 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning
Nov 26, 2018
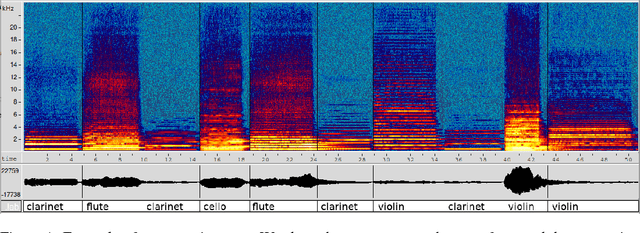
We introduce the task of acoustic question answering (AQA) in the area of acoustic reasoning. In this task an agent learns to answer questions on the basis of acoustic context. In order to promote research in this area, we propose a data generation paradigm adapted from CLEVR (Johnson et al. 2017). We generate acoustic scenes by leveraging a bank elementary sounds. We also provide a number of functional programs that can be used to compose questions and answers that exploit the relationships between the attributes of the elementary sounds in each scene. We provide AQA datasets of various sizes as well as the data generation code. As a preliminary experiment to validate our data, we report the accuracy of current state of the art visual question answering models when they are applied to the AQA task without modifications. Although there is a plethora of question answering tasks based on text, image or video data, to our knowledge, we are the first to propose answering questions directly on audio streams. We hope this contribution will facilitate the development of research in the area.
Active Mini-Batch Sampling using Repulsive Point Processes
Jun 20, 2018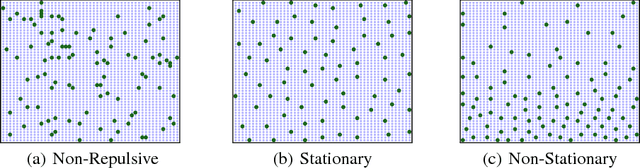
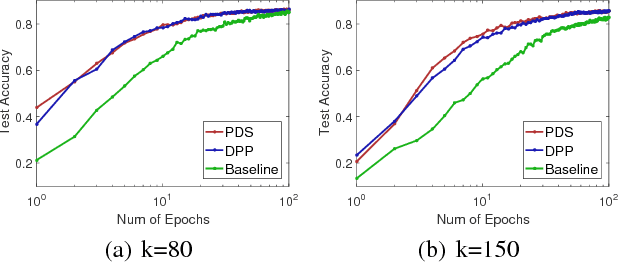
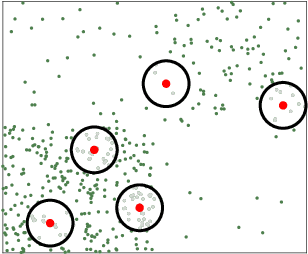

The convergence speed of stochastic gradient descent (SGD) can be improved by actively selecting mini-batches. We explore sampling schemes where similar data points are less likely to be selected in the same mini-batch. In particular, we prove that such repulsive sampling schemes lowers the variance of the gradient estimator. This generalizes recent work on using Determinantal Point Processes (DPPs) for mini-batch diversification (Zhang et al., 2017) to the broader class of repulsive point processes. We first show that the phenomenon of variance reduction by diversified sampling generalizes in particular to non-stationary point processes. We then show that other point processes may be computationally much more efficient than DPPs. In particular, we propose and investigate Poisson Disk sampling---frequently encountered in the computer graphics community---for this task. We show empirically that our approach improves over standard SGD both in terms of convergence speed as well as final model performance.
Language Bootstrapping: Learning Word Meanings From Perception-Action Association
Nov 27, 2017

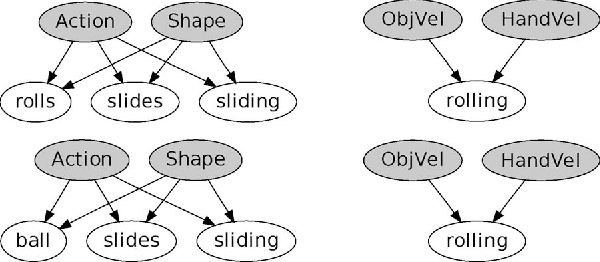
We address the problem of bootstrapping language acquisition for an artificial system similarly to what is observed in experiments with human infants. Our method works by associating meanings to words in manipulation tasks, as a robot interacts with objects and listens to verbal descriptions of the interactions. The model is based on an affordance network, i.e., a mapping between robot actions, robot perceptions, and the perceived effects of these actions upon objects. We extend the affordance model to incorporate spoken words, which allows us to ground the verbal symbols to the execution of actions and the perception of the environment. The model takes verbal descriptions of a task as the input and uses temporal co-occurrence to create links between speech utterances and the involved objects, actions, and effects. We show that the robot is able form useful word-to-meaning associations, even without considering grammatical structure in the learning process and in the presence of recognition errors. These word-to-meaning associations are embedded in the robot's own understanding of its actions. Thus, they can be directly used to instruct the robot to perform tasks and also allow to incorporate context in the speech recognition task. We believe that the encouraging results with our approach may afford robots with a capacity to acquire language descriptors in their operation's environment as well as to shed some light as to how this challenging process develops with human infants.
* code available at https://github.com/giampierosalvi/AffordancesAndSpeech
Interactive Robot Learning of Gestures, Language and Affordances
Nov 24, 2017
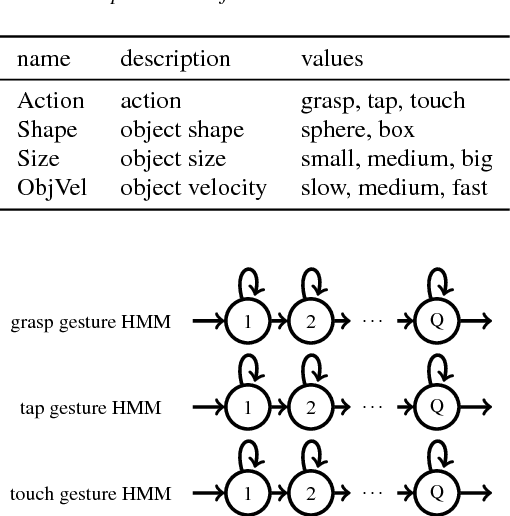
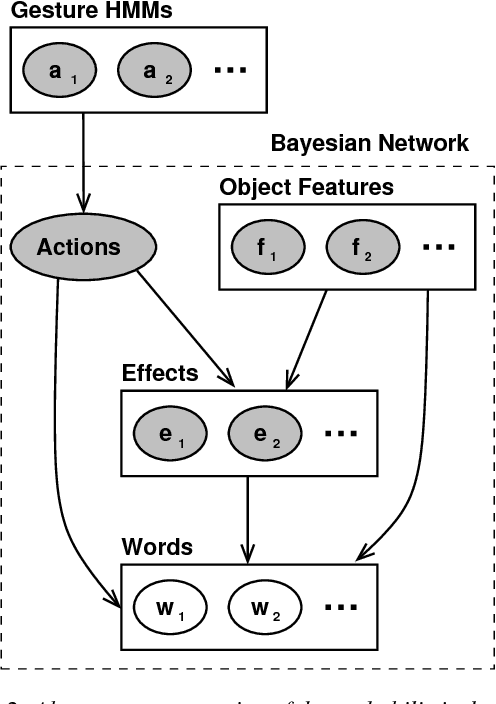
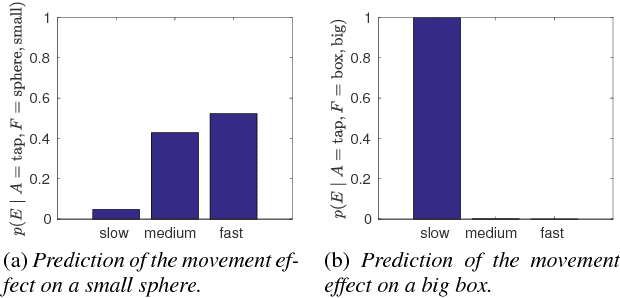
A growing field in robotics and Artificial Intelligence (AI) research is human-robot collaboration, whose target is to enable effective teamwork between humans and robots. However, in many situations human teams are still superior to human-robot teams, primarily because human teams can easily agree on a common goal with language, and the individual members observe each other effectively, leveraging their shared motor repertoire and sensorimotor resources. This paper shows that for cognitive robots it is possible, and indeed fruitful, to combine knowledge acquired from interacting with elements of the environment (affordance exploration) with the probabilistic observation of another agent's actions. We propose a model that unites (i) learning robot affordances and word descriptions with (ii) statistical recognition of human gestures with vision sensors. We discuss theoretical motivations, possible implementations, and we show initial results which highlight that, after having acquired knowledge of its surrounding environment, a humanoid robot can generalize this knowledge to the case when it observes another agent (human partner) performing the same motor actions previously executed during training.
* code available at https://github.com/gsaponaro/glu-gestures
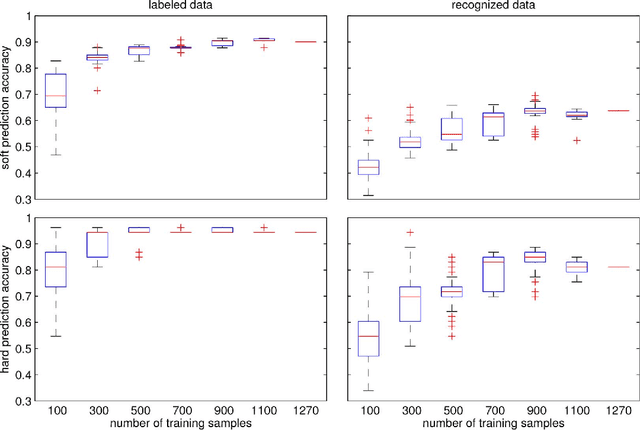
Self-Supervised Vision-Based Detection of the Active Speaker as a Prerequisite for Socially-Aware Language Acquisition
Nov 24, 2017
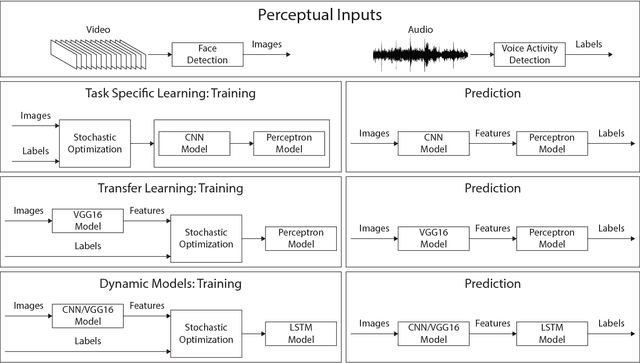
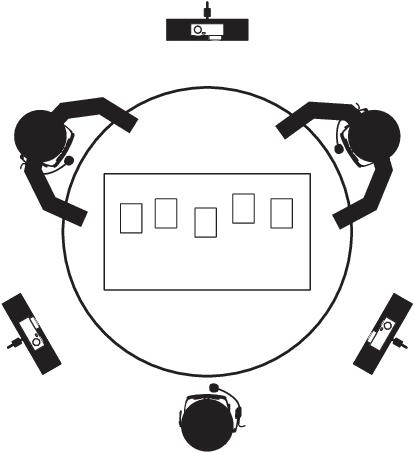
This paper presents a self-supervised method for detecting the active speaker in a multi-person spoken interaction scenario. We argue that this capability is a fundamental prerequisite for any artificial cognitive system attempting to acquire language in social settings. Our methods are able to detect an arbitrary number of possibly overlapping active speakers based exclusively on visual information about their face. Our methods do not rely on external annotations, thus complying with cognitive development. Instead, they use information from the auditory modality to support learning in the visual domain. The methods have been extensively evaluated on a large multi-person face-to-face interaction dataset. The results reach an accuracy of 80% on a multi-speaker setting. We believe this system represents an essential component of any artificial cognitive system or robotic platform engaging in social interaction.
Semi-supervised Learning with Sparse Autoencoders in Phone Classification
Oct 03, 2016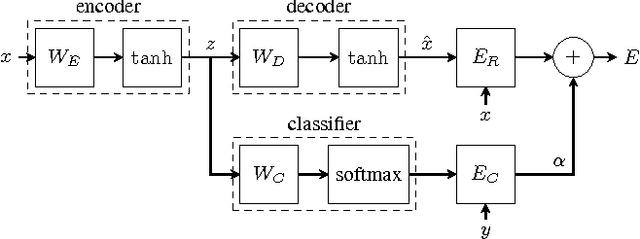
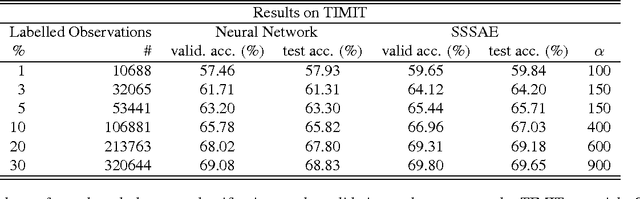
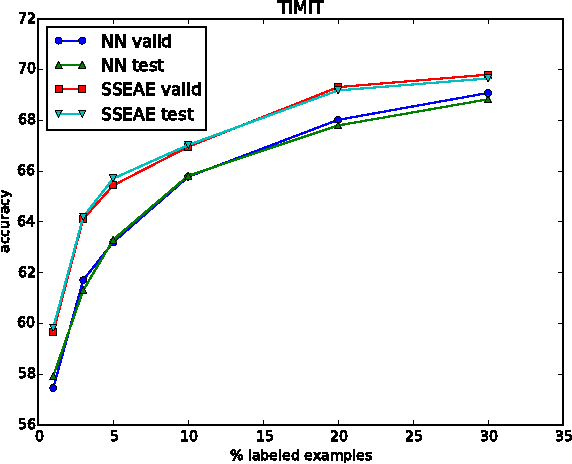
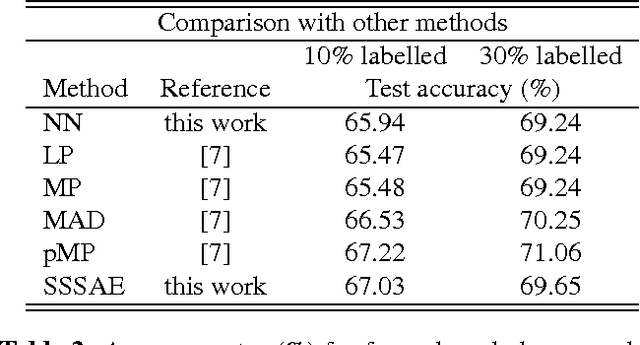
We propose the application of a semi-supervised learning method to improve the performance of acoustic modelling for automatic speech recognition based on deep neural net- works. As opposed to unsupervised initialisation followed by supervised fine tuning, our method takes advantage of both unlabelled and labelled data simultaneously through mini- batch stochastic gradient descent. We tested the method with varying proportions of labelled vs unlabelled observations in frame-based phoneme classification on the TIMIT database. Our experiments show that the method outperforms standard supervised training for an equal amount of labelled data and provides competitive error rates compared to state-of-the-art graph-based semi-supervised learning techniques.
Optimising The Input Window Alignment in CD-DNN Based Phoneme Recognition for Low Latency Processing
Jun 29, 2016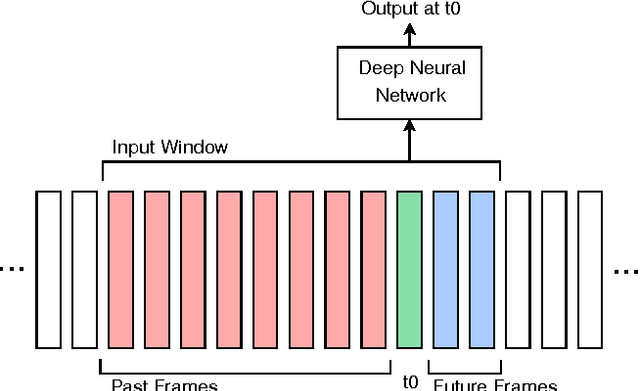
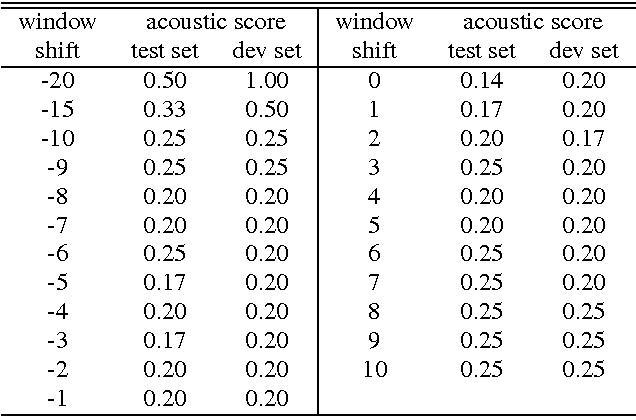
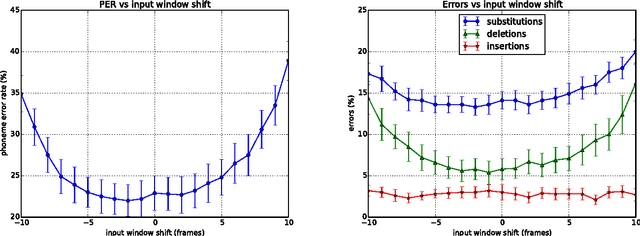
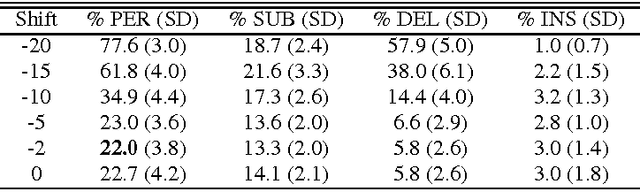
We present a systematic analysis on the performance of a phonetic recogniser when the window of input features is not symmetric with respect to the current frame. The recogniser is based on Context Dependent Deep Neural Networks (CD-DNNs) and Hidden Markov Models (HMMs). The objective is to reduce the latency of the system by reducing the number of future feature frames required to estimate the current output. Our tests performed on the TIMIT database show that the performance does not degrade when the input window is shifted up to 5 frames in the past compared to common practice (no future frame). This corresponds to improving the latency by 50 ms in our settings. Our tests also show that the best results are not obtained with the symmetric window commonly employed, but with an asymmetric window with eight past and two future context frames, although this observation should be confirmed on other data sets. The reduction in latency suggested by our results is critical for specific applications such as real-time lip synchronisation for tele-presence, but may also be beneficial in general applications to improve the lag in human-machine spoken interaction.