 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised forced alignment of disfluent speech using phoneme-level modeling
May 30, 2023



The study of speech disorders can benefit greatly from time-aligned data. However, audio-text mismatches in disfluent speech cause rapid performance degradation for modern speech aligners, hindering the use of automatic approaches. In this work, we propose a simple and effective modification of alignment graph construction of CTC-based models using Weighted Finite State Transducers. The proposed weakly-supervised approach alleviates the need for verbatim transcription of speech disfluencies for forced alignment. During the graph construction, we allow the modeling of common speech disfluencies, i.e. repetitions and omissions. Further, we show that by assessing the degree of audio-text mismatch through the use of Oracle Error Rate, our method can be effectively used in the wild. Our evaluation on a corrupted version of the TIMIT test set and the UCLASS dataset shows significant improvements, particularly for recall, achieving a 23-25% relative improvement over our baselines.
Depression detection in social media posts using affective and social norm features
Mar 24, 2023We propose a deep architecture for depression detection from social media posts. The proposed architecture builds upon BERT to extract language representations from social media posts and combines these representations using an attentive bidirectional GRU network. We incorporate affective information, by augmenting the text representations with features extracted from a pretrained emotion classifier. Motivated by psychological literature we propose to incorporate profanity and morality features of posts and words in our architecture using a late fusion scheme. Our analysis indicates that morality and profanity can be important features for depression detection. We apply our model for depression detection on Reddit posts on the Pirina dataset, and further consider the setting of detecting depressed users, given multiple posts per user, proposed in the Reddit RSDD dataset. The inclusion of the proposed features yields state-of-the-art results in both settings, namely 2.65% and 6.73% absolute improvement in F1 score respectively. Index Terms: Depression detection, BERT, Feature fusion, Emotion recognition, profanity, morality
Sample-Efficient Unsupervised Domain Adaptation of Speech Recognition Systems A case study for Modern Greek
Dec 31, 2022



Modern speech recognition systems exhibits rapid performance degradation under domain shift. This issue is especially prevalent in data-scarce settings, such as low-resource languages, where diversity of training data is limited. In this work we propose M2DS2, a simple and sample-efficient finetuning strategy for large pretrained speech models, based on mixed source and target domain self-supervision. We find that including source domain self-supervision stabilizes training and avoids mode collapse of the latent representations. For evaluation, we collect HParl, a $120$ hour speech corpus for Greek, consisting of plenary sessions in the Greek Parliament. We merge HParl with two popular Greek corpora to create GREC-MD, a test-bed for multi-domain evaluation of Greek ASR systems. In our experiments we find that, while other Unsupervised Domain Adaptation baselines fail in this resource-constrained environment, M2DS2 yields significant improvements for cross-domain adaptation, even when a only a few hours of in-domain audio are available. When we relax the problem in a weakly supervised setting, we find that independent adaptation for audio using M2DS2 and language using simple LM augmentation techniques is particularly effective, yielding word error rates comparable to the fully supervised baselines.
Adapted Multimodal BERT with Layer-wise Fusion for Sentiment Analysis
Dec 01, 2022



Multimodal learning pipelines have benefited from the success of pretrained language models. However, this comes at the cost of increased model parameters. In this work, we propose Adapted Multimodal BERT (AMB), a BERT-based architecture for multimodal tasks that uses a combination of adapter modules and intermediate fusion layers. The adapter adjusts the pretrained language model for the task at hand, while the fusion layers perform task-specific, layer-wise fusion of audio-visual information with textual BERT representations. During the adaptation process the pre-trained language model parameters remain frozen, allowing for fast, parameter-efficient training. In our ablations we see that this approach leads to efficient models, that can outperform their fine-tuned counterparts and are robust to input noise. Our experiments on sentiment analysis with CMU-MOSEI show that AMB outperforms the current state-of-the-art across metrics, with 3.4% relative reduction in the resulting error and 2.1% relative improvement in 7-class classification accuracy.
Extending Compositional Attention Networks for Social Reasoning in Videos
Oct 03, 2022
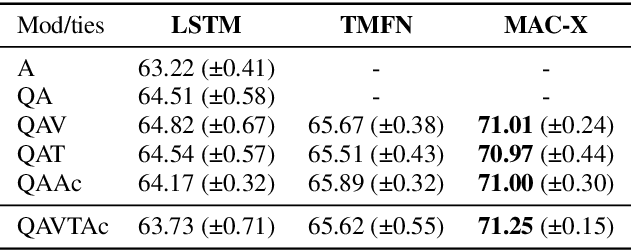
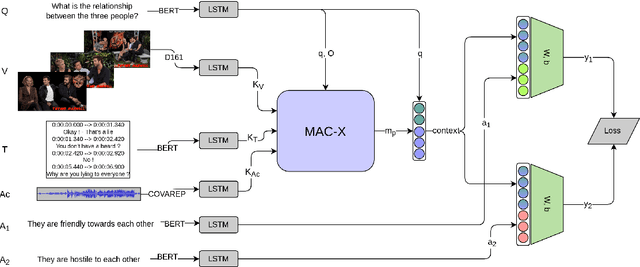

We propose a novel deep architecture for the task of reasoning about social interactions in videos. We leverage the multi-step reasoning capabilities of Compositional Attention Networks (MAC), and propose a multimodal extension (MAC-X). MAC-X is based on a recurrent cell that performs iterative mid-level fusion of input modalities (visual, auditory, text) over multiple reasoning steps, by use of a temporal attention mechanism. We then combine MAC-X with LSTMs for temporal input processing in an end-to-end architecture. Our ablation studies show that the proposed MAC-X architecture can effectively leverage multimodal input cues using mid-level fusion mechanisms. We apply MAC-X to the task of Social Video Question Answering in the Social IQ dataset and obtain a 2.5% absolute improvement in terms of binary accuracy over the current state-of-the-art.
Regotron: Regularizing the Tacotron2 architecture via monotonic alignment loss
Apr 28, 2022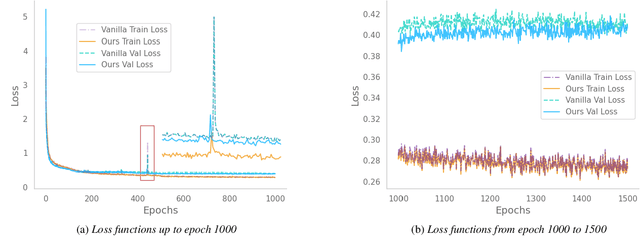
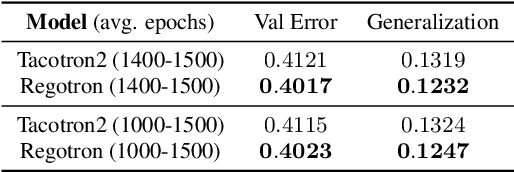
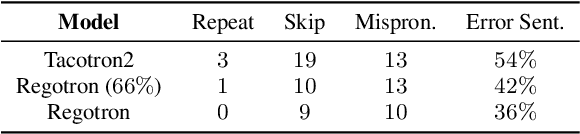
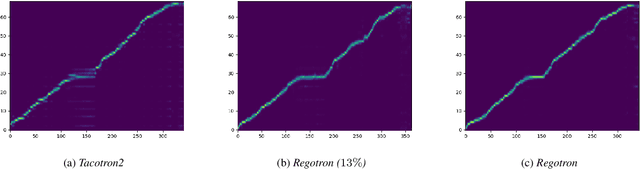
Recent deep learning Text-to-Speech (TTS) systems have achieved impressive performance by generating speech close to human parity. However, they suffer from training stability issues as well as incorrect alignment of the intermediate acoustic representation with the input text sequence. In this work, we introduce Regotron, a regularized version of Tacotron2 which aims to alleviate the training issues and at the same time produce monotonic alignments. Our method augments the vanilla Tacotron2 objective function with an additional term, which penalizes non-monotonic alignments in the location-sensitive attention mechanism. By properly adjusting this regularization term we show that the loss curves become smoother, and at the same time Regotron consistently produces monotonic alignments in unseen examples even at an early stage (13\% of the total number of epochs) of its training process, whereas the fully converged Tacotron2 fails to do so. Moreover, our proposed regularization method has no additional computational overhead, while reducing common TTS mistakes and achieving slighlty improved speech naturalness according to subjective mean opinion scores (MOS) collected from 50 evaluators.
MMLatch: Bottom-up Top-down Fusion for Multimodal Sentiment Analysis
Jan 24, 2022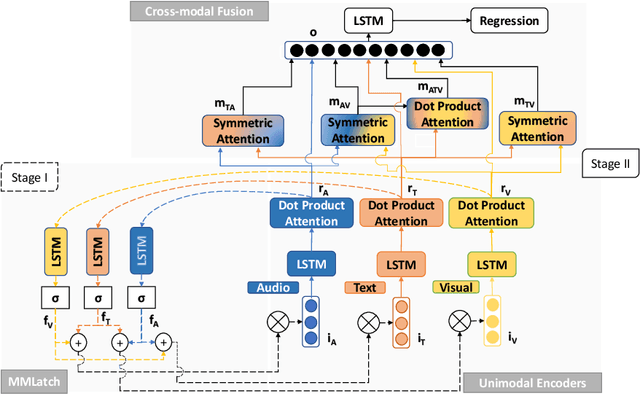
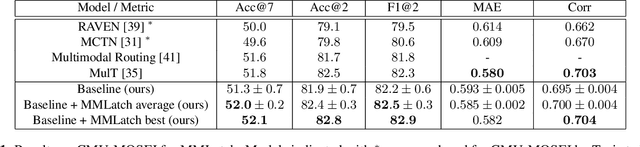


Current deep learning approaches for multimodal fusion rely on bottom-up fusion of high and mid-level latent modality representations (late/mid fusion) or low level sensory inputs (early fusion). Models of human perception highlight the importance of top-down fusion, where high-level representations affect the way sensory inputs are perceived, i.e. cognition affects perception. These top-down interactions are not captured in current deep learning models. In this work we propose a neural architecture that captures top-down cross-modal interactions, using a feedback mechanism in the forward pass during network training. The proposed mechanism extracts high-level representations for each modality and uses these representations to mask the sensory inputs, allowing the model to perform top-down feature masking. We apply the proposed model for multimodal sentiment recognition on CMU-MOSEI. Our method shows consistent improvements over the well established MulT and over our strong late fusion baseline, achieving state-of-the-art results.
EmpBot: A T5-based Empathetic Chatbot focusing on Sentiments
Oct 30, 2021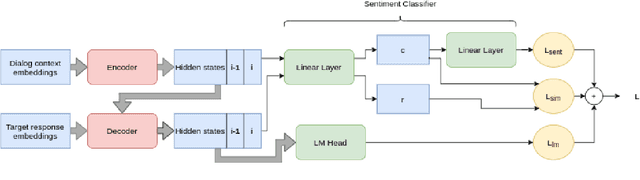
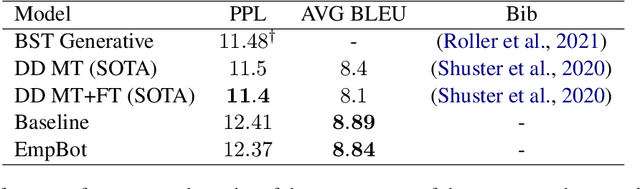


In this paper, we introduce EmpBot: an end-to-end empathetic chatbot. Empathetic conversational agents should not only understand what is being discussed, but also acknowledge the implied feelings of the conversation partner and respond appropriately. To this end, we propose a method based on a transformer pretrained language model (T5). Specifically, during finetuning we propose to use three objectives: response language modeling, sentiment understanding, and empathy forcing. The first objective is crucial for generating relevant and coherent responses, while the next ones are significant for acknowledging the sentimental state of the conversational partner and for favoring empathetic responses. We evaluate our model on the EmpatheticDialogues dataset using both automated metrics and human evaluation. The inclusion of the sentiment understanding and empathy forcing auxiliary losses favor empathetic responses, as human evaluation results indicate, comparing with the current state-of-the-art.
ADMM-DAD net: a deep unfolding network for analysis compressed sensing
Oct 13, 2021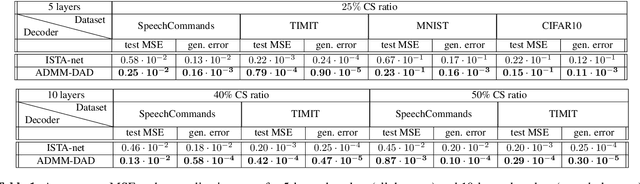
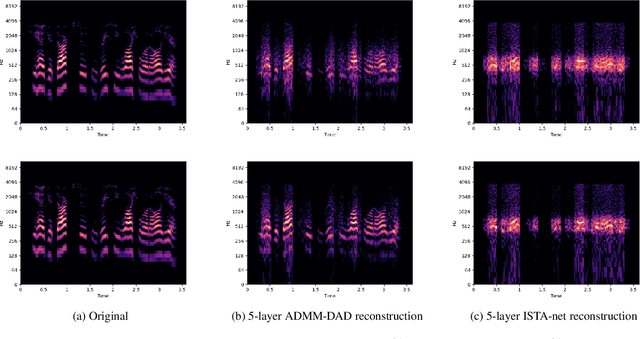

In this paper, we propose a new deep unfolding neural network based on the ADMM algorithm for analysis Compressed Sensing. The proposed network jointly learns a redundant analysis operator for sparsification and reconstructs the signal of interest. We compare our proposed network with a state-of-the-art unfolded ISTA decoder, that also learns an orthogonal sparsifier. Moreover, we consider not only image, but also speech datasets as test examples. Computational experiments demonstrate that our proposed network outperforms the state-of-the-art deep unfolding networks, consistently for both real-world image and speech datasets.
UDALM: Unsupervised Domain Adaptation through Language Modeling
Apr 14, 2021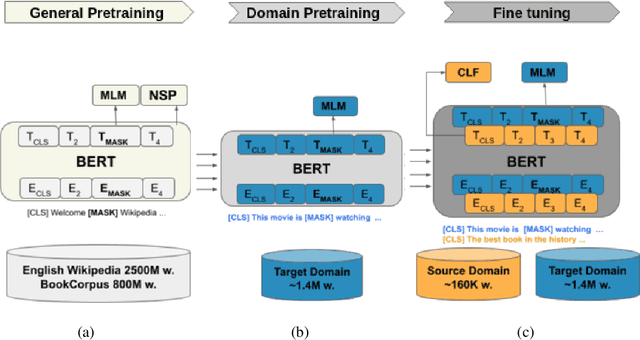
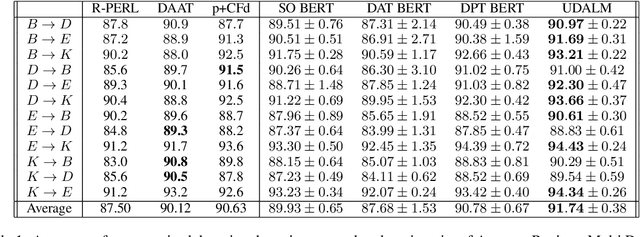
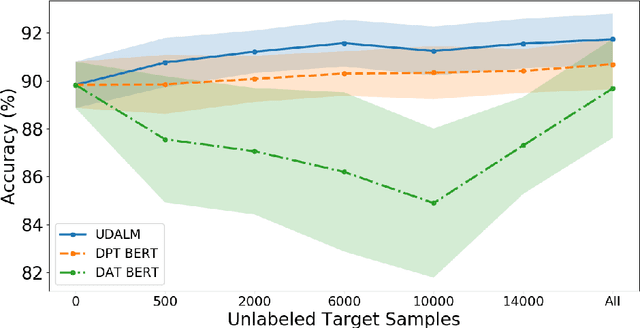
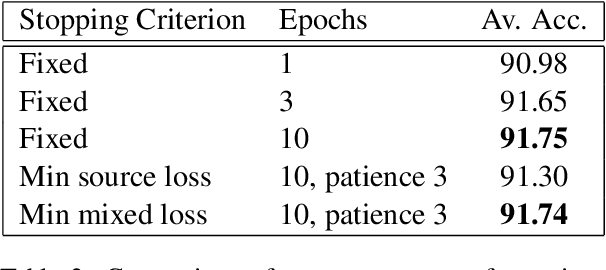
In this work we explore Unsupervised Domain Adaptation (UDA) of pretrained language models for downstream tasks. We introduce UDALM, a fine-tuning procedure, using a mixed classification and Masked Language Model loss, that can adapt to the target domain distribution in a robust and sample efficient manner. Our experiments show that performance of models trained with the mixed loss scales with the amount of available target data and the mixed loss can be effectively used as a stopping criterion during UDA training. Furthermore, we discuss the relationship between A-distance and the target error and explore some limitations of the Domain Adversarial Training approach. Our method is evaluated on twelve domain pairs of the Amazon Reviews Sentiment dataset, yielding $91.74\%$ accuracy, which is an $1.11\%$ absolute improvement over the state-of-the-art.