 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Preference Tuning Generalization and Diversity Under Domain Shift
Jan 09, 2026Preference tuning aligns pretrained language models to human judgments of quality, helpfulness, or safety by optimizing over explicit preference signals rather than likelihood alone. Prior work has shown that preference-tuning degrades performance and reduces helpfulness when evaluated outside the training domain. However, the extent to which adaptation strategies mitigate this domain shift remains unexplored. We address this challenge by conducting a comprehensive and systematic study of alignment generalization under domain shift. We compare five popular alignment objectives and various adaptation strategies from source to target, including target-domain supervised fine-tuning and pseudo-labeling, across summarization and question-answering helpfulness tasks. Our findings reveal systematic differences in generalization across alignment objectives under domain shift. We show that adaptation strategies based on pseudo-labeling can substantially reduce domain-shift degradation
UDALM: Unsupervised Domain Adaptation through Language Modeling
Apr 14, 2021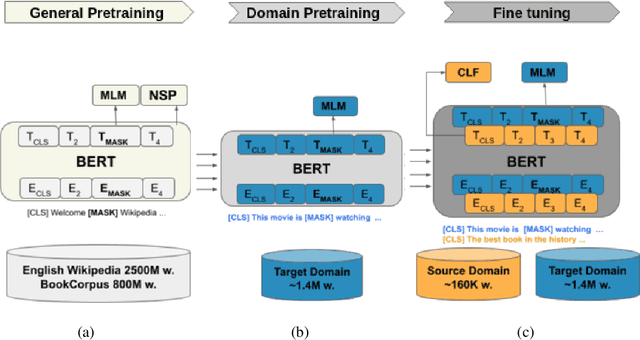
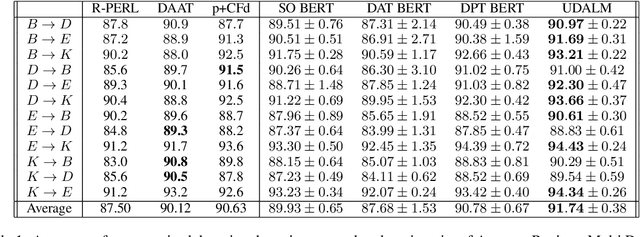
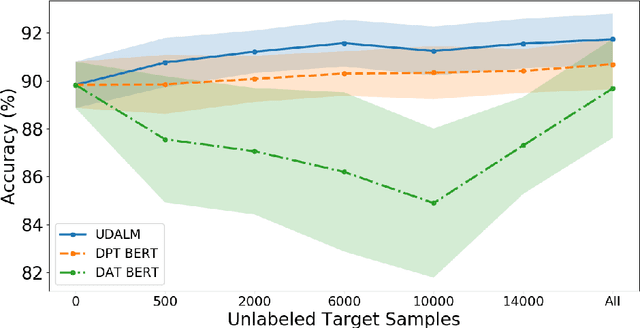
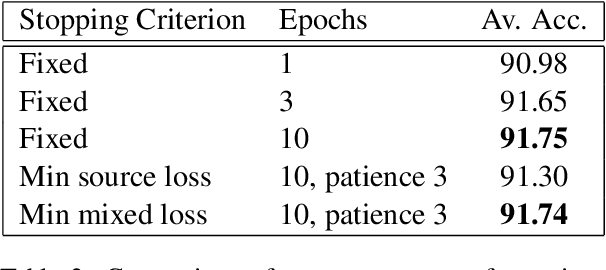
In this work we explore Unsupervised Domain Adaptation (UDA) of pretrained language models for downstream tasks. We introduce UDALM, a fine-tuning procedure, using a mixed classification and Masked Language Model loss, that can adapt to the target domain distribution in a robust and sample efficient manner. Our experiments show that performance of models trained with the mixed loss scales with the amount of available target data and the mixed loss can be effectively used as a stopping criterion during UDA training. Furthermore, we discuss the relationship between A-distance and the target error and explore some limitations of the Domain Adversarial Training approach. Our method is evaluated on twelve domain pairs of the Amazon Reviews Sentiment dataset, yielding $91.74\%$ accuracy, which is an $1.11\%$ absolute improvement over the state-of-the-art.