 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Instance Segmentation via Tracklet Query and Proposal
Mar 03, 2022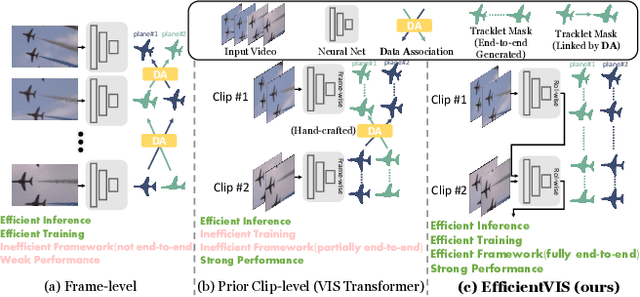
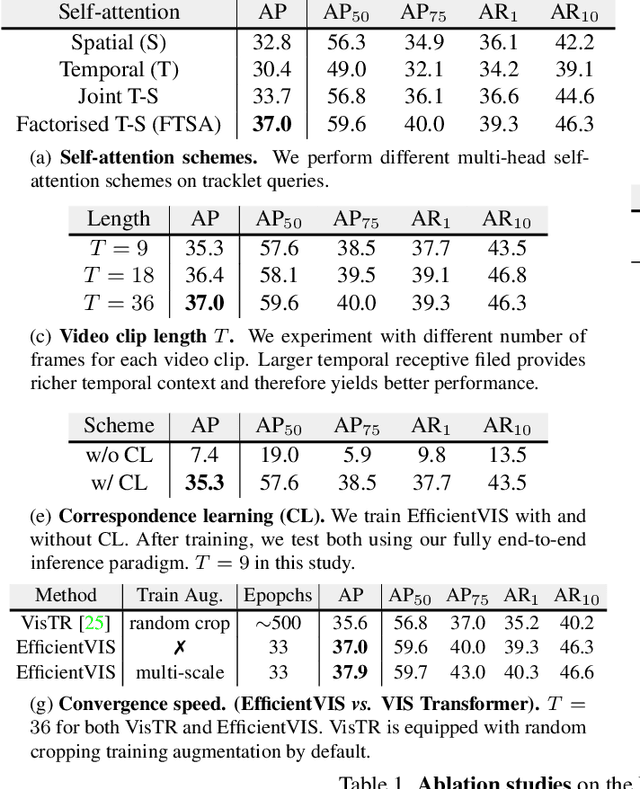
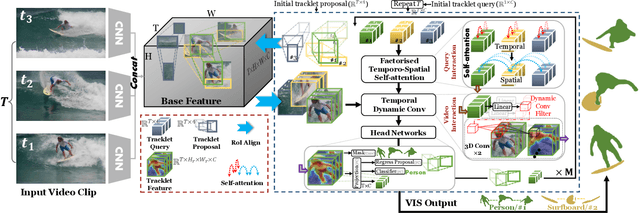
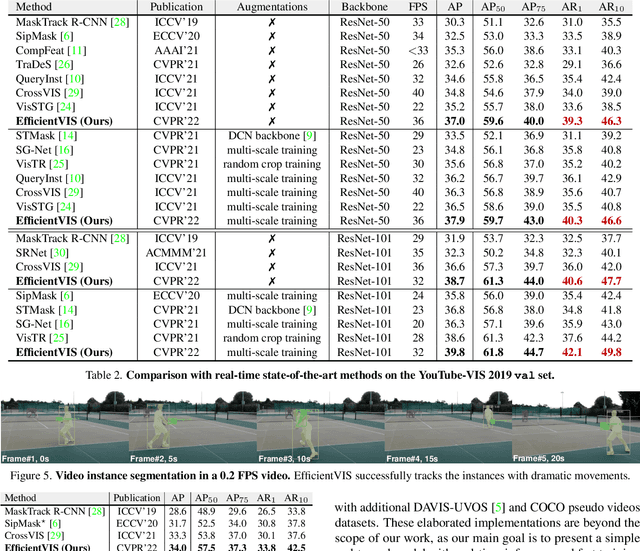
Video Instance Segmentation (VIS) aims to simultaneously classify, segment, and track multiple object instances in videos. Recent clip-level VIS takes a short video clip as input each time showing stronger performance than frame-level VIS (tracking-by-segmentation), as more temporal context from multiple frames is utilized. Yet, most clip-level methods are neither end-to-end learnable nor real-time. These limitations are addressed by the recent VIS transformer (VisTR) which performs VIS end-to-end within a clip. However, VisTR suffers from long training time due to its frame-wise dense attention. In addition, VisTR is not fully end-to-end learnable in multiple video clips as it requires a hand-crafted data association to link instance tracklets between successive clips. This paper proposes EfficientVIS, a fully end-to-end framework with efficient training and inference. At the core are tracklet query and tracklet proposal that associate and segment regions-of-interest (RoIs) across space and time by an iterative query-video interaction. We further propose a correspondence learning that makes tracklets linking between clips end-to-end learnable. Compared to VisTR, EfficientVIS requires 15x fewer training epochs while achieving state-of-the-art accuracy on the YouTube-VIS benchmark. Meanwhile, our method enables whole video instance segmentation in a single end-to-end pass without data association at all.
Synthetic Data for Model Selection
May 03, 2021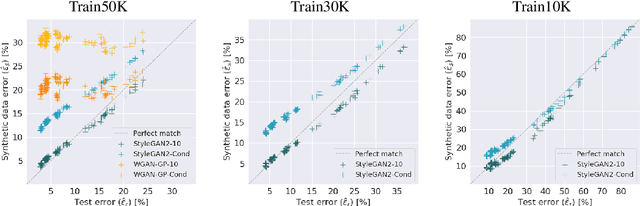
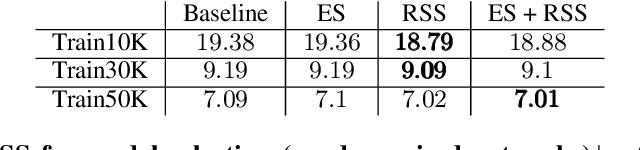
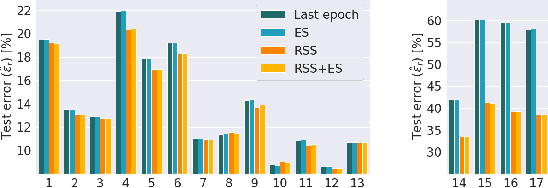

Recent improvements in synthetic data generation make it possible to produce images that are highly photorealistic and indistinguishable from real ones. Furthermore, synthetic generation pipelines have the potential to generate an unlimited number of images. The combination of high photorealism and scale turn the synthetic data into a promising candidate for potentially improving various machine learning (ML) pipelines. Thus far, a large body of research in this field has focused on using synthetic images for training, by augmenting and enlarging training data. In contrast to using synthetic data for training, in this work we explore whether synthetic data can be beneficial for model selection. Considering the task of image classification, we demonstrate that when data is scarce, synthetic data can be used to replace the held out validation set, thus allowing to train on a larger dataset.
Energy-Based Learning for Scene Graph Generation
Mar 03, 2021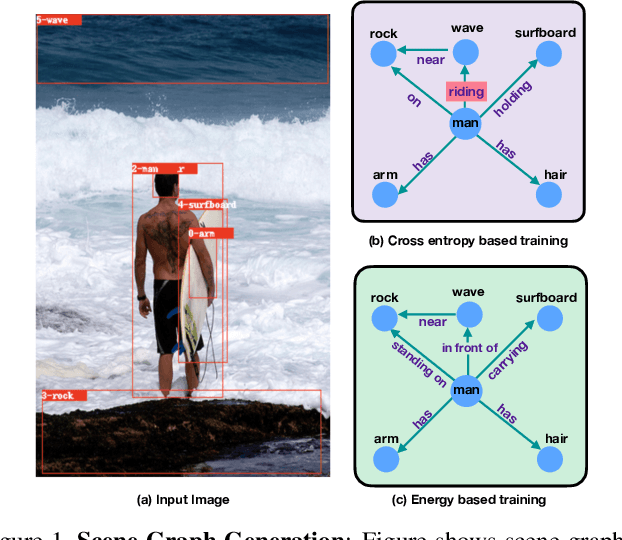
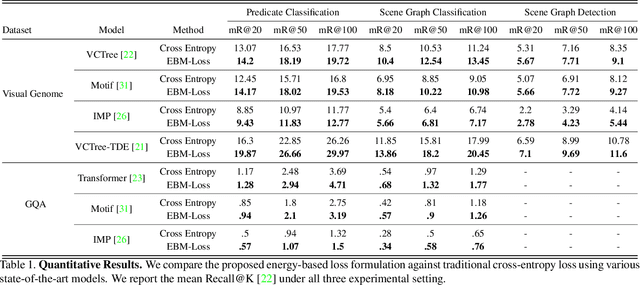
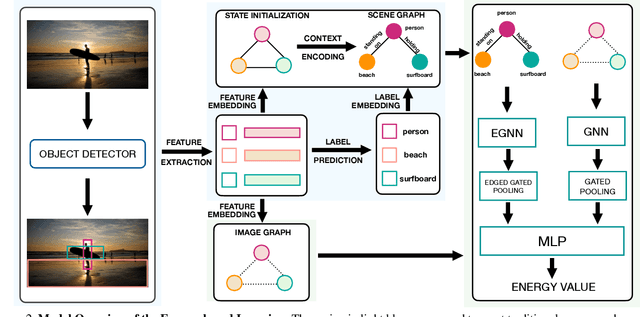
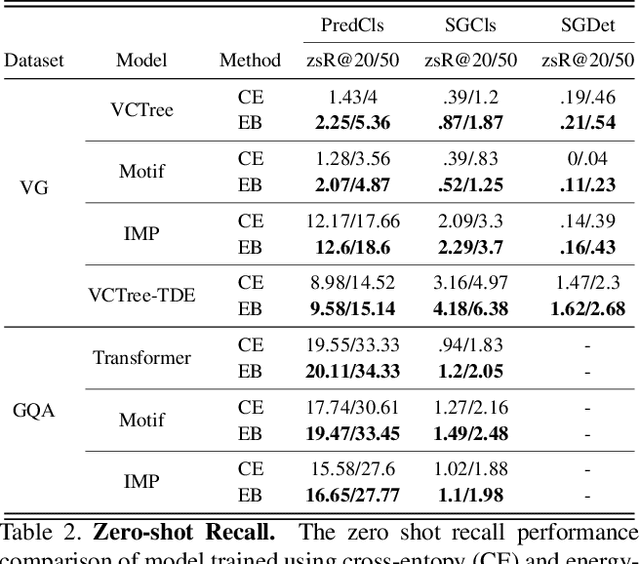
Traditional scene graph generation methods are trained using cross-entropy losses that treat objects and relationships as independent entities. Such a formulation, however, ignores the structure in the output space, in an inherently structured prediction problem. In this work, we introduce a novel energy-based learning framework for generating scene graphs. The proposed formulation allows for efficiently incorporating the structure of scene graphs in the output space. This additional constraint in the learning framework acts as an inductive bias and allows models to learn efficiently from a small number of labels. We use the proposed energy-based framework to train existing state-of-the-art models and obtain a significant performance improvement, of up to 21% and 27%, on the Visual Genome and GQA benchmark datasets, respectively. Furthermore, we showcase the learning efficiency of the proposed framework by demonstrating superior performance in the zero- and few-shot settings where data is scarce.
GAN-Control: Explicitly Controllable GANs
Jan 07, 2021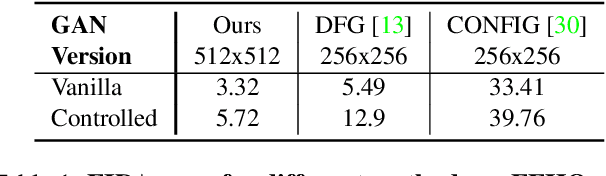
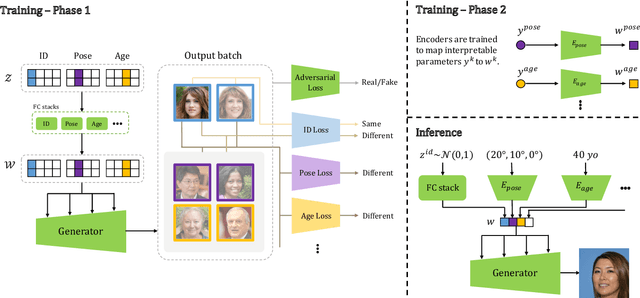

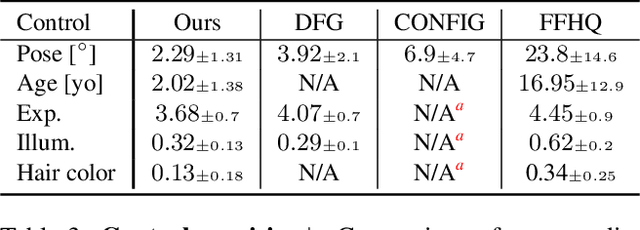
We present a framework for training GANs with explicit control over generated images. We are able to control the generated image by settings exact attributes such as age, pose, expression, etc. Most approaches for editing GAN-generated images achieve partial control by leveraging the latent space disentanglement properties, obtained implicitly after standard GAN training. Such methods are able to change the relative intensity of certain attributes, but not explicitly set their values. Recently proposed methods, designed for explicit control over human faces, harness morphable 3D face models to allow fine-grained control capabilities in GANs. Unlike these methods, our control is not constrained to morphable 3D face model parameters and is extendable beyond the domain of human faces. Using contrastive learning, we obtain GANs with an explicitly disentangled latent space. This disentanglement is utilized to train control-encoders mapping human-interpretable inputs to suitable latent vectors, thus allowing explicit control. In the domain of human faces we demonstrate control over identity, age, pose, expression, hair color and illumination. We also demonstrate control capabilities of our framework in the domains of painted portraits and dog image generation. We demonstrate that our approach achieves state-of-the-art performance both qualitatively and quantitatively.
From Real to Synthetic and Back: Synthesizing Training Data for Multi-Person Scene Understanding
Jun 03, 2020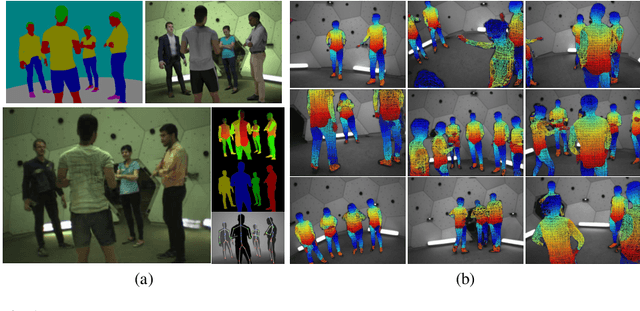
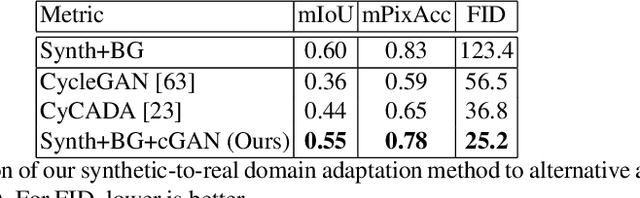
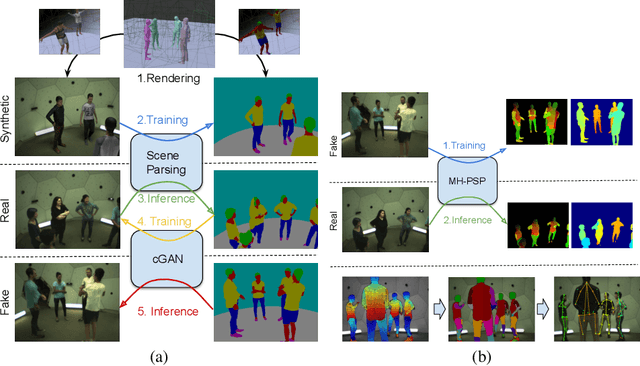
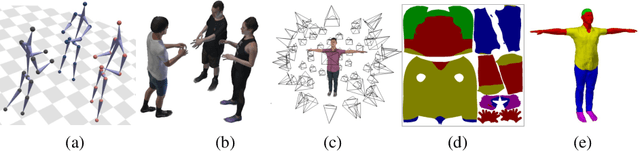
We present a method for synthesizing naturally looking images of multiple people interacting in a specific scenario. These images benefit from the advantages of synthetic data: being fully controllable and fully annotated with any type of standard or custom-defined ground truth. To reduce the synthetic-to-real domain gap, we introduce a pipeline consisting of the following steps: 1) we render scenes in a context modeled after the real world, 2) we train a human parsing model on the synthetic images, 3) we use the model to estimate segmentation maps for real images, 4) we train a conditional generative adversarial network (cGAN) to learn the inverse mapping -- from a segmentation map to a real image, and 5) given new synthetic segmentation maps, we use the cGAN to generate realistic images. An illustration of our pipeline is presented in Figure 2. We use the generated data to train a multi-task model on the challenging tasks of UV mapping and dense depth estimation. We demonstrate the value of the data generation and the trained model, both quantitatively and qualitatively on the CMU Panoptic Dataset.
AOWS: Adaptive and optimal network width search with latency constraints
May 21, 2020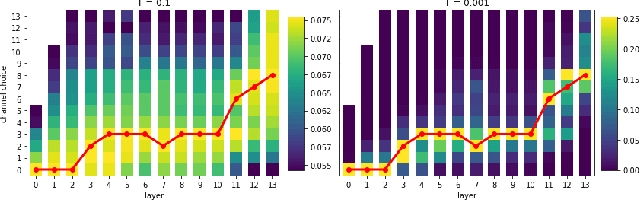
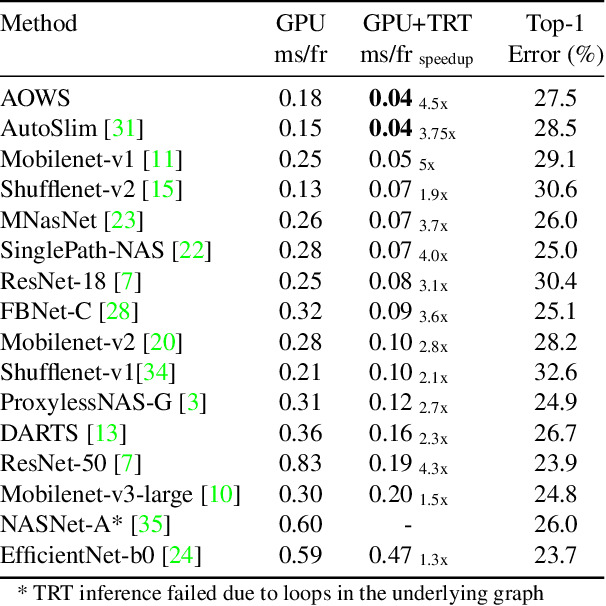
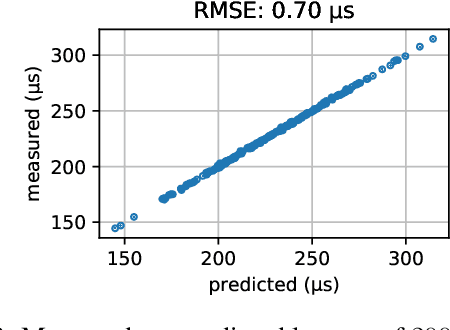
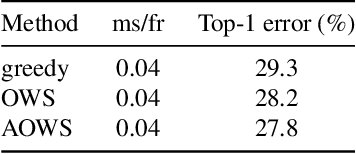
Neural architecture search (NAS) approaches aim at automatically finding novel CNN architectures that fit computational constraints while maintaining a good performance on the target platform. We introduce a novel efficient one-shot NAS approach to optimally search for channel numbers, given latency constraints on a specific hardware. We first show that we can use a black-box approach to estimate a realistic latency model for a specific inference platform, without the need for low-level access to the inference computation. Then, we design a pairwise MRF to score any channel configuration and use dynamic programming to efficiently decode the best performing configuration, yielding an optimal solution for the network width search. Finally, we propose an adaptive channel configuration sampling scheme to gradually specialize the training phase to the target computational constraints. Experiments on ImageNet classification show that our approach can find networks fitting the resource constraints on different target platforms while improving accuracy over the state-of-the-art efficient networks.
Multi-Task Learning from Videos via Efficient Inter-Frame Attention
Feb 18, 2020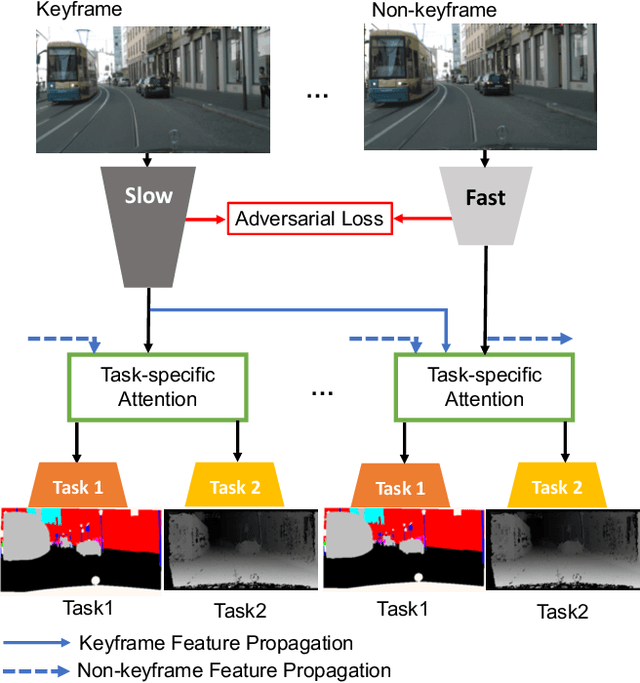
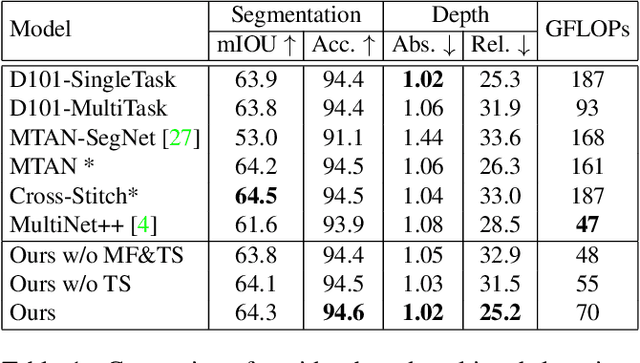
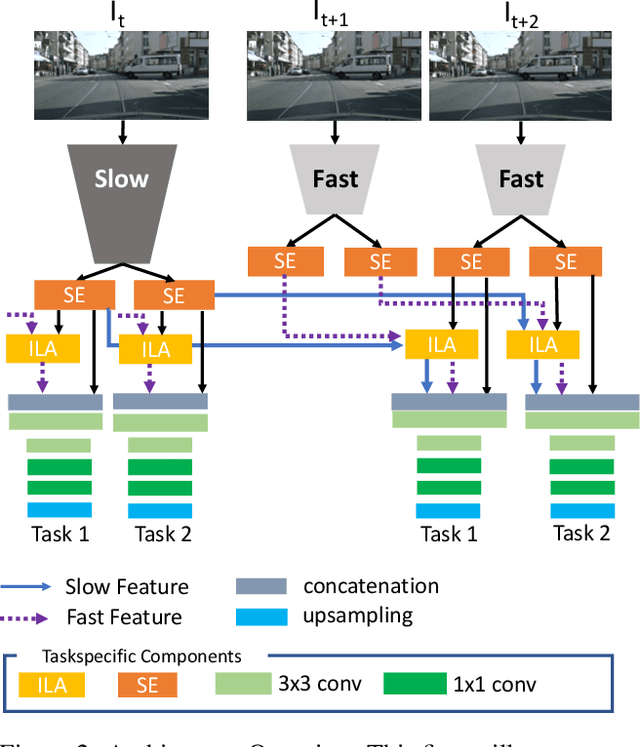
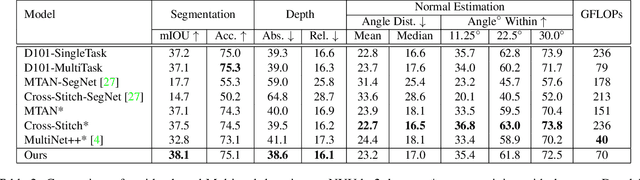
Prior work in multi-task learning has mainly focused on predictions on a single image. In this work, we present a new approach for multi-task learning from videos. Our approach contains a novel inter-frame attention module which allows learning of task-specific attention across frames. We embed the attention module in a "slow-fast" architecture, where the slower network runs on sparsely sampled keyframes and the lightweight shallow network runs on non-key frames at a high frame rate. We further propose an effective adversarial learning strategy to encourage the slow and fast network to learn similar features. The proposed architecture ensures low-latency multi-task learning while maintaining high quality prediction. Experiments show competitive accuracy compared to state-of-the-art on two multi-task learning benchmarks while reducing the number of floating point operations (FLOPs) by 70%. Meanwhile, our attention based feature propagation outperforms other feature propagation methods in accuracy by up to 90% reduction of FLOPs.
Extreme 3D Face Reconstruction: Seeing Through Occlusions
Mar 29, 2018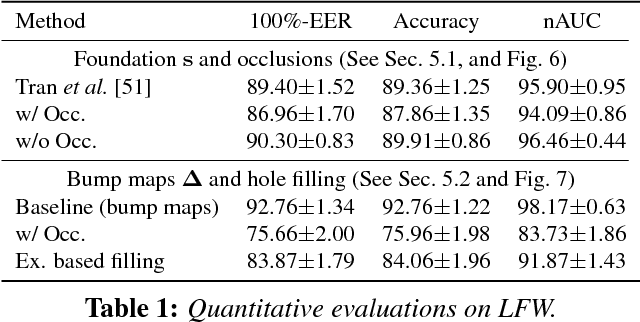
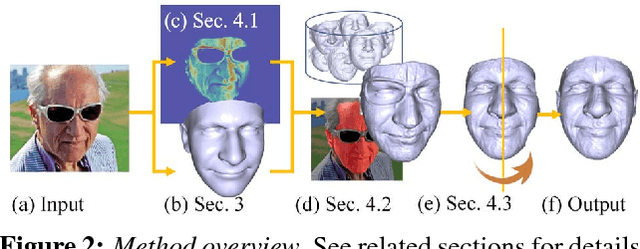

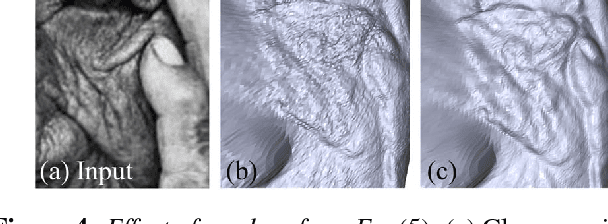
Existing single view, 3D face reconstruction methods can produce beautifully detailed 3D results, but typically only for near frontal, unobstructed viewpoints. We describe a system designed to provide detailed 3D reconstructions of faces viewed under extreme conditions, out of plane rotations, and occlusions. Motivated by the concept of bump mapping, we propose a layered approach which decouples estimation of a global shape from its mid-level details (e.g., wrinkles). We estimate a coarse 3D face shape which acts as a foundation and then separately layer this foundation with details represented by a bump map. We show how a deep convolutional encoder-decoder can be used to estimate such bump maps. We further show how this approach naturally extends to generate plausible details for occluded facial regions. We test our approach and its components extensively, quantitatively demonstrating the invariance of our estimated facial details. We further provide numerous qualitative examples showing that our method produces detailed 3D face shapes in viewing conditions where existing state of the art often break down.
ExpNet: Landmark-Free, Deep, 3D Facial Expressions
Feb 02, 2018
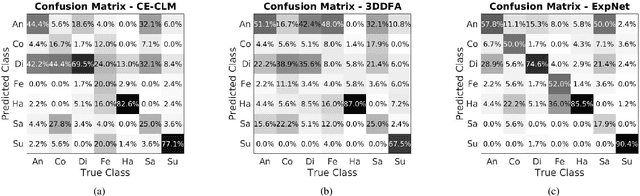
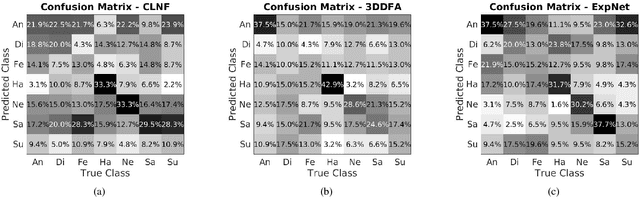
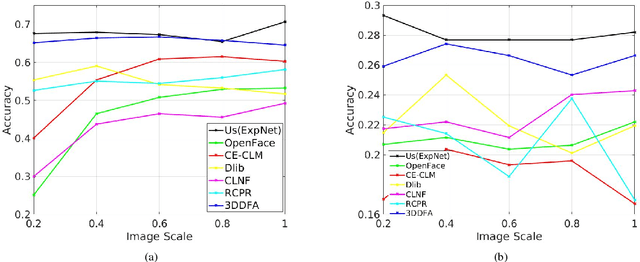
We describe a deep learning based method for estimating 3D facial expression coefficients. Unlike previous work, our process does not relay on facial landmark detection methods as a proxy step. Recent methods have shown that a CNN can be trained to regress accurate and discriminative 3D morphable model (3DMM) representations, directly from image intensities. By foregoing facial landmark detection, these methods were able to estimate shapes for occluded faces appearing in unprecedented in-the-wild viewing conditions. We build on those methods by showing that facial expressions can also be estimated by a robust, deep, landmark-free approach. Our ExpNet CNN is applied directly to the intensities of a face image and regresses a 29D vector of 3D expression coefficients. We propose a unique method for collecting data to train this network, leveraging on the robustness of deep networks to training label noise. We further offer a novel means of evaluating the accuracy of estimated expression coefficients: by measuring how well they capture facial emotions on the CK+ and EmotiW-17 emotion recognition benchmarks. We show that our ExpNet produces expression coefficients which better discriminate between facial emotions than those obtained using state of the art, facial landmark detection techniques. Moreover, this advantage grows as image scales drop, demonstrating that our ExpNet is more robust to scale changes than landmark detection methods. Finally, at the same level of accuracy, our ExpNet is orders of magnitude faster than its alternatives.
FacePoseNet: Making a Case for Landmark-Free Face Alignment
Aug 31, 2017

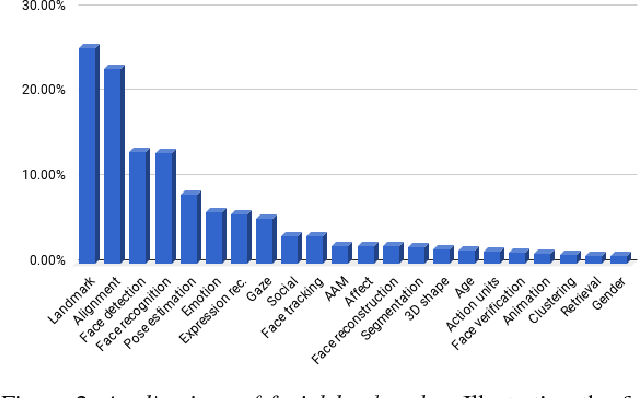
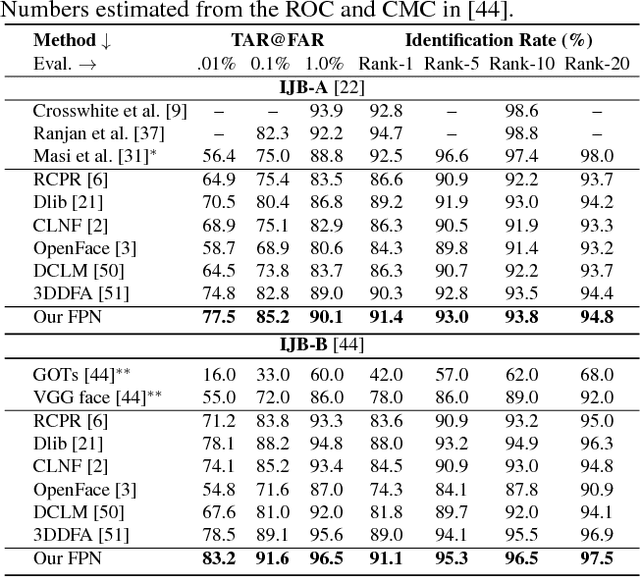
We show how a simple convolutional neural network (CNN) can be trained to accurately and robustly regress 6 degrees of freedom (6DoF) 3D head pose, directly from image intensities. We further explain how this FacePoseNet (FPN) can be used to align faces in 2D and 3D as an alternative to explicit facial landmark detection for these tasks. We claim that in many cases the standard means of measuring landmark detector accuracy can be misleading when comparing different face alignments. Instead, we compare our FPN with existing methods by evaluating how they affect face recognition accuracy on the IJB-A and IJB-B benchmarks: using the same recognition pipeline, but varying the face alignment method. Our results show that (a) better landmark detection accuracy measured on the 300W benchmark does not necessarily imply better face recognition accuracy. (b) Our FPN provides superior 2D and 3D face alignment on both benchmarks. Finally, (c), FPN aligns faces at a small fraction of the computational cost of comparably accurate landmark detectors. For many purposes, FPN is thus a far faster and far more accurate face alignment method than using facial landmark detectors.