 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Simulation-Based Inference with Balanced Neural Ratio Estimation
Aug 29, 2022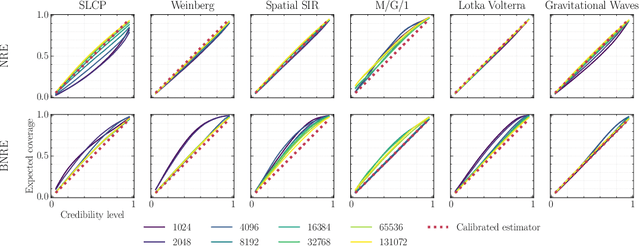
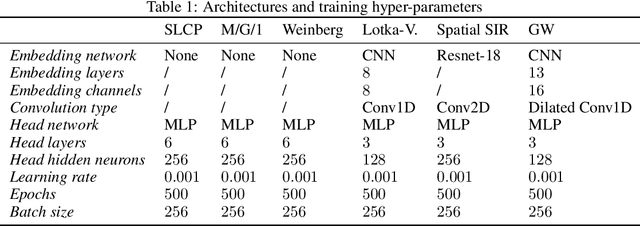
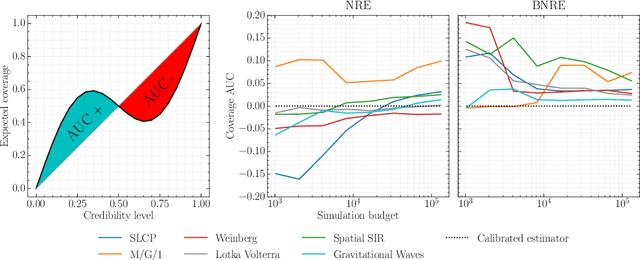
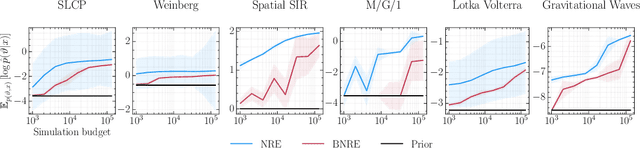
Modern approaches for simulation-based inference rely upon deep learning surrogates to enable approximate inference with computer simulators. In practice, the estimated posteriors' computational faithfulness is, however, rarely guaranteed. For example, Hermans et al. (2021) show that current simulation-based inference algorithms can produce posteriors that are overconfident, hence risking false inferences. In this work, we introduce Balanced Neural Ratio Estimation (BNRE), a variation of the NRE algorithm designed to produce posterior approximations that tend to be more conservative, hence improving their reliability, while sharing the same Bayes optimal solution. We achieve this by enforcing a balancing condition that increases the quantified uncertainty in small simulation budget regimes while still converging to the exact posterior as the budget increases. We provide theoretical arguments showing that BNRE tends to produce posterior surrogates that are more conservative than NRE's. We evaluate BNRE on a wide variety of tasks and show that it produces conservative posterior surrogates on all tested benchmarks and simulation budgets. Finally, we emphasize that BNRE is straightforward to implement over NRE and does not introduce any computational overhead.
Robust Hybrid Learning With Expert Augmentation
Feb 09, 2022



Hybrid modelling reduces the misspecification of expert models by combining them with machine learning (ML) components learned from data. Like for many ML algorithms, hybrid model performance guarantees are limited to the training distribution. Leveraging the insight that the expert model is usually valid even outside the training domain, we overcome this limitation by introducing a hybrid data augmentation strategy termed \textit{expert augmentation}. Based on a probabilistic formalization of hybrid modelling, we show why expert augmentation improves generalization. Finally, we validate the practical benefits of augmented hybrid models on a set of controlled experiments, modelling dynamical systems described by ordinary and partial differential equations.
SAE: Sequential Anchored Ensembles
Dec 30, 2021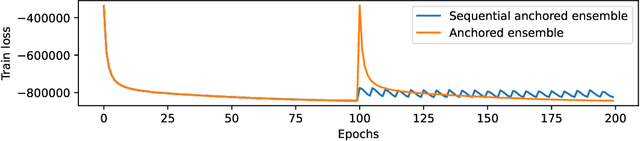
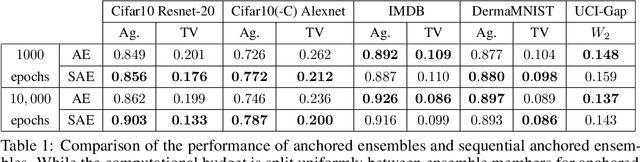
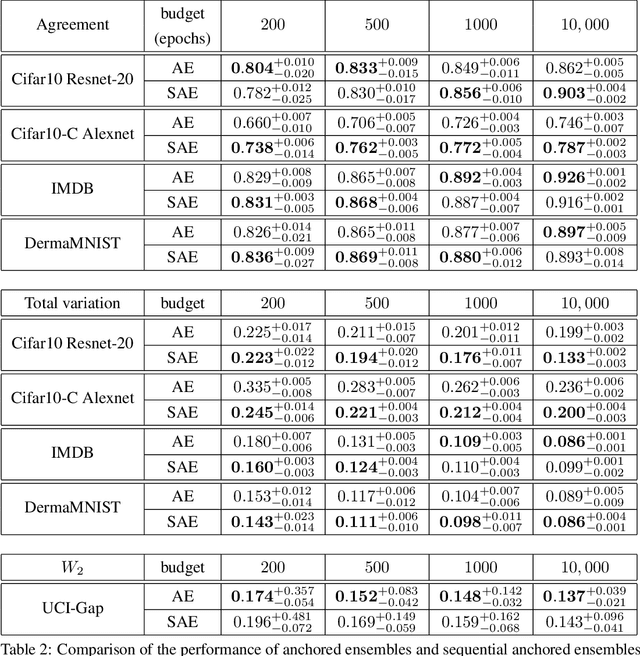
Computing the Bayesian posterior of a neural network is a challenging task due to the high-dimensionality of the parameter space. Anchored ensembles approximate the posterior by training an ensemble of neural networks on anchored losses designed for the optima to follow the Bayesian posterior. Training an ensemble, however, becomes computationally expensive as its number of members grows since the full training procedure is repeated for each member. In this note, we present Sequential Anchored Ensembles (SAE), a lightweight alternative to anchored ensembles. Instead of training each member of the ensemble from scratch, the members are trained sequentially on losses sampled with high auto-correlation, hence enabling fast convergence of the neural networks and efficient approximation of the Bayesian posterior. SAE outperform anchored ensembles, for a given computational budget, on some benchmarks while showing comparable performance on the others and achieved 2nd and 3rd place in the light and extended tracks of the NeurIPS 2021 Approximate Inference in Bayesian Deep Learning competition.
From global to local MDI variable importances for random forests and when they are Shapley values
Nov 03, 2021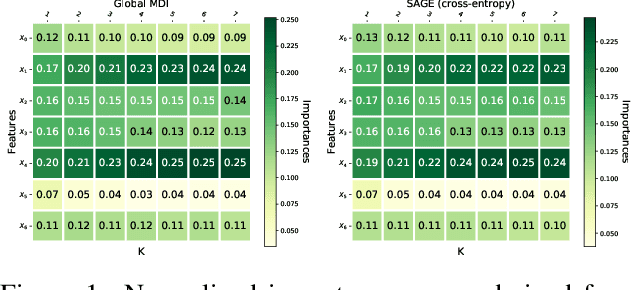
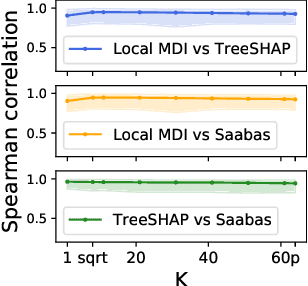

Random forests have been widely used for their ability to provide so-called importance measures, which give insight at a global (per dataset) level on the relevance of input variables to predict a certain output. On the other hand, methods based on Shapley values have been introduced to refine the analysis of feature relevance in tree-based models to a local (per instance) level. In this context, we first show that the global Mean Decrease of Impurity (MDI) variable importance scores correspond to Shapley values under some conditions. Then, we derive a local MDI importance measure of variable relevance, which has a very natural connection with the global MDI measure and can be related to a new notion of local feature relevance. We further link local MDI importances with Shapley values and discuss them in the light of related measures from the literature. The measures are illustrated through experiments on several classification and regression problems.
Averting A Crisis In Simulation-Based Inference
Oct 14, 2021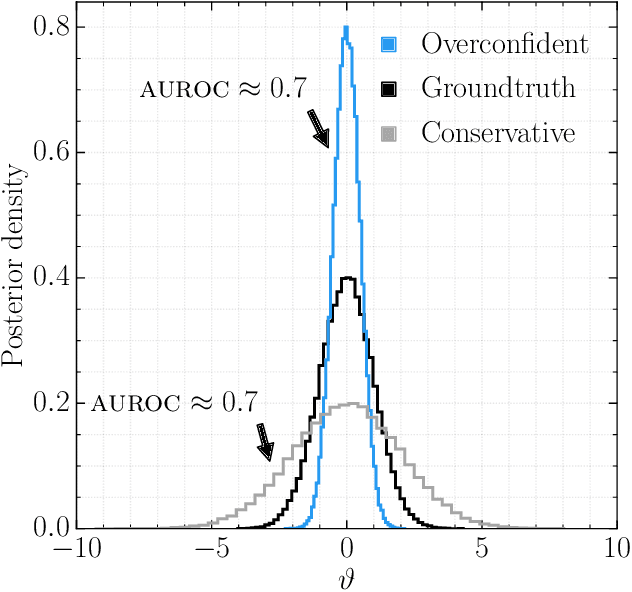
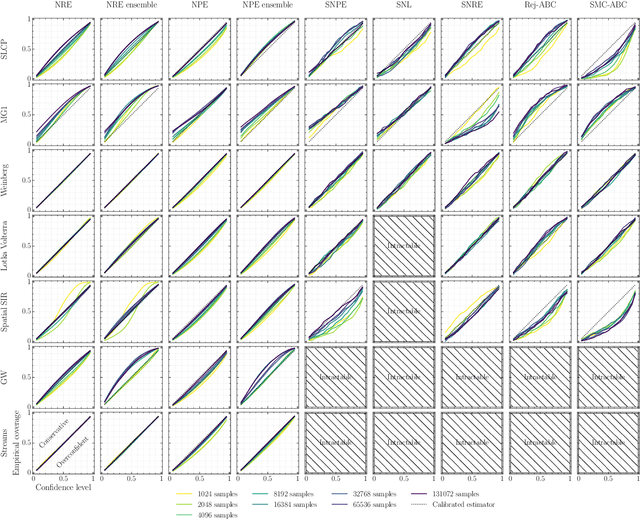
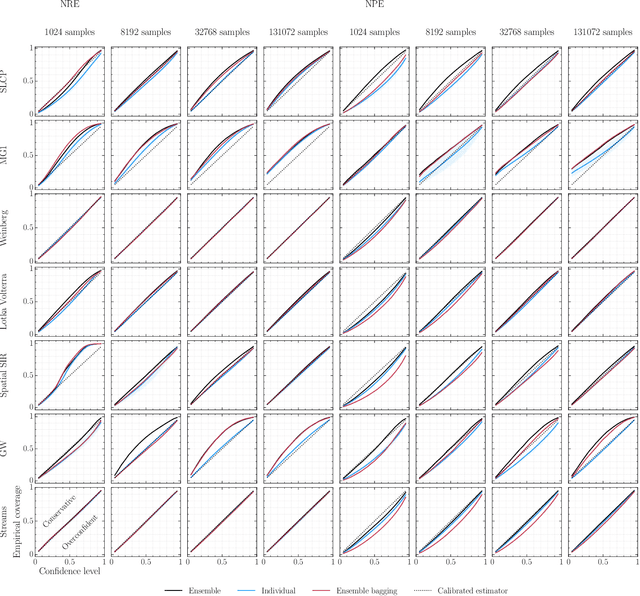
We present extensive empirical evidence showing that current Bayesian simulation-based inference algorithms are inadequate for the falsificationist methodology of scientific inquiry. Our results collected through months of experimental computations show that all benchmarked algorithms -- (S)NPE, (S)NRE, SNL and variants of ABC -- may produce overconfident posterior approximations, which makes them demonstrably unreliable and dangerous if one's scientific goal is to constrain parameters of interest. We believe that failing to address this issue will lead to a well-founded trust crisis in simulation-based inference. For this reason, we argue that research efforts should now consider theoretical and methodological developments of conservative approximate inference algorithms and present research directions towards this objective. In this regard, we show empirical evidence that ensembles are consistently more reliable.
Arbitrary Marginal Neural Ratio Estimation for Simulation-based Inference
Oct 01, 2021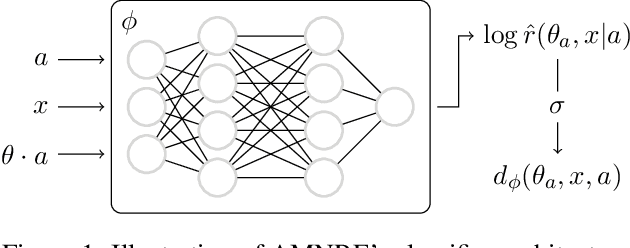

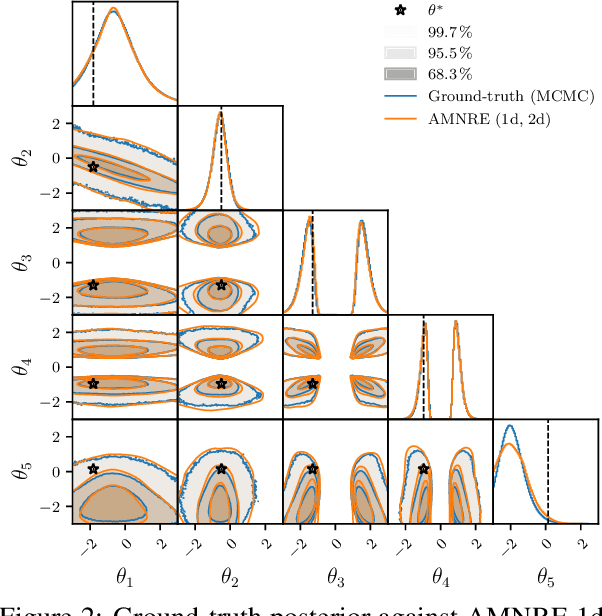

In many areas of science, complex phenomena are modeled by stochastic parametric simulators, often featuring high-dimensional parameter spaces and intractable likelihoods. In this context, performing Bayesian inference can be challenging. In this work, we present a novel method that enables amortized inference over arbitrary subsets of the parameters, without resorting to numerical integration, which makes interpretation of the posterior more convenient. Our method is efficient and can be implemented with arbitrary neural network architectures. We demonstrate the applicability of the method on parameter inference of binary black hole systems from gravitational waves observations.
Simulation-based Bayesian inference for multi-fingered robotic grasping
Sep 29, 2021

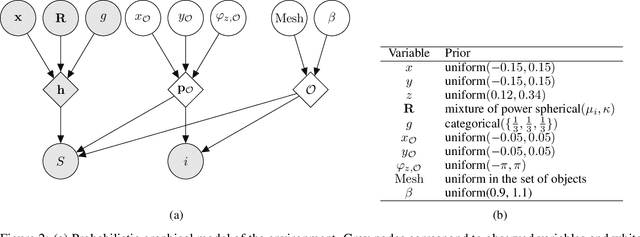
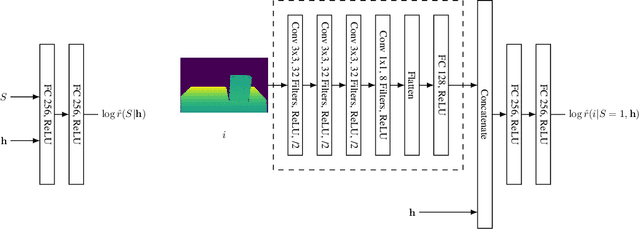
Multi-fingered robotic grasping is an undeniable stepping stone to universal picking and dexterous manipulation. Yet, multi-fingered grippers remain challenging to control because of their rich nonsmooth contact dynamics or because of sensor noise. In this work, we aim to plan hand configurations by performing Bayesian posterior inference through the full stochastic forward simulation of the robot in its environment, hence robustly accounting for many of the uncertainties in the system. While previous methods either relied on simplified surrogates of the likelihood function or attempted to learn to directly predict maximum likelihood estimates, we bring a novel simulation-based approach for full Bayesian inference based on a deep neural network surrogate of the likelihood-to-evidence ratio. Hand configurations are found by directly optimizing through the resulting amortized and differentiable expression for the posterior. The geometry of the configuration space is accounted for by proposing a Riemannian manifold optimization procedure through the neural posterior. Simulation and physical benchmarks demonstrate the high success rate of the procedure.
Truncated Marginal Neural Ratio Estimation
Jul 02, 2021
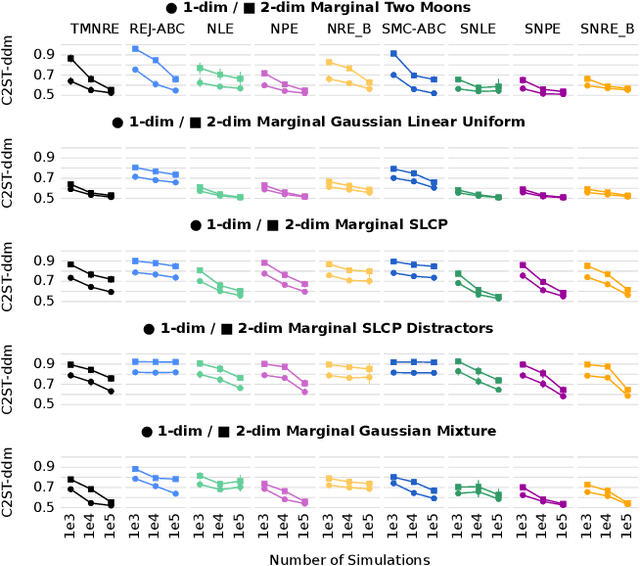
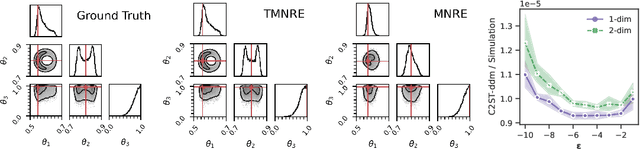
Parametric stochastic simulators are ubiquitous in science, often featuring high-dimensional input parameters and/or an intractable likelihood. Performing Bayesian parameter inference in this context can be challenging. We present a neural simulator-based inference algorithm which simultaneously offers simulation efficiency and fast empirical posterior testability, which is unique among modern algorithms. Our approach is simulation efficient by simultaneously estimating low-dimensional marginal posteriors instead of the joint posterior and by proposing simulations targeted to an observation of interest via a prior suitably truncated by an indicator function. Furthermore, by estimating a locally amortized posterior our algorithm enables efficient empirical tests of the robustness of the inference results. Such tests are important for sanity-checking inference in real-world applications, which do not feature a known ground truth. We perform experiments on a marginalized version of the simulation-based inference benchmark and two complex and narrow posteriors, highlighting the simulator efficiency of our algorithm as well as the quality of the estimated marginal posteriors. Implementation on GitHub.
Diffusion Priors In Variational Autoencoders
Jun 29, 2021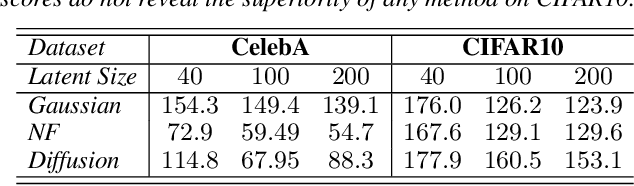


Among likelihood-based approaches for deep generative modelling, variational autoencoders (VAEs) offer scalable amortized posterior inference and fast sampling. However, VAEs are also more and more outperformed by competing models such as normalizing flows (NFs), deep-energy models, or the new denoising diffusion probabilistic models (DDPMs). In this preliminary work, we improve VAEs by demonstrating how DDPMs can be used for modelling the prior distribution of the latent variables. The diffusion prior model improves upon Gaussian priors of classical VAEs and is competitive with NF-based priors. Finally, we hypothesize that hierarchical VAEs could similarly benefit from the enhanced capacity of diffusion priors.
Distributional Reinforcement Learning with Unconstrained Monotonic Neural Networks
Jun 06, 2021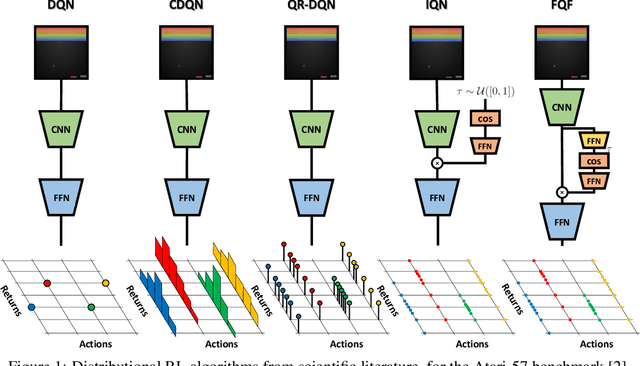
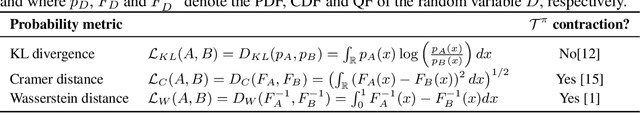
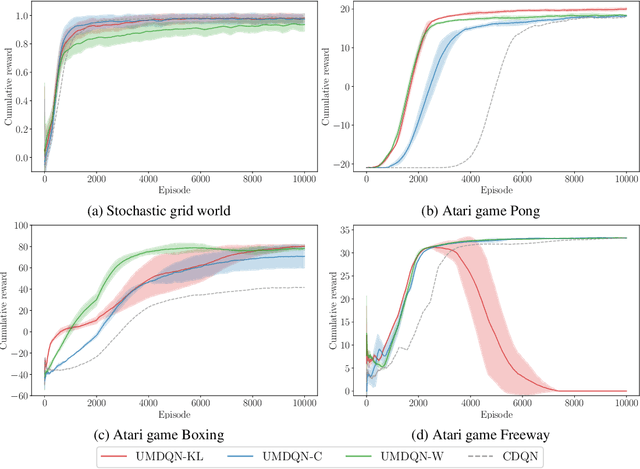

The distributional reinforcement learning (RL) approach advocates for representing the complete probability distribution of the random return instead of only modelling its expectation. A distributional RL algorithm may be characterised by two main components, namely the representation and parameterisation of the distribution and the probability metric defining the loss. This research considers the unconstrained monotonic neural network (UMNN) architecture, a universal approximator of continuous monotonic functions which is particularly well suited for modelling different representations of a distribution (PDF, CDF, quantile function). This property enables the decoupling of the effect of the function approximator class from that of the probability metric. The paper firstly introduces a methodology for learning different representations of the random return distribution. Secondly, a novel distributional RL algorithm named unconstrained monotonic deep Q-network (UMDQN) is presented. Lastly, in light of this new algorithm, an empirical comparison is performed between three probability quasimetrics, namely the Kullback-Leibler divergence, Cramer distance and Wasserstein distance. The results call for a reconsideration of all probability metrics in distributional RL, which contrasts with the dominance of the Wasserstein distance in recent publications.