 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Contribution of Semantic Congruency to Multisensory Integration and Conflict Resolution
Oct 15, 2018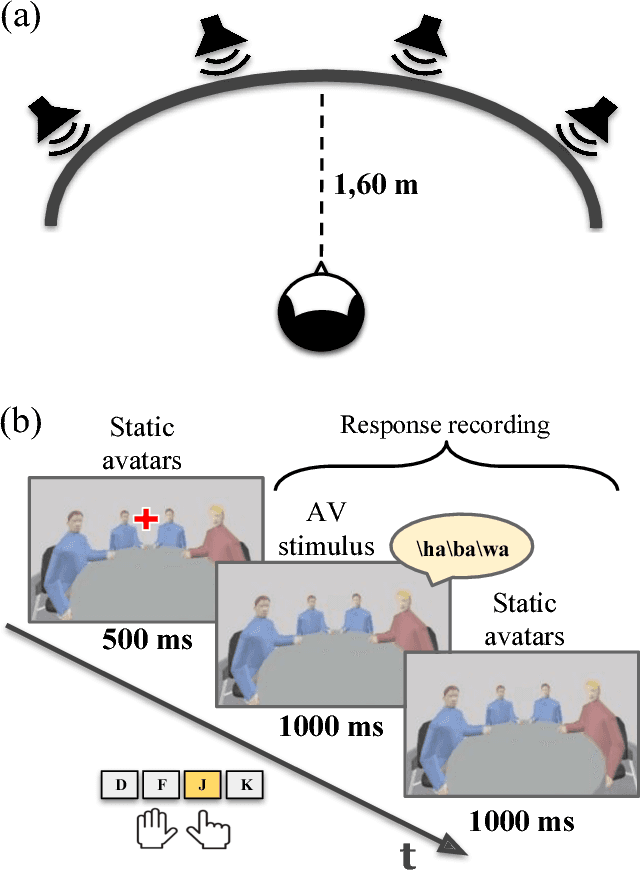
The efficient integration of multisensory observations is a key property of the brain that yields the robust interaction with the environment. However, artificial multisensory perception remains an open issue especially in situations of sensory uncertainty and conflicts. In this work, we extend previous studies on audio-visual (AV) conflict resolution in complex environments. In particular, we focus on quantitatively assessing the contribution of semantic congruency during an AV spatial localization task. In addition to conflicts in the spatial domain (i.e. spatially misaligned stimuli), we consider gender-specific conflicts with male and female avatars. Our results suggest that while semantically related stimuli affect the magnitude of the visual bias (perceptually shifting the location of the sound towards a semantically congruent visual cue), humans still strongly rely on environmental statistics to solve AV conflicts. Together with previously reported results, this work contributes to a better understanding of how multisensory integration and conflict resolution can be modelled in artificial agents and robots operating in real-world environments.
A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
Sep 24, 2018
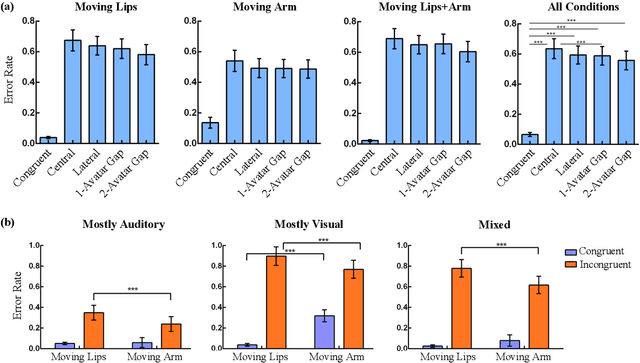
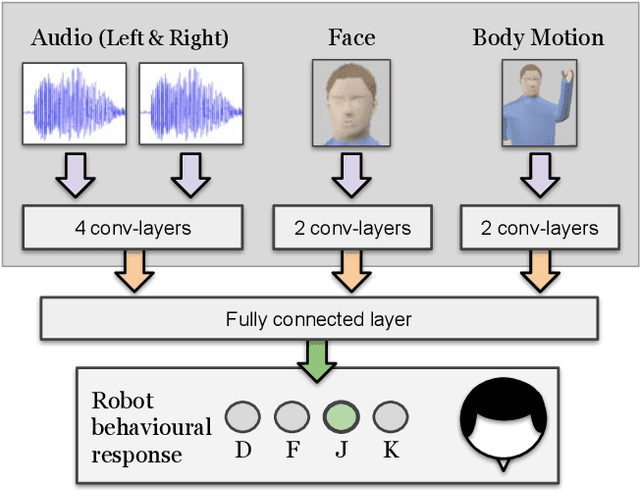
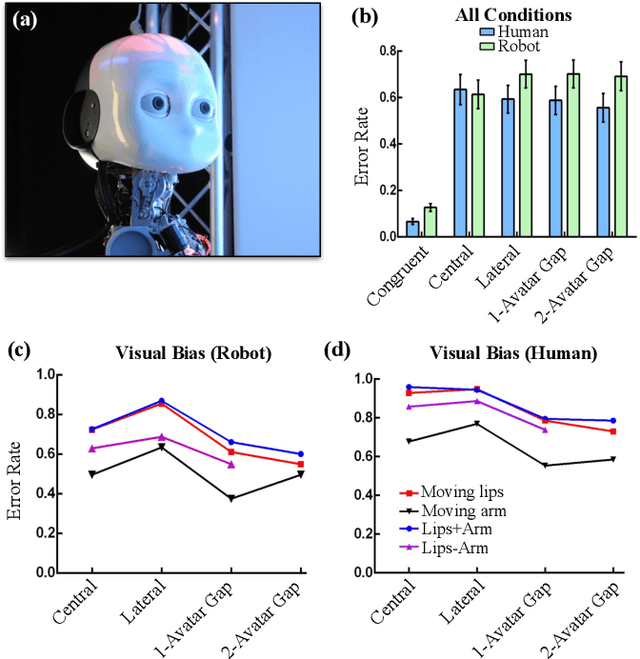
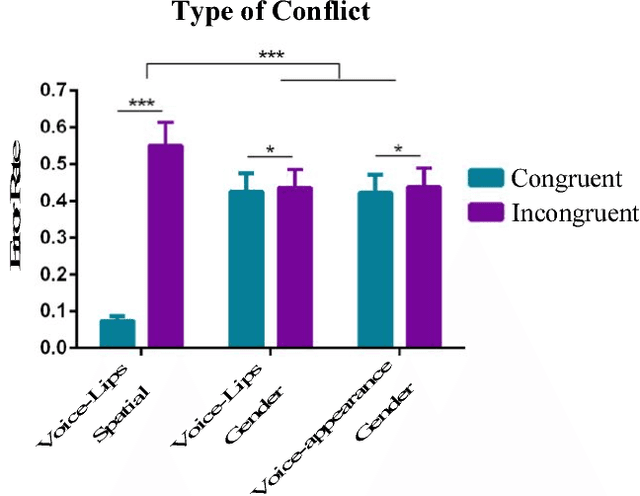
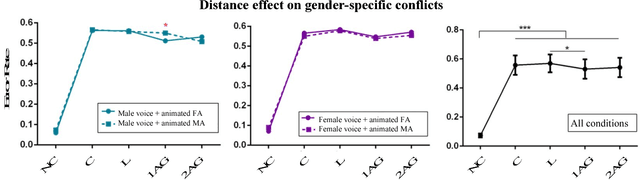
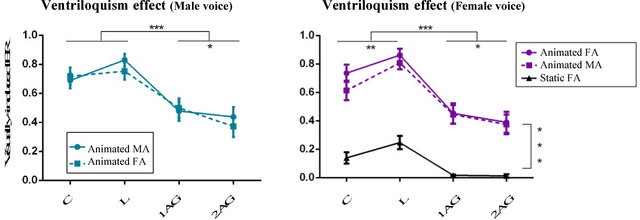
Crossmodal conflict resolution is crucial for robot sensorimotor coupling through the interaction with the environment, yielding swift and robust behaviour also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioural study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce the strongest bias. We implement a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete behavioural response. After training the model, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modelled in robots and introduces future research directions for the efficient combination of sensory observations with internally generated knowledge and expectations.
Multi-modal Feedback for Affordance-driven Interactive Reinforcement Learning
Jul 26, 2018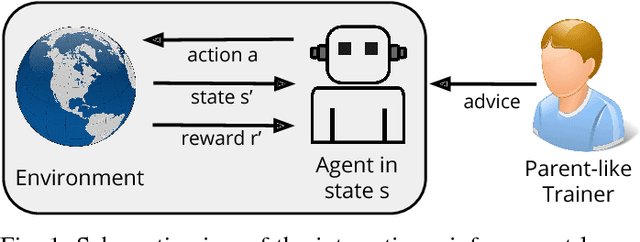
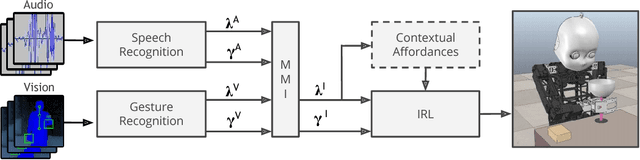
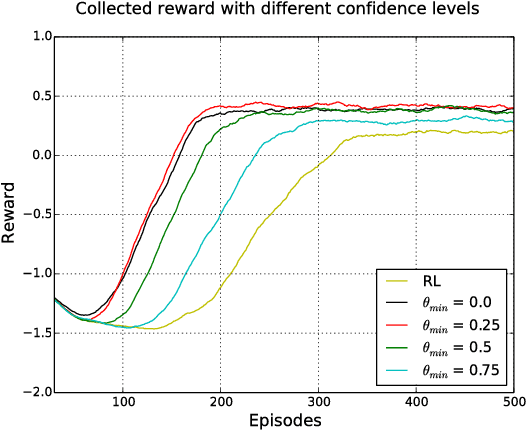
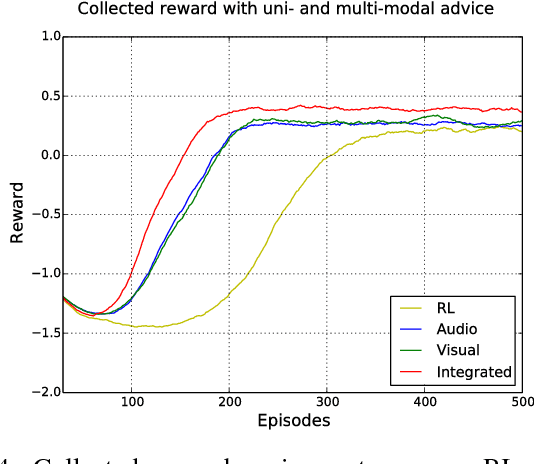
Interactive reinforcement learning (IRL) extends traditional reinforcement learning (RL) by allowing an agent to interact with parent-like trainers during a task. In this paper, we present an IRL approach using dynamic audio-visual input in terms of vocal commands and hand gestures as feedback. Our architecture integrates multi-modal information to provide robust commands from multiple sensory cues along with a confidence value indicating the trustworthiness of the feedback. The integration process also considers the case in which the two modalities convey incongruent information. Additionally, we modulate the influence of sensory-driven feedback in the IRL task using goal-oriented knowledge in terms of contextual affordances. We implement a neural network architecture to predict the effect of performed actions with different objects to avoid failed-states, i.e., states from which it is not possible to accomplish the task. In our experimental setup, we explore the interplay of multimodal feedback and task-specific affordances in a robot cleaning scenario. We compare the learning performance of the agent under four different conditions: traditional RL, multi-modal IRL, and each of these two setups with the use of contextual affordances. Our experiments show that the best performance is obtained by using audio-visual feedback with affordancemodulated IRL. The obtained results demonstrate the importance of multi-modal sensory processing integrated with goal-oriented knowledge in IRL tasks.
Towards Modeling the Interaction of Spatial-Associative Neural Network Representations for Multisensory Perception
Jul 13, 2018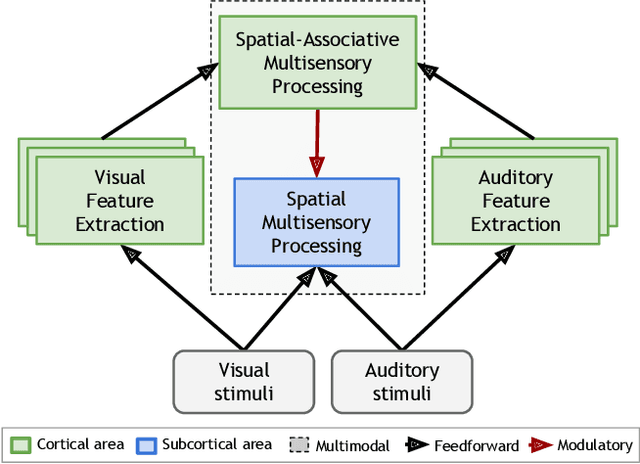
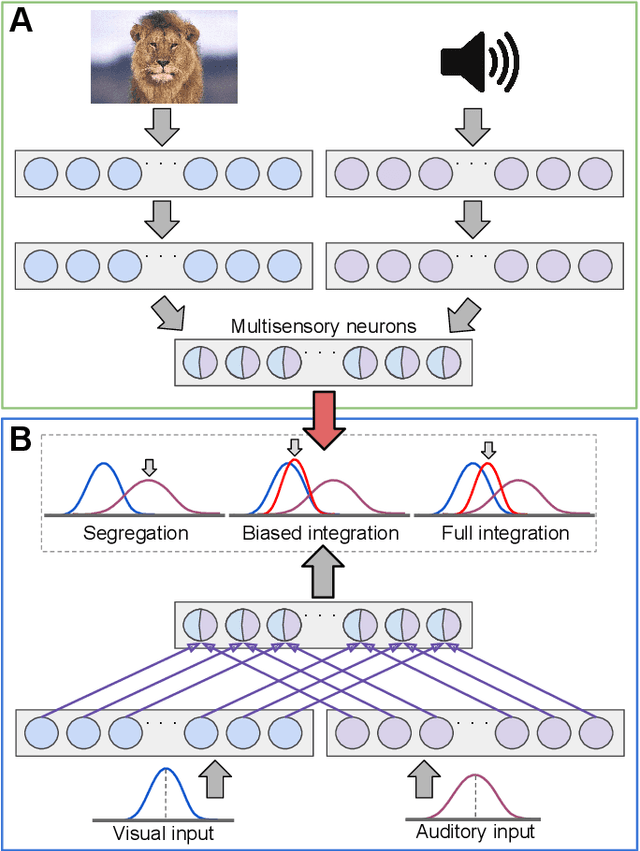
Our daily perceptual experience is driven by different neural mechanisms that yield multisensory interaction as the interplay between exogenous stimuli and endogenous expectations. While the interaction of multisensory cues according to their spatiotemporal properties and the formation of multisensory feature-based representations have been widely studied, the interaction of spatial-associative neural representations has received considerably less attention. In this paper, we propose a neural network architecture that models the interaction of spatial-associative representations to perform causal inference of audiovisual stimuli. We investigate the spatial alignment of exogenous audiovisual stimuli modulated by associative congruence. In the spatial layer, topographically arranged networks account for the interaction of audiovisual input in terms of population codes. In the associative layer, congruent audiovisual representations are obtained via the experience-driven development of feature-based associations. Levels of congruency are obtained as a by-product of the neurodynamics of self-organizing networks, where the amount of neural activation triggered by the input can be expressed via a nonlinear distance function. Our novel proposal is that activity-driven levels of congruency can be used as top-down modulatory projections to spatially distributed representations of sensory input, e.g. semantically related audiovisual pairs will yield a higher level of integration than unrelated pairs. Furthermore, levels of neural response in unimodal layers may be seen as sensory reliability for the dynamic weighting of crossmodal cues. We describe a series of planned experiments to validate our model in the tasks of multisensory interaction on the basis of semantic congruence and unimodal cue reliability.
Continual Lifelong Learning with Neural Networks: A Review
Jul 07, 2018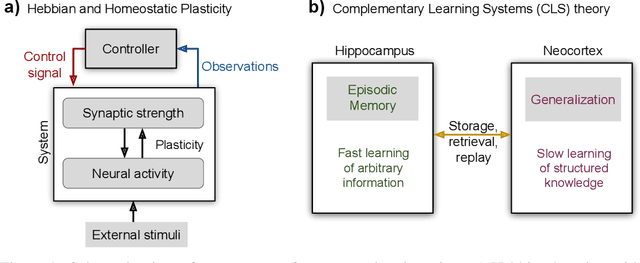
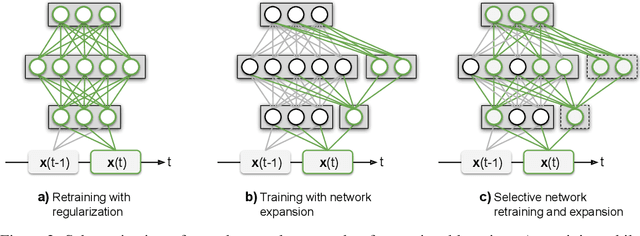

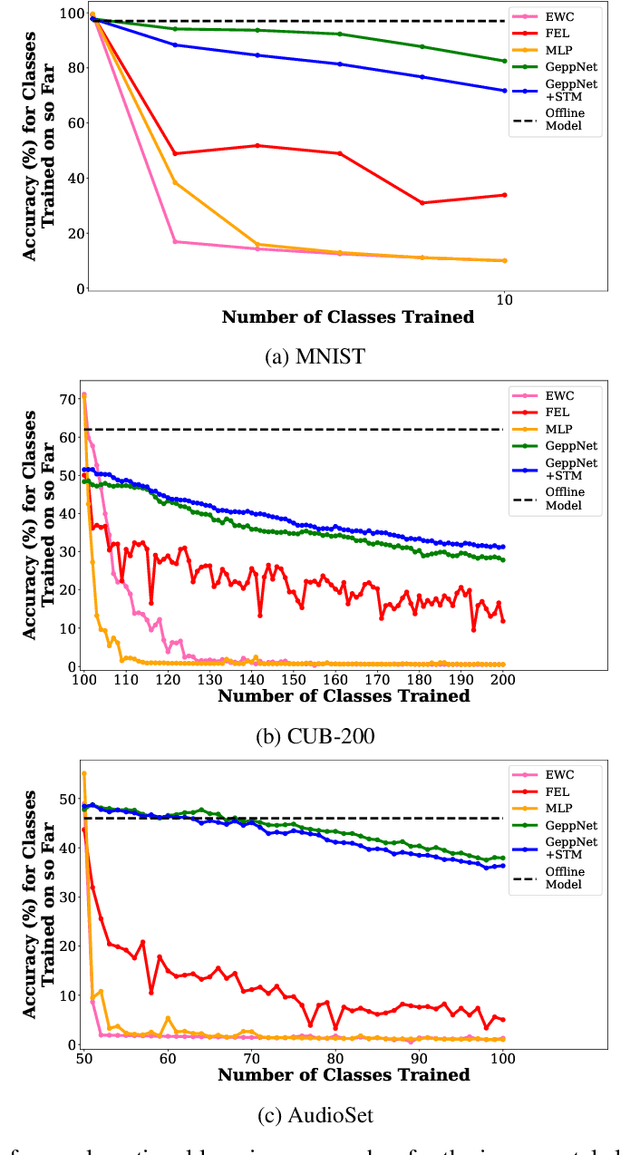
Humans and animals have the ability to continually acquire and fine-tune knowledge throughout their lifespan. This ability, referred to as lifelong learning, is mediated by a rich set of neurocognitive mechanisms that together contribute to the development and specialization of our sensorimotor skills as well as to the long-term memory consolidation and retrieval without catastrophic forgetting. Consequently, lifelong learning capabilities are crucial for computational learning systems and autonomous agents interacting in the real world and processing continuous streams of information. However, lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference. This limitation represents a major drawback also for state-of-the-art deep and shallow neural network models that typically learn representations from stationary batches of training data, thus without accounting for situations in which the number of tasks is not known a priori and the information becomes incrementally available over time. In this review, we critically summarize the main challenges linked to lifelong learning for artificial learning systems and compare existing neural network approaches that alleviate, to different extents, catastrophic forgetting. Although significant advances have been made in domain-specific learning with neural networks, extensive research efforts are required for the development of robust lifelong learning on autonomous agents and robots. We discuss well-established and emerging research motivated by lifelong learning factors in biological systems such as neurosynaptic plasticity, multi-task transfer learning, intrinsically motivated exploration, and crossmodal learning.
An Incremental Self-Organizing Architecture for Sensorimotor Learning and Prediction
Mar 09, 2018
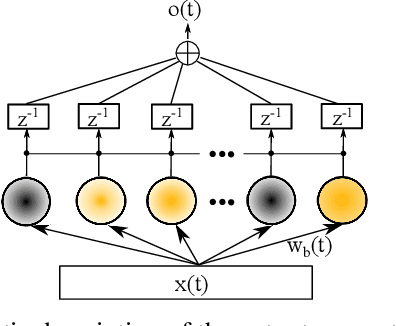
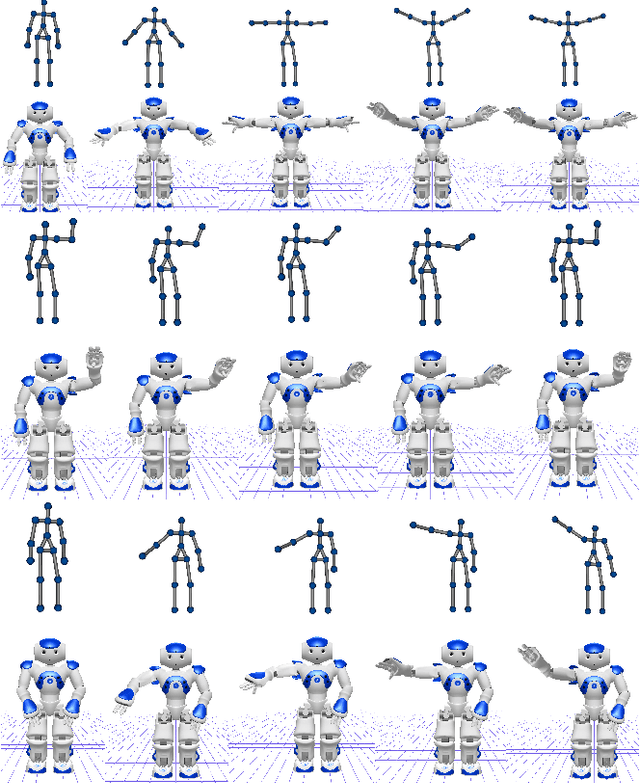
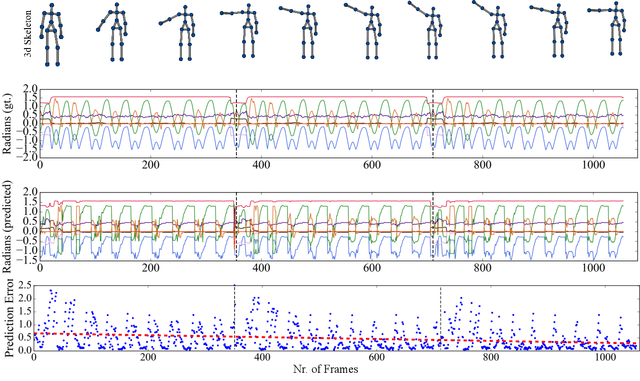
During visuomotor tasks, robots must compensate for temporal delays inherent in their sensorimotor processing systems. Delay compensation becomes crucial in a dynamic environment where the visual input is constantly changing, e.g., during the interacting with a human demonstrator. For this purpose, the robot must be equipped with a prediction mechanism for using the acquired perceptual experience to estimate possible future motor commands. In this paper, we present a novel neural network architecture that learns prototypical visuomotor representations and provides reliable predictions on the basis of the visual input. These predictions are used to compensate for the delayed motor behavior in an online manner. We investigate the performance of our method with a set of experiments comprising a humanoid robot that has to learn and generate visually perceived arm motion trajectories. We evaluate the accuracy in terms of mean prediction error and analyze the response of the network to novel movement demonstrations. Additionally, we report experiments with incomplete data sequences, showing the robustness of the proposed architecture in the case of a noisy and faulty visual sensor.
Closing the loop on multisensory interactions: A neural architecture for multisensory causal inference and recalibration
Mar 04, 2018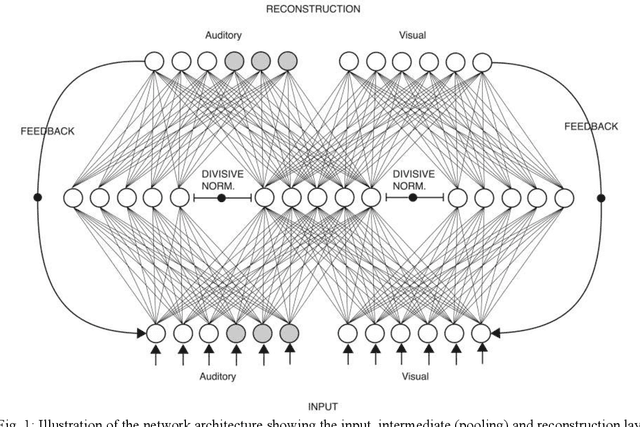
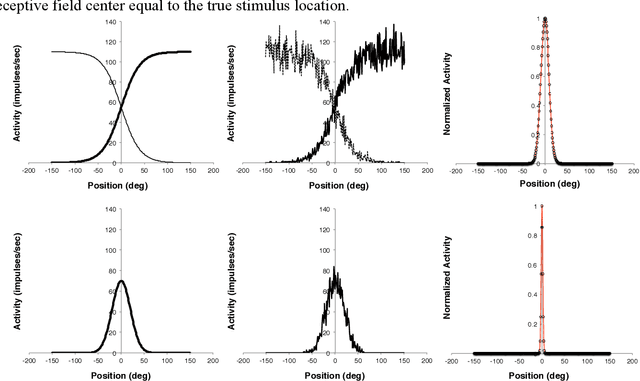
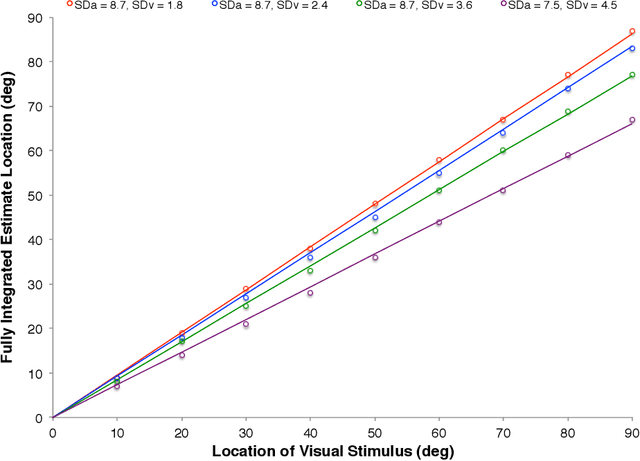
When the brain receives input from multiple sensory systems, it is faced with the question of whether it is appropriate to process the inputs in combination, as if they originated from the same event, or separately, as if they originated from distinct events. Furthermore, it must also have a mechanism through which it can keep sensory inputs calibrated to maintain the accuracy of its internal representations. We have developed a neural network architecture capable of i) approximating optimal multisensory spatial integration, based on Bayesian causal inference, and ii) recalibrating the spatial encoding of sensory systems. The architecture is based on features of the dorsal processing hierarchy, including the spatial tuning properties of unisensory neurons and the convergence of different sensory inputs onto multisensory neurons. Furthermore, we propose that these unisensory and multisensory neurons play dual roles in i) encoding spatial location as separate or integrated estimates and ii) accumulating evidence for the independence or relatedness of multisensory stimuli. We further propose that top-down feedback connections spanning the dorsal pathway play key a role in recalibrating spatial encoding at the level of early unisensory cortices. Our proposed architecture provides possible explanations for a number of human electrophysiological and neuroimaging results and generates testable predictions linking neurophysiology with behaviour.
A self-organizing neural network architecture for learning human-object interactions
Mar 02, 2018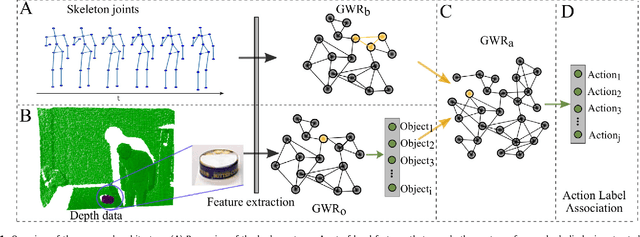
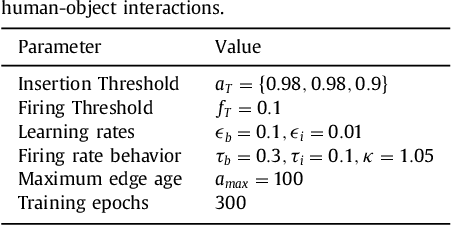
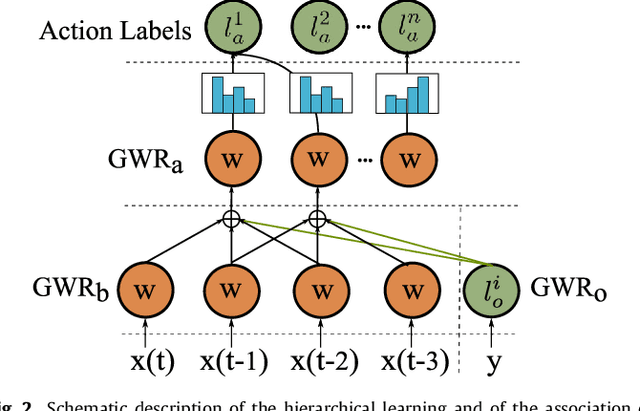
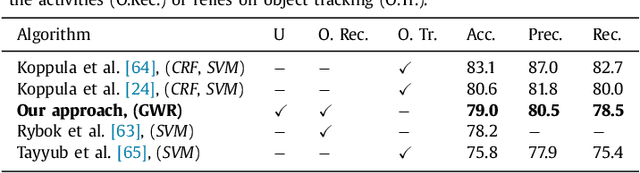
The visual recognition of transitive actions comprising human-object interactions is a key component for artificial systems operating in natural environments. This challenging task requires jointly the recognition of articulated body actions as well as the extraction of semantic elements from the scene such as the identity of the manipulated objects. In this paper, we present a self-organizing neural network for the recognition of human-object interactions from RGB-D videos. Our model consists of a hierarchy of Grow-When-Required (GWR) networks that learn prototypical representations of body motion patterns and objects, accounting for the development of action-object mappings in an unsupervised fashion. We report experimental results on a dataset of daily activities collected for the purpose of this study as well as on a publicly available benchmark dataset. In line with neurophysiological studies, our self-organizing architecture exhibits higher neural activation for congruent action-object pairs learned during training sessions with respect to synthetically created incongruent ones. We show that our unsupervised model shows competitive classification results on the benchmark dataset with respect to strictly supervised approaches.
Expectation Learning for Adaptive Crossmodal Stimuli Association
Jan 23, 2018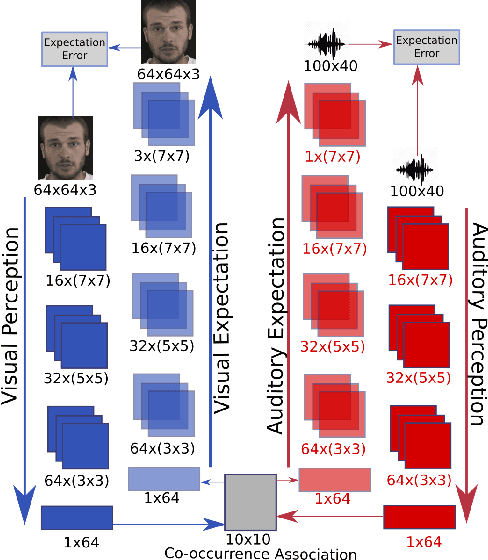
The human brain is able to learn, generalize, and predict crossmodal stimuli. Learning by expectation fine-tunes crossmodal processing at different levels, thus enhancing our power of generalization and adaptation in highly dynamic environments. In this paper, we propose a deep neural architecture trained by using expectation learning accounting for unsupervised learning tasks. Our learning model exhibits a self-adaptable behavior, setting the first steps towards the development of deep learning architectures for crossmodal stimuli association.