 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Strategic Recommendations
Sep 15, 2020

Strategic recommendations (SR) refer to the problem where an intelligent agent observes the sequential behaviors and activities of users and decides when and how to interact with them to optimize some long-term objectives, both for the user and the business. These systems are in their infancy in the industry and in need of practical solutions to some fundamental research challenges. At Adobe research, we have been implementing such systems for various use-cases, including points of interest recommendations, tutorial recommendations, next step guidance in multi-media editing software, and ad recommendation for optimizing lifetime value. There are many research challenges when building these systems, such as modeling the sequential behavior of users, deciding when to intervene and offer recommendations without annoying the user, evaluating policies offline with high confidence, safe deployment, non-stationarity, building systems from passive data that do not contain past recommendations, resource constraint optimization in multi-user systems, scaling to large and dynamic actions spaces, and handling and incorporating human cognitive biases. In this paper we cover various use-cases and research challenges we solved to make these systems practical.
Optimizing for the Future in Non-Stationary MDPs
Jun 02, 2020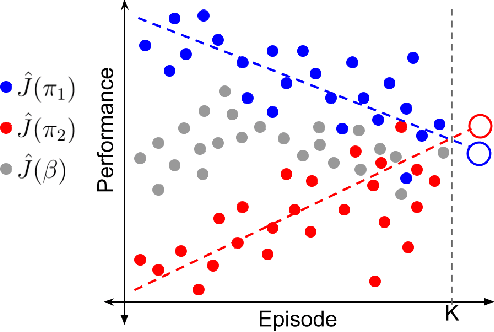
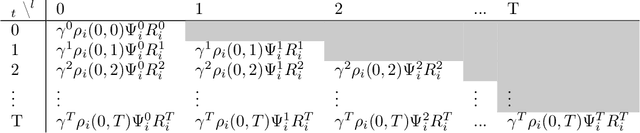
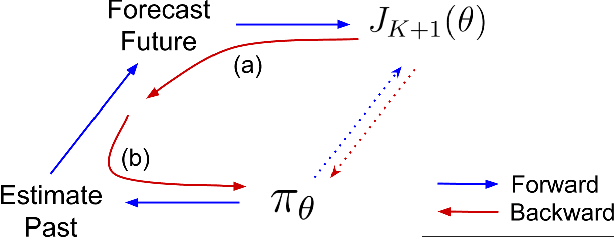
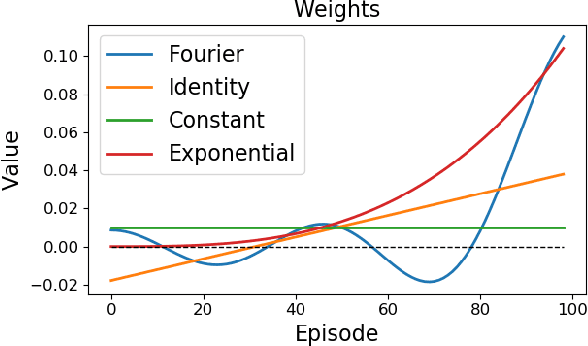
Most reinforcement learning methods are based upon the key assumption that the transition dynamics and reward functions are fixed, that is, the underlying Markov decision process (MDP) is stationary. However, in many practical real-world applications, this assumption is often violated. We discuss how current methods can have inherent limitations for non-stationary MDPs, and therefore searching for a policy that is good for the future, unknown MDP, requires rethinking the optimization paradigm. To address this problem, we develop a method that builds upon ideas from both counter-factual reasoning and curve-fitting to proactively search for a good future policy, without ever modeling the underlying non-stationarity. Interestingly, we observe that minimizing performance over some of the data from past episodes might be beneficial when searching for a policy that maximizes future performance. The effectiveness of the proposed method is demonstrated on problems motivated by real-world applications.
Reinforcement Learning When All Actions are Not Always Available
Jun 05, 2019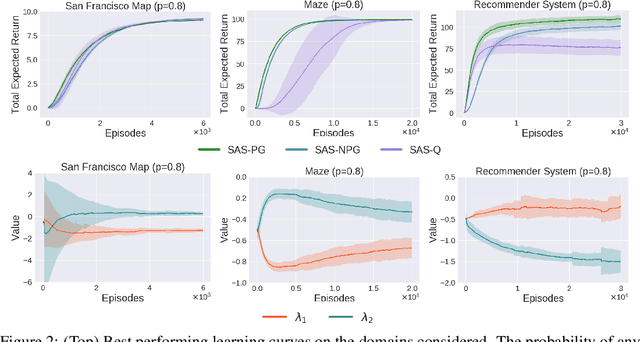
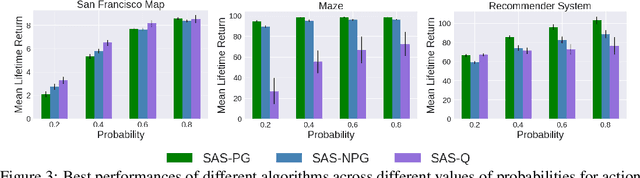
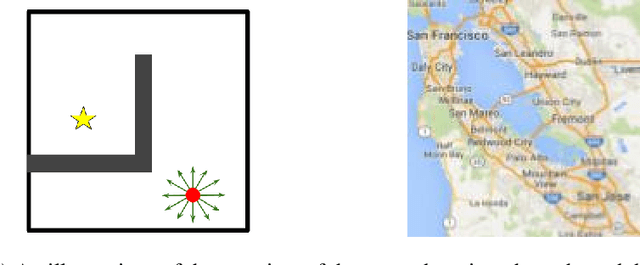
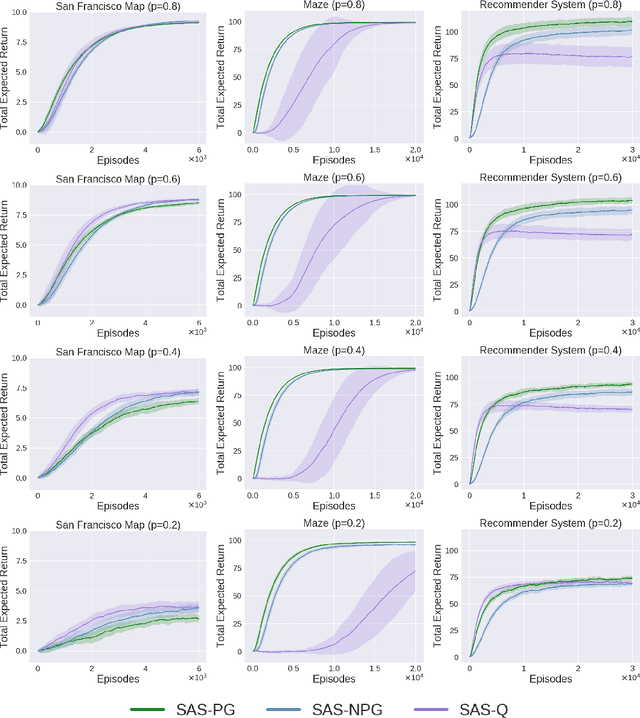
The Markov decision process (MDP) formulation used to model many real-world sequential decision making problems does not capture the setting where the set of available decisions (actions) at each time step is stochastic. Recently, the stochastic action set Markov decision process (SAS-MDP) formulation has been proposed, which captures the concept of a stochastic action set. In this paper we argue that existing RL algorithms for SAS-MDPs suffer from divergence issues, and present new algorithms for SAS-MDPs that incorporate variance reduction techniques unique to this setting, and provide conditions for their convergence. We conclude with experiments that demonstrate the practicality of our approaches using several tasks inspired by real-life use cases wherein the action set is stochastic.
Lifelong Learning with a Changing Action Set
Jun 05, 2019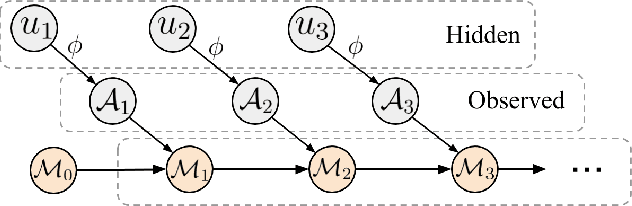
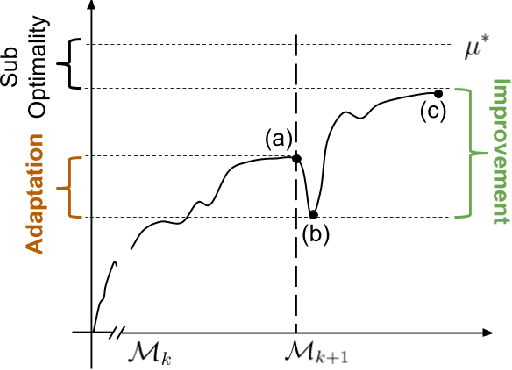
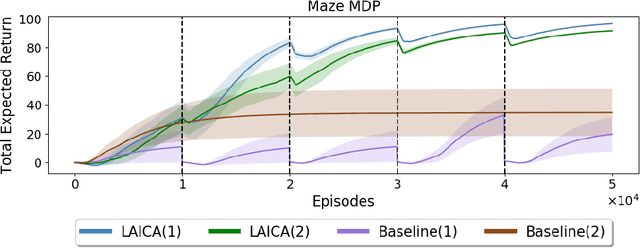
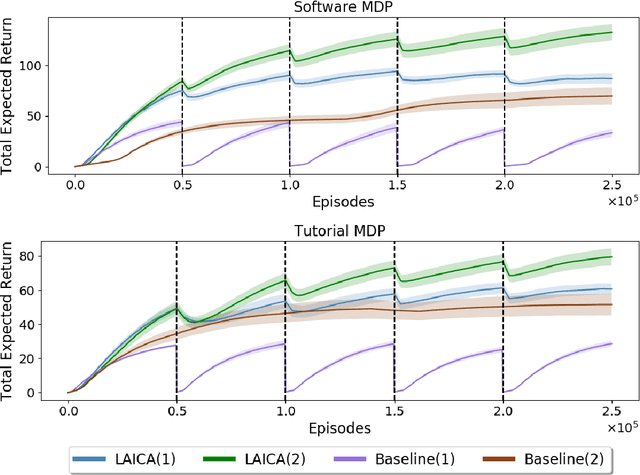
In many real-world sequential decision making problems, the number of available actions (decisions) can vary over time. While problems like catastrophic forgetting, changing transition dynamics, changing rewards functions, etc. have been well-studied in the lifelong learning literature, the setting where the action set changes remains unaddressed. In this paper, we present an algorithm that autonomously adapts to an action set whose size changes over time. To tackle this open problem, we break it into two problems that can be solved iteratively: inferring the underlying, unknown, structure in the space of actions and optimizing a policy that leverages this structure. We demonstrate the efficiency of this approach on large-scale real-world lifelong learning problems.
Learning Action Representations for Reinforcement Learning
Feb 01, 2019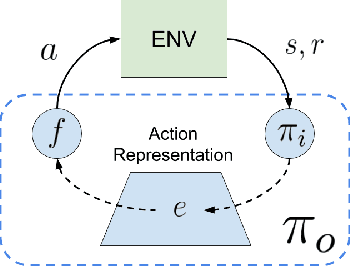
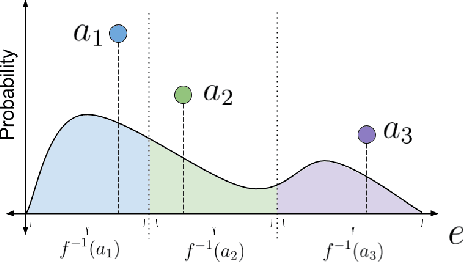
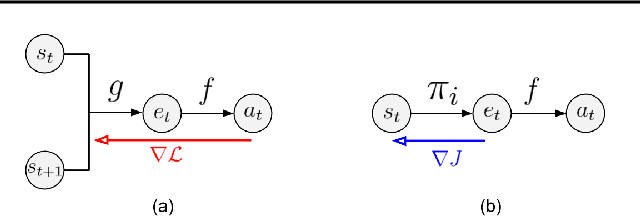
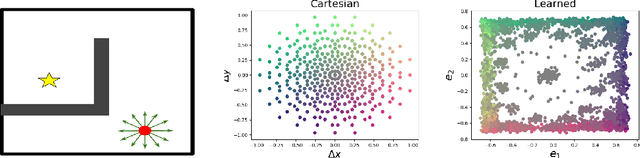
Most model-free reinforcement learning methods leverage state representations (embeddings) for generalization, but either ignore structure in the space of actions or assume the structure is provided a priori. We show how a policy can be decomposed into a component that acts in a low-dimensional space of action representations and a component that transforms these representations into actual actions. These representations improve generalization over large, finite action sets by allowing the agent to infer the outcomes of actions similar to actions already taken. We provide an algorithm to both learn and use action representations and provide conditions for its convergence. The efficacy of the proposed method is demonstrated on large-scale real-world problems.
Posterior Sampling for Large Scale Reinforcement Learning
Oct 22, 2018
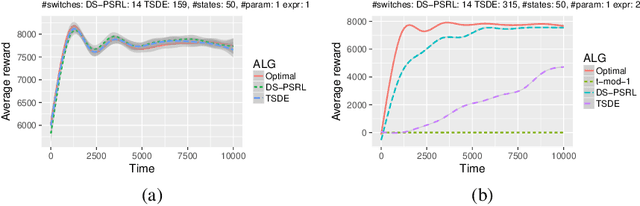
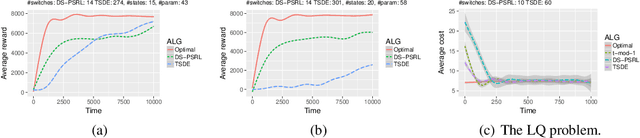
We propose a practical non-episodic PSRL algorithm that unlike recent state-of-the-art PSRL algorithms uses a deterministic, model-independent episode switching schedule. Our algorithm termed deterministic schedule PSRL (DS-PSRL) is efficient in terms of time, sample, and space complexity. We prove a Bayesian regret bound under mild assumptions. Our result is more generally applicable to multiple parameters and continuous state action problems. We compare our algorithm with state-of-the-art PSRL algorithms on standard discrete and continuous problems from the literature. Finally, we show how the assumptions of our algorithm satisfy a sensible parametrization for a large class of problems in sequential recommendations.
Graphical Model Sketch
Jul 18, 2016
Structured high-cardinality data arises in many domains, and poses a major challenge for both modeling and inference. Graphical models are a popular approach to modeling structured data but they are unsuitable for high-cardinality variables. The count-min (CM) sketch is a popular approach to estimating probabilities in high-cardinality data but it does not scale well beyond a few variables. In this work, we bring together the ideas of graphical models and count sketches; and propose and analyze several approaches to estimating probabilities in structured high-cardinality streams of data. The key idea of our approximations is to use the structure of a graphical model and approximately estimate its factors by "sketches", which hash high-cardinality variables using random projections. Our approximations are computationally efficient and their space complexity is independent of the cardinality of variables. Our error bounds are multiplicative and significantly improve upon those of the CM sketch, a state-of-the-art approach to estimating probabilities in streams. We evaluate our approximations on synthetic and real-world problems, and report an order of magnitude improvements over the CM sketch.
Personalized Advertisement Recommendation: A Ranking Approach to Address the Ubiquitous Click Sparsity Problem
Mar 06, 2016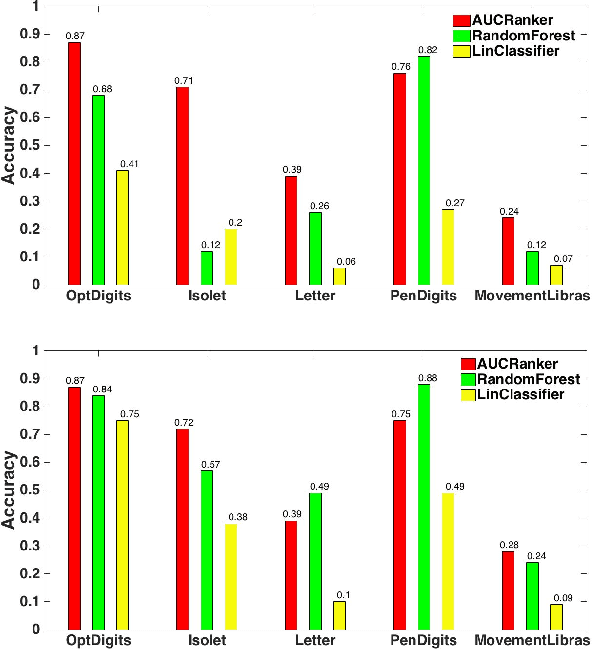

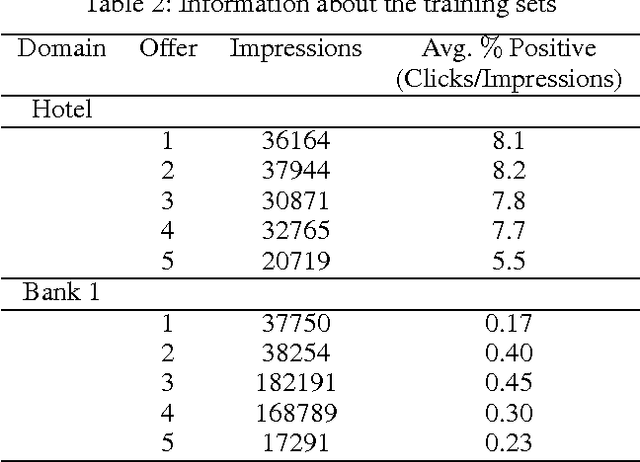
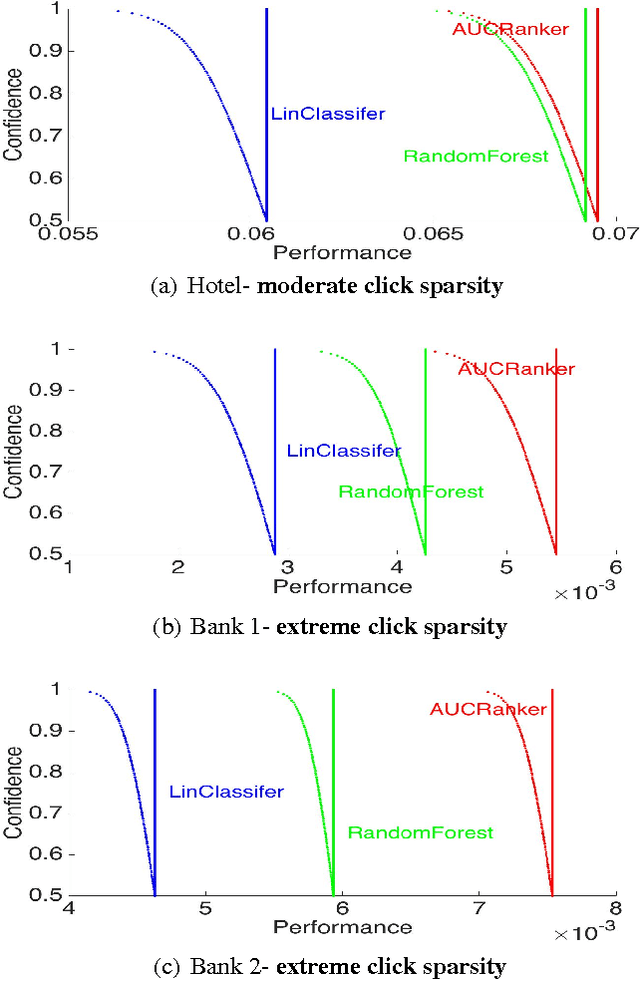
We study the problem of personalized advertisement recommendation (PAR), which consist of a user visiting a system (website) and the system displaying one of $K$ ads to the user. The system uses an internal ad recommendation policy to map the user's profile (context) to one of the ads. The user either clicks or ignores the ad and correspondingly, the system updates its recommendation policy. PAR problem is usually tackled by scalable \emph{contextual bandit} algorithms, where the policies are generally based on classifiers. A practical problem in PAR is extreme click sparsity, due to very few users actually clicking on ads. We systematically study the drawback of using contextual bandit algorithms based on classifier-based policies, in face of extreme click sparsity. We then suggest an alternate policy, based on rankers, learnt by optimizing the Area Under the Curve (AUC) ranking loss, which can significantly alleviate the problem of click sparsity. We conduct extensive experiments on public datasets, as well as three industry proprietary datasets, to illustrate the improvement in click-through-rate (CTR) obtained by using the ranker-based policy over classifier-based policies.