 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT-BCI: Word-Level Neural State Classification Using GPT, EEG, and Eye-Tracking Biomarkers in Semantic Inference Reading Comprehension
Sep 27, 2023



With the recent explosion of large language models (LLMs), such as Generative Pretrained Transformers (GPT), the need to understand the ability of humans and machines to comprehend semantic language meaning has entered a new phase. This requires interdisciplinary research that bridges the fields of cognitive science and natural language processing (NLP). This pilot study aims to provide insights into individuals' neural states during a semantic relation reading-comprehension task. We propose jointly analyzing LLMs, eye-gaze, and electroencephalographic (EEG) data to study how the brain processes words with varying degrees of relevance to a keyword during reading. We also use a feature engineering approach to improve the fixation-related EEG data classification while participants read words with high versus low relevance to the keyword. The best validation accuracy in this word-level classification is over 60\% across 12 subjects. Words of high relevance to the inference keyword had significantly more eye fixations per word: 1.0584 compared to 0.6576 when excluding no-fixation words, and 1.5126 compared to 1.4026 when including them. This study represents the first attempt to classify brain states at a word level using LLM knowledge. It provides valuable insights into human cognitive abilities and the realm of Artificial General Intelligence (AGI), and offers guidance for developing potential reading-assisted technologies.
Active Inference in Hebbian Learning Networks
Jun 22, 2023



This work studies how brain-inspired neural ensembles equipped with local Hebbian plasticity can perform active inference (AIF) in order to control dynamical agents. A generative model capturing the environment dynamics is learned by a network composed of two distinct Hebbian ensembles: a posterior network, which infers latent states given the observations, and a state transition network, which predicts the next expected latent state given current state-action pairs. Experimental studies are conducted using the Mountain Car environment from the OpenAI gym suite, to study the effect of the various Hebbian network parameters on the task performance. It is shown that the proposed Hebbian AIF approach outperforms the use of Q-learning, while not requiring any replay buffer, as in typical reinforcement learning systems. These results motivate further investigations of Hebbian learning for the design of AIF networks that can learn environment dynamics without the need for revisiting past buffered experiences.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
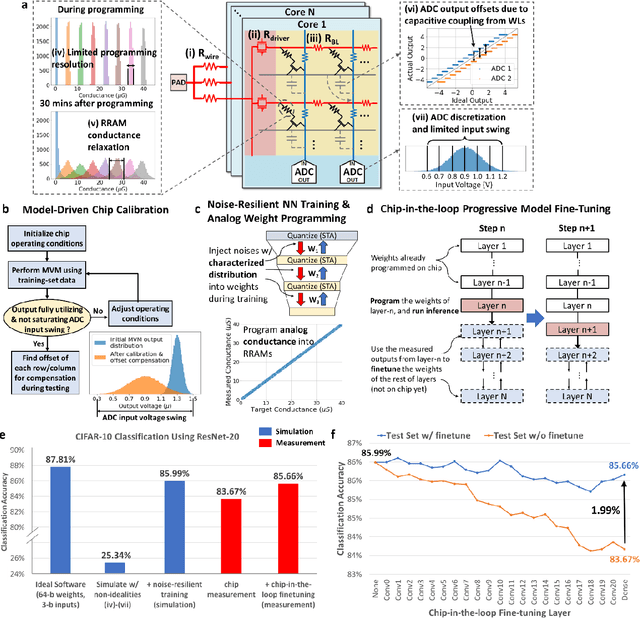
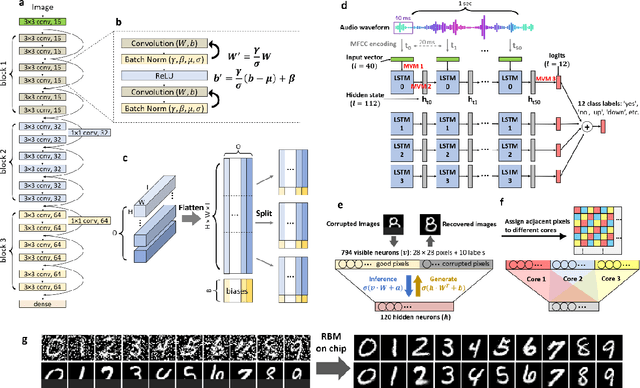
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.
Neural and Synaptic Array Transceiver: A Brain-Inspired Computing Framework for Embedded Learning
Aug 08, 2018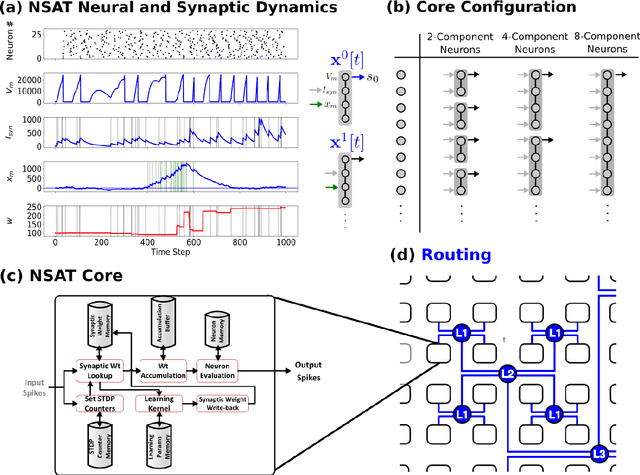

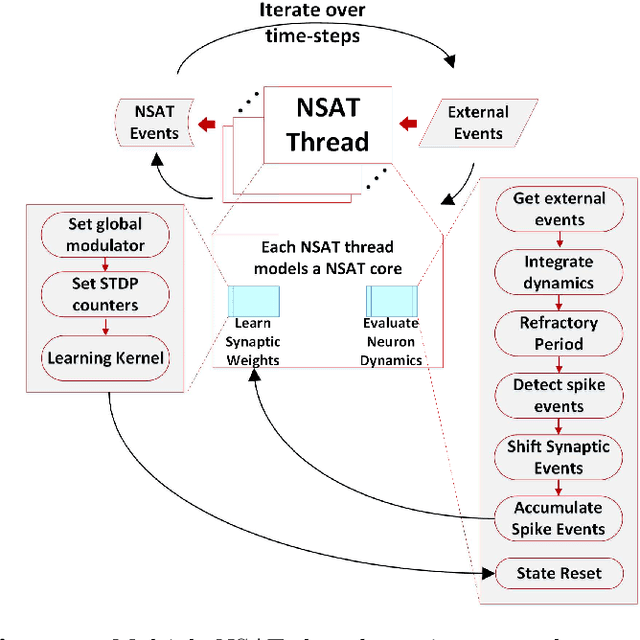
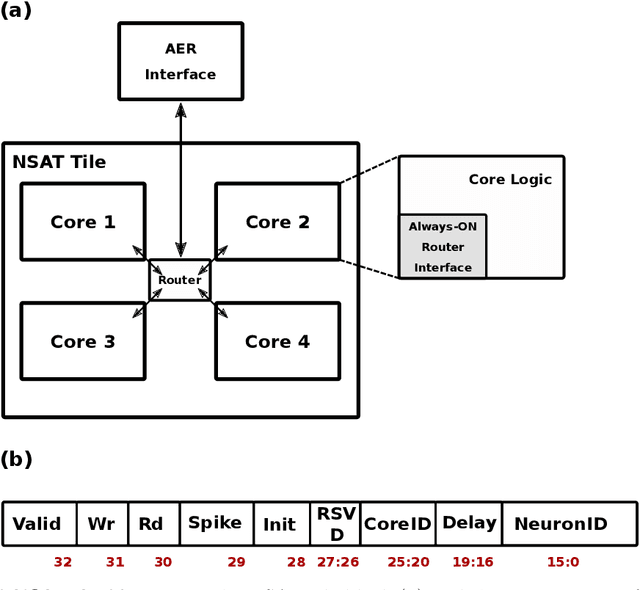
Embedded, continual learning for autonomous and adaptive behavior is a key application of neuromorphic hardware. However, neuromorphic implementations of embedded learning at large scales that are both flexible and efficient have been hindered by a lack of a suitable algorithmic framework. As a result, the most neuromorphic hardware is trained off-line on large clusters of dedicated processors or GPUs and transferred post hoc to the device. We address this by introducing the neural and synaptic array transceiver (NSAT), a neuromorphic computational framework facilitating flexible and efficient embedded learning by matching algorithmic requirements and neural and synaptic dynamics. NSAT supports event-driven supervised, unsupervised and reinforcement learning algorithms including deep learning. We demonstrate the NSAT in a wide range of tasks, including the simulation of Mihalas-Niebur neuron, dynamic neural fields, event-driven random back-propagation for event-based deep learning, event-based contrastive divergence for unsupervised learning, and voltage-based learning rules for sequence learning. We anticipate that this contribution will establish the foundation for a new generation of devices enabling adaptive mobile systems, wearable devices, and robots with data-driven autonomy.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
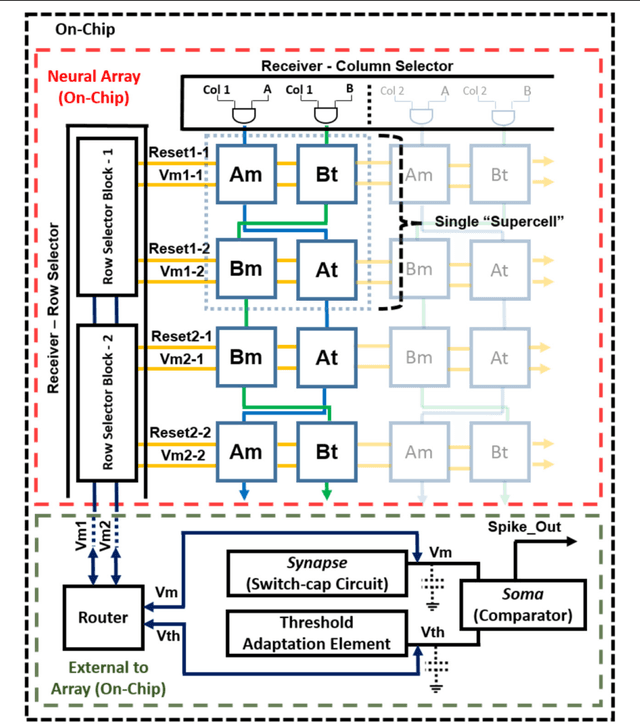
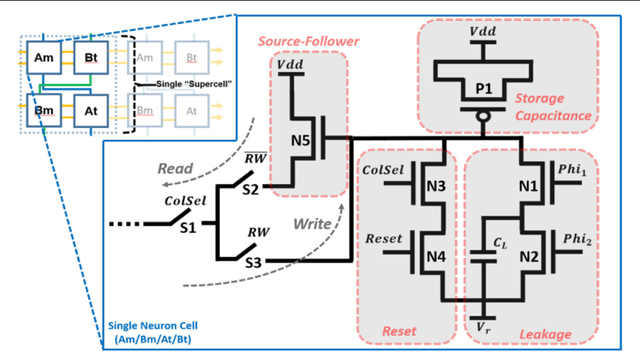
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
A learning framework for winner-take-all networks with stochastic synapses
Feb 05, 2018Many recent generative models make use of neural networks to transform the probability distribution of a simple low-dimensional noise process into the complex distribution of the data. This raises the question of whether biological networks operate along similar principles to implement a probabilistic model of the environment through transformations of intrinsic noise processes. The intrinsic neural and synaptic noise processes in biological networks, however, are quite different from the noise processes used in current abstract generative networks. This, together with the discrete nature of spikes and local circuit interactions among the neurons, raises several difficulties when using recent generative modeling frameworks to train biologically motivated models. In this paper, we show that a biologically motivated model based on multi-layer winner-take-all (WTA) circuits and stochastic synapses admits an approximate analytical description. This allows us to use the proposed networks in a variational learning setting where stochastic backpropagation is used to optimize a lower bound on the data log likelihood, thereby learning a generative model of the data. We illustrate the generality of the proposed networks and learning technique by using them in a structured output prediction task, and in a semi-supervised learning task. Our results extend the domain of application of modern stochastic network architectures to networks where synaptic transmission failure is the principal noise mechanism.
Deep supervised learning using local errors
Nov 17, 2017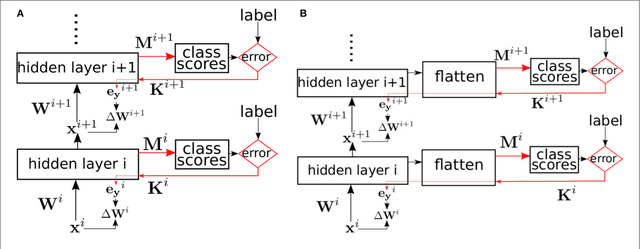

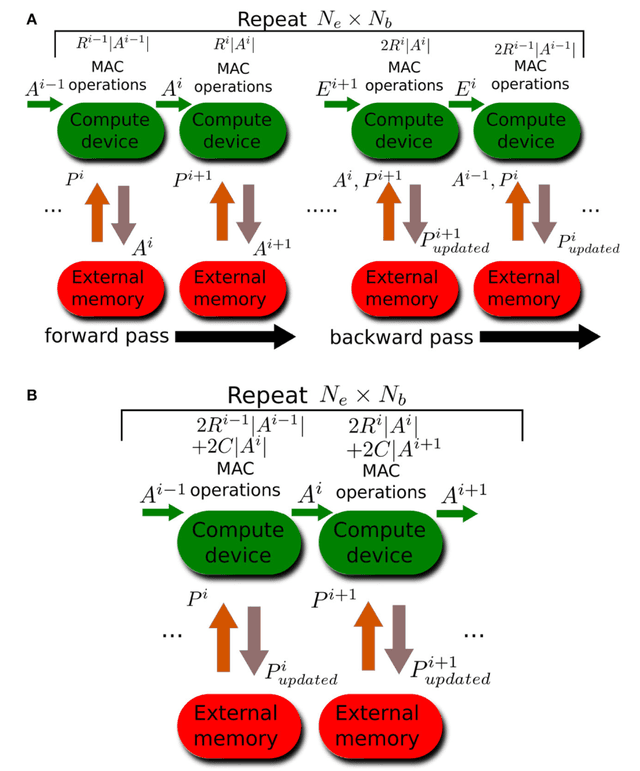
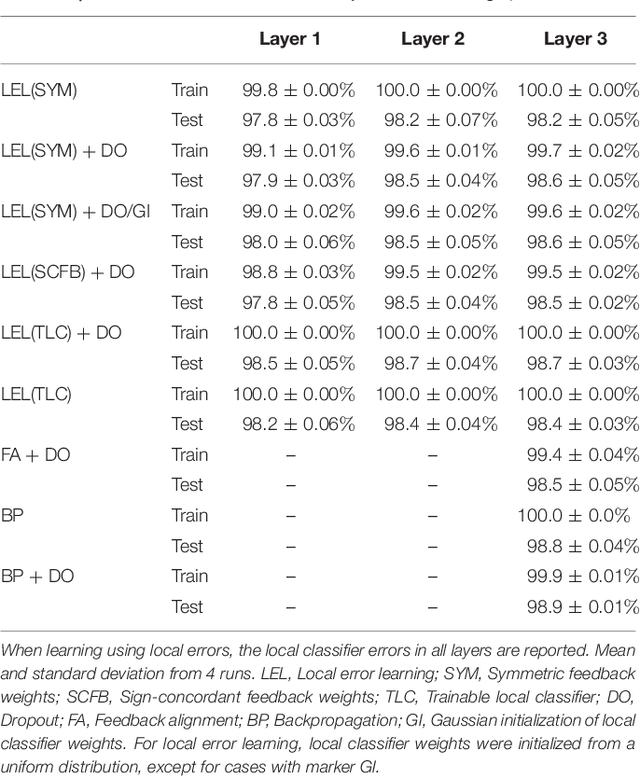
Error backpropagation is a highly effective mechanism for learning high-quality hierarchical features in deep networks. Updating the features or weights in one layer, however, requires waiting for the propagation of error signals from higher layers. Learning using delayed and non-local errors makes it hard to reconcile backpropagation with the learning mechanisms observed in biological neural networks as it requires the neurons to maintain a memory of the input long enough until the higher-layer errors arrive. In this paper, we propose an alternative learning mechanism where errors are generated locally in each layer using fixed, random auxiliary classifiers. Lower layers could thus be trained independently of higher layers and training could either proceed layer by layer, or simultaneously in all layers using local error information. We address biological plausibility concerns such as weight symmetry requirements and show that the proposed learning mechanism based on fixed, broad, and random tuning of each neuron to the classification categories outperforms the biologically-motivated feedback alignment learning technique on the MNIST, CIFAR10, and SVHN datasets, approaching the performance of standard backpropagation. Our approach highlights a potential biological mechanism for the supervised, or task-dependent, learning of feature hierarchies. In addition, we show that it is well suited for learning deep networks in custom hardware where it can drastically reduce memory traffic and data communication overheads.
Hardware-efficient on-line learning through pipelined truncated-error backpropagation in binary-state networks
Aug 16, 2017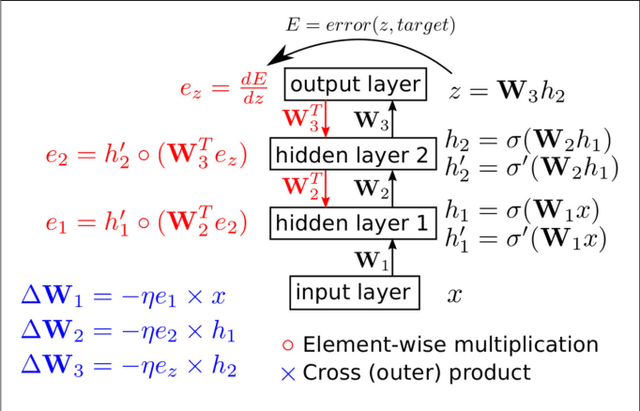
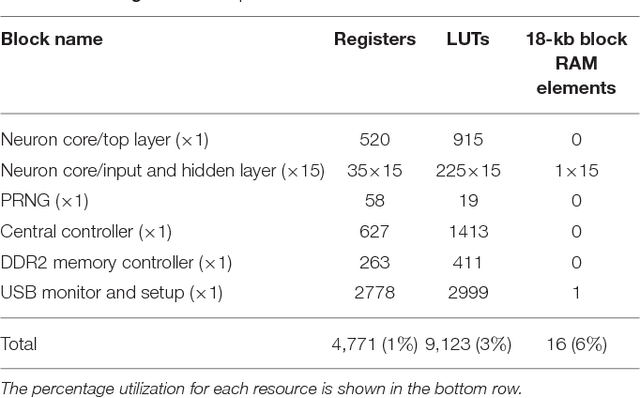
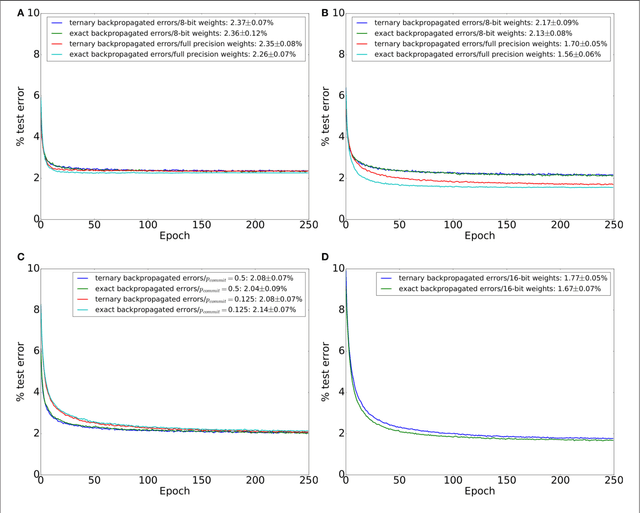

Artificial neural networks (ANNs) trained using backpropagation are powerful learning architectures that have achieved state-of-the-art performance in various benchmarks. Significant effort has been devoted to developing custom silicon devices to accelerate inference in ANNs. Accelerating the training phase, however, has attracted relatively little attention. In this paper, we describe a hardware-efficient on-line learning technique for feedforward multi-layer ANNs that is based on pipelined backpropagation. Learning is performed in parallel with inference in the forward pass, removing the need for an explicit backward pass and requiring no extra weight lookup. By using binary state variables in the feedforward network and ternary errors in truncated-error backpropagation, the need for any multiplications in the forward and backward passes is removed, and memory requirements for the pipelining are drastically reduced. Further reduction in addition operations owing to the sparsity in the forward neural and backpropagating error signal paths contributes to highly efficient hardware implementation. For proof-of-concept validation, we demonstrate on-line learning of MNIST handwritten digit classification on a Spartan 6 FPGA interfacing with an external 1Gb DDR2 DRAM, that shows small degradation in test error performance compared to an equivalently sized binary ANN trained off-line using standard back-propagation and exact errors. Our results highlight an attractive synergy between pipelined backpropagation and binary-state networks in substantially reducing computation and memory requirements, making pipelined on-line learning practical in deep networks.
Membrane-Dependent Neuromorphic Learning Rule for Unsupervised Spike Pattern Detection
Jan 05, 2017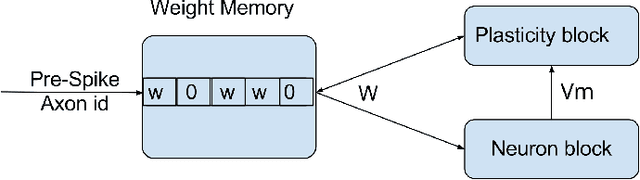
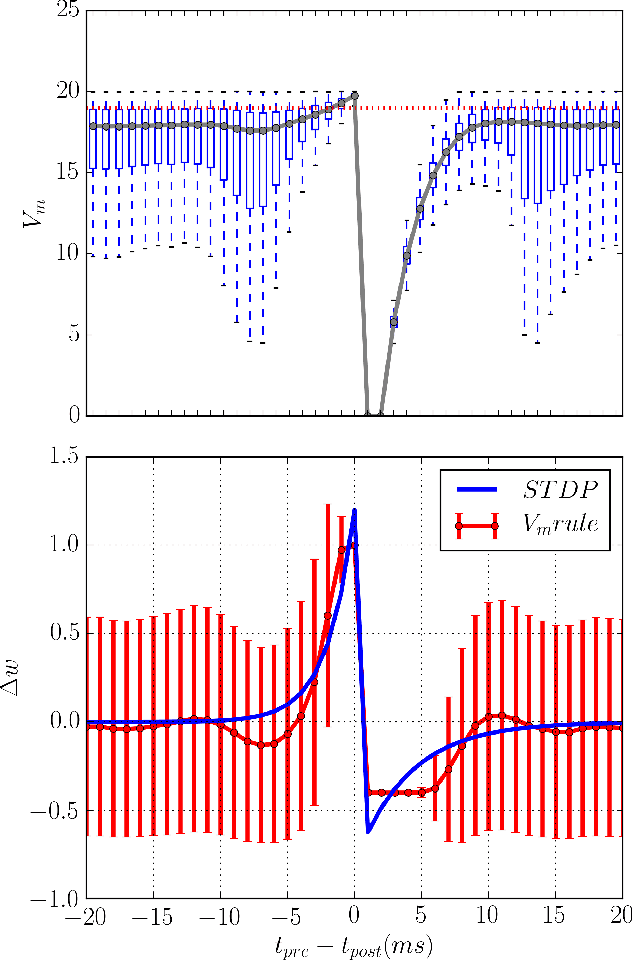
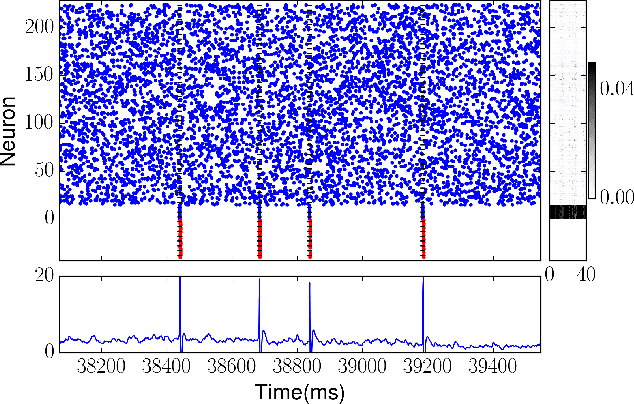
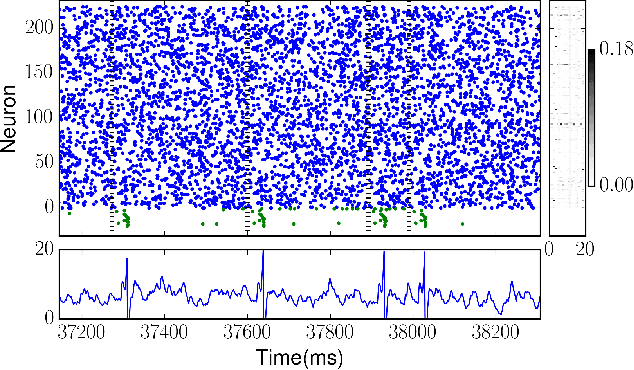
Several learning rules for synaptic plasticity, that depend on either spike timing or internal state variables, have been proposed in the past imparting varying computational capabilities to Spiking Neural Networks. Due to design complications these learning rules are typically not implemented on neuromorphic devices leaving the devices to be only capable of inference. In this work we propose a unidirectional post-synaptic potential dependent learning rule that is only triggered by pre-synaptic spikes, and easy to implement on hardware. We demonstrate that such a learning rule is functionally capable of replicating computational capabilities of pairwise STDP. Further more, we demonstrate that this learning rule can be used to learn and classify spatio-temporal spike patterns in an unsupervised manner using individual neurons. We argue that this learning rule is computationally powerful and also ideal for hardware implementations due to its unidirectional memory access.