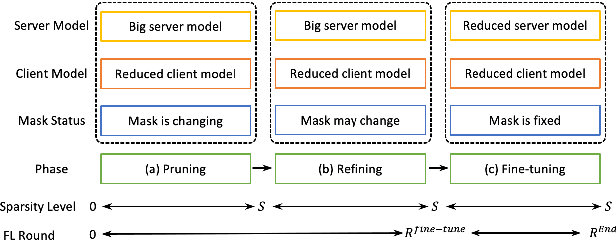
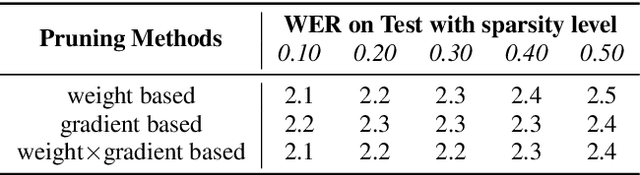
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
Online Model Compression for Federated Learning with Large Models
May 06, 2022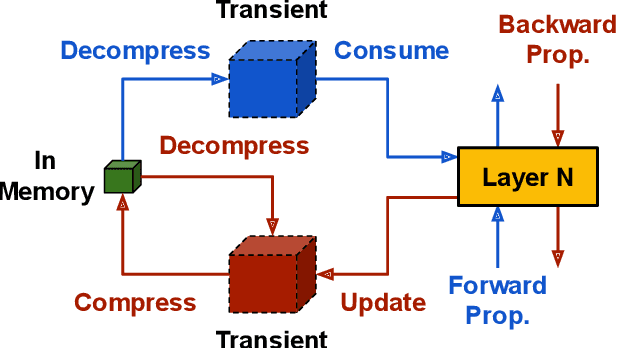
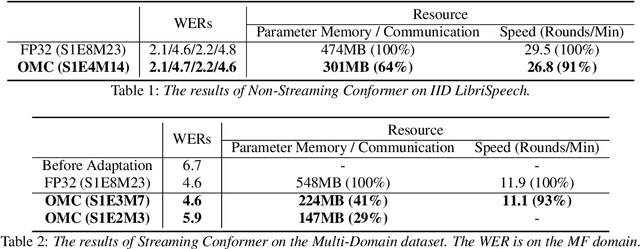
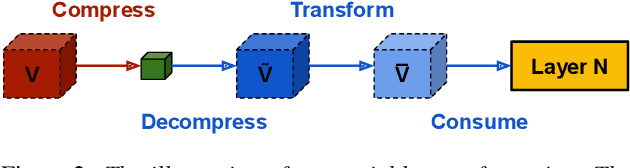
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
Partial Variable Training for Efficient On-Device Federated Learning
Oct 11, 2021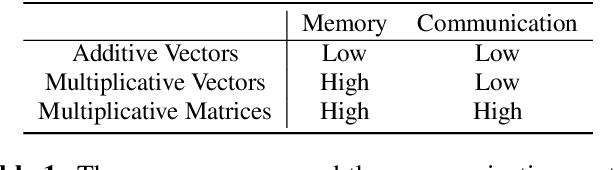
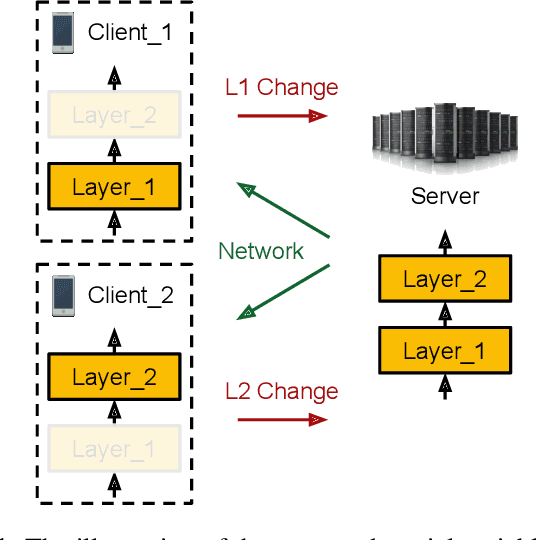
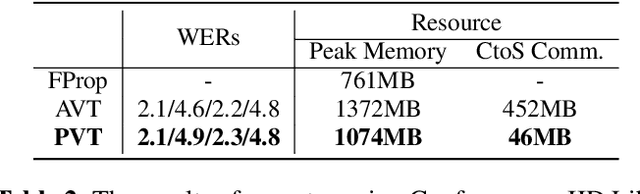
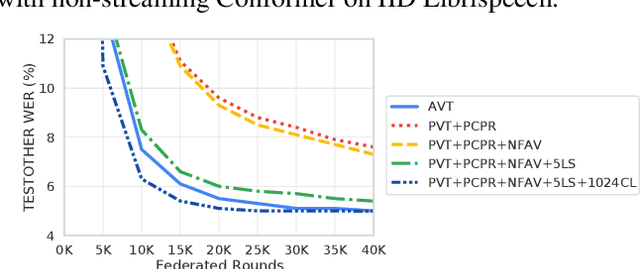
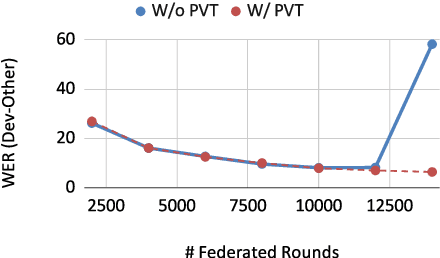
This paper aims to address the major challenges of Federated Learning (FL) on edge devices: limited memory and expensive communication. We propose a novel method, called Partial Variable Training (PVT), that only trains a small subset of variables on edge devices to reduce memory usage and communication cost. With PVT, we show that network accuracy can be maintained by utilizing more local training steps and devices, which is favorable for FL involving a large population of devices. According to our experiments on two state-of-the-art neural networks for speech recognition and two different datasets, PVT can reduce memory usage by up to 1.9$\times$ and communication cost by up to 593$\times$ while attaining comparable accuracy when compared with full network training.
Exploring Heterogeneous Characteristics of Layers in ASR Models for More Efficient Training
Oct 08, 2021

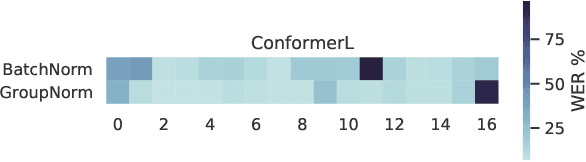
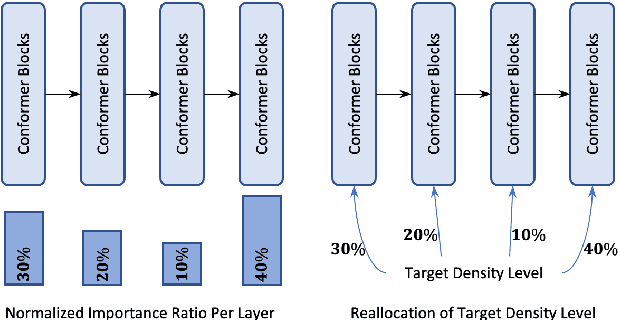
Transformer-based architectures have been the subject of research aimed at understanding their overparameterization and the non-uniform importance of their layers. Applying these approaches to Automatic Speech Recognition, we demonstrate that the state-of-the-art Conformer models generally have multiple ambient layers. We study the stability of these layers across runs and model sizes, propose that group normalization may be used without disrupting their formation, and examine their correlation with model weight updates in each layer. Finally, we apply these findings to Federated Learning in order to improve the training procedure, by targeting Federated Dropout to layers by importance. This allows us to reduce the model size optimized by clients without quality degradation, and shows potential for future exploration.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
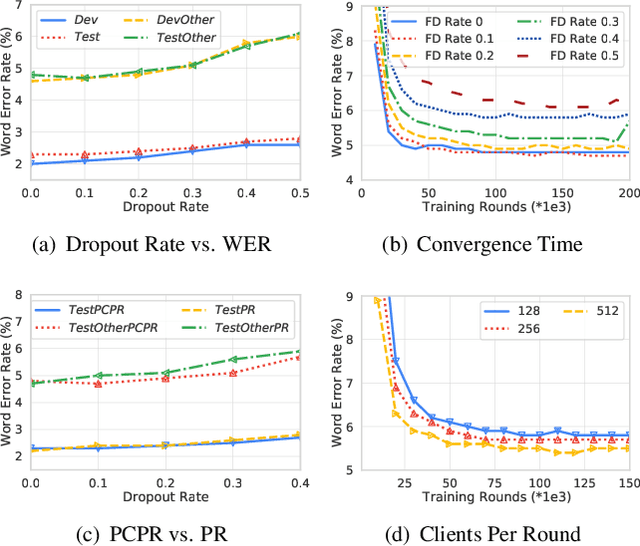

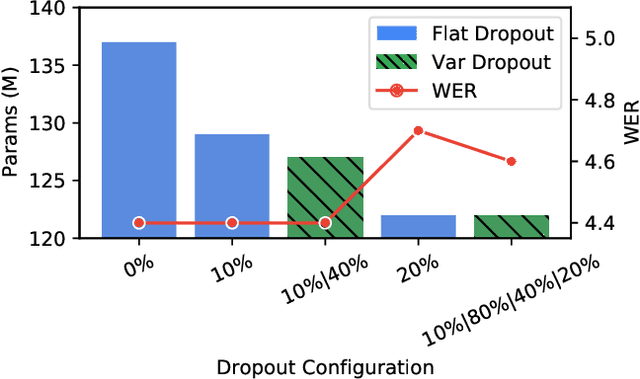
Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.
Training Speech Recognition Models with Federated Learning: A Quality/Cost Framework
Oct 29, 2020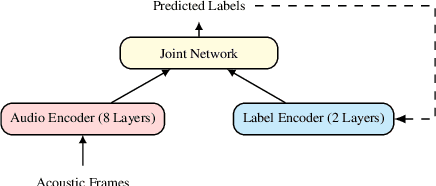
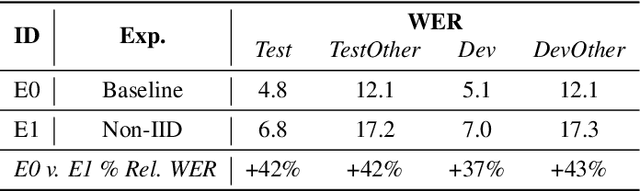
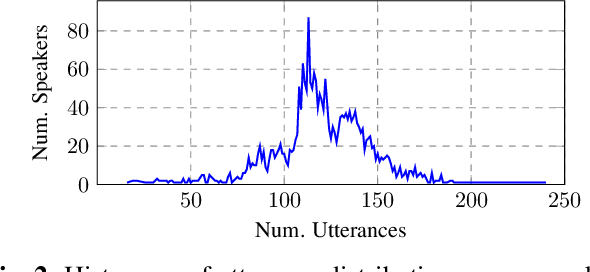
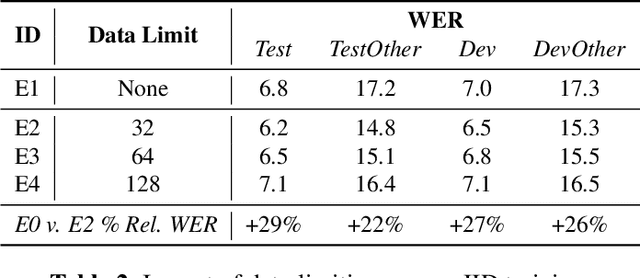
We propose using federated learning, a decentralized on-device learning paradigm, to train speech recognition models. By performing epochs of training on a per-user basis, federated learning must incur the cost of dealing with non-IID data distributions, which are expected to negatively affect the quality of the trained model. We propose a framework by which the degree of non-IID-ness can be varied, consequently illustrating a trade-off between model quality and the computational cost of federated training, which we capture through a novel metric. Finally, we demonstrate that hyper-parameter optimization and appropriate use of variational noise are sufficient to compensate for the quality impact of non-IID distributions, while decreasing the cost.
Low-rank Gradient Approximation For Memory-Efficient On-device Training of Deep Neural Network
Jan 24, 2020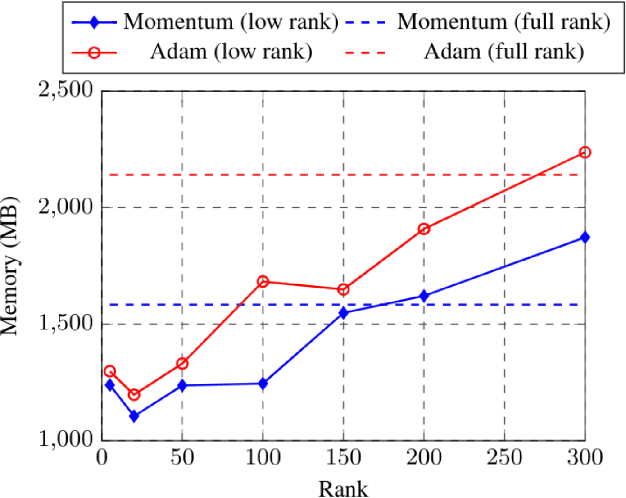
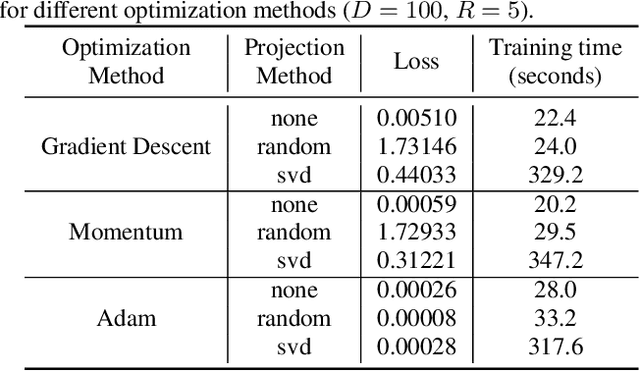
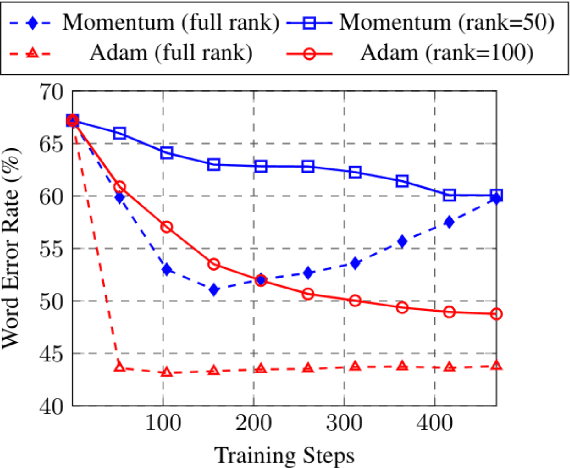
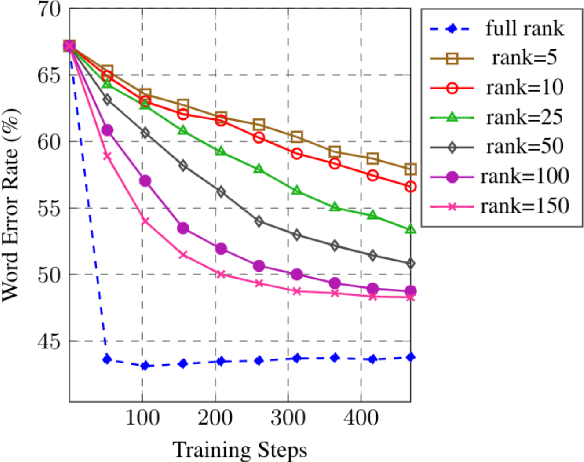
Training machine learning models on mobile devices has the potential of improving both privacy and accuracy of the models. However, one of the major obstacles to achieving this goal is the memory limitation of mobile devices. Reducing training memory enables models with high-dimensional weight matrices, like automatic speech recognition (ASR) models, to be trained on-device. In this paper, we propose approximating the gradient matrices of deep neural networks using a low-rank parameterization as an avenue to save training memory. The low-rank gradient approximation enables more advanced, memory-intensive optimization techniques to be run on device. Our experimental results show that we can reduce the training memory by about 33.0% for Adam optimization. It uses comparable memory to momentum optimization and achieves a 4.5% relative lower word error rate on an ASR personalization task.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019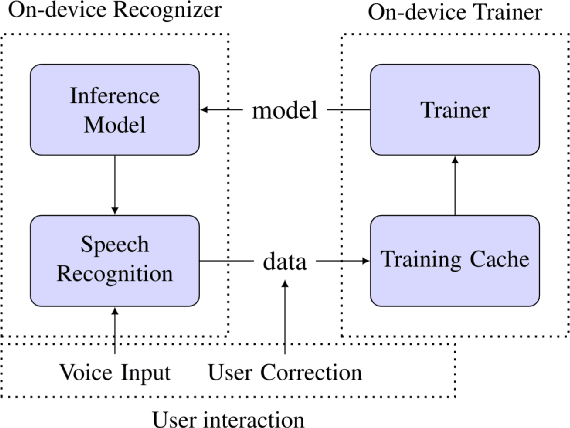
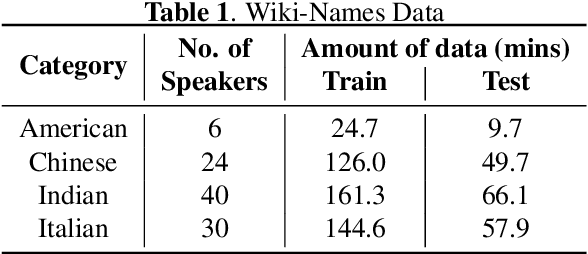
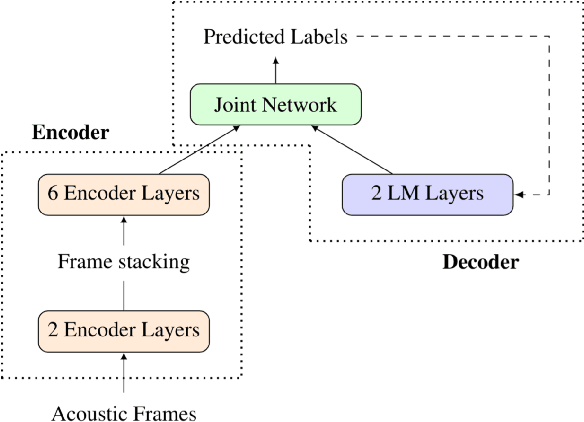
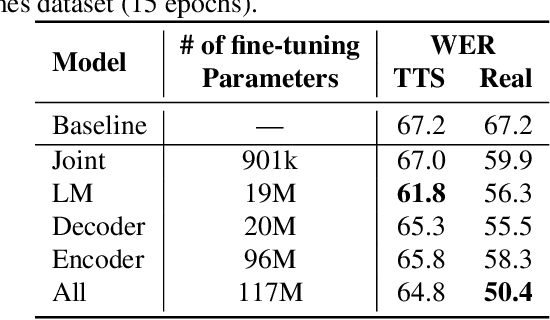
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.